はじめに
Cloud Spanner にシーケンスと UUID 生成機能が実装されました。従来はアプリケーション側で主キーを生成して書き込む必要がありましたが、この機能によりデータベース側に任せる事ができるようになりました。
シーケンスとは
MySQL では AUTO INCREMENT を使う事が多いため、シーケンス(SEQUENCE)にあまり馴染みがない可能性もあるためシーケンスについて軽く触れます。シーケンスとは一意の整数を生成することができるデータベースのオブジェクトです。
PostgreSQL ではCREATE SEQUENCEで以下のように使います。
CREATE SEQUENCE serial;
のように予め作成しておき、nextval() を呼ぶことで次の値が取り出せます。
SELECT nextval('serial');
nextval() をカラムのデフォルトとして指定することで、自動採番が可能となります。
Cloud Spanner でのシーケンスの使い方
Cloud Spanner での使い方も同様です。
CREATE SEQUENCE serial OPTIONS(sequence_kind='bit_reversed_positive');
で予め作っておき、GET_NEXT_SEQUENCE_VALUE() 関数で次の値が取得できます。
spanner> BEGIN;
Query OK, 0 rows affected (0.02 sec)
spanner(rw txn)> SELECT GET_NEXT_SEQUENCE_VALUE(SEQUENCE serial);
+---------------------+
| |
+---------------------+
| 6917529027641081856 |
+---------------------+
1 rows in set
(65.76 msecs)
spanner(rw txn)> commit;
Query OK, 0 rows affected (0.02 sec)
いきなり大きな値が取れて面食らった方もいらっしゃるかと思いますが、こちらについては次節で説明します。
シーケンスからの値をとるためにトランザクションを開始しているのは、GET_NEXT_SEQUENCE_VALUE 関数は実行によってシーケンスの値という状態変化を伴うため、読み書きトランザクション中での呼び出しを求めているためです。
CREATE SEQUENCE はいくつかオプションを取りますが、sequence_kind が必須のオプションで現時点でbit_reversed_positiveが唯一とり得る値です。その他、開始する値なども指定可能です。他のデータベースから移行してきた場合など、一定の大きさの主キーまで既にレコードが入っている場合など、開始地点を大きめにしたいときにはこれらのオプションを指定ください。
シーケンスは実際には主キーのカラムのデフォルトとして指定することが多いでしょう。その場合は、DDL にDEFAULT (GET_NEXT_SEQUENCE_VALUE(SEQUENCE serial))といった指定をすることで、シーケンスから得た一意の値が自動的に入ります。
spanner> CREATE TABLE Users (
-> UserId INT64 DEFAULT (GET_NEXT_SEQUENCE_VALUE(SEQUENCE serial)),
-> FirstName STRING(1024),
-> LastName STRING(1024),
-> ) PRIMARY KEY (UserId);
Query OK, 0 rows affected (11.96 sec)
spanner> INSERT INTO Users (FirstName, LastName) VALUES ('Yamada', 'Taro');
Query OK, 1 rows affected (0.12 sec)
spanner> INSERT INTO Users (FirstName, LastName) VALUES ('Tanaka', 'Satoko');
Query OK, 1 rows affected (0.32 sec)
spanner> SELECT UserId, BIT_REVERSE(UserId, true) AS Id, FirstName, LastName FROM Users ORDER BY Id;
+---------------------+----+-----------+----------+
| UserId | Id | FirstName | LastName |
+---------------------+----+-----------+----------+
| 8070450532247928832 | 7 | Yamada | Taro |
| 2882303761517117440 | 10 | Tanaka | Satoko |
+---------------------+----+-----------+----------+
2 rows in set (8.65 msecs)
このように INSERT 時に主キーにデフォルトで一意な順序性のある値が設定されます。
実際のアプリケーションから使う場合には、書き込んだレコードの主キーに何が割り当てられたのかを得る必要がありますので、その場合には INSERT 文のTHEN RETURN 構文を使って書き込みの応答を得てください。
BIT_REVERSE 関数
Cloud Spanner では主キーを辞書順に並べて、更に主キーの範囲ごとにデータを複数のノードに分散させます。
そのため、主キーとして単調増加する値を使うと追記する箇所が常に既存データの末尾に集中することになります。これは書き込みの性能についてボトルネックとなる可能性があります。そのため、Cloud Spanner のシーケンスは単調増加する連番をそのままではなく、連番をビット順序反転した値を返します。この反転と同じ処理を行う関数が BIT_REVERSE 関数です。シーケンスは内部の連番に対してビット順を反転した値を返すので、BIT_REVERSE 関数を通すことで元の連番を得ることができます。
余談ですが、BIT_REVERSEの訳語としてはビット反転はちょっと誤解を招くかなと思います。私は最初に聞いたときは各ビットを反転させる(つまりNOT動作)と勘違いしてしまいました。「ビット順序反転」、あるいは「ビットリバース」の方が誤解する可能性は低いと思います。
このセクションではこの関数の動作について解説しますが、通常使う上ではその詳細まで把握している必要はありません。
使用例
spanner> SELECT BIT_REVERSE(50, true) AS results;
+---------------------+
| results |
+---------------------+
| 2738188573441261568 |
+---------------------+
1 rows in set (2.31 msecs)
spanner> SELECT BIT_REVERSE(51, false) AS results;
+----------------------+
| results |
+----------------------+
| -3746994889972252672 |
+----------------------+
1 rows in set (2.37 msecs)
この例では入力として 50 と 51 を与えて、そのビット順序を反転した整数値を得ています。第二引数は入力された値の符号から変更しないフラグです。無効(false)にして呼び出すと 51 のときのように正の値 に対して負の値を返す場合があります。これは Cloud Spanner の整数が符号付き 64bit 整数であることと、以下の動作によるものです。
この関数がどのような変換を行っているかは入力と出力を2進数表記にするとわかりやすいです。
| 10進数表記 | 2進数表記 |
|---|---|
| 50 | 0000000000000000000000000000000000000000000000000000000000110010 |
| 51 | 0000000000000000000000000000000000000000000000000000000000110011 |
| 2738188573441261568 | 0010011000000000000000000000000000000000000000000000000000000000 |
| -3746994889972252672 | 1100110000000000000000000000000000000000000000000000000000000000 |
符号を保存しないときの動作
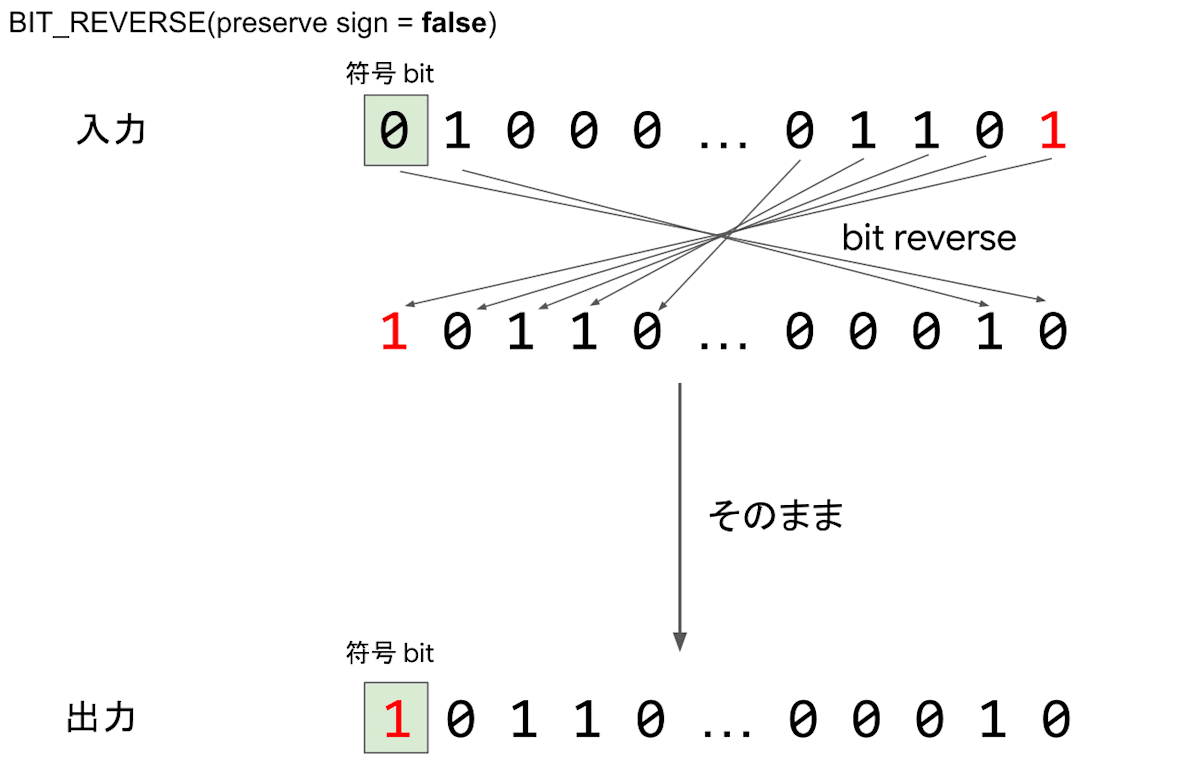
符号を保存した場合には最上位ビット(MSB)が入力の符号と揃えられるためそこを除いて、入力の最下位ビット(LSB)からの並び順が出力の最上位ビットと同じであることがわかると思います。入力が1違うことで出力の最上位ビットが変わることになります。この動作によって、入力が連番であっても出力は数値空間に対して広く分布します。
余談ですが、この処理と同様の関数は Go 言語の math/bits の Reverse などがあります。こちらは符号なし整数型が対象であるため BIT_REVERSE 関数の第二引数に false を与えたときの挙動に相当します。ただし Cloud Spanner の整数は符号付きであるためその点は異なります。
閑話休題。通常この関数はシーケンスの値を元の連番に戻すときに使う事が多いと思います。この場合、第二引数は true の固定で使うと良いでしょう。 false を与えて実行した場合も順序が変わる事はありませんが入力の最上位ビットの分、出力が左シフトされた結果となるため常に2倍の値が得られます。
シーケンスの主キーを使う上での注意点
シーケンスではビット順反転の値を返すため、この値によってソートすると意図した順序の結果が得られません。
また、値は一意となる結果を返しますが、1ずつ増える値ではなく飛び飛びの値となり、順序についても書き込み負荷の状況によっては入れ替わる可能性があります。
BIT_REVERSE 関数を通した値でソートする(ORDER BY)ことで、生成された連番の順で結果を得ることができます。しかしながら、関数を通した値でのソートとなるためインデックスによるソートができず、順序の厳密さもやや欠けます。
厳密に更新した順でソートを行いたい場合は、Commit タイムスタンプのカラムを使うことをご検討ください。Commit タイムスタンプは True Time を使った時刻が記録されているため、このカラムでのソート結果は更新順となります。
UUID の自動生成
以前から一意性があり広く分布する主キーとして、UUIDv4 を使うことが推奨されていました。今回のアップデートで UUID の生成関数が新設され、それを主キーのデフォルトに指定可能となりました。
使用例
spanner> CREATE TABLE Fans (
-> FanId STRING(36) DEFAULT (GENERATE_UUID()),
-> Name STRING(MAX),
-> ) PRIMARY KEY (FanId);
Query OK, 0 rows affected (8.58 sec)
spanner> INSERT INTO Fans (Name) VALUES ('Geordi La Forge') THEN RETURN FanId;
+--------------------------------------+
| FanId |
+--------------------------------------+
| 513ed37d-a3c1-4716-aaa7-80daf8e7fddb |
+--------------------------------------+
Query OK, 1 rows affected (0.15 sec)
spanner> INSERT INTO Fans (Name) VALUES ('Hikaru Sulu') THEN RETURN FanId;
+--------------------------------------+
| FanId |
+--------------------------------------+
| 5a55e0af-9039-455c-8458-d3cf20c928b5 |
+--------------------------------------+
Query OK, 1 rows affected (0.04 sec)
spanner> SELECT * FROM Fans;
+--------------------------------------+-----------------+
| FanId | Name |
+--------------------------------------+-----------------+
| 513ed37d-a3c1-4716-aaa7-80daf8e7fddb | Geordi La Forge |
| 5a55e0af-9039-455c-8458-d3cf20c928b5 | Hikaru Sulu |
+--------------------------------------+-----------------+
2 rows in set (7.39 msecs)
上記の例では書き込みを行った結果について INSERT 文のTHEN RETURNで得ています。アプリケーションから実行される場合も同様に THEN RETURN で書き込み結果を得ると良いです。
UUIDv4 は 122bit の空間にほぼ一様に分布します。これは一般な用途に対して十分に広い空間です。ドキュメントでは 50% の確率で衝突が起こるまで毎秒10億個の生成を 86 年間を続ける必要があると説明されています。通常の用途に対して十分に低い確率ではありますが、衝突以外の要因でも書き込みに失敗する可能性はあるため安全のためにアプリケーション側でのリトライ処理への考慮は引き続き推奨されます。
まとめ
Cloud Spanner にシーケンスと UUID の自動生成機能が実装されました。これらを使うことでアプリケーション側で主キーを生成する必要がなくなりました。使い勝手としては AUTO INCREMENT に近くなりました。
いずれの機能も主キーが広く分布しますので、書き込み性能のボトルネックとならないよう考慮されています。

Discussion