はじめに
Cloud Spanner (以下、Spanner)はスケールアウトする分散データベースとしての特性がありますが、一般的な RDBMS と同じく SQL を実行することができます。SQL の実行時には実行計画を立てて、実データにアクセスを行います。実行計画の内容は分散データベース特有の概念も含まれている場合もありますが、基本的なコンセプトは RDBMS と共通する部分も多くあります。本記事では Spanner でのクエリーの実行計画についての実例をもとにその内容を読み解きます。
対象とするスキーマ及びクエリーは MySQL を対象にした次の記事の内容を Spanner 向けに読み換えた物を使用いたしました。
参考となる記事を公開いただきありがとうございます。ダミーデータについても元記事のスクリプトを Spanner 向けに書き換えたものを使用しました。
Spanner は Google 標準 SQL と PostgreSQL 互換の二通りの SQL モードがデータベース毎に使い分けられますが、本稿では Google 標準 SQL を使用しています。
スキーマ
スキーマに関しては、元記事の定義から変更点があります。
主キーは元の定義では INTEGER の AUTO_INCREMENT として定義されていますが、UUID に変更したため型についても STRING(36) に変更しました。
Spanner ではインターリーブという概念があり、テーブル間で親子関係が定義できます。子テーブルは親テーブルの関連する行と連続した場所に配置されることで、効率的なアクセスが可能となります。
今回の場合、users を親テーブルとして、follows と posts は両方を子テーブルとしました。インターリーブの子テーブルは親テーブルの主キー(user_id)を先頭にした複合主キーである必要があります。
CREATE TABLE `users` (
`user_id` STRING(36) NOT NULL,
`name` STRING(100) NOT NULL,
) PRIMARY KEY (`user_id`);
CREATE TABLE `follows` (
`user_id` STRING(36) NOT NULL,
`followee_id` STRING(36) NOT NULL,
) PRIMARY KEY (user_id, followee_id),
INTERLEAVE IN PARENT users ON DELETE CASCADE;
ALTER TABLE `follows` ADD FOREIGN KEY (followee_id) REFERENCES `users` (user_id);
CREATE TABLE `posts` (
`user_id` STRING(36) NOT NULL,
`post_id` STRING(36) NOT NULL,
`body` STRING(MAX) NOT NULL,
`posted_at` TIMESTAMP NOT NULL,
`deleted` BOOL NOT NULL,
) PRIMARY KEY (`user_id`, post_id),
INTERLEAVE IN PARENT users ON DELETE CASCADE;
CREATE INDEX `idx_user_id_posted_at` ON `posts` (`user_id`, `deleted`, `posted_at` DESC), INTERLEAVE IN users;
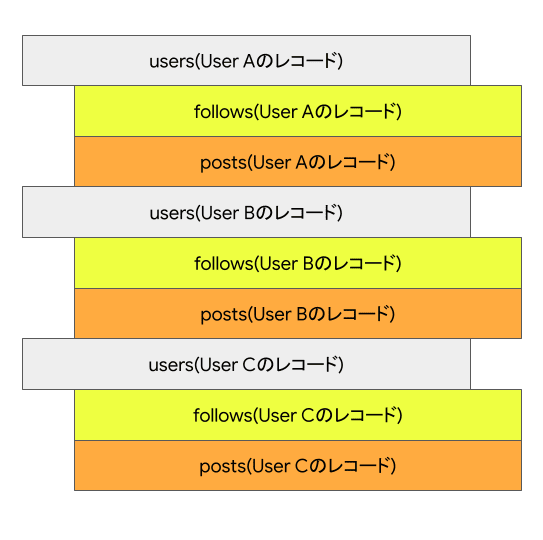
インターリーブの定義により、あるユーザーがフォローしているユーザーの一覧(follows)とポストした記事(posts)はユーザー自体の情報に続いて物理的にまとまって配置されます。物理的には以下の図のようなレイアウトになります。
クエリ
スキーマの変更に伴い一部のカラム名と型を変更しました。そのためクエリー中でのカラム名と条件句の値をを変更しましたが、それ以外の部分についてはそのまま実行可能でした。
SELECT
posts.post_id, posts.posted_at
FROM
posts
JOIN
follows
ON
posts.user_id = follows.followee_id
WHERE
follows.user_id = '07beb0ca-6263-4cc8-9e32-61a308d476b1'
AND posts.deleted = FALSE
AND posts.posted_at <= '2023-09-16 02:41:52.000'
ORDER BY
posts.posted_at DESC
LIMIT
20;
クエリーの意味としては、特定のユーザー('07beb0ca-6263-4cc8-9e32-61a308d476b1')がフォローしているユーザーの投稿記事の一覧を削除済みではなく(posts.deleted = FALSE)、一定の日付よりも前の投稿日(posts.posted_at <= '2023-09-16 02:41:52.000')という条件で取得して、投稿日の降順で先頭20件を取得するというものです。
以降の内容はこのクエリーについての実行計画を読み解きます。
実行計画の取得方法
Spanner の実行計画を取得する主な方法はウェブコンソールまたはクライアントライブラリから取得可能です。定期的な取得であればクライアントライブラリを使ってクライアントを作ることも有効ですが、spanner-cli で対話的にも取得可能です。
実行計画の詳細を JSON 形式で出力することも可能です。クライアントライブラリや gcloud コマンドから取得可能な他、ウェブコンソールからもダウンロードが可能です。JSON 形式は情報量が多いものの、人間が直接読むには複雑であるため apstndb さん作成の spannerplanviz で可視化されると便利です。
実行計画の詳細
ウェブコンソールで取得した実行計画
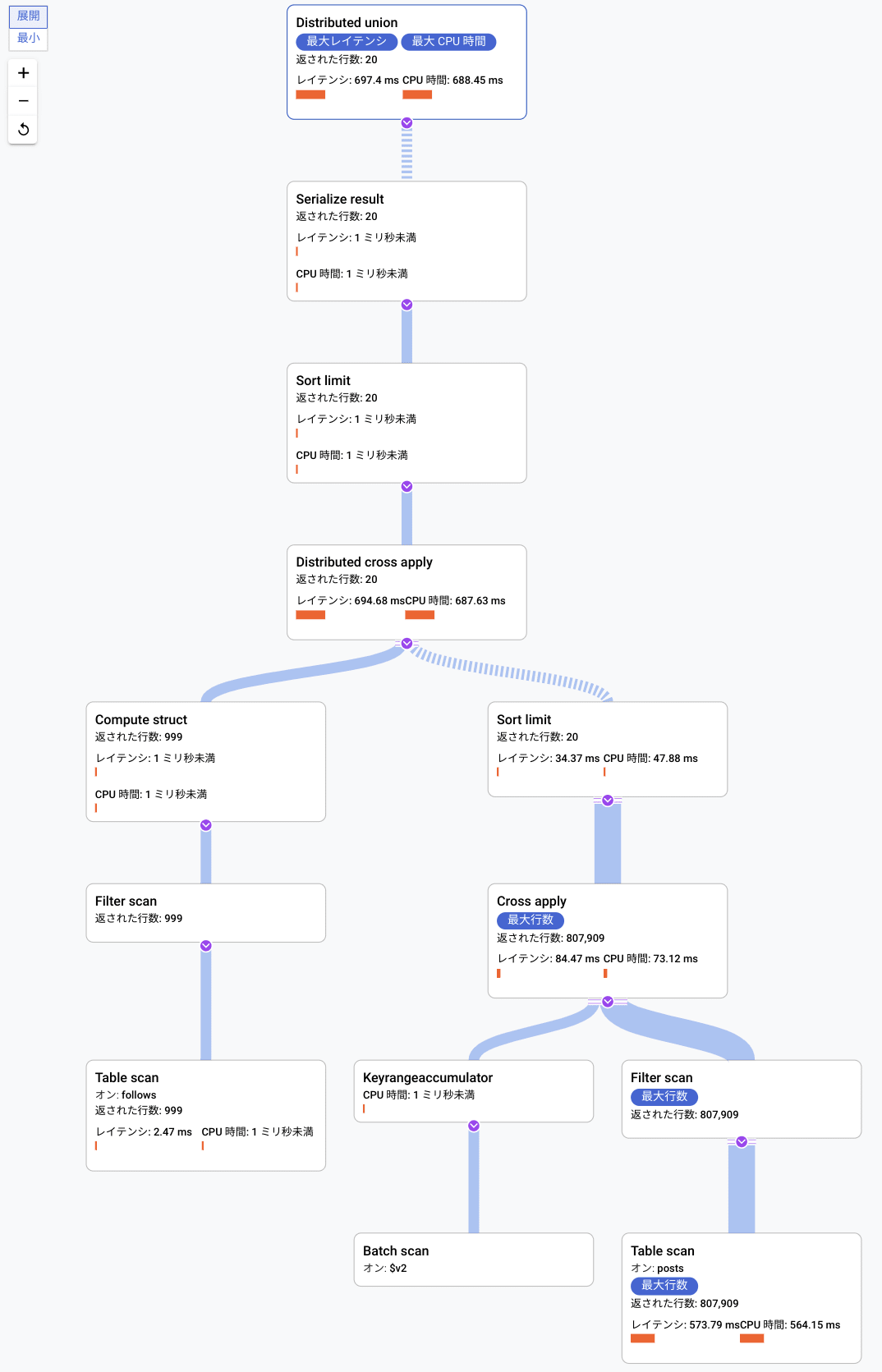
ウェブコンソールからクエリーを実行し、その「説明」タブを見ると実行計画をグラフ化したものが見えます。
spanner-cli から取得した実行計画
spanner-cli から同じクエリーについて EXPLAIN ANALYZE(実行計画と実際の実行時ステータスの取得)を行った結果が以下です。
spanner> EXPLAIN ANALYZE
-> SELECT
-> posts.*
-> FROM
-> posts
-> JOIN
-> follows
-> ON
-> posts.user_id = follows.followee_id
-> WHERE
-> follows.user_id = '07beb0ca-6263-4cc8-9e32-61a308d476b1'
-> AND posts.deleted = FALSE
-> AND posts.posted_at <= '2023-09-16 02:41:52.000'
-> ORDER BY
-> posts.posted_at DESC
-> LIMIT
-> 20;
+-----+---------------------------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+-----+---------------------------------------------------------------------------+---------------+------------+---------------+
| *0 | Distributed Union (distribution_table: users, split_ranges_aligned: true) | 20 | 1 | 443.34 msecs |
| 1 | +- Serialize Result | 20 | 1 | 443.32 msecs |
| 2 | +- Global Sort Limit | 20 | 1 | 443.31 msecs |
| *3 | +- Distributed Cross Apply | 60 | 1 | 443.26 msecs |
| 4 | +- [Input] Create Batch | | | |
| 5 | | +- Local Distributed Union | 999 | 1 | 0.7 msecs |
| 6 | | +- Compute Struct | 999 | 1 | 0.62 msecs |
| *7 | | +- Filter Scan | | | |
| 8 | | +- Table Scan (Table: follows, scan_method: Scalar) | 999 | 1 | 0.41 msecs |
| 17 | +- [Map] Local Sort Limit | 60 | 3 | 798.73 msecs |
| 18 | +- Cross Apply | 807909 | 3 | 751.36 msecs |
| 19 | +- [Input] KeyRangeAccumulator | | | |
| 20 | | +- Batch Scan (Batch: $v2, scan_method: Scalar) | | | |
| 22 | +- [Map] Local Distributed Union | 807909 | 999 | 707.34 msecs |
| *23 | +- Filter Scan | | | |
| 24 | +- Table Scan (Table: posts, scan_method: Scalar) | 807909 | 999 | 662.8 msecs |
+-----+---------------------------------------------------------------------------+---------------+------------+---------------+
Predicates(identified by ID):
0: Split Range: ($user_id_1 = '07beb0ca-6263-4cc8-9e32-61a308d476b1')
3: Split Range: ($user_id = $followee_id)
7: Seek Condition: ($user_id_1 = '07beb0ca-6263-4cc8-9e32-61a308d476b1')
23: Seek Condition: ($user_id = $batched_followee_id)
Residual Condition: (($deleted = false) AND ($posted_at <= timestamp (2023-09-16 02:41:52-07:00)))
20 rows in set (454.37 msecs)
timestamp: 2023-09-29T18:59:19.131112+09:00
cpu time: 833.31 msecs
rows scanned: 999999 rows
deleted rows scanned: 0 rows
optimizer version: 5
optimizer statistics: auto_20230927_10_45_18UTC
結果は実行計画の各ステップの、フィルタリングを行う処理などでの条件句がどのように指定されているか、クエリー全体の諸情報の順で出力されています。
このクエリーは 99999 行スキャンが行われ(rows scanned)、オプティマイザのバージョンは 2023 年 10 月初旬時点でのデフォルトである 5 が使われていることが分かります。より新しいオプティマイザのバージョン 6 は現在選択可能となっており、今後デフォルトが変更される可能性があります。オプティマイザは継続的に改良が続けられており、実行計画はオプティマイザのバージョンによって変化する場合があります。そのため、クライアント側の設定やセッション単位、データベース単位でオプティマイザのバージョンを指定することも可能です。
JSON 形式の実行計画をグラフ化したもの
JSON 形式で取得した実行計画を spannerplanviz で可視化したものが以下の通りです。
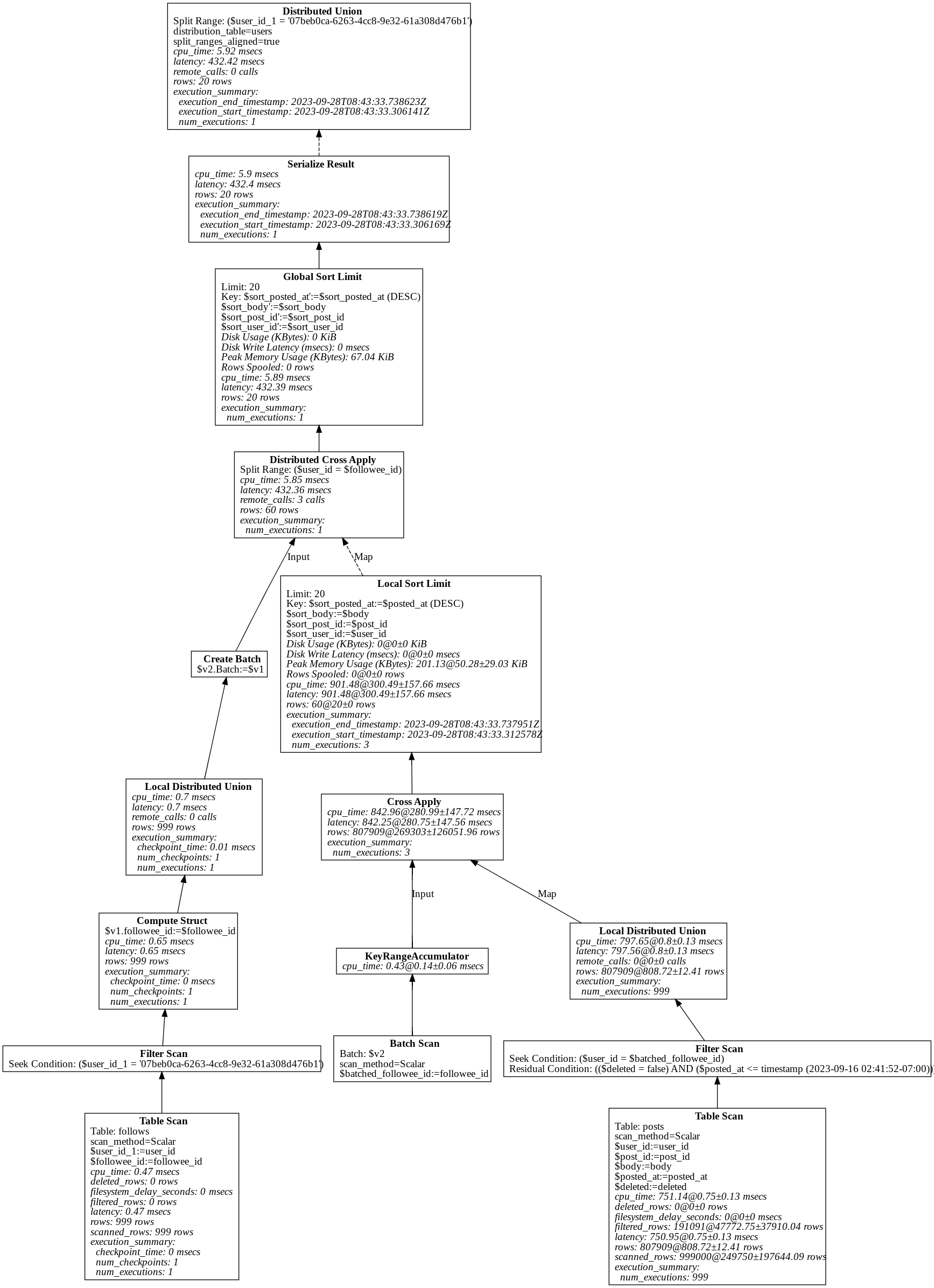
非常に細かい情報まで出力されていますが、これは最も細かい出力を有効にしているためで通常はここまで細かい情報まで見る必要は必ずしもありません。
実行計画の読み解き
実行計画は一見したところ非常に複雑に見えますが、各ステップが細かく表現されているだけで主要な処理はそれほど複雑ではありません。
実行計画は大きく分けて3つのグループから構成されるので、それぞれ A,B,C とします。
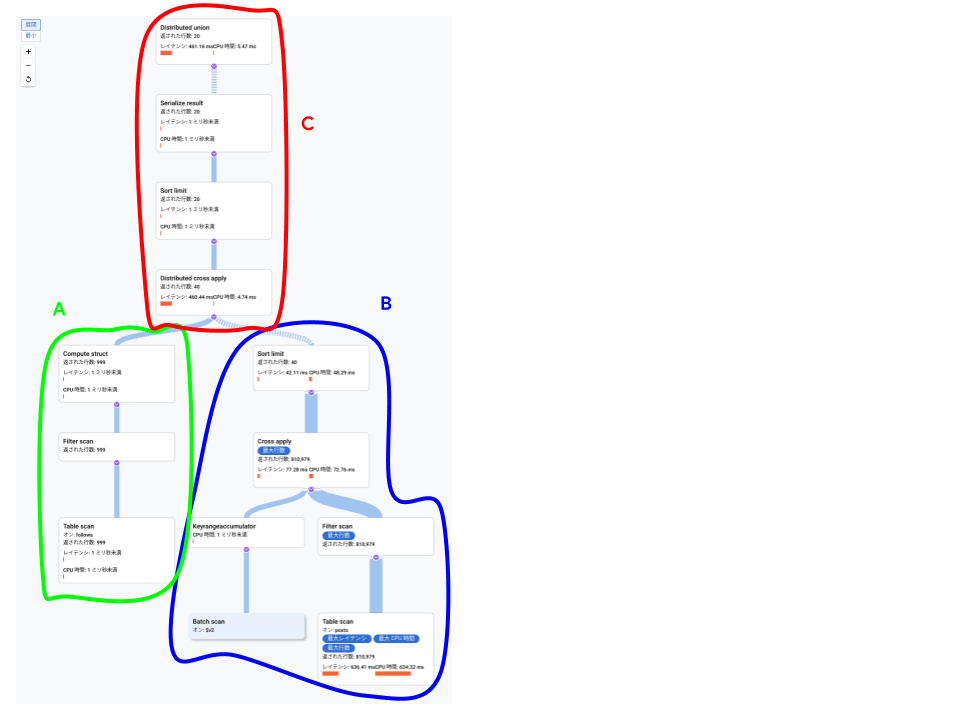
以降の説明での処理時間は spanner-cli で得られたテキスト版での結果に基づきます。
実行環境は 1000 PU (1ノード)ですが、実行に掛かった時間に関しては参考程度とご理解ください。
グループ A の処理内容
グループ A の末端では follows テーブルに対するスキャン(Table Scan と Filter Scan)を行っています。テキスト形式の実行計画での 7 と 8 の行です。指定したユーザーのフォローしているユーザー一覧を取ってくる処理です。follows テーブルは user テーブルへインターリーブされているため、スキャンする範囲は物理的に連続した領域にあります。処理時間は 1ms ほどで実行完了しており、999行返されています。
ウェブコンソール版の実行計画グラフでは省略されていますが、spannerplanviz 版では Create batch で結果を $v2 にまとめています。この結果が次のステップで使われます。
グループ B の処理内容
グループ B では先のステップで得られたユーザー ID 一覧($v2)に基づき、各ユーザーの posts を集めています。テキスト形式での実行計画では17行目から24行目がそれにあたります。個別のユーザーの posts はユーザー毎に物理的にまとまって配置されているため、Cross Apply で実行されています(Cross Apply とは MySQL などの Nested Loop Join と同様にテーブル同士を結合する処理です)。テーブルスキャンは個別のフォローしているユーザー毎に行われるため、999 回実行され条件に適合する合計 80万行ほど返されています。
また、今回のケースではグループ B の処理全体が 3 並行(concurrent)で実行されています。並行処理の実行単位ごとにソートが行われ、LIMIT の指定により日付の降順で上位 20行の結果が返されます。全体としては 60 行となっているのは 3 つの並行処理間でのマージがこの段階では行われていないためですが、処理途中で LIMIT 句に従って件数を削減出来ています。
グループ B のテーブルスキャンが全体の処理中で最も長い部分ですが、クエリーの全体のレイテンシ 468.75ms よりも長く 807.6ms ほどかかっています。全体の処理時間よりも長いのは並行実行されており、3 並行での延べ時間となっているためです。実際に何並列(parallel)でされるかはその時点でのノード数や空き状況にも依存します[1]。
グループ C の処理内容
グループ C は Distributed Cross Apply(テキスト形式での3行目)でグループ A が返したユーザーの一覧とグループ B の各ユーザーのポストを結合する処理です。グループ B での Cross Apply と違い Distributed がついているのは、グループ B とは異なり分散した処理の結果を集計する内容であるためです。今回のケースでは前段階で件数が 60 件まで削減されていたため、処理時間が全体の占める割合は大きくありませんでした。対象の件数が非常に大きい場合には、多くの時間を要する場合もあります。
その後ソートで最終的な LIMIT 句 での指定通り 20件だけを返します。ここでのソート対象は 60件からの絞り込みだったため。ソートのレイテンシも 0.1ms 未満で終わっています。
セカンダリインデックス
今まで見てきた実行計画ではセカンダリインデックスを全く使われていませんでした。スキーマの段階でインターリーブを行うなどデータの局所性を高めていたため、テーブルスキャンでもそれなりの時間で完了していました。実行時間への要求次第ではそのままでも良いかもしれませんが、セカンダリインデックスを使う方法を考えてみます。
Spanner のセカンダリインデックスはベーステーブル(セカンダリインデックスの検索対象となるテーブル)のインデックス対象カラムとベーステーブルの主キーを内容とした別のテーブルとして実装されています。今回のケースでは最終結果として posts テーブルの全カラム(posts.*)を要求するためセカンダリインデックスへのスキャンのみでは完結できず、ベーステーブルとの結合が必要となります。この処理はそれなりに高コストです。
セカンダリインデックスのみで完結するにはセカンダリインデックスに含まれるベーステーブルの主キー(posts.user_id, posts.post_id)だけを取得するように変更するか、セカンダリインデックスの STORING 句で必要なカラムをセカンダリインデックスに含めてしまう方法も考えられます。
前者の方法を試した例が以下の通りです。
spanner> EXPLAIN ANALYZE
-> SELECT
-> posts.post_id, posts.posted_at
-> FROM
-> posts
-> JOIN
-> follows
-> ON
-> posts.user_id = follows.followee_id
-> WHERE
-> follows.user_id = '07beb0ca-6263-4cc8-9e32-61a308d476b1'
-> AND posts.deleted = FALSE
-> AND posts.posted_at <= '2023-09-16 02:41:52.000'
-> ORDER BY
-> posts.posted_at DESC
-> LIMIT
-> 20;
+-----+----------------------------------------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+-----+----------------------------------------------------------------------------------------+---------------+------------+---------------+
| *0 | Distributed Union (distribution_table: users, split_ranges_aligned: true) | 20 | 1 | 677.27 msecs |
| 1 | +- Serialize Result | 20 | 1 | 677.26 msecs |
| 2 | +- Global Sort Limit | 20 | 1 | 677.25 msecs |
| *3 | +- Distributed Cross Apply | 60 | 1 | 677.23 msecs |
| 4 | +- [Input] Create Batch | | | |
| 5 | | +- Local Distributed Union | 999 | 1 | 0.75 msecs |
| 6 | | +- Compute Struct | 999 | 1 | 0.69 msecs |
| *7 | | +- Filter Scan | | | |
| 8 | | +- Table Scan (Table: follows, scan_method: Scalar) | 999 | 1 | 0.48 msecs |
| 17 | +- [Map] Local Sort Limit | 60 | 3 | 1.37 secs |
| 18 | +- Cross Apply | 807909 | 3 | 1.32 secs |
| 19 | +- [Input] Batch Scan (Batch: $v2, scan_method: Scalar) | 999 | 3 | 0.88 msecs |
| 21 | +- [Map] Local Distributed Union | 807909 | 999 | 1.27 secs |
| *22 | +- Filter Scan (seekable_key_size: 3) | 807909 | 999 | 1.23 secs |
| 23 | +- Index Scan (Index: idx_user_id_posted_at, scan_method: Scalar) | 807909 | 999 | 1.13 secs |
+-----+----------------------------------------------------------------------------------------+---------------+------------+---------------+
Predicates(identified by ID):
0: Split Range: ($user_id_1 = '07beb0ca-6263-4cc8-9e32-61a308d476b1')
3: Split Range: (($deleted = false) AND ($user_id = $followee_id) AND ($posted_at <= timestamp (2023-09-16 02:41:52-07:00)))
7: Seek Condition: ($user_id_1 = '07beb0ca-6263-4cc8-9e32-61a308d476b1')
22: Seek Condition: (($user_id = $batched_followee_id) AND ($deleted = false)) AND ($posted_at <= timestamp (2023-09-16 02:41:52-07:00))
20 rows in set (686.86 msecs)
timestamp: 2023-09-29T19:00:57.297412+09:00
cpu time: 868.37 msecs
rows scanned: 808908 rows
deleted rows scanned: 0 rows
optimizer version: 5
optimizer statistics: auto_20230927_10_45_18UTC
23行目がテーブルスキャンではなくインデックススキャン(Index Scan)になっているのが分かります。しかしながら、実行時間自体は速くはなりませんでした。テーブルスキャンからインデックススキャンになったことで、クエリー全体でのスキャン行数が減っている(999999 行から808908 行へ)ことからスキャンの途中打ち切りが可能となった事が分かりますが、打ち切りまでにスキャンした行数が多くテーブルスキャン比較して処理時間は短縮できなかったようです。より選択度が高いインデックスや早期に打ち切りが出来る条件句であればインデックススキャンの方が高速に処理できる可能性はあります。
まとめ
Spanner での実行計画の取得とその内容についてサンプルをベースに解説いたしました。JOIN が処理される様子などの基本的なコンセプトについては共通しているところが見て取れると思います。一方で、実行計画の一部に分散データベース特有の並列処理なども出現することがあります。
実行計画まで深掘りするときにはクエリーのパフォーマンスの改善のためであることが多いと思います。その場合、時間が掛かっているステップや多くの行数を返しているステップに着目して効率化していくという流れは RDBMS でのノウハウが流用可能でしょう。
よき Spanner ライフを
参考資料
- https://engineering.mercari.com/blog/entry/20201210-cloud-spanner-query-plan/
- https://cloud.google.com/spanner/docs/tune-query-with-visualizer?hl=ja
- https://engineering.dena.com/blog/2020/07/spanner-secondary-index/
- https://spanner-hacks.apstn.dev/operators/

Discussion