この記事は Google Cloud Japan Advent Calendar 2025
の2日目の記事です。
こんにちは。Google CloudのTechnical Solutions Engineerのカケルです。
Google Cloud の技術サポートのチームでは、お客様のお問合せをもとに Google Kubernetes Engine(GKE) をはじめとする多様な Kubernetes 環境で発生した障害の原因調査をお手伝いすることがあります。
はじめに
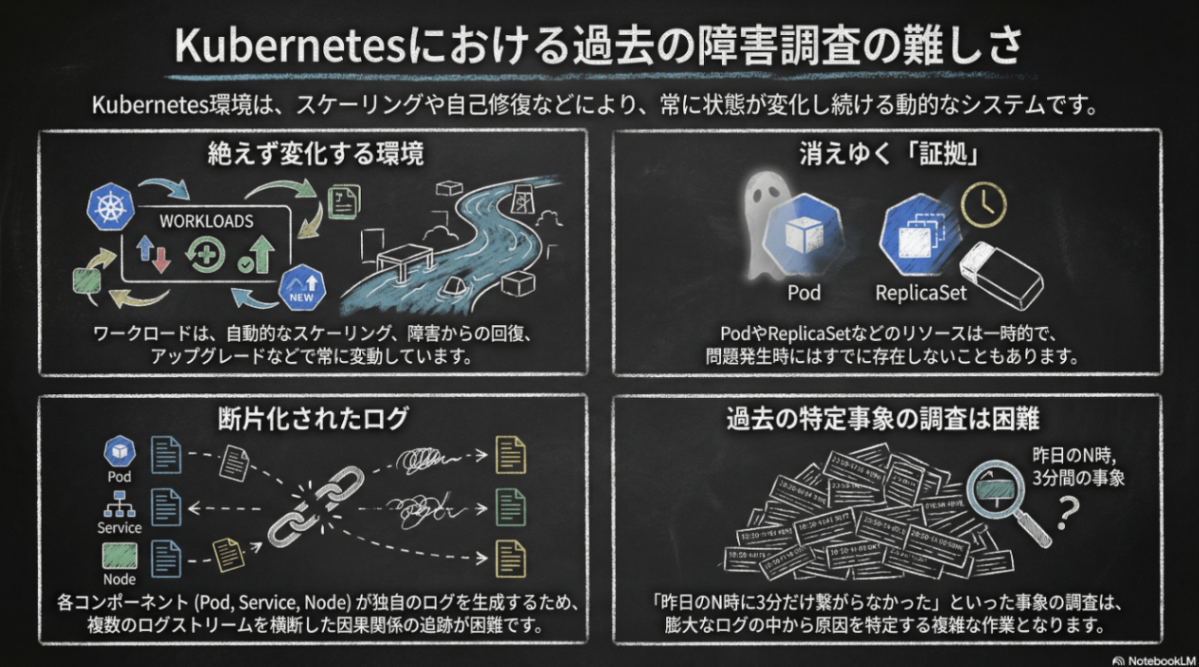
Kubernetes における障害原因調査(Root Cause Analysis,RCA)の難しさ
Kubernetes 環境はお客様の利用方法に応じてスケールや稼働しているワークロードが大きく異なります。また、「動的なスケーリング」、「障害に対する自動的な回復」、「アップグレード」など様々な理由で稼働しているワークロードが常に変化していくものです。
この結果として障害の調査時には問題はすでに解消していることも多く、Kubernetes 上の何らかの自動的なオペレーションに伴って短期間に発生する問題の調査が必要になることも少なくありません。
(例:「スケールインした瞬間にPodとの接続性の問題が生じる」、「Pod Disruption Budgetが設定されているはずなのにワーカーノードのアップグレード操作中にダウンタイムが生じる」など)。
また、Kubernetes では多数のコンポーネントが自立分散的に稼働しており、それぞれがログを出力しています。トラブルシューティングのためにはそれぞれのログの流れを追わなければならず、ログのタイミングを見て複数のログを突合したり、時にはコンテナIDやリソースのUIDといったリソース固有の情報で再検索しリソースに関連するログを見る必要があります。
Kubernetes History Inspector(KHI) の紹介
このような障害原因調査が難しくなりやすい Kubernetes 上で、私たち Google Cloud の技術サポートでは、「昨日の N時に XX名前空間のService Yに3分だけ繋がらなかった原因が知りたい」などのご質問を受けてから初めて、お客様の環境を知り、ログなどを見て原因の調査をお手伝いします。
Kubernetes の知識はあっても環境ごとに大きく状況が違う中で、ログやメトリクスなどのテレメトリだけから何が起きてどの様な問題が生じたか、過去のクラスタの振る舞いを分析することは多くの時間を要していました。
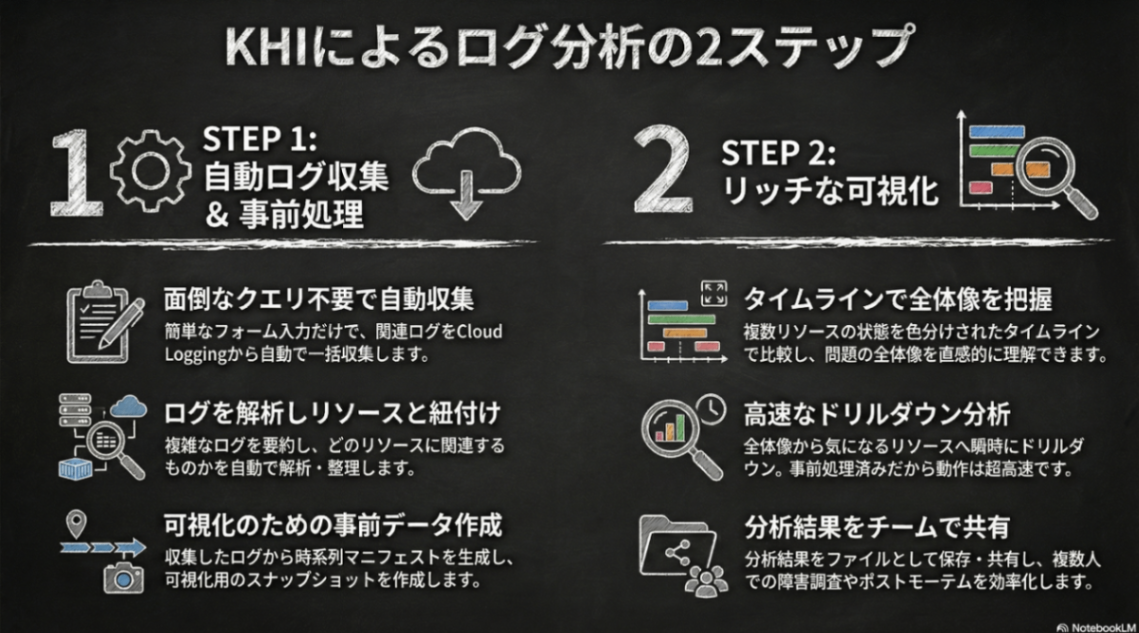
今年2月にGoogle CloudのGitHubのレポジトリで公開した、Kubernetes History Inspector(KHI) はこうした Kubernetes 上の RCA をより複雑な問題に対しても迅速に提供できる様に開発された 「Kubernetesの障害原因調査のためのログビューア」 です。
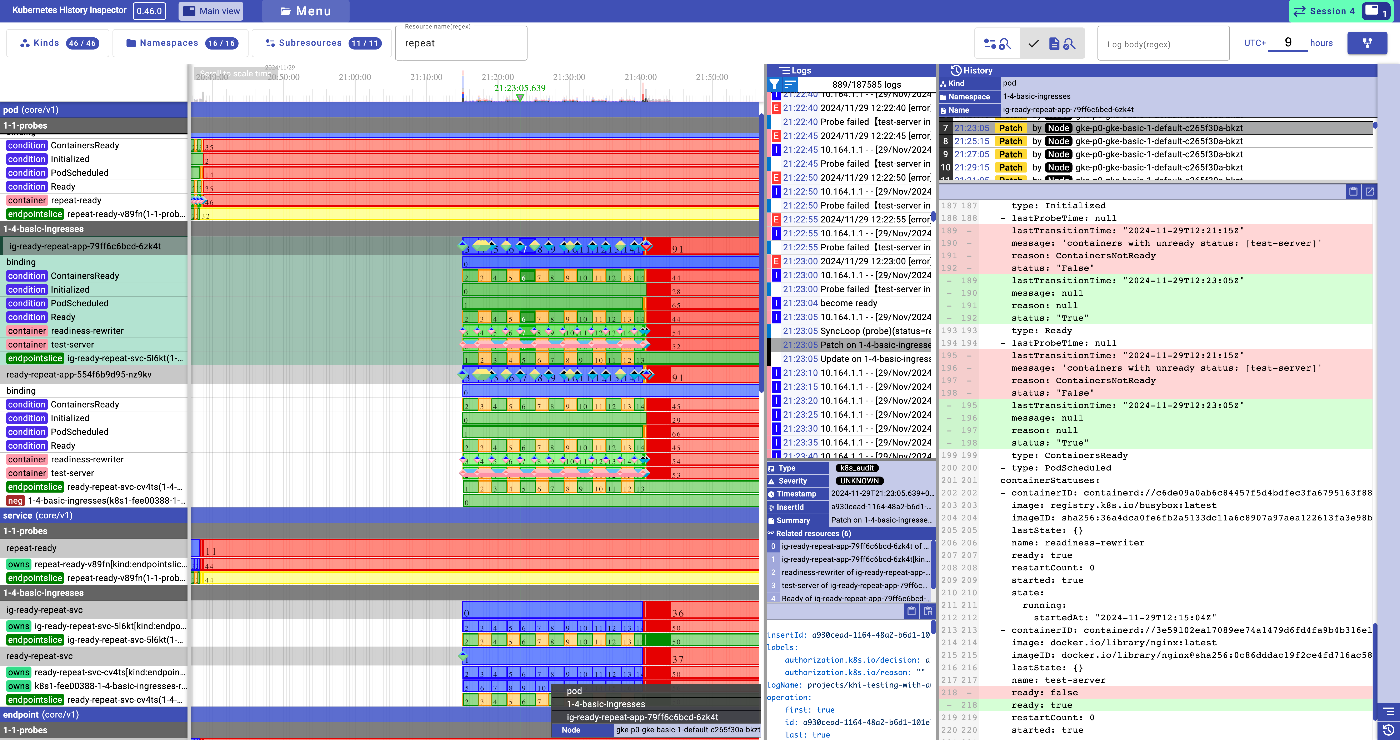
タイムライン画面: クラスタ上の各リソースの状態をログから復元しタイムラインとして表示している画面。変更されたタイミングをクリックするとそのタイミングのマニフェストがわかる
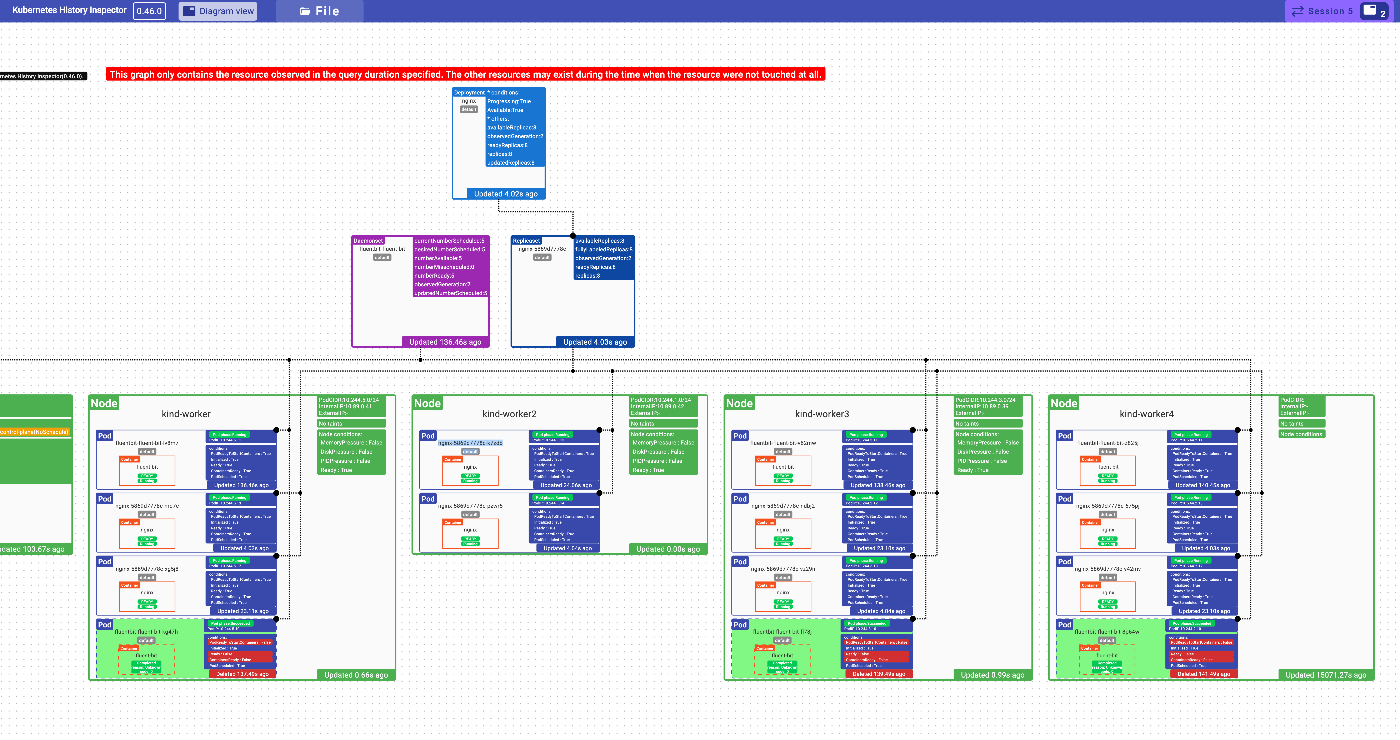
リソーストポロジ画面: 特定のタイミングのリソースの配置をログだけから復元しダイアグラムとして表示する画面
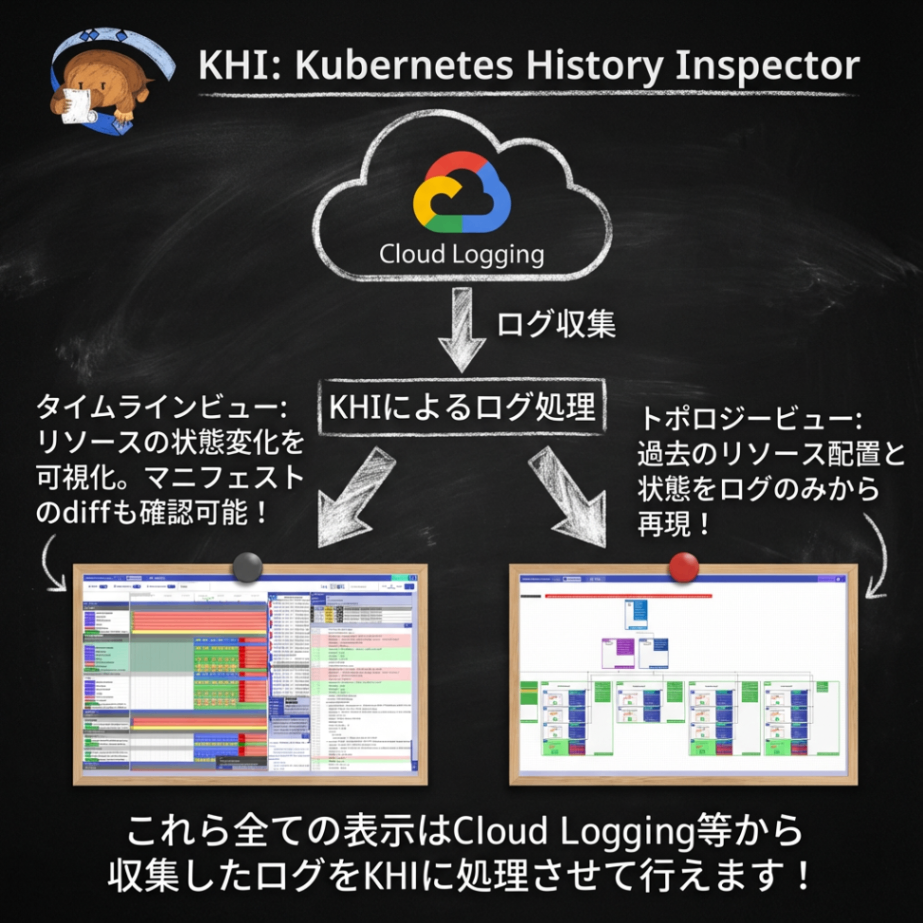
KHI は Cloud Logging上のログをごっそり持ってきてこれら迅速な障害調査のための可視化を提供する
KHI は元々、私自身のログ分析作業の効率化のために3年ほど前から作っていた、単なる個人的な業務改善ツールだったものですが、現在までに数千を超えるサポートケースで実際に活用されてきており、Google での様々な Kubernetes 上の障害調査に活用されてきたものを、ユーザの皆様自身のトラブルシューティングでも使える様に公開したものです。
ちなみになんと、主に日本のGoogle Cloudのサポートチームでメンテしているので日本語ドキュメントがあります
今日は Kubernetes History Inspector の提供する機能と、このツールが再定義する Kubernetes 上のログの歩き方、簡単な障害調査の実例を紹介します。
KHI の動かし方
今までの説明を聞くと、クラスタ上に何かインストールする必要がありそうに感じますが、KHIはあくまで「ログビューア」です。既存の GKE/GDC などがデフォルトで書き出すログを活用しているため、何らかのエージェントをクラスタ上にインストールする必要はありません。
ユーザのローカルの開発環境やCloud Shellでログを見たい時に起動し、Cloud Loggingから様々なログをかき集め、障害原因調査のためにわかりやすい可視化を提供します。
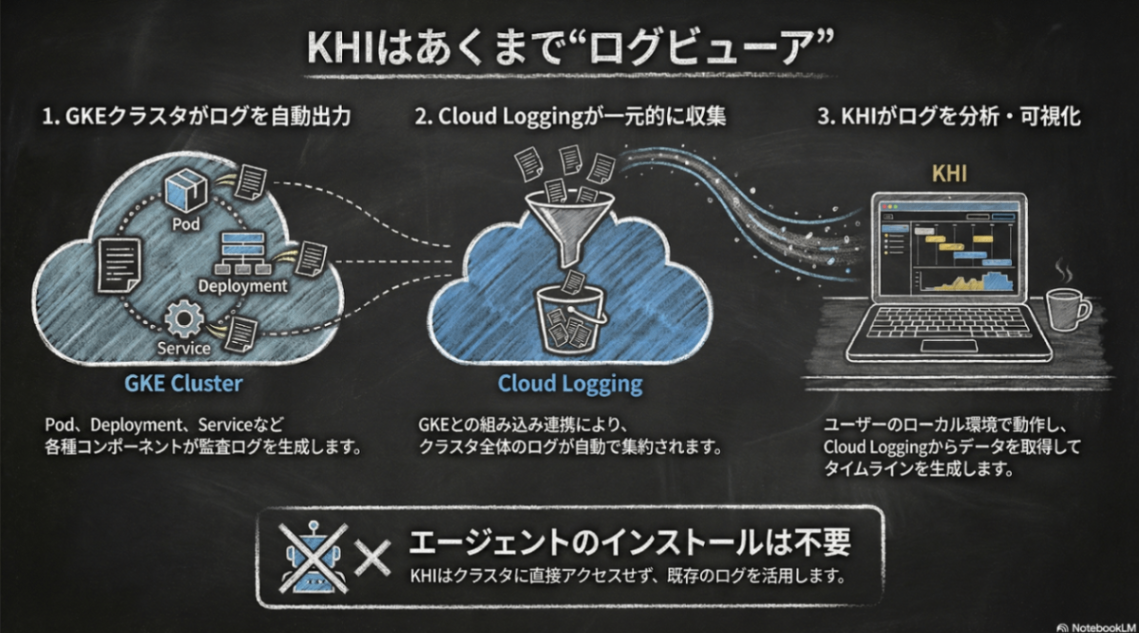
何はともあれ、まずKHIを起動してみましょう。
レポジトリの README に記載されている通り、 Cloud Shell 上であれば以下のコマンド一つで動作し、8080番ポートでKHIのWebサーバが起動するので、Cloud Shell上のWebでプレビューボタンからアクセスができます。
$ docker run -p 127.0.0.1:8080:8080 gcr.io/kubernetes-history-inspector/release:latest
KHI を Cloud Shell以外の環境で動かすには?
KHI はローカル環境でも動作させることができます。
Linux, Mac あるいは WSL の環境では、docker, gcloudコマンドが入っていれば
gcloud auth application-default login
docker run \
-p 127.0.0.1:8080:8080 \
-v ~/.config/gcloud/application_default_credentials.json:/root/.config/gcloud/application_default_credentials.json:ro \
gcr.io/kubernetes-history-inspector/release:latest
で起動可能です。
また、最近のバージョンからシングルバイナリで実行できる形としての配布も試験的に開始しています。
リリースページから対応するバイナリをダウンロードすれば、上記dockerコマンドのようにポートの設定や認証ファイルのマウントの設定が必要なく、単にダウンロードしたバイナリファイルを起動すれば実行できます。詳細なオプション等は --helpをつけて起動して確認してください。
KHI が再定義する Kubernetesのログの歩き方
KHI でログをかき集める
KHI は、検索クエリを用いたストリーミングを前提とするCloud Loggingのようなログビューアとは異なり、特定のタイミングを指定して、その間のクラスタのログを可能な限りまとめて収集し可視化することを前提とする ログビューアです。
通常のログビューアでは、現実的にログを分析できる量に絞るためには、時間だけではなくリソースを限定する必要があり、複数のリソースからのログが混ざっている状態では解釈が難しくなり、混乱を招いてしまいます。しかし、Kubernetes 上の障害が発生したタイミングで、原因となるリソースが特定できている状況はどれほど多いでしょうか?
KHI は時間を指定することで、全体のログをできる限り取得し、Kubernetes のリソース構造に沿った形で可視化します。したがって、数日のような長いスパンのログを見るのではなく、数十分から数時間程度に時間を絞ってログを詳細に観察することに特化しています
ログの集め方も簡単で、まずは起動したらNew inspectionボタンからクラスタのタイプを選び、必要なログのタイプを選ぶと、入力する必要のあるフォームが生成されるのでこれを埋めるだけです。
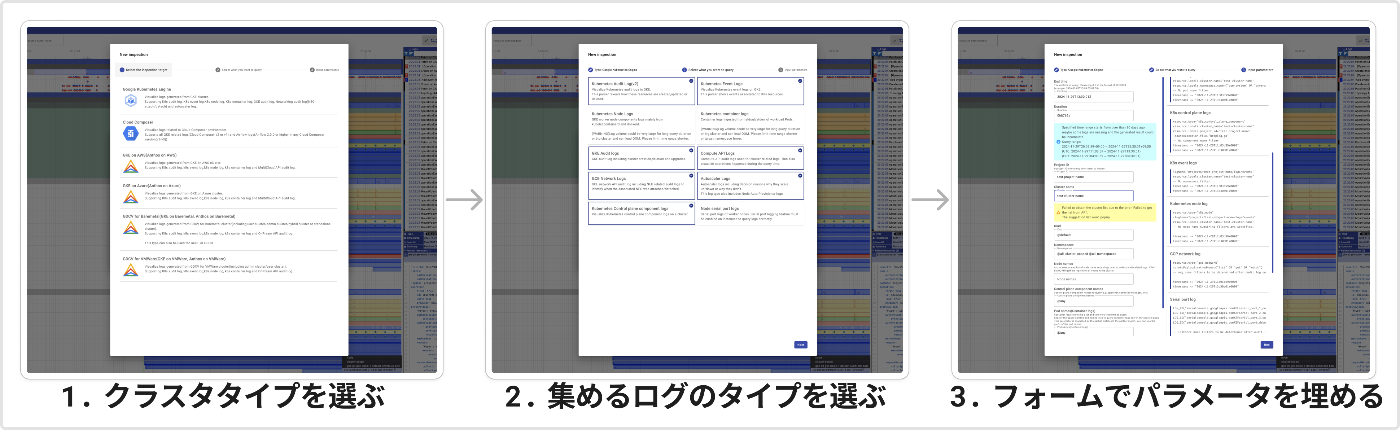
入力フォームを埋めて、Runボタンを押すと KHI が自動でログを集めてくれます。
指定した Duration パラメータとクラスタサイズにもよりますが、多くの処理をするので数秒から数分の時間でログが可視化できる状態になります。
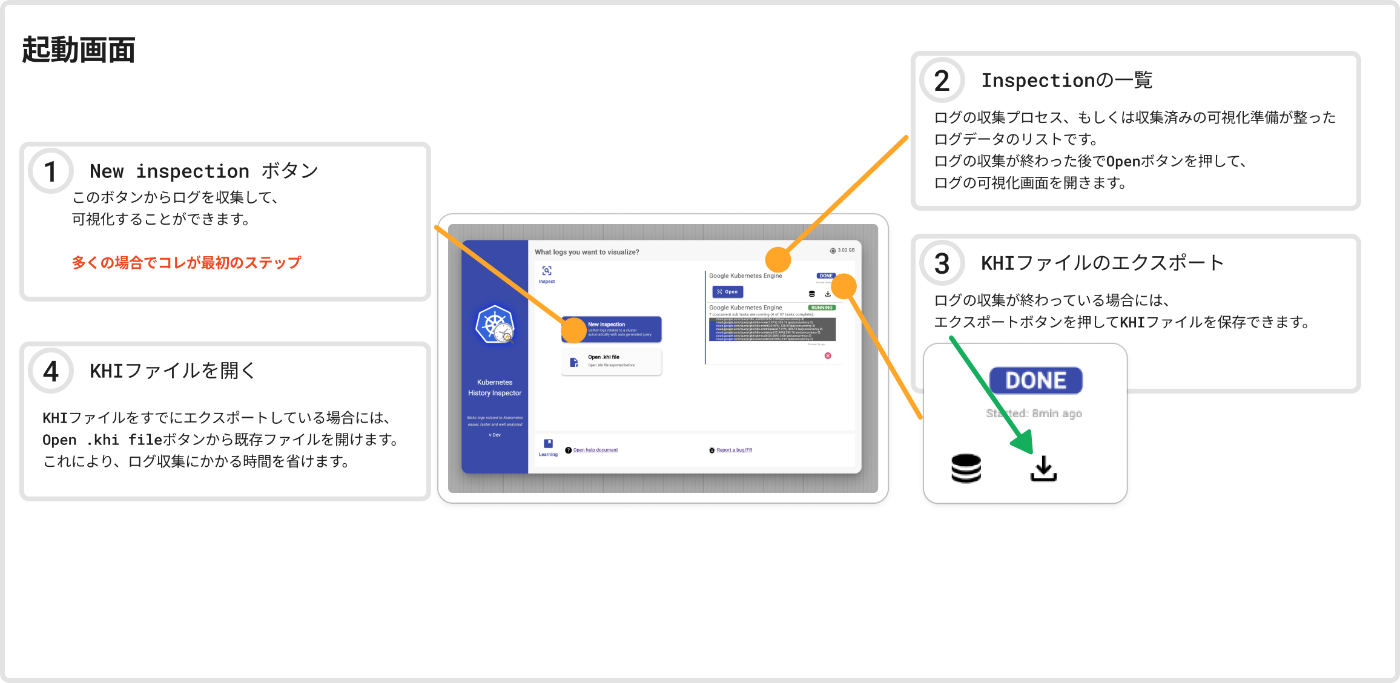
完了後に Openボタンを押せばクラスタのログを可視化した結果が確認可能です。
ちなみに一度処理したログデータはダウンロードすることもでき、チーム内での情報共有や、ポストモーテムをまとめる際のスナップショットとしても有用です。
KHI の可視化を理解する
Open ボタンを押すとカラフルな画面に圧倒されてしまうかもしれません。まず最初に画面の大まかな配置を理解する必要があります。
画面の左側はタイムラインになっていて、マクロにクラスタのリソースの状態を見るための画面です。
画面の右側は選択したタイムラインのリソース関連のログとそのリソースのdiffを見るための画面です。
基本的にはタイムライン画面を見て問題のありそうなリソースや疑うリソースを見つけていき、対象のリソースをクリックしてそのリソース関連の情報だけドリルダウンして見ていく様なフローになります。

タイムラインはリソースごとに階層的に表示されています。一番上に Pod, ReplicaSetのようなkindのレイヤがあり、名前空間のレイヤ、リソース名のレイヤのように並んでいます。
時間をスケールしたい時は、タイムライン上でSHIFTを押しながらスクロールすることでスケールできるということもこの画面で押さえておいてください。

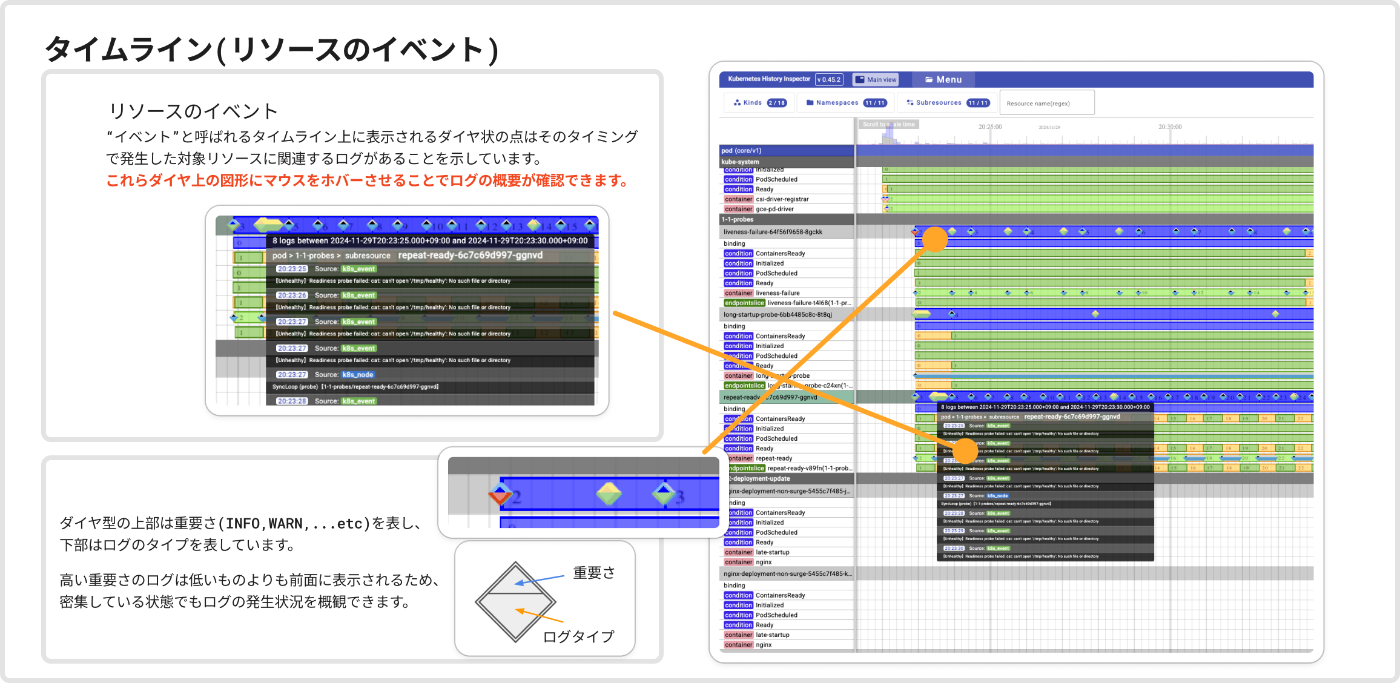
タイムラインには2種類の要素が表示されています。
-
リビジョン: タイムラインとして表示されているカラフルな長方形。リソースの継続する状態を表していて、左端で状態が始まり、右端で次の状態になったことを示している。 -
イベント: タイムライン上に表示されている2色に分かれている菱形のドット。 リソースに紐づくが状態ではないログ。例えばコンテナのログなど。
リビジョンの状態は多数の種類があり、今後も機能の拡充に合わせて増えていきます。マウスカーソルをリビジョンにホバーするとStatusにどういう状態であるのか表示されるのでこちらを確認すると色ごとの意味がわかる様になります。
例えば青色は対象のリソースが存在していること、赤色はリソースがすでに削除されていることを示しています。(赤はエラーっぽいですが、あくまでリソースが存在しないというだけです)

イベントは継続的な状態として表すことができないログを表します。上下が色の違う菱形の図形で表されますが、上が重要さ(Severity: (Info, Warningなど))を表しています。
下はログの出所です。例えば一口にPodに紐づくログと言っても、「Kubernetesの監査ログ」、「コンテナのログ」、「kubeletのログ」などなど多数存在します。こちらもカーソルを合わせればログのタイプが表示され色の意味がわかるかと思います。
さらにタイムライン上のそれぞれの要素はマウスカーソルで選択ができます。タイムラインで選択したリソースに関連するログとマニフェストのdiffのログが右側に絞られて表示されるようになるので、タイムライン画面を見て問題のありそうなリソースや疑うリソースを見つけていき、対象のリソースをクリックしてそのリソース関連の情報だけドリルダウンして見るのが基本的なKHIの使い方です。

以上が簡単なKHIの使い方です。ログを複数回クエリして関連するログを見ていく様なフローとかなり違ったフローになることが見て取れるのではないかと思います。
この使い方の説明は今回必要最低限しか説明しなかったので、より詳細が気になる方はこちらを確認してください。
KHI で始める障害原因調査
ここでは仮のシナリオとして、「あるDeploymentを更新すると数分間ServiceのCluster IPに繋がらなくなる」というシナリオがあるとします。
このアプリケーションは Readyになるまで数分時間がかかるのですが、.spec.strategy.rollingUpdateの設定はmaxUnavailable: 0です。ダウンタイムは起きないはずなのですが、確かに更新するとServiceに繋がらなくなってしまうとします。
apiVersion: apps/v1
kind: Deployment
metadata:
name: flaky-deployment
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: flaky
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
labels:
app: flaky
spec:
containers:
image: gcr.io/test-project/sample-app
imagePullPolicy: Always
name: main
ports:
- containerPort: 8080
protocol: TCP
readinessProbe:
httpGet:
path: /
failureThreshold: 1
periodSeconds: 3
successThreshold: 1
timeoutSeconds: 1
その時 Service は繋がる状態だったか? → EndpointSlices をみよう
これが現在起きているならどう確認したら良いでしょうか?
Pod の Ready 状態自体は、Pod自身を kubectl describe pods <pod名>をしたら見れますが、Serviceに紐づいているPod全て見たいとなると少し大変です。
Service が作成されると、EndpointSlicesというリソースが作られます。このリソースは Service のラベルにマッチするPodそれぞれのReady状態を含んでいます。
kubectl describe endpointslices flaky-service-d4hs9
Name: flaky-service-d4hs9
Namespace: default
Labels: endpointslice.kubernetes.io/managed-by=endpointslice-controller.k8s.io
kubernetes.io/service-name=flaky-service
Annotations: endpoints.kubernetes.io/last-change-trigger-time: 2025-12-01T06:30:13Z
AddressType: IPv4
Ports:
Name Port Protocol
---- ---- --------
<unset> 8080 TCP
Endpoints:
- Addresses: 10.56.0.21
Conditions:
Ready: true # <- ここにReady状態が入る
Hostname: <unset>
TargetRef: Pod/flaky-deployment-55866c788-cccxf
NodeName: gke-ca-cluster-default-pool-0b09ccfe-azz7
Zone: asia-northeast1-c
Events: <none>
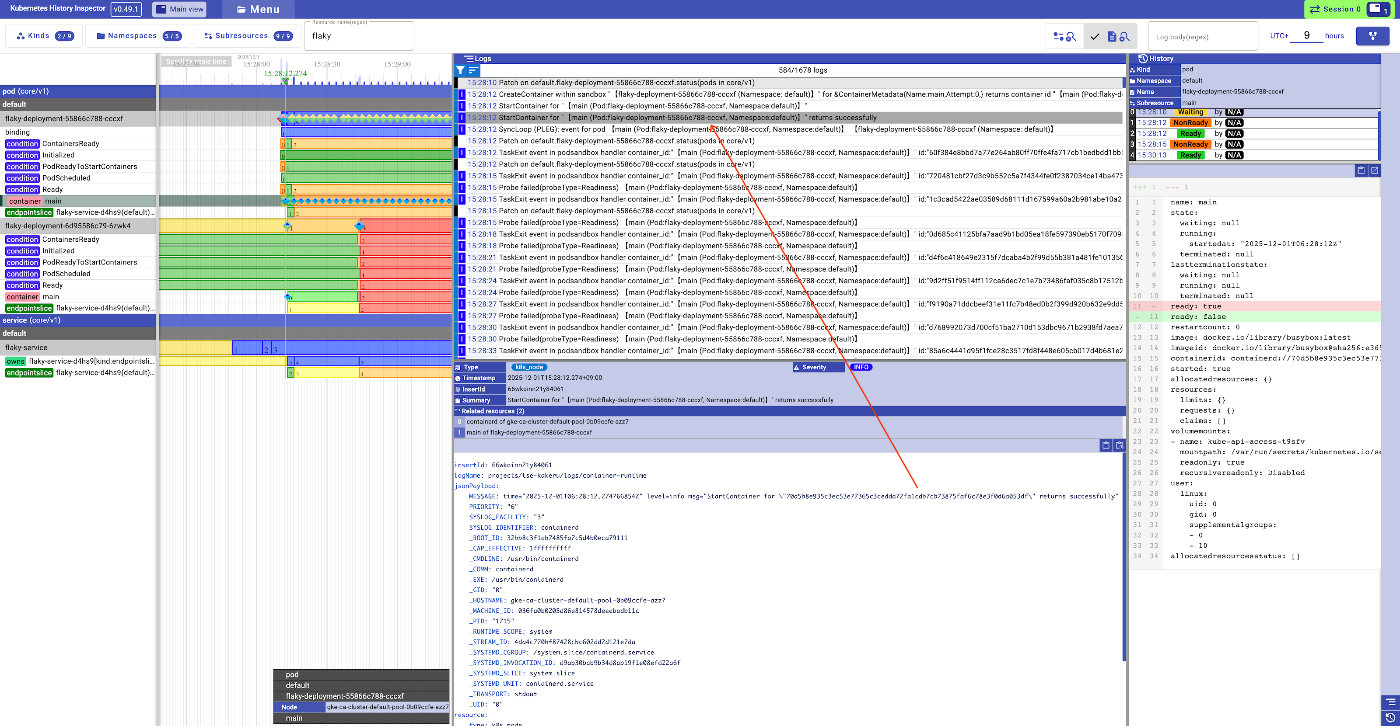
この EndpointSlices を KHI で見ると以下の様になります。
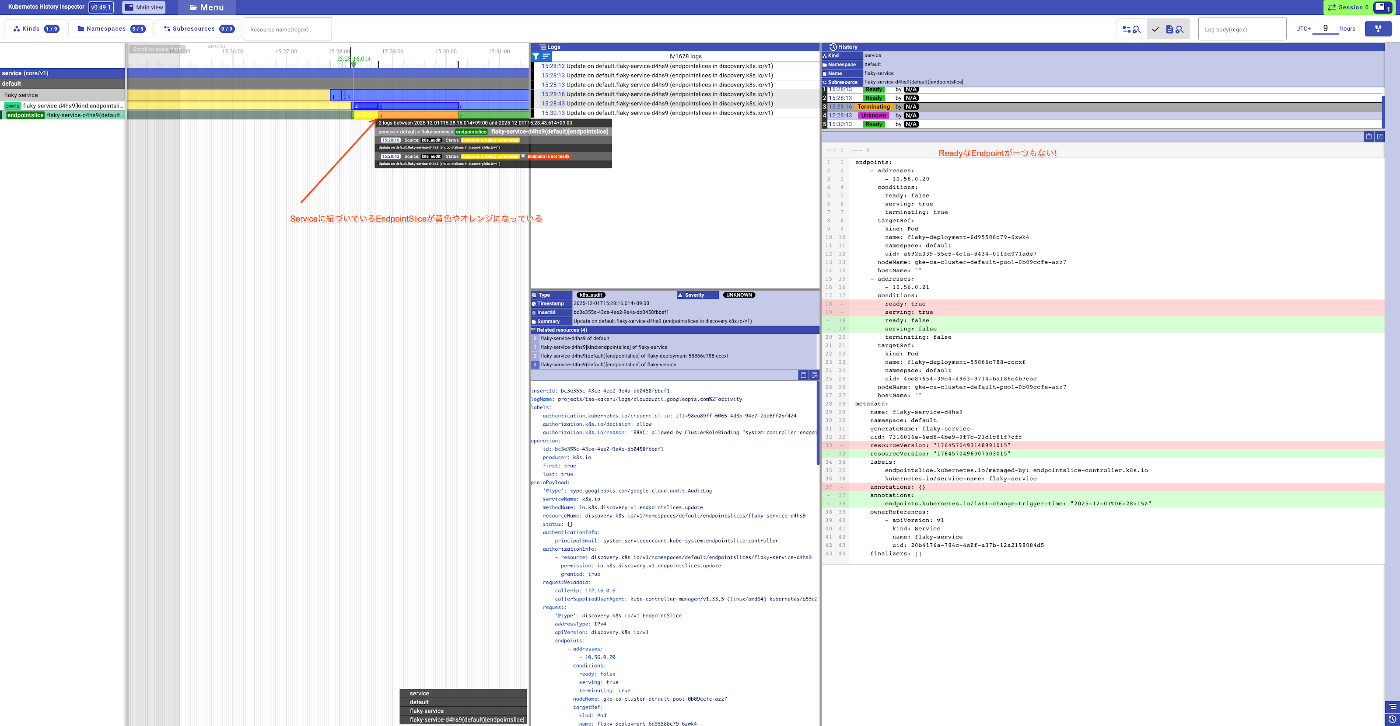
カーソルを合わせて拡大すると、この様にあるタイミングでReadyの状態から終了処理中であるという表示になっています。

その時 Pod はいつまで生きていた?
黄色くなったタイミングで終了処理中で、Readyなエンドポイントが一つもないことがわかりました。
では、対応するPodのタイムラインも見るとこの様な形になります。
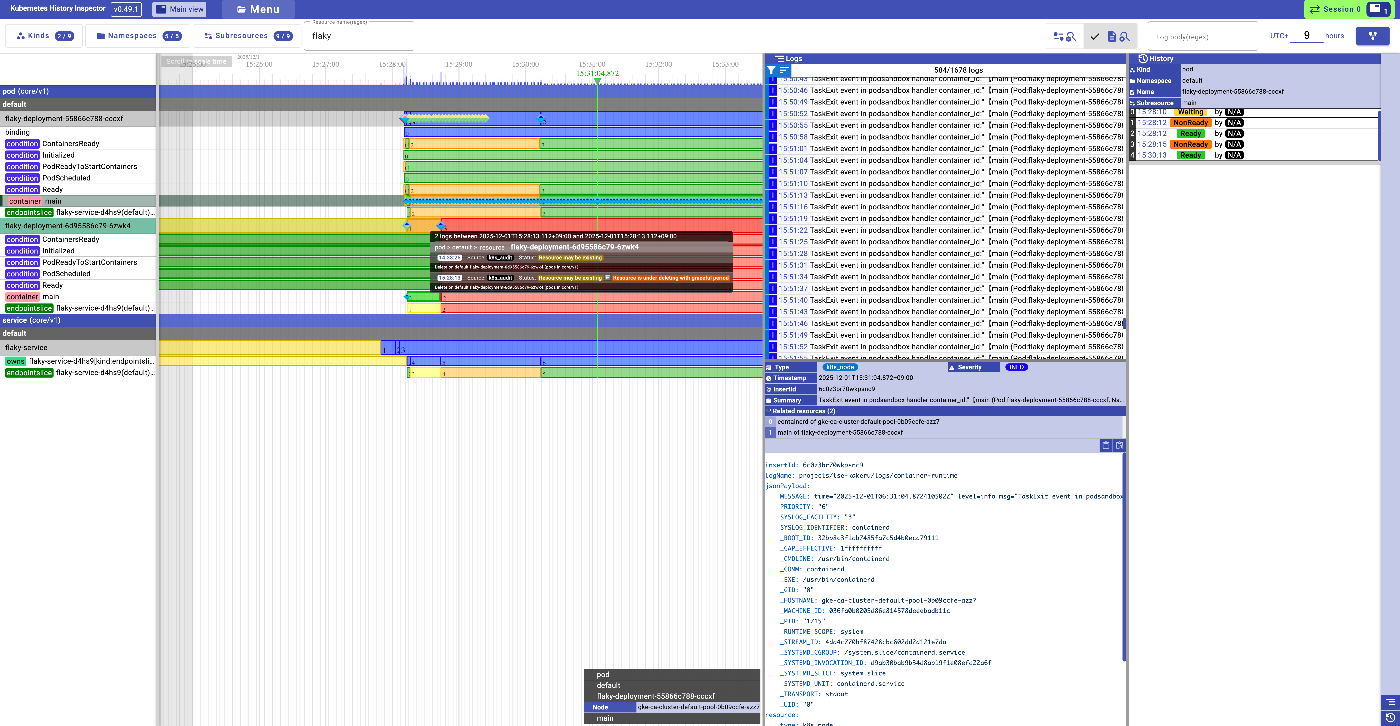

赤い部分はリソースがもう存在しないタイミングを表しており、オレンジ色のところは終了処理中であるタイミングを表しています。なお、黄色い部分は対象の区間の詳細を表示するログがクエリした区間に含まれていないものの、何かあったはずであることを示しています。
いずれにしてもエンドポイントが黄色くなっていたタイミングで、一つのPodが消されていたことがこれでわかります。ちなみにそのタイミングで出ている緑と青の菱形にカーソルを合わせるとそれぞれ別のソースからそのPodを消そうとしていることが見て取れます。
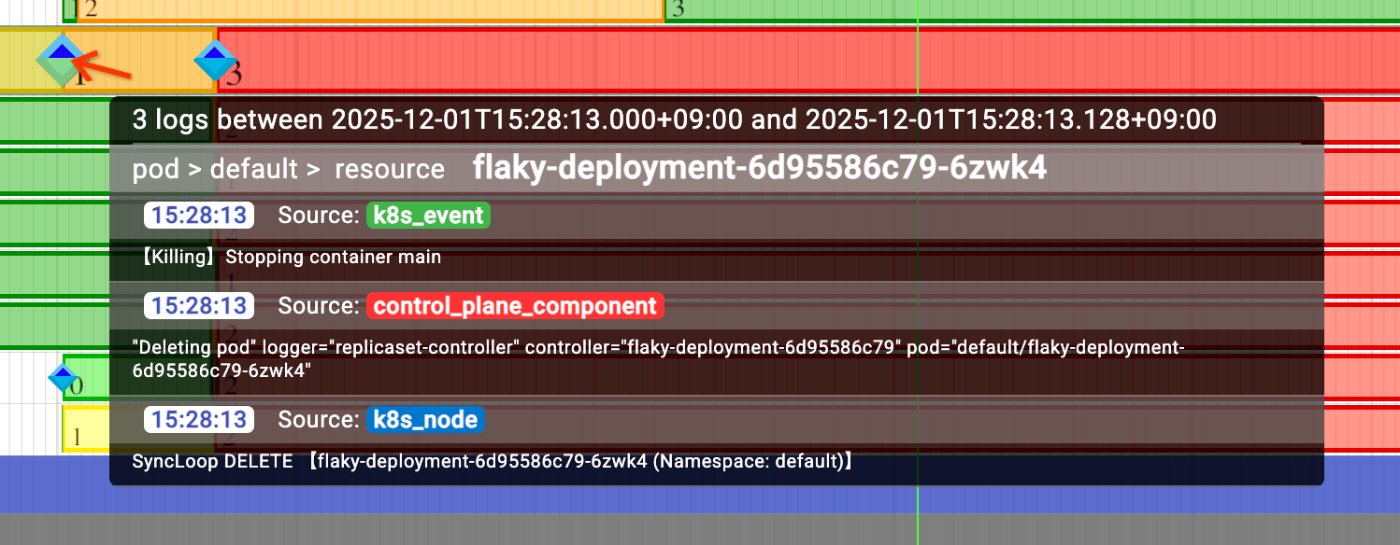
- 緑のログ(Kubernetesイベント):
Killingの Kubernetes イベント - 赤のログ(コントロールプレーンログ): コントロールプレーンの
replicaset-controllerが対象のPodを消そうとしたログ - 青のログ(Kubernetesノードログ): ノード上で稼働する
kubeletがPodの DELETE を受信したタイミングのログ
これらのログは別々の種類のログですから、本来簡単なクエリで一発で集めることは難しいログです。
しかし、KHI はログ中のPod名やコンテナIDなどを認識して対応するリソースに紐づけてくれます。
containerdのコンテナIDも紐づける!
限られた層にしかウケないであろう超便利機能として、実は KHI は containerdのコンテナIDを認識します。
こんなランダムな文字列が来てもどのPodのどのコンテナかわからないので、ログのサマリー画面では自動的にPod名やコンテナ名に置き換えてくれます。
元々
time="2025-12-01T06:28:12.274766854Z" level=info msg="StartContainer for \"70d5b8e935c3ec53e77365c3cedda72fa1cdb7cb73875faf6c78e3f0d6a053df\" returns successfully"
変換後のサマリー
StartContainer for "【main (Pod:flaky-deployment-55866c788-cccxf, Namespace:default)】" returns successfully
Pod内のコンテナの状態は .status.containerStatusesをみよう
今起きている問題に対して、コンテナの終了コードや、コンテナそれぞれのReadinessの状態を見たいのであれば.status.containerStatusesを見ればわかります。
KHI は自動的に containerStatusesが変わるタイミングの監査ログや、その中に含まれるタイムスタンプから可能な範囲でコンテナがどのタイミングでReadyであったか表示できます。
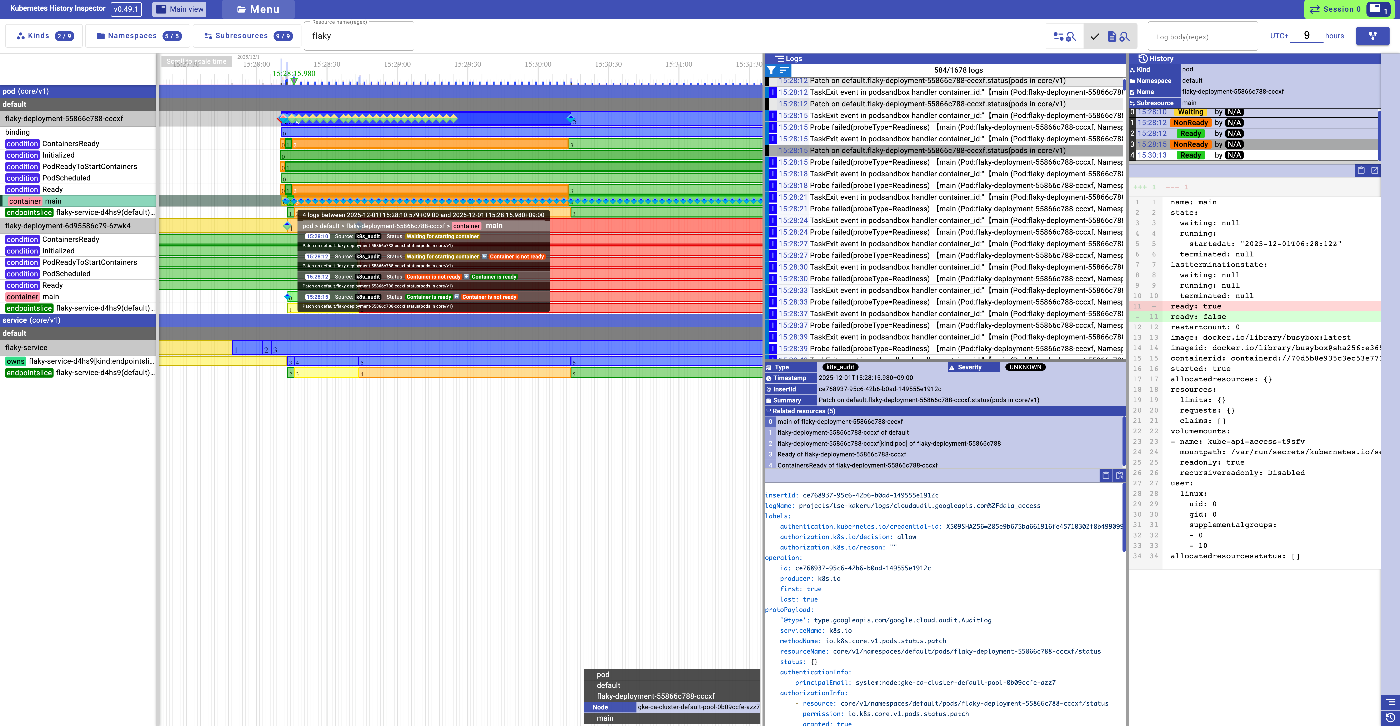
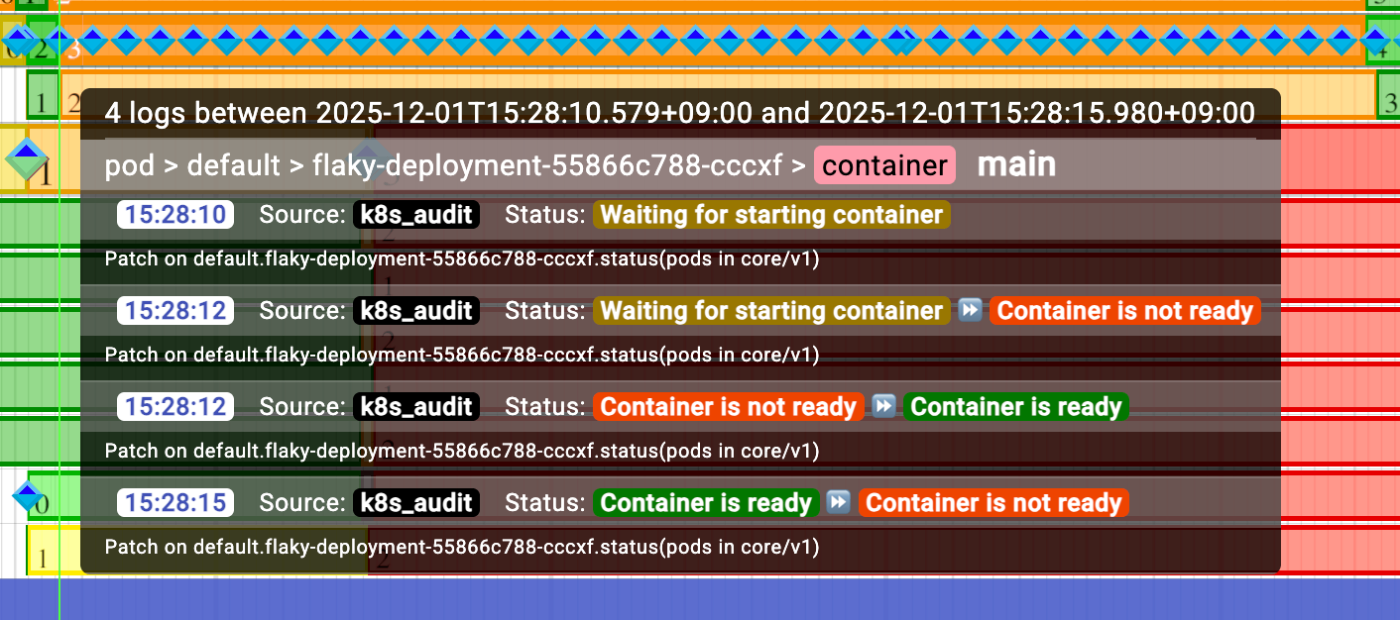
他のログが重なっていてみにくいですが、黄色い部分がイメージのPullなどコンテナが稼働する前で、オレンジの区間がReadyではないタイミング、緑のタイミングがReadyであったタイミングです。
おやおや、ずっと起動から数分間ずっとNot Readyと思いきや、一瞬だけReadyになってからNot Readyになってしまっているようですね。これなら、DeploymentもこのPodがReadyになったと思って古いPodを消してしまうのも納得がいきます。
この例では、PodのReadinessProbeに応答するプログラムが初期化の最中なのにReadyを返してしまうことがあるというシナリオでした。
今回は簡単な例を用いてましたが実際にはもっと複雑になりえます。
たとえば、
- 更新のタイミングではなく、自動的なスケールアウトの時に発生している
- 他のリソースの更新のタイミングと重なった場合のみ起きる
などなど、実際には難しいシチュエーションが現実世界にはたくさんあると思います。これを多数のログフィルタを作ってトラブルシューティングするのがどれだけ大変か考えてみてください。KHI はこうしたトラブルシューティングをより一歩現実的なものにします。
使って!
もし KHI が便利そうだと思ったらぜひ使ってみてください。 GitHub上でのStarもいただけると励みになります。

Discussion