本記事は Google Cloud Japan Advent Calendar 2025 3 日目の記事です。
Google Cloud Japan の RyuSA です。本記事は Cloud Native Days Winter 2025 の私の登壇 おうちKubernetes障害レポ をまとめた内容です。
さて、みなさんのご家庭にも Kubernetes クラスタのひとつやふたつ、ありますよね?我が家でも合計 4 台の Node で構成されている、よくある構成のクラスタが元気に稼働しています。

クラウドのようなマネージドな環境と異なり、自宅サーバーは停電や、掃除中にうっかり電源コードを抜いてしまうなど、物理的な電源断のリスクと常に隣り合わせです。
先日、まさにそんな不意の電源断により、ワーカーノードの 1 台が強制的にシャットダウンしてしまう事態に見舞われました。今回はこの「物理的な Node の停止」によって、Kubernetes の中で何が起きるのか、特にコントロールプレーンから見た挙動を追いかけてみたいと思います。
(机上) Node が強制シャットダウンされると……?
Kubernetes は、ご存知の通り自己回復可能なシステムです。Node が突然停止しても、そこで稼働していた Pod を別の正常な Node で自動的に再作成してくれます。その裏側では、以下のような仕組みが動いています。
- ハートビート停止: 各 Node で動作する kubelet は、コントロールプレーンに対してハートビートとして
NodeLeaseリソースを定期的に更新します。シャットダウンなどが原因で Node が機能しなくなるとこの更新が途絶えます。 - 異常の検知: コントロールプレーンは、NodeLease が一定期間更新されない場合、Node を UnReachable として切り離し始めます。そして、その Node のステータスを NotReady へと変更します。こうなると、この Node には Taint が設定され、新しい Pod がスケジューリングされなくなります。
- デフォルトではこの期間は 50 秒と設定されており、kube-controller-manager の
node-monitor-grace-periodオプションで上書きできます。 - https://kubernetes.io/docs/reference/command-line-tools-reference/kube-controller-manager/
- デフォルトではこの期間は 50 秒と設定されており、kube-controller-manager の
- 退避勧告: NotReady になった Node 上で動いている Pod はすぐには追い出されず、デフォルトでは 300 秒(5 分)の猶予期間が与えられます。この時間は kube-apiserver
のdefault-unreachable-toleration-secondsとdefault-not-ready-toleration-secondsオプションで設定できます。 - Pod の退避 (Eviction): 猶予期間を過ぎても Node が応答しない場合、TaintManager が Pod を Evict して Pod が再度別のノード上で動かせるようにします。
- Podの再スケジュール: Pod が退避されると、ReplicaSet などのコントローラーが利用可能な Node に Pod を再配置します。この場合、理論上は NotReady な Node と新しい Ready な Node の上の最大 2 つが同時に存在している可能性があります。
このように、様々なコンポーネントが連携し、Node の障害からの自動復旧が実現されています。
(実際) Node が強制シャットダウンされると……?
では、この一連の流れを実際の監査ログから追ってみましょう。
Google Cloud の日本のサポートチームが開発・メンテナンスしている Kubernetes History Inspector (KHI) を使って挙動を可視化していきましょう。
KHI はコントロールプレーンの監査ログを元にクラスターで起きた過去の事象をタイムラインにして目にみえる形式にしてくれます。
今回の構成では、自宅のコントロールプレーンの監査ログを Loki へ転送し、そこから JSONL 形式の監査ログを復元する手段をとっています。もし試してみたい人がいればチュートリアルもあるので参考にしてみてください。
お試し用の環境ログ

Node の状態遷移
まず、Node の状態がどのように変化したかを見てみます。以下の図は、正常な Node optilex と、シャットダウンされた Node centre のタイムラインを比較したものです。
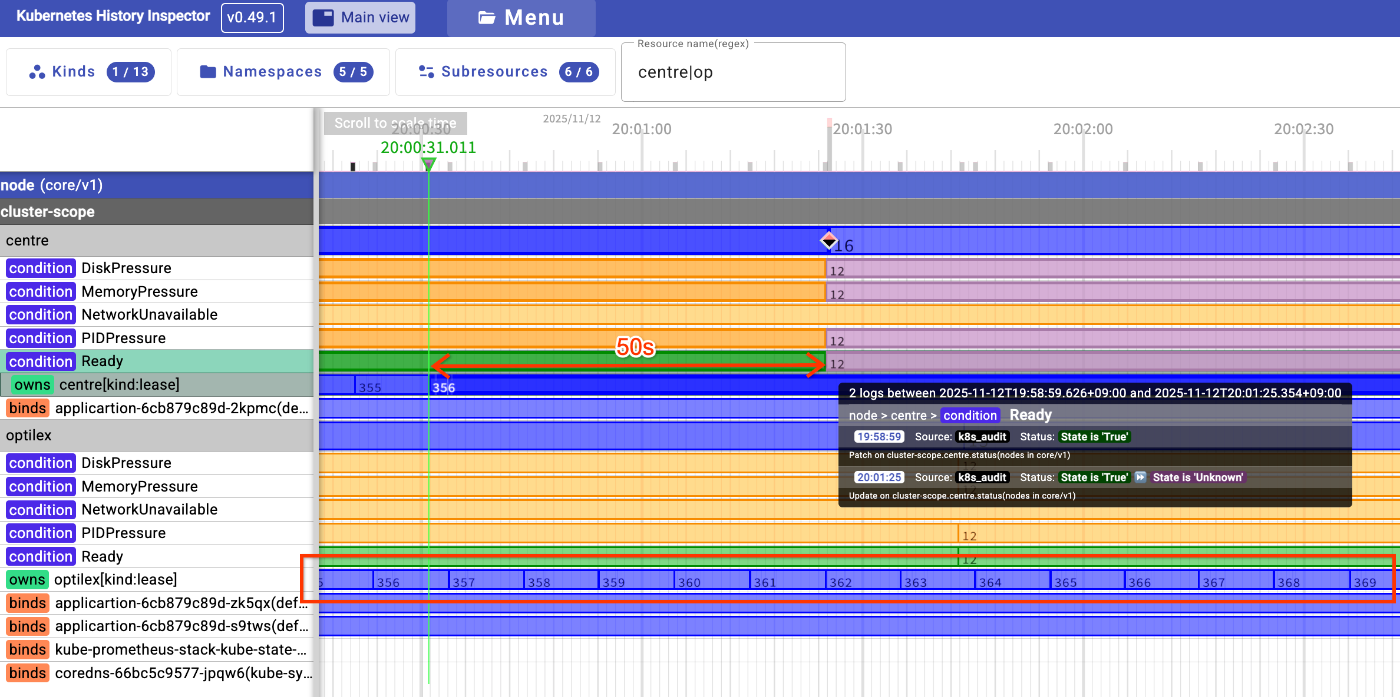
KHI の見方
Kubernetes 上のリソースが一番右のパネル、隣にリソースのタイムラインがあります。タイムラインの上の数字は「リソースの変更回数」を表しており、変更があるたびに数字が増え、ステータスが変わるとタイムラインの色が変わります。基本的に緑色はヘルシー、黄色は不明 or 未定義、赤系はあかん状態を表すことが多いです。

正常な optilex の lease は定期的に更新され続けています。一方、centre の lease は 356 番目の更新が停止しています。物理的なシャットダウンが行われた瞬間です。
そして、lease の更新が止まってから約 50 秒後、centre Node の Ready Condition が false に変更されているのが分かります。これで、Kubernetes クラスタはこの Node を NotReady として認識しました。
さらにこのタイミングでコントロールプレーンの node-controller から centre の Node のスペックが変更され node.kubernetes.io/unreachable:NoExecute の Taint が付与されています。これが後述の Pod の変更につながっていきます。

Pod の状態遷移
次に、NotReady となった Node centre 上で動いていた Pod がどうなったかを見ていきましょう。Node のステータスが NotReady になると、ほぼ同時にその上で稼働していた Pod のステータスも NotReady に変更されます。

Pod にはデフォルトで node.kubernetes.io/unreachable:NoExecute という Toleration が設定されており、tolerationSeconds は 300 秒です。そのため、Pod は即座に削除されるのではなく、5 分間待機します。

そして 5 分後の猶予期間を過ぎると、TaintManager は Pod の削除を要求(Evict)します。これにより Pod オブジェクトに削除タイムスタンプが設定され、ReplicaSet などのコントローラーが Pod の喪失を検知し、新しい Pod を正常なノード上にスケジュールします。

ちなみに、シャットダウンされた centre を再起動すると kubelet が起動し、削除対象としてマークされていた古い Pod のクリーンアップを自動的に実行してくれます。
まとめ
今回の障害におけるダウンタイムを振り返ってみましょう。
- Node 停止から NotReady 認識まで: 約50秒
- NotReady 認識から Pod の再作成完了まで: 約5分
合計で約 5 分 50 秒、サービスの一部の Replica がダウンしたことになります。正確には前者 50 秒の間は該当の Pod が生きている扱いになっているため、該当の Pod への通信にタイムアウトなどのネットワークエラーが発生し、後者 5 分の間ではいわゆる「片肺飛行」の状態になっていました。
マネージドな環境では物理障害に起因する問題に遭遇することはあまりありません。しかし、おうち Kubernetes では、熱暴走、停電、そして今回のような不意の電源断など、予期せぬ物理イベントが起こり得ます。こうした障害を実際に体験し、Kubernetes の自己回復能力の力強さを肌で感じられるのは、おうち Kubernetes ならではの醍醐味ではないでしょうか。みなさんもぜひ、ご家庭で Kubernetes を育ててみてください。

Discussion