はじめに
Cloud SQLにはEnterprise Plusというエディションがあります。その特徴の1つとして計画メンテナンス時のダウンタイムの短さがあります。本稿ではこのメンテナンス時間の短縮がどのような仕組みで実現されているかを解説します。マニュアルなどではこのメンテナンスの方式のことを「ダウンタイムがほぼゼロの計画的メンテナンス(Near-zero downtime planned maintenance)」と呼んでいます。そのままでは少々長いので本稿では以降、ニアゼロダウンタイムと記載します。
Cloud SQL Enterprise Plusを使うだけであればメンテナンス時の利用できない時間が短いのだなという理解でも十分です。その中で実際に何が行われているか興味がある方のための解説です。
ニアゼロダウンタイムの仕組み詳細
これ以降の説明はCloud SQL Enterprise Plus for MySQLを前提にします。データベースエンジンでの用語などの違いはありますが、基本的にはPostgreSQLでも同様のプロセスで実行されます。
解説はHA構成を例としてます[1]。そのため、構成要素は以下の通りです。
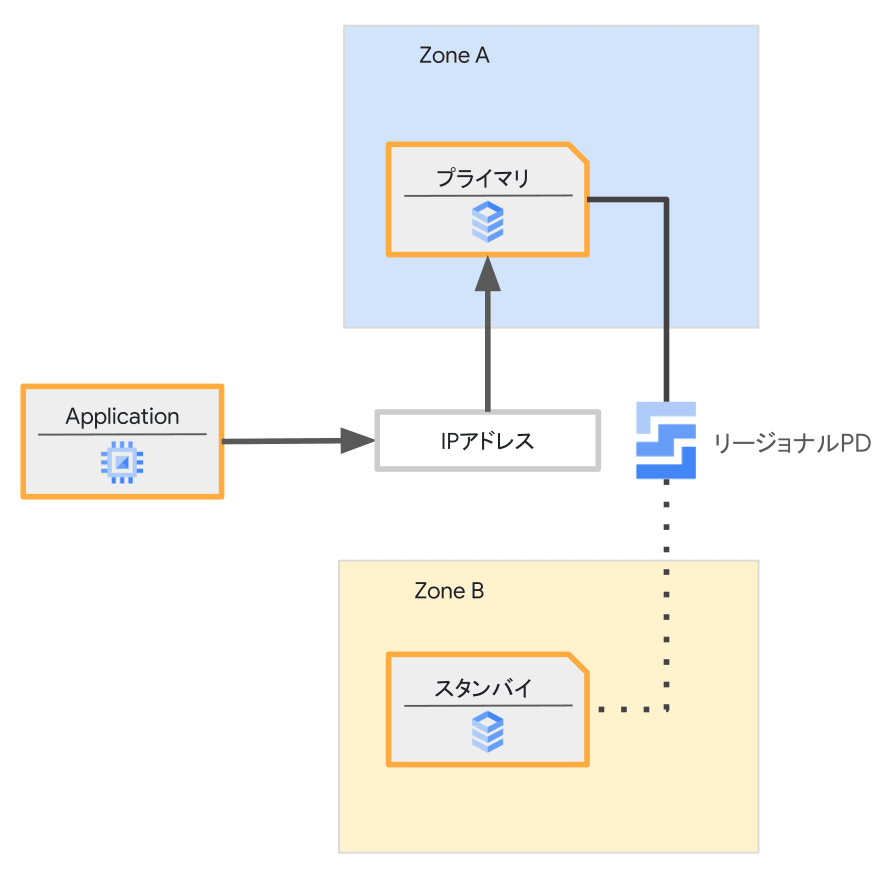
- プライマリ:HA構成のアクティブ側のVM
- スタンバイ:HA構成のスタンバイ側のVM
- リージョナルPD(Regional Persistent Disk):複数のゾーンに同期コピーされており冗長性があるブロックストレージ(ディスクデバイス)
- IPアドレス:データベースエンジンにアクセスするためのIPアドレスで、その時点のプライマリを指しています
準備
このステップではストレージも含めて、既存のインスタンスの構成と同じ構成を再現します。
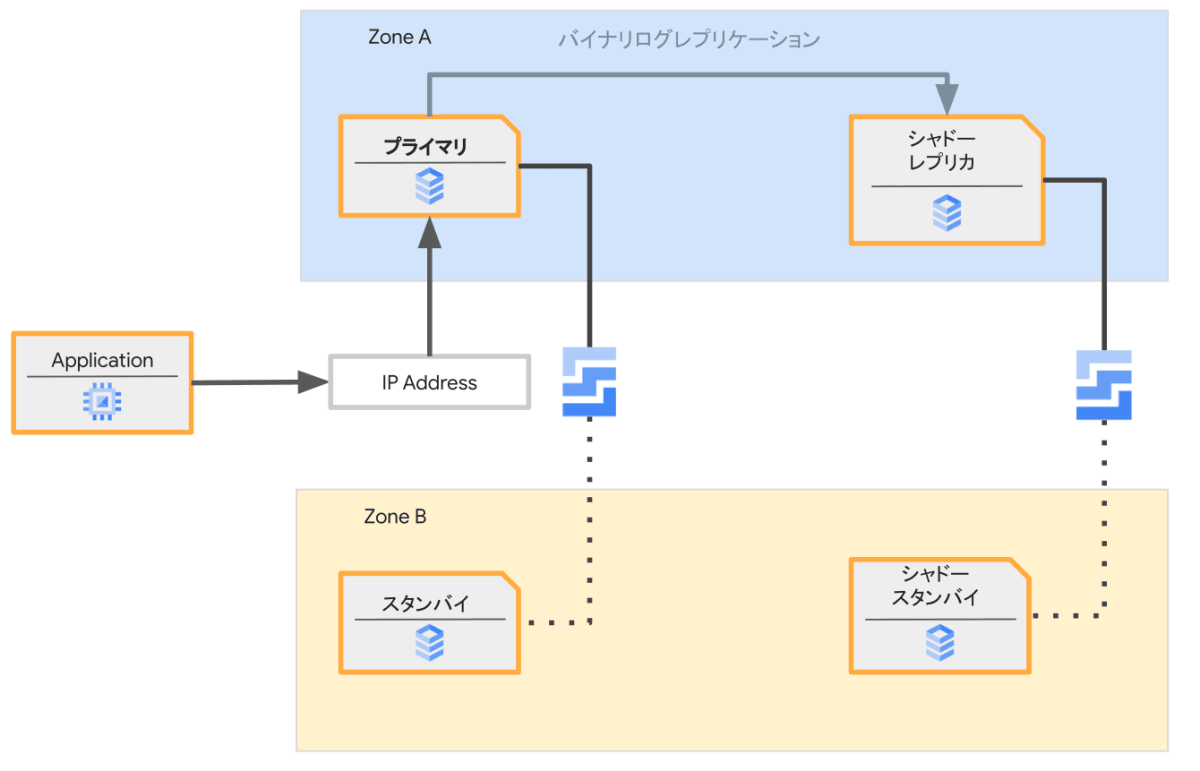
ここでは新たに作られるプライマリとスタンバイの複製はそれぞれここではシャドーレプリカ、シャドースタンバイと呼びます。ストレージはメンテナンス対象のストレージの内容を複製します。ハードウェアなどの構成を行ったあとにプライマリとシャドーレプリカの間でバイナリログレプリケーションを構成します。これによりシャドースタンバイはストレージの複製により作られた以降の更新内容も受け取れます。
シャドーレプリカはこの時点ではユーザーからアクセス可能なIPアドレスを持っていません。
このステップは言い換えると、外からはアクセスできないHA構成のリードレプリカを作成する動作とも言えます。
シャドーレプリカへのメンテナンスの適用
この時点でシャドーレプリカを対象にメンテナンスを実行します。
データベースエンジンの更新など適用後にデータベースエンジンの再起動を必要とする場合もありますが、メンテナンスの適用対象はユーザーのサービス(アプリケーション)からはアクセスできないシャドーレプリカであるため実際のサービスへの中断は発生しません。
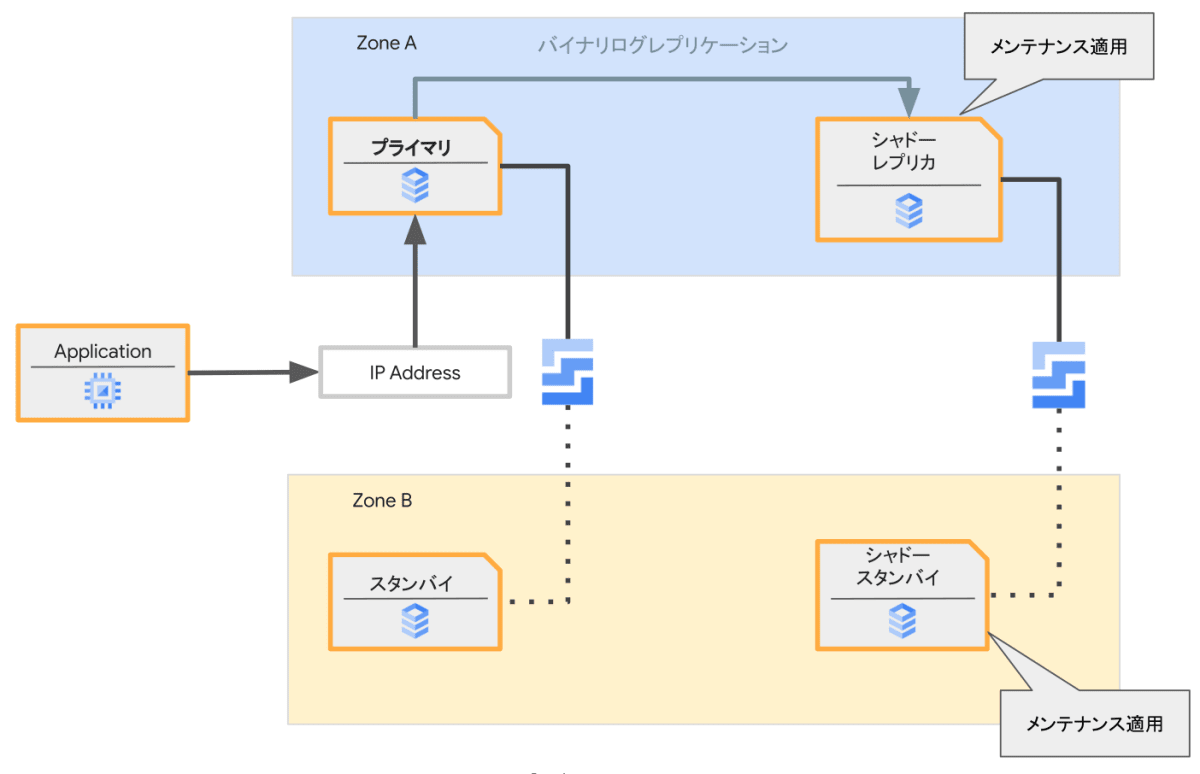
メンテナンス適用の復帰後、レプリケーションは再開され再起動中の更新差分も受け取とることでシャドーレプリカの内容はプライマリに追いついた状態となります。
サービスの中断
このステップが実際のサービスの中断となります。先のステップの完了後でレプリケーションが追いついていることを確認してから実行されます。
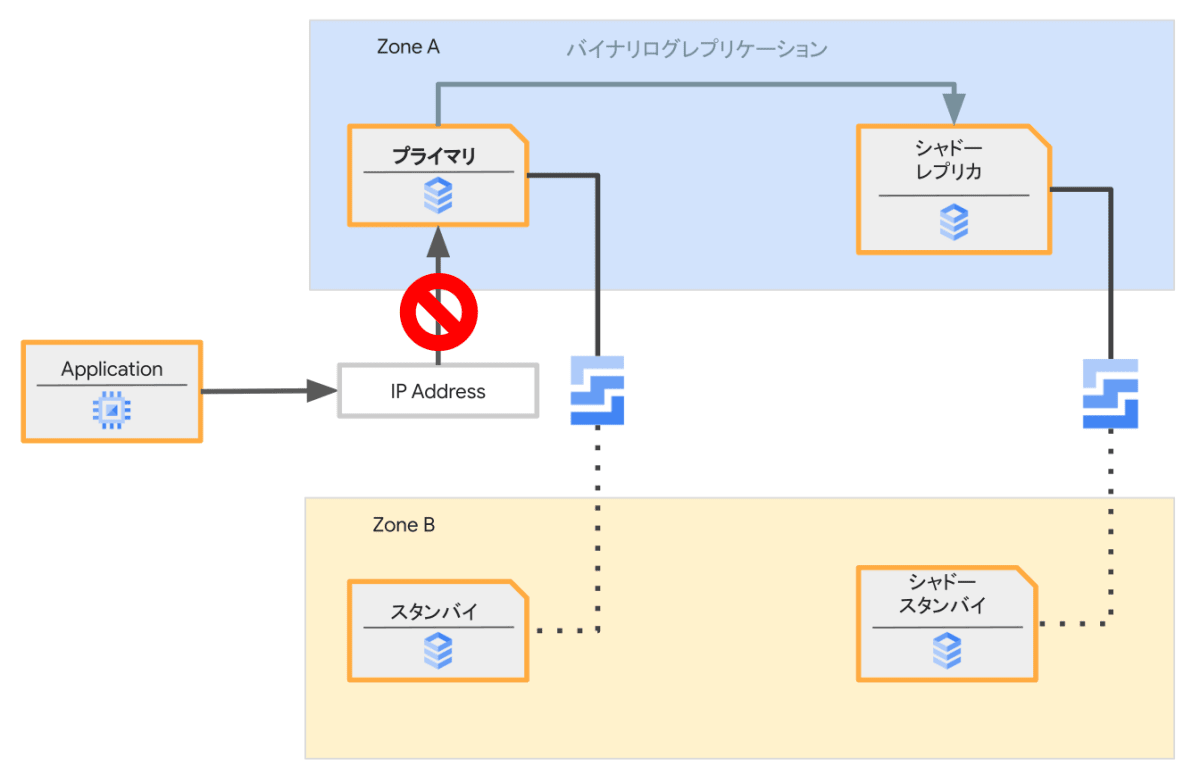
プライマリで新規のコネクションの受付を止めて、IPアドレスをプライマリからシャドーレプリカに切り替えます。
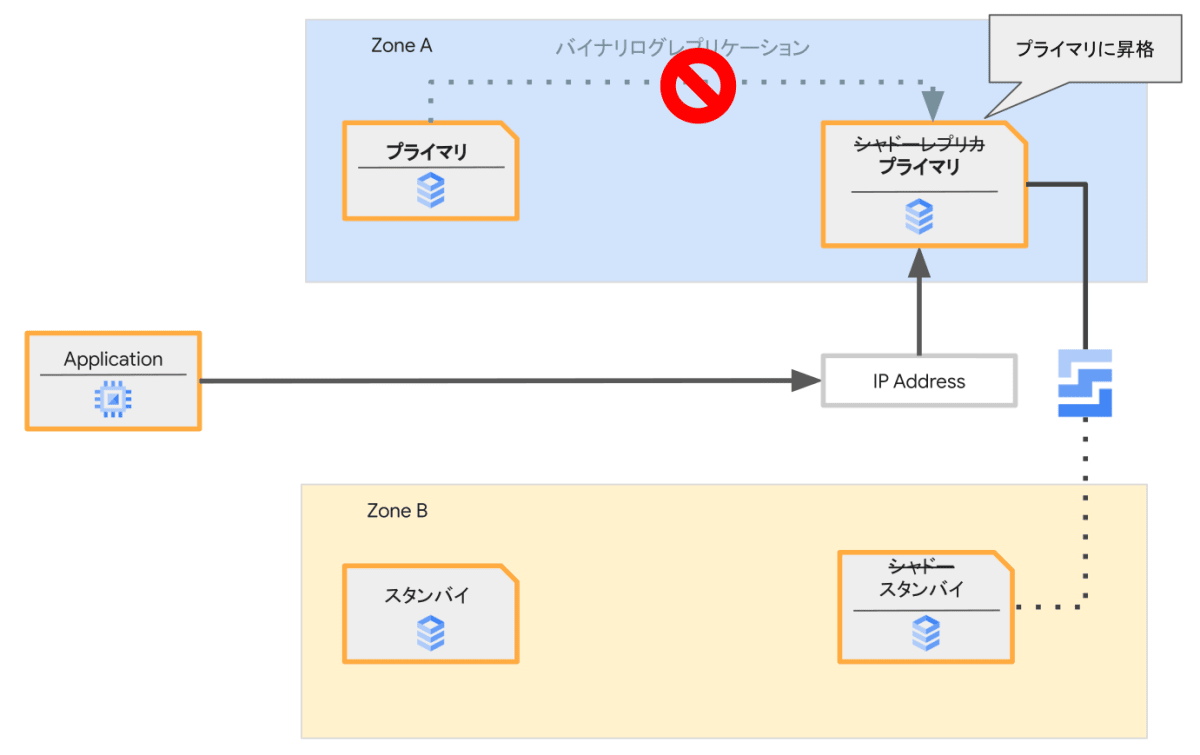
次に、プライマリとシャドーレプリカ間でのレプリケーションを解消します(RESET REPLICA)。これによりシャドーレプリカが新たなプライマリへと昇格されます。
新規のコネクション受付停止から昇格後の新たなプライマリがコネクションを受け付けるまでがダウンタイムとなります。この間の時間は通常、1秒程度です。
片付け
シャドーレプリカが昇格したため、元のプライマリは不要となります。それらのリソースの順次片付けが行われます。
このステップはもちろんデータベースエンジンの動作には影響ありません。
よくある(かもしれない)疑問点
メンテナンスの前提条件は何か、なぜあるのか
ニアゼロダウンタイムが適用できるためには前提条件がいくつかあります。なぜこのような条件が必要なのでしょうか。ニアゼロダウンタイムの仕組みを理解すると、このメンテナンスの前提条件や制約は理解しやすいと思います。
次のフラグについて、デフォルト値から変更していないことが前提条件の1つになっています。つまりこれらの設定をデフォルトのまま使っていれば大丈夫です。
-
sync_binlog値: 1 -
innodb_flush_log_at_trx_commit値: 1 -
replica_skip_errors値: OFF -
binlog_order_commit値: ON
これらのフラグの設定は安全なバイナリログレプリケーションで求められる一般的な内容です。これはプライマリとシャドーレプリカの間でバイナリログレプリケーションを実行しているためです。
メンテナンス対象のインスタンスが外部のリードレプリカを持っている場合、メンテナンスの前後でレプリケーションも正確に追従する必要があるため、GTIDによる自動ポジショニングが有効であることも求められます。メンテナンス中にログが二重に出るタイミングがあるのは、メンテナンス時にプライマリとシャドーレプリカでVM間での切り替わりが理由です。
前提条件ではありませんが、メンテナンスの前後でMySQLサーバーのUUIDが変更されることからもメンテナンスによってサーバープロセスが変更になっていることが分かります。
対象となるメンテナンス
現時点(2024年11月時点)では以下のメンテナンスがニアゼロダウンタイムの対象となります。
- OSへのパッチ適用
- DBエンジンのマイナーバージョンアップ
- インスタンスサイズのスケールアップ・ダウン[2]
- EnterpriseエディションからEnterprise Plusへの変更
- Data Cacheの有効・無効[3]
メンテナンスの全体の時間
ニアゼロダウンタイムのメンテナンスはダウンタイムを短くするため、事前に追加のリソースを使い準備期間を長めにとります。そのためメンテナンス適用本体が十秒で終わる内容であっても、事前の準備と片付けも含めると数分程度となることが一般的です。
メンテナンス後のパフォーマンス
メンテナンスの前後で異なるVMに切り替わるため、メモリ上のキャッシュがクリアされます。そのためメモリ上のキャッシュに再びデータが十分にロードされるまでストレージへのアクセスが増える可能性はあります。
ストレージについてもメンテナンス前後で別のストレージボリュームが使用されますが、Cloud SQLのストレージとして使っているリージョナルPDは複製後の初回アクセス時にレイテンシが高くなるといった症状は一般的に発生しません(いわゆるファースタッチレイテンシはありません)。そのためストレージの性能はメンテンナンス前後で同程度の性能であることが期待されます。
メンテナンス内容によってダウンタイムは差があるか?
メンテナンス方法の解説の通り、ニアゼロダウンタイムでは準備段階でメンテナンスに必要な変更作業を行います。そしてダウンタイムはその後の切り替え時に発生します。そのためメンテナンス内容とダウンタイムの長さは一般的に影響はないはずです。
ただし、ダウンタイム以外も含めた全体の適用時間はメンテナンスでの変更内容によって多少の長短が生じる可能性はあります。
通常のメンテナンスとニアゼロダウンタイムの違い
(Enterprise Plusではない)Cloud SQL Enterpriseでは通常のメンテナンス方法を実施しています。この方式でもフェイルオーバーの仕組みをつかってダウンタイムを短くする努力が払われています。スタンバイのVMを作成し、そちらへメンテナンスを適用しフェイルオーバーします。基本的なコンセプトはニアゼロダウンタイムと似ています。通常のメンテナンスで行っている内容についてはマニュアルに各ステップを詳細に解説しています。
これに対して、ニアゼロダウンタイムではストレージも複製を行ってそちらに切り替えます。この方式のメリットはプライマリでのデータベースエンジンのシャットダウンとその後に行うストレージの引き継ぎを行うステップを省略できる点があります。この変更によりダウンタイムがさらに短くすることが可能となります。ただし、準備すべき内容が増えるためメンテナンスプロセス全体の時間は長くなる傾向はあります。
アプリケーションから見たときのメンテナンス
接続先のIPアドレスを引き継ぐため、メンテナンス中での切り替えの前後でアプリケーションからの接続先に変更はありません。
ただし、VMとその上で動作するデータベースエンジンが切り替わるためメンテナンス以前から確立していたコネクションは使えなくなり、その瞬間に実行されていたトランザクションは中断されます。
また、切り替わりが短時間で実行されるため、データベースエンジンへのコネクションが正しく切断されたことを検出できていない場合があります。コネクションプーリングなどでコネクションを維持している場合は、空のSELECT文を発行するなどのキープアライブでコネクションの死活管理が有効です。
ニアゼロダウンタイムメンテナンスのシミュレーション
ニアゼロダウンタイムメンテナンスはアプリケーションへの影響は瞬断となるように設計されていますが、実際のアプリケーションでどのような影響があるかを事前に知りたい場合もあると思います。そのような場合のため、シミュレーションすることも可能です
gcloud sql instances patch INSTANCE_NAME --simulate-maintenance-event
このコマンドでは、本記事で解説したプロセスをシミュレーションします。ただし、シャドーレプリカへのメンテナンスの適用のプロセスが行われません。いわばメンテナンスの「空打ち」が実行できます。サーバーの交換は実行されるため、アプリケーションとの通信切断は実際に行われます。開発やステージング環境で実行することで、アプリケーションへの影響を事前に確認することで本番環境での影響を予測することができます。
参考リンク
- Cloud SQL Enterprise Plusエディションにおけるマイナーバージョンアップ時のダウンタイムについて実際にメンテナンス時のダウンタイムを計測されています。この記事の時点から処理の最適化が進んだため、より短くなっているはずです
-
2024年9月12日の更新でHA構成以外でもニアゼロダウンタイムが利用できるようになりました。 https://cloud.google.com/sql/docs/release-notes#September_12_2024 ↩︎
-
スケールダウンについては2024年11月18日のアップデートで対応しました。 https://cloud.google.com/sql/docs/release-notes#November_18_2024 ↩︎
-
Data Cacheについては、2024年11月18日のアップデートで対応しました。 https://cloud.google.com/sql/docs/release-notes#November_18_2024 ↩︎

Discussion