tl;dr
- Spannerのパーティション化DML(PDML)は、トランザクション上限を超える大規模な更新や削除を行うための機能です。
- テーブルを内部でパーティションに分割し、各々を並列で処理するため、実行するDMLは冪等である必要があります。
- バッチ処理での一括データ更新や、アドホックなTTLの代替としての大量レコード削除といった、アトミック性が不要な場面で役立ちます。
はじめに
Spannerではバッチ処理などの場合に、DMLで大規模な変更を行う場合にミューテーション(Mutation、Spannerにおけるよりプリミティブな変更の単位)の数について考慮する必要があります。
1つのトランザクションあたりに行えるミューテーション(変更)[1]の上限は現在80,000です。
この値は、幾度かの引き上げを経て現在の上限になっていますが、依然として無制限ではありません。
通常のOLTPで使うには十分な大きさですが、バッチ処理などでテーブル全体に対して一気に値を変更したい場合など、この上限を考慮しなければならない場面もあります。
このような場面で利用できるのがパーティション化DML(Partitioned DML 以下、PDML)です。
この機能はSpanner独特の機能なので、どのような機能であるのか、どのような点に注意して利用するべきなのかを解説します。
PDMLとは何か
マニュアルにはPDMLについて、以下のような説明がされています。
パーティション化 DML は、キー空間を分割し、スコープの小さい個別のトランザクションでパーティションにステートメントを実行します。これにより、同時トランザクション処理に及ぼす影響を最小限に抑えながら、データベース全体にわたる大規模なオペレーションを実行できます。
テーブル全体を適当な大きさのパーティションに区切って、全体に実行したいDMLを各パーティション毎に実行していくイメージです。パーティションの分割はSpannerの内部で自動的に行われます。パーティション毎の個別のDMLの実行が何らかの理由により失敗した場合、Spannerの内部で自動的に再実行され、全体に少なくとも1回以上DMLが適用される動作となります。
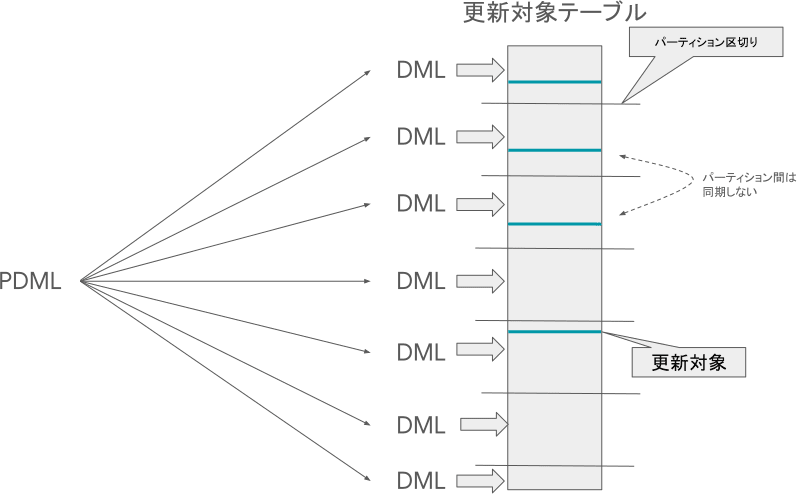
この内部での再実行の可能性があるため、PDMLで実行されるDMLは冪等である必要があります。
マニュアルにもある例として、以下のような UPDATE 文の実行をPDMLで行ったとします。
UPDATE Singers SET MarketingBudget = 1.5 * MarketingBudget WHERE true;
このようなDMLではリトライされたときにMarketingBudgetへの1.5倍が複数回実行される可能性があるため、意図しない結果になります。リトライは自動的に分割された各パーティションごとに必要に応じて実行されるため、特定の行だけ2回実行されたような整合性の取れない結果となる場合があるためです。
PDMLで実行可能なDMLはUPDATEとDELETEです。
PDMLはどのような場合に使うべきか
PDMLはテーブル全体に対して値を埋めていくような処理に適しています。たとえば、「運用中のサービスで全ユーザーに対して一律に特定のフィールドの値を設定したい」などが考えられます。これはカラムのデフォルト値などでも可能ですが、PDMLではより柔軟にDMLで実行できます。
他には、特定の条件に当てはまるレコードを一気に削除したい場合などが考えられます。これは同じくTTLによっても実現可能ですが、TTLを使用する場合は事前に削除ポリシーをつけておく必要があったり、削除条件となるカラムがTIMESTAMP型である必要があるなどの制約があるためDMLで実行したい場合にはPDMLが有効な方法となります。
PDMLが有効な例1
Webサービスのユーザー情報を持っているテーブル Users で退会ユーザーは削除フラグで管理していたとします。削除フラグはTIMESTAMP型の deleted_at カラムで、NULL値以外が入っている場合は退会ユーザーとします。このときサービス提供国の法規制により、退会後2年を経過したユーザーのレコードは削除する必要があったときのDMLは以下のような内容になるでしょう。
DELETE FROM Users
WHERE deleted_at < TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 2 YEAR);
このようなDMLはPDMLでの実行に適しています。
PDMLが有効な例2
ECサイトで新たに商品のレコメンド機能をリリースしようとしています。レコメンドの初期スコアは商品のカテゴリによっていくつかのパターンがあり、本の場合は0.5、それ以外のときは0.1設定します。
UPDATE Products
SET recommend_score =
CASE
WHEN category = 'books' THEN 0.5
ELSE 0.1
END
WHERE TRUE;
PDMLはどのような場合に適さないか
マニュアルでは以下のようなDMLについてはPDMLで実行できないとされています。
- アトミックな更新である必要がある処理
- 冪等ではない処理
- サブクエリで他のテーブルが関係する処理や同じテーブルでも他の行を参照するような処理
PDMLは更新をアトミックに行わないことで大規模な更新に対応しているため、厳密なアトミック性が必要な処理(口座間での振替処理や在庫管理など)には適していません。
冪等である必要があるのは前述の通りです。複数のテーブルが関係すると分散トランザクションとなってしまいますし、同じテーブルでも他の行(=他のパーティションである可能性がある)を読み込む処理はパーティション個別にDMLを適用するときに問題となります。
そのため、このような処理はPDMLでは実行できません。
PDMLの実装者の気持ちになって考えてみる
ちょっと視点を変えて、PDMLという機能自体を実装する側の気持ちになってどのような仕組みを実装すればよいかを想像してみます。
Spanner自体はアトミックに大規模な更新を行う事はできません。これは単一のDMLであっても更新対象行が多いと更新前後のデータ量が大きくなり、ロールバックを行うために必要なデータを保持する必要がありそれらの新旧の状態を単一の実行コンポーネントで保持することの難しさがあるなと想像できます。大規模な更新をアトミックに行うことの難しさはMySQLなどでも同様でしょう。大規模なDMLを実行すると、ロールバックセグメントが一気に肥大化することで他のトランザクションのスループットに悪影響が懸念されます。DMLとしてのアトミック性は諦めて、DB全体への影響を小さくするため数千行ごとに分割してCommitするようなバッチを作られているケースは多いと思います。
閑話休題。では、Spannerに対してどのように大規模更新を行えばいいでしょうか。同じように大規模な更新を小さな更新へ分割することは有効であるように思えます。
Spannerではテーブルは主キーの昇順で物理的に配置されているため、この主キーを一定の区間で分割してその領域ごとにDMLを実行することが良さそうです。一定の区間とは、ミューテーションの上限が80,000であるため、これよりは小さい単位が良さそうです。
ただし、分割実行するにしてもDMLは実行時に一時的なエラーとなることを考慮する必要があります。パーティションごとに実行完了を見届けて、必要であれば再実行するような処理とする必要があります。
このとき、各パーティションは他のパーティションの実行結果とは独立しているはずなので分散データベースの特性を活かして、並列実行すると全体のスループットが向上することが期待できます。
各パーティションにナイーブにDMLを実行してしまうと想定以上に広い範囲でロックを取ってしまう恐れがあります。これは通常のDMLはWHERE句でフィルターをするために列を読み取る必要があり、列の読み取り時に共有ロックを取るためです。セカンダリインデックスがあった場合には読み取り範囲を小さくすることが可能ですが、セカンダリインデックスがない列をWHERE句で指定した場合には全行のスキャンしてその条件句の列を広範囲にロックしてしまいます。ロックは各パーティション毎に個別に実行されるとはいえ、これは通常の更新トランザクションを阻害しかねないロック範囲となります。
このため、更新対象行の抽出はロックを取らない読み取り専用で行いつつ、対象行を更新する処理とは分離するといった工夫が欲しいところです。実際のPDMLでもこれに相当する工夫がされており、更新対象の行にのみロックを取得する動作となります。
このような小さなバッチでDML相当の更新を処理して回るようなレイヤーがPDMLの実装としては適当な事がわかります。
まとめると以下のようなステップになります。
- 更新対象のテーブルを適当な大きさに分割
- パーティションごとに処理を並列化する
- 各パーティションで更新対象行の抽出
- 各パーティションで更新対象行だけに更新を適用
- すべてのパーティションでの更新の正常終了を確認
さいごに
PDMLは大規模な更新を一気に適用することができるSpannerに特有の機能です。実行可能なDMLについては制限などがあるものの、同様の処理を行うバッチを毎回作るよりはAPI一つで実行可能でパフォーマンス面でもメリットもあります。
制限事項などを確認の上でご活用ください
-
DMLによって幾つのミューテーションを消費するかは、操作の内容とセカンダリインデックスの数に依存します。たとえばセカンダリインデックスのない1行のDELETEなどを1ミューテーションとしてカウントします。 ↩︎

Discussion