tl;dr
Cloud Spanner で gcsb という負荷試験ツールを使ってウォームアップを行う方法と、それに関連するいくつかの Tips を紹介します。
はじめに
この記事は「Cloud Spanner のウォームアップ ツールとベンチマーク ツールでアプリケーションのリリースを簡単に」の内容を踏襲しています。こちらの記事の内容に対して、いくつか補足説明を行ったものとなります。
Cloud Spanner におけるウォームアップとは何か
Cloud Spanner は自動シャーディングにより、テーブルを内部で分割することでノード数に応じてスケールアウトする仕組みがあります。分割されたデータはスプリットと呼ばれる単位で管理されます。スプリットの分割は「負荷」と「サイズ」のいずれかの条件で行われます。テーブルを複数のスプリットの分割する処理は自動的に実行されるため、スプリットの分割がいつ行われたかについて通常は意識する必要はありません。

単一ノードでテーブル作成直後の状態(スプリットは一つ)

テーブルをウォームアップすると単一ノードでも複数のスプリットに分割される

その後、複数のノードに増やすとそれぞれのノードが個別にスプリットを担当するので、全体として性能がスケールできます
一方で、分割が行われるタイミングでバックグラウンドでの分割処理が発生するため、対象のスプリットへのアクセスなどでテールレイテンシ(99パーセンタイルなど高いパーセンタイルのレスポンス時間)の増加が生じる可能性があります。ゲームタイトルや大規模なウェブサービスでリリース直後に一気に大量のトラフィックが予想される場面では、予めスプリット分割を促しておくことで素早くトラフィックの増加に追従することができます。
この作業のことをウォームアップや暖機運転と呼んでいます。
gcsb とは何か、何故使うのか
スプリットはデータへのアクセス状況に応じて自動的に分割されるため、本番相当のアクセスを事前に実行することで本番で必要なスプリット数に分割を行うことが可能です。しかしながら、ローンチ前に本番のワークロードを再現することが難しい場合もあります。
そのような場合に、Cloud Spanner 単体へ負荷試験ツールで負荷をかけることでウォームアップを行う方法が考えられます。gcsb とはこのような用途に使える Cloud Spanner 用の負荷試験ツールです。負荷試験ツールではありますが、試験用の独自のテーブル定義ではなくアプリケーション用のテーブル定義を読み取ってそれに対応したデータの投入とアクセスを行う事が可能という特徴があります。
準備
gcsb はコンテナで実行可能なため、大規模に実行されたい場合は参照元の記事 を参考に GKE 上にデプロイし複数のノードから実行されることをおすすめします。
この記事では GCE 上で直接実行し、gcsb の基本的な動作を紹介します。
git clone https://github.com/cloudspannerecosystem/gcsb.git
cd gcsb
make
でバイナリが作成されます。
設定ファイルは gcsb.yaml です。コメントなども豊富なので環境に応じて編集いただければ大丈夫ですが、ここでは構成を説明します。大きく分けて、インスタンスに関するパート、コネクションやそのプールのパート、読み書きなどのオペレーションに関するパート、テーブルに関するパートからなります。最低限変更する必要がある部分はインスタンスの指定に関する部分です。
インスタンスのパートでは、プロジェクトID、インスタンス名、データベース名を指定します。
# GCP Project ID
project: sample-project
# Spanner Instance ID
instance: sample-instance
# Spanner Database Name
database: sample-database
コネクションなどのパラメータは負荷をかけるクライアントのスペックと、対象の Cloud Spanner インスタンスのノード数により変更ください。
実行
gcsb 実行モードは大きく分けて load と run の2つがあります。load でデータを書き込み、run で実際の負荷の対象となるクエリーを発行します。
対象テーブル Singers に対して100万行書き込み(load)、1000万回のアクセス(run)を行ったときの例を示します。
gcsb load -o 1000000 -t Singers
gcsb run -o 10000000 -t Singers
gcsb.yaml のテーブルに関するパートに対象テーブルのカラムに関する指定を行っていた場合は、それに従ってダミーデータを書き込みます。無指定の場合は、カラムのデータ型から適当なダミーデータを生成します。プライマリキーやセカンダリインデックスの対象カラムについては本番のデータ範囲と分布に沿うように指定して下さい。
データの書き込みは実際のアプリケーションで行い、負荷掛けだけを gcsb で行うといったことも可能です。その場合は事前にテーブルにデータを書き込んでおき、run だけ実行ください。書き込み済のデータからサンプリングを行ってアクセスを行います。
片付け
ウォームアップを行ったあとのテーブルにはダミーデータが残っています。これらは本番のサービスには不要なデータかと思いますので、本番利用開始前に削除ください。
このとき、DROP TABLE を行ってテーブルを再作成してはいけません。再作成を行うとスプリットが初期状態である一つで再作成されてしまうためです。ウォームアップを行ったテーブルを残し、データの削除のみを行ってください。データの削除のみを行ってもスプリットの状態は維持されます。
このようなデータの全件削除処理は spanner-cli から TRUNCATE TABLE を実行することで可能です。TRUNCATE TABLE 相当の処理を行う単機能の spanner-truncate コマンドによる削除も有効です。
注意点
キーの範囲
Cloud Spanner は自動シャーディングの分割にプライマリキーの範囲を使います。
このため、ウォームアップ時のプライマリキーの範囲と本番で使うプライマリキーの範囲が同じであることが重要です。
例として、プライマリキーの先頭 a-z の範囲のみを使うとします。
このときウォームアップ時のデータが a-m のみを一様に使っていた場合、この範囲のデータを分散して格納できるようにスプリットが作られます。

これに対して、本番のデータが a-z を全て使う場合、a-m の範囲はスプリットが十分に作られているので期待通りのパフォーマンスとなりますが、n-z の範囲のデータは m より後ろということで最後のスプリットに集中することになります。

利用開始後に負荷が継続しますと、最後のスプリットも負荷に応じて更に分割されて最終的には負荷の内容に応じたスプリットに至りますが、ウォームアップで本来期待できる効果には十分ではない可能性が高くなります。
負荷の継続時間
スプリットの分割は負荷の条件などが満たされていれば数分で行われますが、その後の平衡状態となるまでもう少し長い時間がかかります。負荷に応じたスプリットの分割が継続する場合もあるため、規模にも依存しますが十分に安定した平衡状態となるまで1時間程度継続した負荷を掛けることがお勧めです。
ウォームアップの効果確認
ウォームアップ用の負荷を掛け続けると、インスタンスのモニタリングで読み書きの99パーセンタイルレイテンシが減少し、1秒あたりのオペレーション回数が上昇し、CPU 使用率が上昇していく様子が確認できます。この状態がスプリットが負荷に対して最適な状態となり、ウォームアップの効果が現れている状態です。
ウォームアップの対象のテーブルに対して、テーブルスキャンを実行するようなクエリーを実行し、その実行プランでのテーブルスキャンでの「実行数」を確認することでテーブルのスプリット分割数と相関性の高いメトリクスを確認可能です。
spanner-cli での実行例
spanner> explain analyze select count(*) from Singers@{FORCE_INDEX=_BASE_TABLE};
+----+----------------------------------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+----+----------------------------------------------------------------------------------+---------------+------------+---------------+
| 0 | Serialize Result | 1 | 1 | 390.29 msecs |
| 1 | +- Global Stream Aggregate (scalar_aggregate: true) | 1 | 1 | 390.28 msecs |
| 2 | +- Distributed Union | 5 | 1 | 390.28 msecs |
| 3 | +- Local Stream Aggregate (scalar_aggregate: true) | 5 | 5 | 720.53 msecs |
| 4 | +- Local Distributed Union | 1000000 | 5 | 682.26 msecs |
| 5 | +- Table Scan (Full scan: true, Table: Singers, scan_method: Scalar) | 1000000 | 5 | 621.8 msecs |
+----+----------------------------------------------------------------------------------+---------------+------------+---------------+
1 rows in set (392.93 msecs)
timestamp: 2022-11-17T05:11:35.153525Z
cpu time: 725.1 msecs
rows scanned: 1000000 rows
deleted rows scanned: 0 rows
optimizer version: 5
optimizer statistics: auto_20221115_06_46_07UTC
実行プラン中の ID 5の行がテーブルスキャン(Table Scan)ですが、この行の Exections が実行数にあたります。この例では"5"となっているのでテーブルスキャンは5並列で行われていることを示しています。Total_Latency も実行プラン上でその後に実行されている ID 0 から 2までと比べて大きくなっており、クエリ全体よりも大きなレイテンシになっていることからも並列実行されていたことが分かります。この実行数はスプリットの数と強い相関性があるため、この数が予定のノード数よりも大きくなっていることを確認することが有効です。
上記の例ではテーブルの指定にヒント句(@{FORCE_INDEX=_BASE_TABLE})がついています。対象テーブルにセカンダリインデックスがある場合、そちらへのインデックススキャンが実行される場合がありますが、ヒント句を付与することでテーブルスキャンを強制できます。インデックススキャンについては次のセクションで説明しています。
Cloud Spanner では spanner-cli 以外にもウェブコンソールからクエリを発行することできます。ウェブコンソールからクエリーを発行するには、対象の DB インスタンスを選択してクエリーを発行する先のデータベースを選択、左側のメニューの「クエリ」を選びます。

クエリ画面から spanner-cli のときと同様にテーブルスキャンを実行する SELECT 文を実行します。違いは、explain analyze など実行プランを取得する指定は不要であるということです。「実行」を選ぶと通常の SQL の実行と実行プランの取得も同時に行われます。実行プランを確認するには「説明」タブを選択します。
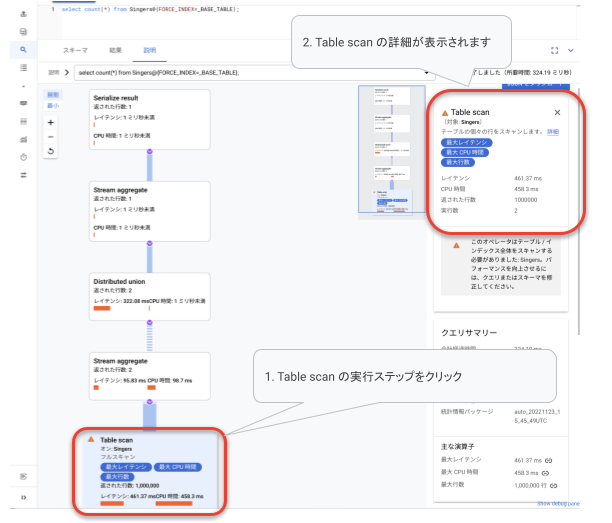
実行プランでは各ステップが四角い箱で表現されるので、その一番下にある Table scan に注目します。

Table scan ではレイテンシなどの情報と共に表示される「実行数」が使用予定のノード数以上になっていることを確認ください。
インデックス
Cloud Spanner ではセカンダリインデックスもテーブルの一種です。そのため、セカンダリインデックスに対してもスプリットの考え方は適用可能です。
具体的にはテーブルと同様にスプリットに分割され、その分割数もテーブルと同様に確認が可能です。テーブルの場合は対象のテーブルへのフルスキャンを実行することで確認可能ですが、インデックスの場合はインデックスへのフルスキャンを実行するクエリーの実行プランを見ることで分割数を確認ができます。テーブルスキャンを強制するのと同様に、インデックススキャンをヒント句で指示ください。
以下の実行例では Singers テーブルに SingersByFirstLastName というセカンダリインデックスがある場合です。実行計画中の Index Scan 行の Executions 列に注目してください
spanner> explain analyze select count(*) from Singers@{FORCE_INDEX=SingersByFirstLastName};
+----+-------------------------------------------------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+----+-------------------------------------------------------------------------------------------------+---------------+------------+---------------+
| 0 | Serialize Result | 1 | 1 | 430.81 msecs |
| 1 | +- Global Stream Aggregate (scalar_aggregate: true) | 1 | 1 | 430.8 msecs |
| 2 | +- Distributed Union | 1 | 1 | 430.79 msecs |
| 3 | +- Local Stream Aggregate (scalar_aggregate: true) | 1 | 1 | 430.78 msecs |
| 4 | +- Local Distributed Union | 1000000 | 1 | 390.1 msecs |
| 5 | +- Index Scan (Full scan: true, Index: SingersByFirstLastName, scan_method: Scalar) | 1000000 | 1 | 341.18 msecs |
+----+-------------------------------------------------------------------------------------------------+---------------+------------+---------------+
1 rows in set (433.17 msecs)
timestamp: 2022-11-24T00:43:51.824655Z
cpu time: 433.1 msecs
rows scanned: 1000000 rows
deleted rows scanned: 0 rows
optimizer version: 5
optimizer statistics: auto_20221123_15_45_49UTC
ウォームアップからサービスインまでの期間
Cloud Spanner では負荷が低い状態が長時間継続すると、分割されたスプリットを統合する処理が実行されます。そのため、実際にプロダクション環境で使い始める前の2日前ぐらいにウォームアップを行われるのがおすすめです。
インターリーブ
インターリーブとは Cloud Spanner であるテーブルのレコードを別のテーブルのレコードと物理的に連続した場所に配置することを指示できる機能です。データの性質として親子関係があるようなテーブル間でこの指定を行うことで、効率的にアクセスができます。
gcsb は現時点でインターリーブの最も親テーブル(APEX Table)へのアクセスにのみ対応しているため、インターリーブのテーブルへのウォームアップを行う場合、親テーブルを指定して実行ください。インターリーブの性質上、子テーブル各レコードはは親テーブルの対象レコードと連続した場所に配置されてるためテーブル全体は親テーブルと同様に分散したスプリットに配置されることが期待されます。

Discussion
先日gcsb を用いてwarmup を行い、この記事も大変参考になりました。ありがとうございます。
もしご存知でしたら細かい数字について教えていただきたいです。
どの公式ソースでも少なくとも1時間程度の負荷をかけると書いてあります。
ここらへんの時間とスプリットの状況の関係性を詳しく知りたいのですが、公式の資料などご存知でしょうか?
こちらももし詳しいソースについてご存知でしたら教えていただきたいです。
具体的にどれくらいの期間でどのようにスプリットが統合されていくのかが気になっています。
コメントありがとうございます。
この記事では公式ソースとして冒頭で紹介している blog エントリーを参照しております。記事の内容よりも詳細な公開されている公式ソースについては残念ながら持ち合わせておりません。
スプリットは統合される可能性があり、そのためにクエリーの実行時にリトライする仕組みを実装したという話が公開されている論文 (https://research.google/pubs/pub46103/ ) の中で言及されておりました。ウォームアップの記事などでも実際のローンチ2日前に実施を推奨していることから、2日間低負荷の状態が継続しても直ちにスプリットがマージされることはないことは推測可能だと思います。