

何の話かと言うと
GitHub で公開されている下記の画像セグメンテーションモデル(SAM 2)を Vertex AI のオンライン予測サービスにデプロイして、API サービスとして利用する手順を紹介します。
画像セグメンテーションモデルを Google Cloud で利用する方法の一例として、また、より一般に、カスタムモデルを Vertex AI にデプロイして API サービス化する手順の例として参考にしてください。
このモデルを利用すると、下記の例のように、画像内の指定区画にある物体を検出して、その物体だけを取り出すマスクが取得できます。マスクを反転させれば、背景を消去する処理にも利用できます。
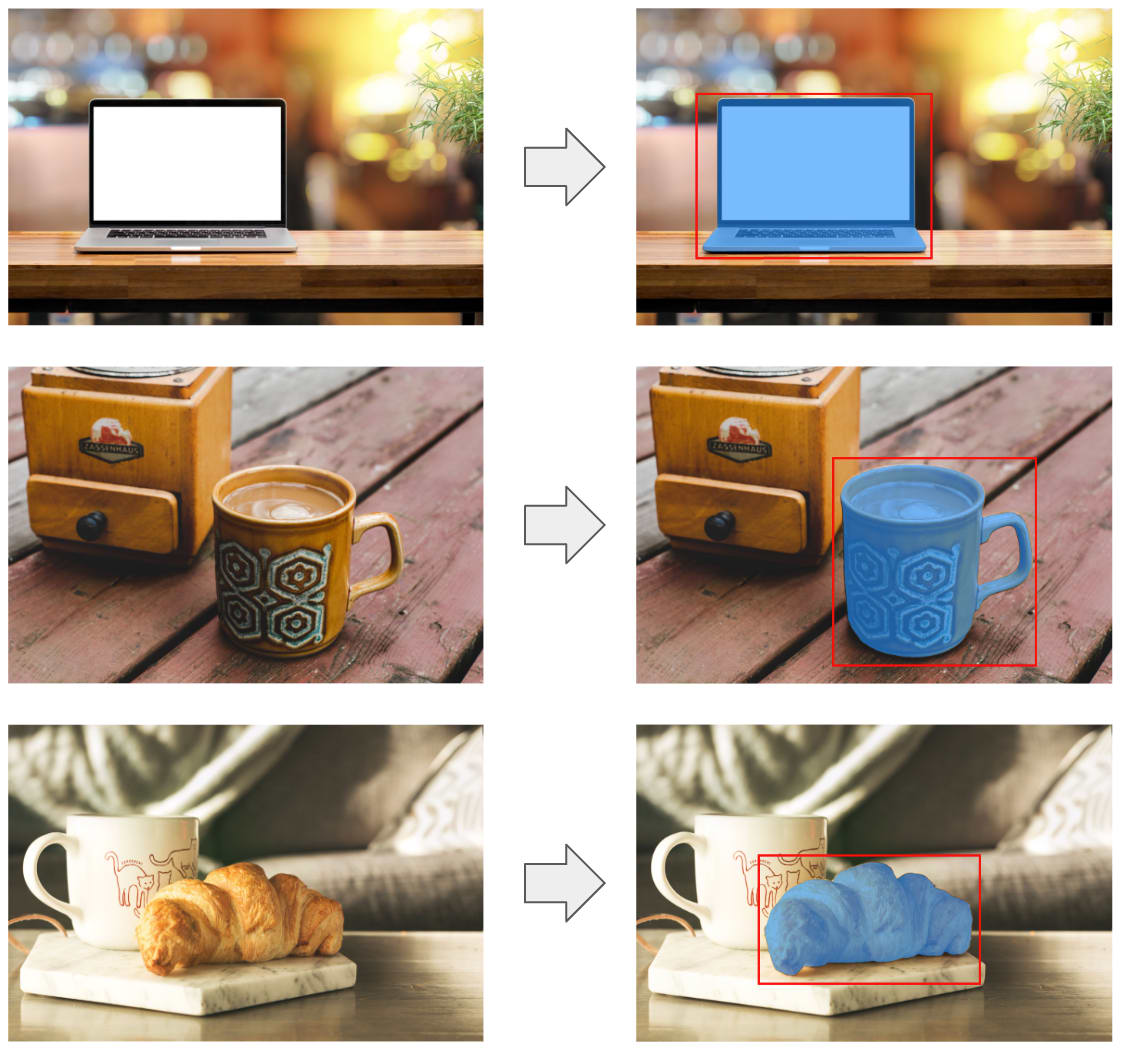
画像セグメンテーションの実行例
Vertex AI のオンライン予測サービスについて
機械学習モデルによる予測処理を REST API として提供するコンテナイメージを独自に作成しておき、これを Vertex AI のオンライン予測サービスとしてデプロイします。これにより、オートスケールに対応した予測サービスの API が実現できます。
一般的な API サービスであれば、Cloud Run のサービスとしてデプロイすることもできますが、Vertex AI にデプロイすることにより、ハードウェアアクセラレーター(GPU/TPU)を使用したり、予測モデルに特化したモニタリングなど、Vertex AI 固有の機能と連携することが可能になります。この後の手順で見るように、Vertex AI のクライアント SDK を使って予測処理を実行することもできます。
コンテナイメージを作成する際は、ざっくりと次のルールに従います。
- API の受付ポートは環境変数
AIP_HTTP_PORTの値を使用する - ヘルスチェック用エンドポイントを公開する
- 予測用エンドポイントのパスは環境変数
AIP_PREDICT_ROUTEの値を使用する - ヘルスチェック用エンドポイントのパスは環境変数
AIP_HEALTH_ROUTEの値を使用する - リクエストは
instancesをキーにして、予測対象データのリストを受け取る
{"instances": [
{予測対象データ1},
{予測対象データ2},
...
]}
- レスポンスは
predictionsをキーにして、予測結果のリストを返す
{"predictions": [
{予測結果1},
{予測結果2},
...
]}
上記の例からわかるように、1 つのリクエストに複数の予測対象データを含めることができます。個々の予測対象データと予測結果は、JSON で記述できるものであれば任意のフォーマットが使用できます。この後の説明では、個々の予測対象を「インスタンス」と呼びます。
今回は、処理対象の画像ファイルはストレージバケットに保存しておき、ファイルの URI(gs://...)をリクエストで指定する仕様にします。モデルのチェックポイントファイルもストレージバケットに保存しておき、モデルをデプロイするタイミングでバケットからロードする形にします。

全体の構成図
セグメンテーションモデルの使い方
はじめに、前述のセグメンテーションモデル(SAM 2)の使い方を簡単に説明します。リクエストとレスポンスのフォーマットはモデルをホストするコンテナの作り方に依存しますが、ここでは、この後の手順で作成するコンテナの仕様にあわせます。具体例として、次のサンプル画像を使います。縦 1,200 ピクセル、横 1,800 ピクセルのカラー画像です。

説明用のサンプル画像
基本機能
基本的には、画像ファイルと処理対象区画の長方形を指定すればOKです。インスタンスの image 要素にストレージバケットに保存した画像ファイルの URI、そして、box 要素に区画の左上と右下の x, y 座標を並べたリストを与えます。また、id 要素には個々のリクエストデータを区別する任意の ID を指定します。省略時は None になります。そして、multimask 要素に True を指定すると、3 種類の候補が信頼度スコアとともに得られます。デフォルトは False で、この場合は、最もスコアが高い結果だけが得られます。
次は、multimask 要素がデフォルトの False のインスタンスと、True にしたインスタンスの 2 つのインスタンスを含むリクエストです。
image_truck = f'{BUCKET_URI}/{IMAGE_DIR}/truck.jpg'
box_truck_body = [50, 240, 1740, 870]
request = { 'instances': [
{
'id': 'truck_body_single_mask',
'image': image_truck,
'box': box_truck_body
},
{
'id': 'truck_body_multi_mask',
'image': image_truck,
'box': box_truck_body,
'multimask': True
},
]}
このリクエストに対して、次の構造のレスポンスが得られます。masks と scores は、実際の値ではなく、リストの構造(shape)を示してあります。
[
{
'id': 'truck_body_single_mask',
'masks': (1, 1200, 1800),
'scores': (1,)
},
{
'id': 'truck_body_multi_mask',
'masks': (3, 1200, 1800),
'scores': (3,)
}
]
先に truck_body_multi_mask をの方を見ると、masks と scores の最初の次元が「3」になっており、3 種類の結果が返っていることがわかります。それぞれの結果の中身は、マスク画像(マスク部分が 1、背景部分が 0 になった画像サイズのリスト)と信頼度スコアのスカラー値です。一方、truck_body_single_mask の方は、最初の次元が「1」で、1 種類の結果のみが含まれます。
truck_body_multi_mask の結果を信頼度スコアとあわせてビジュアライズすると、次のようになります。結果は、信頼度スコアの順にソートされているわけではありません。

区画指定による検出結果
物体と背景のポイント指定
区画指定だけで意図通りの検出ができない場合は、区画内の特定の点について「そこは物体に含まれる」「そこは背景に含まれる」という情報が指定できます。先に結果を示すと次のようになります。

物体/背景のポイント指定
上の例では、タイヤ部分とホイール部分の両方がマスクされています。一方、下の例では、ホイール部分の 1 点(青丸で示した部分)に「そこは背景に含まれる」という指定を加えており、結果として、タイヤ部分だけがマスクされています。これらに対応するリクエストは次になります。
box_wheel = [425, 600, 700, 875]
points_wheel_center = [[550, 750]]
labels_wheel_center = [0]
request = { 'instances': [
{
'id': 'wheel_without_points',
'image': image_truck,
'box': box_wheel
},
{
'id': 'wheel_with_points',
'image': image_truck,
'box': box_wheel,
'points': points_wheel_center,
'labels': labels_wheel_center
}
]}
points 要素には、指定する点(x, y 座標)のリスト、labels 要素には、それぞれの点のラベル(0 が背景で、1 が物体)のリストを与えます。
次は、複数の点を指定する例になります。

物体/背景のポイント指定
上の例では、窓ガラスの部分を区画に指定していますが、うまく検出できていません。下の例では、窓ガラスのある 3 箇所の点(赤丸で示した部分)を「物体」に指定しており、こちらはうまく検出できています。これらに対応するリクエストは次になります。
box_windows = [200, 280, 1270, 480]
points_windows = [[460, 380], [760, 380], [1090, 380]]
labels_windows = [1, 1, 1]
request = { 'instances': [
{
'id': 'truck_windows_without_points',
'image': image_truck,
'box': box_windows
},
{
'id': 'truck_windows_with_points',
'image': image_truck,
'box': box_windows,
'points': points_windows,
'labels': labels_windows
},
]}
同様の方法で、複数の「物体」の点と、複数の「背景」の点を同時に指定することもできます。
複数区画の同時指定
box 要素に複数の区画をリストで与えると、それぞれの区画を個別に処理した結果がまとめて得られます。この場合、points 要素と lables 要素は、それぞれの区画に対する指定をまとめたリストになります。具体例を示すと次のようになります。
box_windows_split = [
[200, 280, 650, 470],
[640, 290, 875, 455],
[920, 290, 1270, 465],
]
points_windows_split = [
[[460, 380]],
[[760, 380]],
[[1090, 380]],
]
labels_windows_split = [
[1],
[1],
[1],
]
request = { 'instances': [
{
'id': 'truck_windows_split_with_points',
'image': image_truck,
'box': box_windows_split,
'points': points_windows_split,
'labels': labels_windows_split
}
]}
この例では、3 箇所の窓ガラスに対応した 3 つの区画を指定しており、それぞれの区画において、1 点を「物体」に指定しています。
これに対するレスポンス(masks と scores)は、それぞれの区画に対する結果をまとめたリストになります。
[
{
'id': 'truck_windows_split_with_points',
'masks': (3, 1, 1200, 1800),
'scores': (3, 1)
}
]
それぞれ、最初の次元の「3」は、3 つの区画に対応します。「基本機能」で示した例と比較すると、リストの次元が 1 つ上がっている点に注意してください。結果を 1 枚の画像にまとめて示すと次のようになります。

複数区画の同時指定
この例で、さらに、multimask 要素を True にした場合、それぞれの区画に対して 3 種類の結果が得られます。対応するレスポンスの構造は次のようになります。最初の次元の「3」が区画の数で、次の次元の「3」が各区画における 3 種類の結果です。
[
{
'id': 'truck_windows_split_with_points_multimask',
'masks': (3, 3, 1200, 1800),
'scores': (3, 3)
}
]
モデルのデプロイ手順
このモデルを Vertex AI のオンライン予測サービスにデプロイする手順を説明します。
事前準備
新規プロジェクト作成と API の有効化
新規プロジェクトを作成して、Cloud Shell から次のコマンドを実行していきます。
まず、プロジェクト ID とプロジェクト番号を環境変数に保存します。
PROJECT_ID=$(gcloud config list --format 'value(core.project)')
PROJECT_NUMBER=$(gcloud projects list --filter="PROJECT_ID: $PROJECT_ID" \
--format 'value(PROJECT_NUMBER)')
次に、必要な API を有効化して、Vertex AI サービスエージェントを作成します。
gcloud services enable \
aiplatform.googleapis.com \
notebooks.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
sleep 10
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/$PROJECT_ID/locations/us-central1/endpoints \
-d ""
ストレージバケットとサービスアカウントの作成
最初に説明したように、チェックポイントファイルと画像ファイルをストレージバケットから取得する構成にするので、そのためのストレージバケットを作成します。バケット名 BUCKET と作成リージョン LOCATION は、必要に応じて変更してください。
BUCKET=$PROJECT_ID-sam2
LOCATION=asia-northeast1
gsutil mb -b on -c regional -l $LOCATION gs://$BUCKET
Vertex AI にモデルをデプロイする際は、このバケットにアクセス可能なサービスアカウントを指定する必要があります。そのためのサービスアカウント sam2-serving を作成して、バケットに対する読み取り権限を与えます。
gcloud iam service-accounts create sam2-serving
SERVICE_ACCOUNT=sam2-serving@$PROJECT_ID.iam.gserviceaccount.com
sleep 5
gsutil iam ch serviceAccount:$SERVICE_ACCOUNT:objectViewer gs://$BUCKET
gsutil iam get gs://$BUCKET | \
jq '.bindings[] | select(.role=="roles/storage.objectViewer")'
[出力結果]
Created service account [sam2-serving].
{
"members": [
"serviceAccount:sam2-serving@{PROJECT_ID}.iam.gserviceaccount.com"
],
"role": "roles/storage.objectViewer"
}
上記の出力結果から、サービスアカウント sam2-serving に、バケットに対する roles/storage.objectViewer ロールが割り当てられたことがわかります。
また、次のコマンドで Vertex AI サービスエージェント(service-$PROJECT_NUMBER@gcp-sa-aiplatform.iam.gserviceaccount.com)に、サービスアカウント sam2-serving の管理権限を与えます。
gcloud iam service-accounts add-iam-policy-binding $SERVICE_ACCOUNT \
--role=roles/iam.serviceAccountAdmin \
--member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-aiplatform.iam.gserviceaccount.com
これは、モデルのデプロイ時に、サービスアカウント sam2-serving にサービングに必要な権限を自動設定するために必要になります。
ワークベンチインスタンタンスの作成
この後はノートブック環境で作業するので、Vertex AI ワークベンチのインスタンスを作成します。ローカルでテストできるように GPU(Tesla T4)をアタッチしたインスタンスを使用します。
gcloud workbench instances create sam2-deployment \
--project=$PROJECT_ID \
--location=asia-northeast1-a \
--machine-type=n1-standard-4 \
--accelerator-type=NVIDIA_TESLA_T4 \
--accelerator-core-count=1
クラウドコンソールのナビゲーションメニューから「Vertex AI」→「ワークベンチ」を選択すると、インスタンス sam2-deployment があるので、インスタンスの起動が完了するのを待って、「JUPYTERLAB を開く」をクリックします。
Jupyter Lab の管理画面が表示されるので、ローンチャーから「Terminal」を開きます。すると、下記のメッセージが出るので、「y」で返答して Nvidia ドライバーをインストールします。
This VM requires Nvidia drivers to function correctly. Installation takes ~1 minute.
Would you like to install the Nvidia driver? [y/n]
ドライバーのインストールが完了するのを待ってから、次の作業に進みます。
コンテナイメージの作成とローカルでのテスト
ここからは、ワークベンチのノートブック環境で作業を進めます。Jupyter Lab のローンチャーから「Python 3(ipykernel)」をクリックして新規ノートブックを作成します。そして、この後のコマンドをノートブックで実行していきます。
事前準備
動作確認に必要なパッケージをインストールします。
!pip install opencv-python
インストールしたパッケージを有効にするために、次のコマンドでカーネルを再起動します。
import IPython
app = IPython.Application.instance()
_ = app.kernel.do_shutdown(True)
再起動を確認するポップアップが表示されるので、[Ok] をクリックします。
モデルのレスポンスをビジュアライズする補助関数を定義しておきます。
def show_points(ax, coords, labels):
pos_points = coords[labels==1]
neg_points = coords[labels==0]
ax.scatter(pos_points[:, 0], pos_points[:, 1],
color='red', marker='o', s=40, edgecolor='white', linewidth=0.8)
ax.scatter(neg_points[:, 0], neg_points[:, 1],
color='blue', marker='o', s=40, edgecolor='white', linewidth=0.8)
def show_box(ax, box):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
box_patch = plt.Rectangle((x0, y0), w, h,
edgecolor='red', facecolor=(0, 0, 0, 0), linewidth=2)
ax.add_patch(box_patch)
def show_mask(ax, mask, score, show_score):
color = np.array([30/255, 144/255, 255/255, 0.6])
h, w = mask.shape
mask = mask.astype(np.uint8).reshape(h, w, 1)
mask_image = mask * color.reshape(1, 1, -1)
ax.imshow(mask_image)
if show_score:
m = cv2.moments(mask, False)
x,y = m['m10']/m['m00'] , m['m01']/m['m00']
dic_box = dict(facecolor='white', alpha=0.5, edgecolor='red', linewidth=2)
ax.text(x, y, f'{score:0.3f}', size=11, weight='bold', color='red', bbox=dic_box)
def _show_result(candidate, image, masks, scores,
box, points, labels, show_score):
plt.figure(figsize=(8, 8))
plt.imshow(image)
plt.axis('off')
if len(scores.shape) == 1: # Single box
masks = [masks]
scores = [scores]
for mask, score in zip(masks, scores):
show_mask(plt.gca(), mask[candidate], score[candidate],
show_score=show_score)
if points is not None:
show_points(plt.gca(), points.squeeze(), labels.squeeze())
if box is not None:
if len(box.shape) == 1: # Single box
box = [box]
for one_box in box:
show_box(plt.gca(), one_box)
def show_result(image, masks, scores,
box=None, points=None, labels=None,
show_score=False):
masks = np.array(masks)
scores = np.array(scores)
if points is not None:
points = np.array(points)
if labels is not None:
labels = np.array(labels)
if box is not None:
box = np.array(box)
for i in range(scores.shape[-1]):
_show_result(i, image, masks, scores,
box=box, points=points, labels=labels,
show_score=show_score)
グローバル変数(環境変数)を設定します。バケット BUCKET_URI とリージョン LOCATION は先の手順で指定した値とそろえておいてください。
PROJECT_ID = !gcloud config list --format 'value(core.project)'
PROJECT_ID = PROJECT_ID[-1]
PROJECT_NUMBER = !gcloud projects list --filter='PROJECT_ID: {PROJECT_ID}' \
--format 'value(PROJECT_NUMBER)'
PROJECT_NUMBER = PROJECT_NUMBER[-1]
LOCATION = 'asia-northeast1'
# Storage bucket
BUCKET_URI = f'gs://{PROJECT_ID}-sam2'
CHECKPOINTS_DIR = 'checkpoints'
IMAGE_DIR = 'images'
# Container image repository
REPO_NAME = 'container-image-repo'
IMAGE_NAME = 'sam2'
REPO = f'{LOCATION}-docker.pkg.dev/{PROJECT_ID}/{REPO_NAME}'
必要なモジュールをインポートして、SDK を初期化します。
import os, sys, json
import numpy as np
import matplotlib.pyplot as plt
import cv2
from PIL import Image
from IPython.display import Image as display_image
from google.cloud import aiplatform
aiplatform.init(project=PROJECT_ID, location=LOCATION)
コンテナイメージを保存するリポジトリを作成します。
result = !gcloud artifacts repositories describe \
--location {LOCATION} {REPO_NAME}; echo $?
if int(result[-1]):
!gcloud artifacts repositories create {REPO_NAME} \
--repository-format docker --location {LOCATION}
動作確認に使用する画像ファイルを取得して、ストレージバケットに保存します。
base_url='https://raw.githubusercontent.com/google-cloud-japan/sa-ml-workshop/main/blog/images'
!mkdir -p images
for file in ['truck.jpg', 'coffee.jpg', 'croissant.jpg', 'laptop.jpg']:
!wget -q -O images/{file} {base_url}/{file}
!gsutil -m cp images/* {BUCKET_URI}/{IMAGE_DIR}/
モデルのチェックポイントファイルを取得して、ストレージバケットに保存します。
base_url='https://dl.fbaipublicfiles.com/segment_anything_2/072824'
!mkdir -p checkpoints
for file in ['sam2_hiera_tiny.pt', 'sam2_hiera_small.pt',
'sam2_hiera_base_plus.pt', 'sam2_hiera_large.pt']:
!wget -q -O checkpoints/{file} {base_url}/{file}
!gsutil -m cp checkpoints/* {BUCKET_URI}/{CHECKPOINTS_DIR}/
この時点で、ワークベンチインスタンスのローカル環境には以下のファイルが用意されています。
images/ # 動作確認用の画像ファイル
├── coffee.jpg
├── croissant.jpg
├── laptop.jpg
└── truck.jpg
checkpoints/ # モデルのチェックポイントファイル
├── sam2_hiera_base_plus.pt
├── sam2_hiera_large.pt
├── sam2_hiera_small.pt
└── sam2_hiera_tiny.pt
同じファイルがストレージバケットにも以下のように保存されています。
gs://{PROJECT_ID}-sam2/images/coffee.jpg
gs://{PROJECT_ID}-sam2/images/croissant.jpg
gs://{PROJECT_ID}-sam2/images/laptop.jpg
gs://{PROJECT_ID}-sam2/images/truck.jpg
gs://{PROJECT_ID}-sam2/checkpoints/sam2_hiera_base_plus.pt
gs://{PROJECT_ID}-sam2/checkpoints/sam2_hiera_large.pt
gs://{PROJECT_ID}-sam2/checkpoints/sam2_hiera_small.pt
gs://{PROJECT_ID}-sam2/checkpoints/sam2_hiera_tiny.pt
セグメンテーションモデルはストレージバケットからファイルを取得するので、セグメンテーションモデルを実行する上では、ローカル環境のファイルは不要です。ただし、この後の動作確認では、画像をビジュアライズする際にローカル環境の画像ファイルを使用します。そのため、ローカル環境の画像ファイルはこのまま残しておいてください。
コンテナイメージのビルドに必要なファイルを作成
ここでは、コンテナイメージのビルドに必要となる、以下のファイルをローカル環境に用意します。
build/
├── Dockerfile # コンテナイメージをビルドするための Dockerfile
├── app/
│ ├── main.py # サービング用のモジュールファイル
│ └── prestart.sh # prestart スクリプト
├── gunicorn_conf.py # Gunicorn の設定ファイル
├── requirements.txt # パッケージをインストールするための requirements ファイル
└── start.sh # Gunicron の起動スクリプト(コンテナ起動時に最初に実行)
まずは、これらのファイルを保存するディレクトリを作成します。
!mkdir -p build/app
続いて、サービング用のモジュールファイル build/app/main.py を作成します。
%%writefile build/app/main.py
import json
import os
import tempfile
import traceback
import numpy as np
import torch
import torchvision
from PIL import Image
from google.cloud import storage
from fastapi import FastAPI, Request
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
app = FastAPI()
gcs_client = storage.Client()
is_cuda = torch.cuda.is_available()
print(f'PyTorch version: {torch.__version__}')
print(f'Torchvision version: {torchvision.__version__}')
print(f'CUDA is available: {is_cuda}')
checkpoint = os.environ['CHECKPOINT']
model_cfg_map = {
'sam2_hiera_large.pt': 'sam2_hiera_l.yaml',
'sam2_hiera_base_plus.pt': 'sam2_hiera_b+.yaml',
'sam2_hiera_small.pt': 'sam2_hiera_s.yaml',
'sam2_hiera_tiny.pt': 'sam2_hiera_t.yaml'
}
model_cfg = model_cfg_map[os.path.basename(checkpoint)]
if is_cuda:
torch.autocast(device_type='cuda', dtype=torch.bfloat16).__enter__()
if torch.cuda.get_device_properties(0).major >= 8:
# turn on tfloat32 for Ampere GPUs
# (https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices)
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
device = torch.device('cuda')
else:
device = torch.device('cpu')
print(f'Model config: {model_cfg}')
print(f'Using device: {device}')
with tempfile.NamedTemporaryFile(delete=True) as t:
checkpoint_file = t.name
with open(checkpoint_file, 'wb') as f:
gcs_client.download_blob_to_file(checkpoint, f)
sam2_model = build_sam2(model_cfg, checkpoint_file, device=device)
predictor = SAM2ImagePredictor(sam2_model)
@app.get(os.getenv('AIP_HEALTH_ROUTE', '/health'), status_code=200)
def health():
return {}
@app.post(os.getenv('AIP_PREDICT_ROUTE', '/predict'))
async def predict(request: Request):
debug = os.getenv('DEBUG', False)
body = await request.json()
instances = body['instances']
predictions = []
for item in instances:
if 'id' in item.keys():
instance_id = item['id']
else:
instance_id = None
if 'image' not in item.keys():
predictions.append({
'id': instance_id,
'masks': None,
'scores': None,
'error': 'Field "image" is required.'
})
continue
try:
image_path = item['image']
with tempfile.NamedTemporaryFile(delete=True) as t:
image_file = t.name
with open(image_file, 'wb') as f:
gcs_client.download_blob_to_file(image_path, f)
image = Image.open(image_file)
image = np.array(image.convert('RGB'))
predictor.set_image(image)
input_params = {
'box': None,
'points': None,
'labels': None,
'multimask': False
}
for param in input_params.keys():
if param in item.keys():
if item[param] is not None:
input_params[param] = np.array(item[param])
if debug:
for param in input_params.keys():
print(f'{param}: {input_params[param]}')
masks, scores, _ = predictor.predict(
box=input_params['box'],
point_coords=input_params['points'],
point_labels=input_params['labels'],
multimask_output=input_params['multimask']
)
predictions.append({
'id': instance_id,
'masks': masks.tolist(),
'scores': scores.tolist()
})
except Exception as e:
if debug:
print(traceback.format_exc())
predictions.append({
'id': instance_id,
'masks': None,
'scores': None,
'error': str(e)
})
response = {
'predictions': predictions
}
if debug:
for item in response['predictions']:
for key in sorted(item.keys()):
if key == 'id':
print(f'\nid: {item[key]}')
else:
print(f'- {key}: {np.array(item[key]).shape}')
return response
これが予測処理を実行するメインのモジュールになります。REST API を提供するフレームワークには FastAPI を使用しています。「Vertex AI のオンライン予測サービスについて」で説明したルールに従って、次の条件を満たすように実装している点に注意してください。
- 予測用エンドポイントのパスは環境変数
AIP_PREDICT_ROUTEの値を使用する - ヘルスチェック用エンドポイントのパスは環境変数
AIP_HEALTH_ROUTEの値を使用する - リクエストは
instancesをキーにして、予測対象データのリストを受け取る - レスポンスは
predictionsをキーにして、予測結果のリストを返す
FastAPI を実行するサーバー(Gunicorn)の起動スクリプト build/start.sh と設定ファイル build/gunicorn_conf.py を取得して保存します。
!wget -q -O build/start.sh https://raw.githubusercontent.com/tiangolo/uvicorn-gunicorn-docker/0.8.0/docker-images/start.sh
!wget -q -O build/gunicorn_conf.py https://raw.githubusercontent.com/tiangolo/uvicorn-gunicorn-docker/0.8.0/docker-images/gunicorn_conf.py
prestart スクリプト build/app/prestart.sh を作成します。
%%writefile build/app/prestart.sh
#!/bin/bash
export PORT=$AIP_HTTP_PORT
Gunicorn の起動スクリプト build/start.sh は、この prestart スクリプトを実行した後に、Gunicorn を起動します。ここでは、Gunicorn が環境変数 AIP_HTTP_PORT で指定されるポートを使用するように設定しています。
パッケージの requirements ファイル build/requirements.txt を作成します。
%%writefile build/requirements.txt
google-cloud-storage==2.8.0
uvicorn[standard]==0.20.0
gunicorn==22.0.0
fastapi[all]==0.109.1
numpy==1.24.4
pillow==10.4.0
git+https://github.com/facebookresearch/segment-anything-2.git
--find-links https://download.pytorch.org/whl/torch_stable.html
torch==2.3.1+cu121
torchvision==0.18.1+cu121
Dockerfile build/Dockerfile を作成します。ベースイメージには、Cuda に対応した Nvidia の公式イメージを使用しています。
%%writefile build/Dockerfile
FROM nvidia/cuda:12.6.0-cudnn-runtime-ubuntu22.04
RUN apt-get update && \
apt-get install --no-install-recommends -y curl pip git && \
python3 -m pip --no-cache-dir install --upgrade pip
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
COPY ./gunicorn_conf.py /gunicorn_conf.py
COPY ./start.sh /start.sh
RUN chmod +x /start.sh
COPY ./app /app
WORKDIR /app/
ENV PYTHONPATH=/app
EXPOSE 80
CMD ["/start.sh"]
これでコンテナイメージをビルドする準備ができました。
ローカル環境でのテスト
まずは、ワークベンチインスタンスのローカル環境でコンテナを作成・起動して動作確認を行います。次のコマンドでコンテナイメージをビルドします。
!pushd build; docker build . --tag {REPO}/{IMAGE_NAME}-local; popd
ビルドしたイメージを使って、ローカル環境でコンテナを起動します。
!docker run -d -p 80:8080 \
--gpus all \
--name=sam2-local \
-e AIP_HTTP_PORT=8080 \
-e CHECKPOINT={BUCKET_URI}/{CHECKPOINTS_DIR}/sam2_hiera_large.pt \
-e DEBUG=1 \
-e GRACEFUL_TIMEOUT=300 \
-e TIMEOUT=300 \
'{REPO}/{IMAGE_NAME}-local'
環境変数 CHECKPOINT では、先に取得したチェックポイントファイルの 1 つを指定します。指定するファイルによって、使用するモデルのサイズが変わります。ここでは、Large モデルを指定しています。
また、GRACEFUL_TIMEOUT と TIMEOUT は、Gunicorn に設定するタイムアウト値(秒)です。この時間内にレスポンスを返せない場合はプロセスに異常が生じたと判断されますので、モデルの処理時間に応じて設定してください。
コンテナの起動が完了するのを 1 分ほど待ってから次に進みます。
ヘルスチェック API の応答を確認します。次のように {} が返れば問題ありません。
!curl -q -s localhost/health
[出力結果]
{}
コンテナのログ出力から、CUDA が有効になっていることを確認します。
!docker logs sam2-local 2>&1 | grep 'CUDA is available'
[出力結果]
CUDA is available: True
ローカルの API にリクエストを送信して、レスポンスを取得する補助関数を定義します。
def send_request_local(request):
with open('request.json', 'w') as f:
json.dump(request, f)
!curl -s -X POST \
-d @request.json \
-H "Content-Type: application/json; charset=utf-8" \
localhost/predict > response.json
with open('response.json', 'r') as f:
response=json.loads(f.read())
for item in response['predictions']:
for key in sorted(item.keys()):
if key == 'id':
print(f'\nid: {item[key]}')
else:
print(f'- {key}: {np.array(item[key]).shape}')
print()
return response
サンプル画像を使って、リクエストを送信します。
%%time
image_laptop = f'{BUCKET_URI}/{IMAGE_DIR}/laptop.jpg'
box_laptop = [280, 400, 1380, 1170]
request = { 'instances': [
{
'id': 'laptop',
'image': image_laptop,
'box': box_laptop,
},
]}
response_laptop = send_request_local(request)
[出力結果]
id: laptop
- masks: (1, 1487, 2230)
- scores: (1,)
CPU times: user 811 ms, sys: 108 ms, total: 919 ms
Wall time: 13.6 s
上記の出力結果では、レスポンスに含まれる masks と scores のデータ構造(リストの shape)が表示されています。
レスポンスからマスクと信頼度スコアを取り出して、画像表示します。
masks = response_laptop['predictions'][0]['masks']
scores = response_laptop['predictions'][0]['scores']
image = Image.open('images/laptop.jpg')
show_result(image, masks, scores, box=box_laptop, show_score=True)
次のような結果が表示されます。

ローカルテストの実行結果
なお、これらのテストを実行する際は、Jupyter Lab のターミナルで次のコマンドを実行すると、コンテナのログ出力がモニタリングできます。
docker logs -f sam2-local
ローカルテストが完了したら、次のコマンドでコンテナを停止します。
!docker stop sam2-local
!docker rm sam2-local
サービング環境の構成
ローカルでの動作確認ができたので、Vertex AI にデプロイして、API サービスとして利用できるようにします。この後のコマンドも、先ほどのノートブックで続けて実行していきます。
コンテナイメージのビルド
Cloud Build を使用して、クリーンな環境でコンテナをビルドします。
!pushd build; gcloud builds submit . --tag {REPO}/{IMAGE_NAME}; popd
ビルド処理には 30 分程度かかるので、少し気長にお待ちください。ビルドされたイメージは、手順の最初に作成したリポジトリに保存されます。
モデルの登録とデプロイ
ビルドしたイメージを Vertex AI のモデルレジストリにアップロードして、モデルとして登録します。
model = aiplatform.Model.upload(
display_name='sam2-large',
serving_container_image_uri=f'{REPO}/{IMAGE_NAME}',
serving_container_environment_variables={
'CHECKPOINT': f'{BUCKET_URI}/{CHECKPOINTS_DIR}/sam2_hiera_large.pt',
'GRACEFUL_TIMEOUT': '300',
'TIMEOUT': '300',
},
)
serving_container_environment_variables オプションでは、コンテナを起動する際に設定する環境変数の値を指定します。ここでは、チェックポイントファイルを指定する CHECKPOINT と、Gunicorn に設定するタイムアウト値 GRACEFUL_TIMEOUT と TIMEOUT を指定しています。
モデルが登録されると、次のようなメッセージが表示されます。
...
To use this Model in another session:
model = aiplatform.Model('projects/{PROJECT_NUMBER}/locations/asia-northeast1/models/{MODEL_ID}@{VERSION}')
今、変数 model には、登録されたモデルのオブジェクトが入っていますが、同じオブジェクトを再取得する際は、メッセージに示されたコマンド(model = aiplatform.Model(...)を実行します。
この後は、エンドポイントを作成して、登録したモデルをデプロイすると、API サービスとして利用可能になります。まずは、次のコマンドでエンドポイントを作成します。
endpoint = aiplatform.Endpoint.create(
display_name='sam2-large-endpoint',
project=PROJECT_ID,
location=LOCATION
)
エンドポイントが作成されると、次のようなメッセージが表示されます。
...
To use this Endpoint in another session:
endpoint = aiplatform.Endpoint('projects/{PROJECT_NUMBER}/locations/asia-northeast1/endpoints/{ENDPOINT_ID}')
今、変数 endpoint には、作成されたエンドポイントのオブジェクトが入っていますが、同じオブジェクトを再取得する際は、メッセージに示されたコマンド(endpoint = aiplatform.Endpoint(...)を実行します。
続いて、エンドポイントにモデルをデプロイします。
model.deploy(
endpoint=endpoint,
deployed_model_display_name='sam2-large',
service_account=f'sam2-serving@{PROJECT_ID}.iam.gserviceaccount.com',
machine_type='n1-standard-4',
min_replica_count=1,
max_replica_count=1,
accelerator_type='NVIDIA_TESLA_T4',
accelerator_count=1
)
service_account オプションで、最初に作成したサービスアカウント sam2-serving を指定する点に注意してください。
マシンタイプやオートスケールの設定は、必要に応じて変更してください。ここでは、ハードウェアアクセラレーターに Tesla T4 を使用して、オートスケールの範囲を 1 ノードに限定しています。
モデルのデプロイが完了するまで、20分〜30分程度かかるので、気長にお待ちください。
API サービスの利用例
モデルのデプロイが完了すると、エンドポイントのオブジェクトを介して API サービスが使用できます。ここでは、冒頭で紹介したコーヒーカップをマスクする例を試してみます。
次のようにリクエストを構成します。コーヒーの液面部分にもマスクをかけるように、「物体」のポイントを 1 つ指定しています。
image_coffee = f'{BUCKET_URI}/{IMAGE_DIR}/coffee.jpg'
box_coffee = [920, 430, 1870, 1400]
points_coffee = [[1160, 665]]
labels_coffee = [1]
request = { 'instances': [
{
'id': 'coffee',
'image': image_coffee,
'box': box_coffee,
'points': points_coffee,
'labels': labels_coffee
}
]}
次のコマンドでリクエストを送信します。instances 要素の中身(インスタンスを並べたリスト部分)だけを送信する点に注意してください。
response = endpoint.predict(instances=request['instances'])
response の predictions 要素から予測結果が得られます。次のコマンドで、得られた結果のデータ構造を確認します。
for item in response.predictions:
for key in sorted(item.keys()):
if key == 'id':
print(f'id: {item[key]}')
else:
print(f'- {key}: {np.array(item[key]).shape}')
[出力結果]
id: coffee
- masks: (1, 1487, 2230)
- scores: (1,)
得られた結果を画像表示します。
masks = response.predictions[0]['masks']
scores = response.predictions[0]['scores']
image = Image.open('images/coffee.jpg')
show_result(image, masks, scores, box=box_coffee,
points=points_coffee, labels=labels_coffee,
show_score=True)
次のような結果が表示されます。

API サービスによる予測結果
クリーンアップ
モデルをデプロイしたままにすると課金が継続するので、エンドポイントからモデルをアンデプロイして、エンドポイントを削除しておきます。
endpoint.undeploy_all()
endpoint.delete()
おまけ:GUI ツールのサンプル
ノートブック上で利用できるツール
今回の手順では、JSON 形式のリクエストを手動で用意した上で API サービスに送信しましたが、処理対象の区画と「物体/背景」のポイントを GUI で指定できるフロントエンドを用意すればより便利に使えるでしょう。ここでは、ワークベンチのノートブック上で利用できる簡易的な GUI ツールのサンプルコードを紹介しておきます。
はじめに、これまでの作業に使用したノートブック上で次のコードを実行します。
from IPython.display import HTML, display, Javascript
from PIL import Image
def show_canvas(image_file, width=600):
image = Image.open(image_file)
w, h = image.width, image.height
ratio = w / width
height = h // ratio
ui_html = f'''
<html>
<body>
<div hidden><img id="image" src="{image_file}" width="{width}"></div>
<canvas id="myCanvas" width="{width}" height="{height}"
style="border:20px solid gray"></canvas>
<div>
<input id="Clear" type="button" value="Clear" />
<input id="Box" type="button" value="Box" />
<input id="Object" type="button" value="Object" />
<input id="Background" type="button" value="Background" />
<input id="Output" type="button" value="Output" />
<span id="message"></span>
</div>
<textarea id="text" cols="80" rows="5"></textarea>
</body>
</html>
'''
js = f'''
const [imageWidth, imageHeight, ratio] = [{width}, {height}, {ratio}];
'''
js += '''
let dataset = {'box': [0, 0, 0, 0], 'points': [], 'labels': []};
let [mode, isDrawing, init] = ['box', false, true];
let startX, startY;
const canvas = document.getElementById('myCanvas');
const ctx = canvas.getContext('2d');
const img = document.getElementById('image');
const outputText = document.getElementById('text');
drawCanvas();
const clear = document.getElementById('Clear');
clear.addEventListener('click', (e) => {
dataset.box = [0, 0, 0, 0];
dataset.points = [];
dataset.labels = [];
mode = 'box';
drawCanvas();
outputText.innerHTML = '';
});
const box = document.getElementById('Box');
box.addEventListener('click', (e) => { mode = 'box'; drawCanvas();});
const fg = document.getElementById('Object');
fg.addEventListener('click', (e) => { mode = 'fg'; drawCanvas();});
const bg = document.getElementById('Background');
bg.addEventListener('click', (e) => { mode = 'bg'; drawCanvas();});
const output = document.getElementById('Output');
output.addEventListener('click', (e) => { output_value(); });
function drawCanvas() {
const [x1, y1, x2, y2] = dataset.box;
ctx.drawImage(img, 0, 0, imageWidth, imageHeight);
if(x1 != 0 | y1 != 0 | x2 != 0 | y2 != 0) {
[ctx.strokeStyle, ctx.lineWidth] = ['Red', 2];
ctx.strokeRect(x1, y1, x2-x1, y2-y1);
}
for (let i=0; i<dataset.points.length; i++) {
const [x, y] = dataset.points[i];
const label = dataset.labels[i];
if (label == 0) [ctx.strokeStyle, ctx.fillStyle] = ['White', 'Blue'];
if (label == 1) [ctx.strokeStyle, ctx.fillStyle] = ['White', 'Red'];
ctx.lineWidth = 1;
ctx.beginPath();
ctx.arc(x, y, 4, 0, 2 * Math.PI);
ctx.stroke();
ctx.closePath();
ctx.fill();
}
let message;
const messageText = document.getElementById('message');
if (mode == 'box') message = 'Set box';
if (mode == 'fg') message = 'Set object points';
if (mode == 'bg') message = 'Set background points';
if (init) {
message = 'Push [Clear] to show image.';
init = false;
}
messageText.innerHTML = message;
}
function output_value() {
const [x1, y1, x2, y2] = dataset.box.map((x) => {return Math.floor(x * ratio)});
const boxText = 'box = [' + [x1, y1, x2, y2].toString() + ']';
const [points, labels] = [[], []];
for (let i=0; i<dataset.points.length; i++) {
const [x, y] = dataset.points[i];
const label = dataset.labels[i];
const [xx, yy] = [Math.floor(x * ratio), Math.floor(y * ratio)];
points.push('[' + [xx, yy].toString() + ']');
labels.push(label.toString());
}
const pointsText = 'points = [' + points.toString() + ']';
const labelsText = 'labels = [' + labels.toString() + ']';
const data = boxText + '
' + pointsText + '
' + labelsText;
outputText.innerHTML = data;
}
canvas.addEventListener('click', (e) => {
if (mode == 'fg') {
dataset.points.push([e.offsetX, e.offsetY]);
dataset.labels.push(1);
drawCanvas();
}
if (mode == 'bg') {
dataset.points.push([e.offsetX, e.offsetY]);
dataset.labels.push(0);
drawCanvas();
}
});
canvas.addEventListener('mousedown', (e) => {
if (mode != 'box') return;
isDrawing = true;
[startX, startY] = [e.offsetX, e.offsetY];
if (startX < 0) startX = 0;
if (startY < 0) startY = 0;
if (startX > imageWidth) startX = imageWidth;
if (startY > imageHeight) startY = imageHeight;
});
canvas.addEventListener('mouseup', () => {
isDrawing = false;
});
canvas.addEventListener('mousemove', (e) => {
if (mode != 'box' | !isDrawing) return;
let [currentX, currentY] = [e.offsetX, e.offsetY];
if (currentX < 0) currentX = 0;
if (currentY < 0) currentY = 0;
if (currentX > imageWidth) currentX = imageWidth;
if (currentY > imageHeight) currentY = imageHeight;
const [x1, y1] = [Math.min(startX, currentX), Math.min(startY, currentY)]
const [x2, y2] = [Math.max(startX, currentX), Math.max(startY, currentY)]
dataset.box = [x1, y1, x2, y2]
drawCanvas();
});
'''
display(HTML(ui_html))
return js
続いて、次のコマンドを実行します。変数 image には作業対象の画像ファイルを指定します。オプション width で画面表示のサイズ(横幅)が指定できます。
image = 'images/croissant.jpg'
Javascript(show_canvas(image, width=600))
次のようなツールが表示されて、ノートブックの画面上で使用できます。
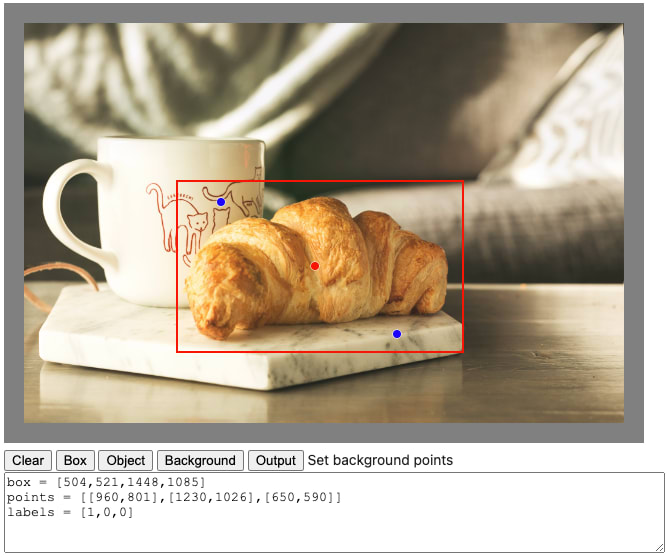
ノートブックで使用する簡易 GUI ツール
コマンド実行直後は画像が表示されていないので、はじめに [Clear] をクリックすると画像が表示されます。その後、次のボタンでモードを切り替えながら、処理対象の区画と「物体/背景」のポイントを指定します。
- [Box]:処理対象区画の長方形を描きます。
- [Object]:「物体」を表す点を指定します。(赤丸で表示)
- [Background]:「背景」を表す点を指定します。(青丸で表示)
指定できる処理対象の区画は 1 つだけです。最初からやり直す場合は、[Clear] をクリックします。
最後に [Output] をクリックすると、下のテキストボックスに、box、points、labels の各要素に対応したリストをセットするコマンドが表示されます。これをコピペして利用してください。上図のクロワッサン画像の例であれば、次のようにリクエストを構成・送信することができます。
image = f'{BUCKET_URI}/{IMAGE_DIR}/croissant.jpg'
#### この部分にコピペしたコードを挿入する
box = [504,521,1448,1085]
points = [[960,801],[1230,1026],[650,590]]
labels = [1,0,0]
####
request = { 'instances': [
{
'id': 'croissant',
'image': image,
'box': box,
'points': points,
'labels': labels
}
]}
response = endpoint.predict(instances=request['instances'])
背景消去アプリケーションのサンプル
この記事で紹介した方法を応用して作成した、画像の背景を消去するサンプルアプリケーションを GitHub のリポジトリで公開しています。デプロイ手順は、下記の README を参照してください。
まとめ
この記事では、画像セグメンテーションモデル(SAM 2)を Vertex AI のオンライン予測サービスにデプロイして、API サービスとして利用する手順を紹介しました。ノートブック上で利用できる簡易的な GUI ツールも紹介しましたが、フロントエンド実装が得意な方は、ぜひ、より本格的な画像処理ツールとして完成させてください。
なお、今回の実装では、モデルが予測したマスクデータをそのままの形で返却していますが、画像サイズが大きくなるとマスクデータのサイズも大きくなるため、レスポンスの受信に時間がかかるようになります。また、レスポンスサイズの上限でエラーになる可能性もあります。実際の所、API のレスポンス時間の大部分は、サーバーからクライアントへのマスクデータの送信処理にかかっていますので、この点については、マスクデータを圧縮して返却するなどの工夫の余地がありそうです。
サービング用のモジュールファイル build/app/main.py は比較的シンプルな構成ですので、これをカスタマイズするのはそれほど難しくはないでしょう。さらにまた、このモジュールの内容を変更すれば、その他の予測モデルをサービングすることも可能です。
今回実装したモジュールファイル build/app/main.py の内容、および、ビジュアライズ用の補助関数については、下記のノートブックを参考にしています。
SAM 2 の詳細については、公式リポジトリの README.md を参考にしてください。

Discussion