
この記事は Google Cloud Japan Advent Calendar 2022 の「今から始める Google Cloud」編の 10 日目の記事です。
TL;DR
- 新しいデータベースサービス AlloyDB for PostgreSQL が一般公開されました
- 手元の PostgreSQL のデータを AlloyDB へ移行したい方のために、移行手法をご紹介
はじめに
2022 年 5 月に Google I/O にて発表された、Google AlloyDB for PostgreSQL について先日とうとう一般提供 (GA) が開始されました!
参考ブログ:AlloyDB for PostgreSQL の一般提供開始を発表
可用性 SLA も当初の案内通り、メンテナンスを含めた 99.99% が適用されるようになります。
一般提供直前には、リージョンをまたいだレプリケーションを可能とする クロスリージョン レプリケーション やワークロードを監視してインデックスを推奨する インデックス アドバイザー といった機能も追加され、ますます魅力的なサービスとなりました。
AlloyDB for PostgreSQL の特徴を短くご紹介すると、下記のようなメリットのあるサービスです。
- PostgreSQL 完全互換: 機能が充実しており、Oracle Database などの商用データベースからオープンソース データベースへの移行先として人気が高まっている、PostgreSQL との完全互換性を備えている
- トランザクション性能: ストレージ層へクラウドネイティブなインテリジェントストレージを導入することで、トランザクション処理で標準的な PostgreSQL と比較して 4 倍以上高速になる
- 分析クエリ性能: 列指向キャッシュを含むカラム型エンジンの導入により、標準的な PostgreSQL と比較して、分析クエリで最大 100 倍の高速化を実現できていることを確認している
- 可用性: メンテナンスも含めて 99.99% の可用性 SLA が設定されており、リージョンごとに高い可用性を期待できます。
- 管理性: ストレージの自動プロビジョニング、アダプティブ オートバキュームなどのオートパイロット システムにより、データベースの管理が容易になる。
今回の記事では、「AlloyDB へ手元のデータベースを早速移行してみたい!」という方のために、利用できる移行手法をいくつか紹介したいと思います。
AlloyDB への移行手法
AlloyDBの移行手法については 公式ドキュメント に案内がありますが、移行ツールとして大きく分けて、手動移行のための2つのツールと、Database Migration Service が紹介されています。
- 手動ツール
a. \COPY コマンド
b. pg_dump / pg_restore ツール - Database Migration Service
これらのツールの特徴を表にしてみました。
| ツール | 移行単位 | 移行元と移行先のネットワーク通信 | 継続的レプリケーション (CDC) | 移行によるダウンタイム |
|---|---|---|---|---|
| \COPY コマンド | テーブル | 不要 | 不可 | 長め |
| pg_dump / pg_restore ツール | データベース | 不要 | 不可 | 長め |
| Database Migration Service | 全データベース | 必要 | 可能 | 短い |
\COPY コマンド や pg_dump / pg_restore ツール は PosegreSQL 標準のツールです。これらのツールを使う場合、一度移行データをファイル出力し、移行先においてファイルをインポートする形式となるため、ファイルの受け渡しができれば移行元と移行先の間の直接のネットワーク通信は不要となります。しかしながらファイル出力された後に、移行元データベースで更新されたデータは、移行先へは反映されないという問題があり、最新の更新データまで移行する必要がある場合には、移行中は移行元データベースへの更新を止める必要があります。
Database Migration Service は、継続的レプリケーション (CDC) による移行を簡単な設定で行え、無料で利用できる、Google Cloud の移行サービスです。移行先データベースとして、AlloyDB へも対応(2022 年 12 月時点ではプレビュー段階)しています。CDC により、データの移行後も、移行元データベースの更新を継続的に移行先へ反映します。その分移行元と移行先のネットワーク通信の設定や、移行元における追加での設定が必要となりますが、移行時にデータベースの更新を止めなければならない時間を短く出来る利点があります。

今回の環境
それでは、ここから実際の手順を見てみましょう。
今回は Compute Engine 上の PostgreSQL を AlloyDB へ移行する手順を参考例として、紹介します。

移行元データベースとして、今回は Compute Engine 上で稼働している、PostgreSQL サーバを利用します。環境の OS / DB のバージョンは下記です。
| Component | Type | Version |
|---|---|---|
| OS | Debian | 11.6 |
| DB | PostgreSQL | 13.9 |
\COPY コマンド
-
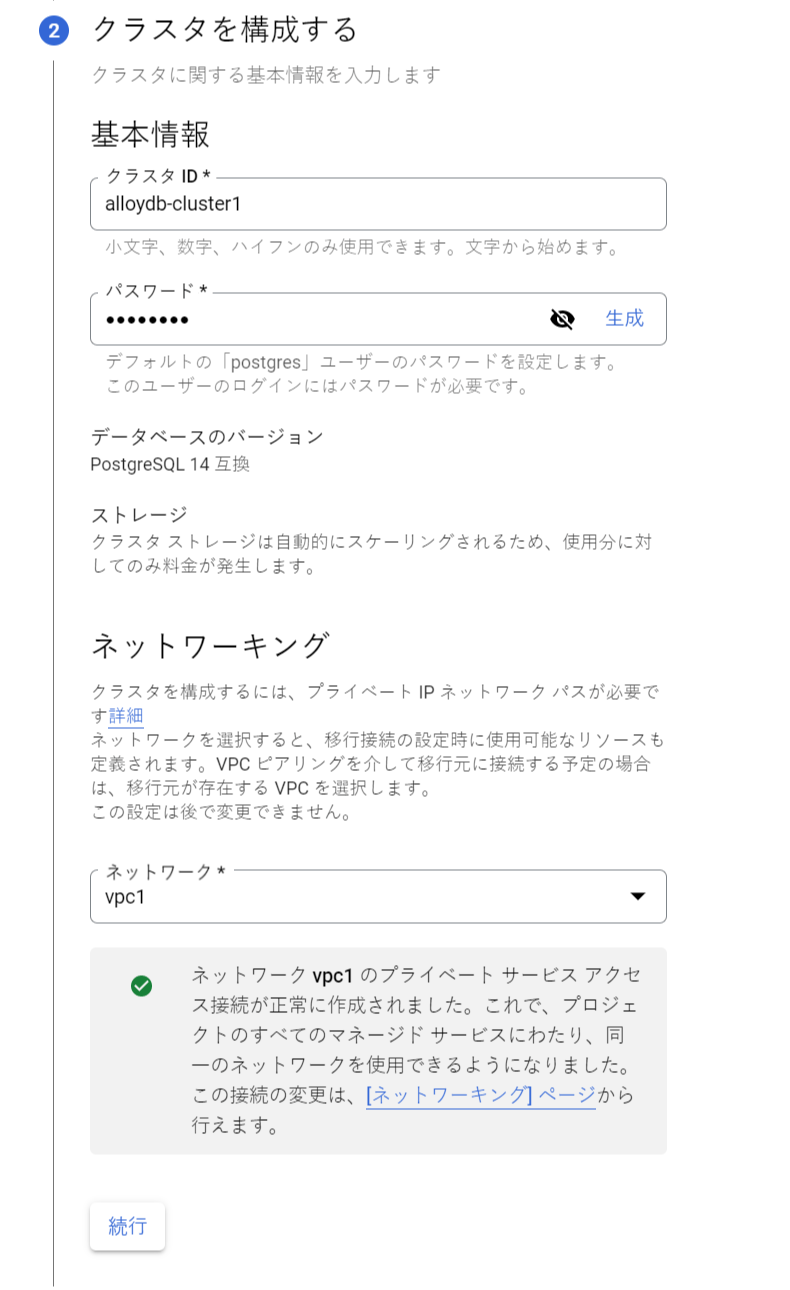
移行先となる AlloyDB クラスタとプライマリインスタンスを作成
-
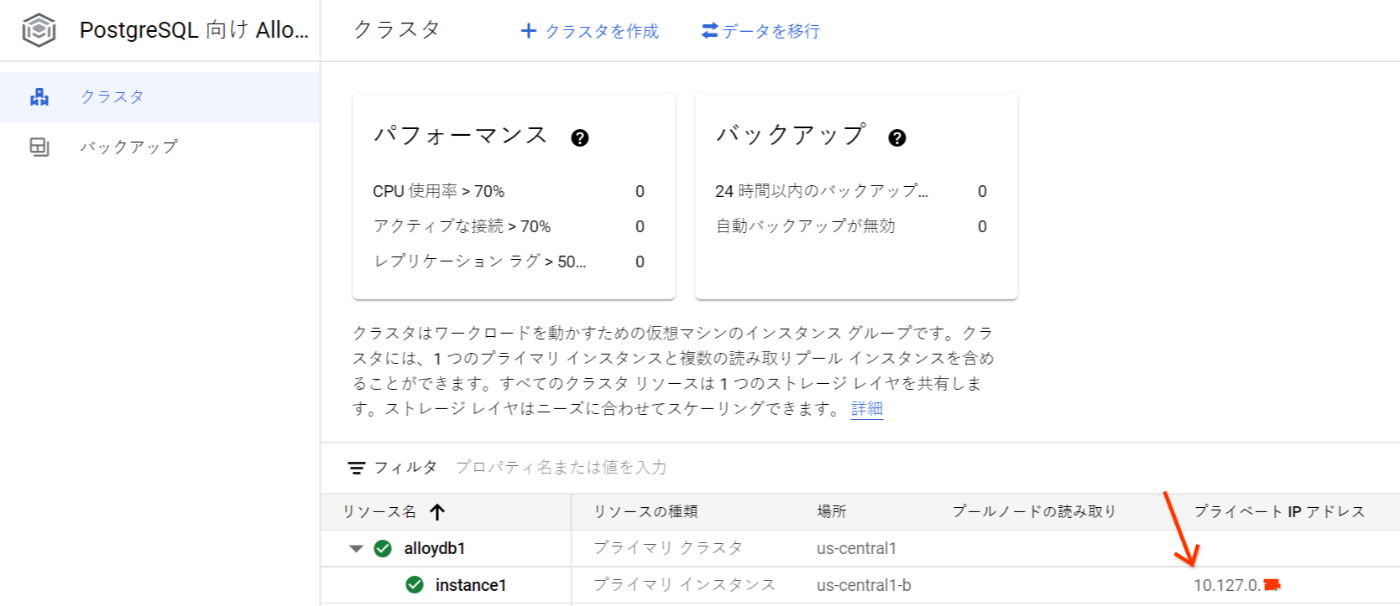
作成したプライマリインスタンスのIPアドレスを確認

-
ソースデータベースの Compute Engine へ SSH接続
-
対象のデータベース (例: mydb ) へ psql コマンドで接続
$ psql -U postgres mydb
- テーブル (例:t1 ) のデータを \COPY コマンドにより CSV ファイル出力
-- 対象テーブルを確認
mydb=> SELECT * FROM t1;
no | text
----+-------
1 | text1
2 | text2
(2 rows)
-- CSVファイルを出力
mydb=> \copy t1
TO 't1.csv'
WITH DELIMITER ','
CSV HEADER
;
COPY 2
mydb=> quit
# CSVファイル出力を確認
$ cat t1.csv
no,text
1,text1
2,text2
- AlloyDB (例: IPアドレス 10.127.0.xxx) へ psql コマンドで接続 する
$ psql -h 10.127.0.xxx -U postgres
- CSV ファイルを、目的のテーブル (例:mydb データベースの t1 テーブル ) へインポート
-- mydb データベースを作成し、接続
postgres=> create database mydb;
CREATE DATABASE
postgres=> \c mydb
You are now connected to database "mydb" as user "postgres".
-- t1 テーブルを作成
mydb=> create table t1 (no int, text varchar(60));
CREATE TABLE
-- t1 テーブルへ CSV ファイルをインポート
mydb=> \copy t1(no, text)
FROM 't1.csv'
DELIMITER ','
CSV HEADER
;
COPY 2
mydb=> select * from t1;
no | text
----+-------
1 | text1
2 | text2
(2 rows)
pg_dump / pg_restore ツール
pg_dump では、DMP や SQL など出力ファイル形式を選べますが、今回の例では DMP 形式で出力し、pg_restore でインポートをする手順を紹介します。
- 移行先となる AlloyDB クラスタとプライマリインスタンスを作成
- 作成したプライマリインスタンスのIPアドレスを確認
- 移行元データベースの Compute Engine へ SSH接続 する
- 対象のデータベース (例: mydb ) を pg_dump ツールでファイル出力
# データベース内のテーブルを確認
$ psql -h localhost -U postgres mydb -c "\dt"
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------
public | t1 | table | postgres
(1 row)
# DMP ファイル出力
$ pg_dump -h localhost -U postgres -F custom \
mydb > mydb.dmp
# DMP ファイル出力を確認
$ ls mydb.dmp
mydb.dmp
- DMP ファイルを AlloyDB (例: IPアドレス 10.127.0.xxx) の目的のデータベース (例: mydb ) へインポート
# mydb データベースを作成
$ psql -h 10.127.0.xxx -U postgres -c "create database mydb;"
# EXTENSION ステートメントを除いた、TOC ファイルを作成
$ pg_restore \
-l mydb.dmp | sed -E 's/(.* EXTENSION )/; \1/g' > mydb.toc
# TOC ファイルをインポート
$ pg_restore -h 10.127.0.xxx -U postgres \
-d mydb \
-L mydb.toc \
mydb.dmp
# インポート結果の確認
$ psql -h 10.127.0.xxx -U postgres mydb -c "\dt"
Password for user postgres:
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------
public | t1 | table | postgres
(1 row)
Database Migration Service
移行元データベースの設定
Database Migration Service では、継続的なレプリケーション 機能を有効化するために、移行元データベースにおいて いくつかの設定 が必要となります。
- postgres データベースの確認
$ psql -U postgres -c "\l postgres"
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
----------+----------+----------+---------+---------+-------------------
postgres | postgres | UTF8 | C.UTF-8 | C.UTF-8 |
(1 row)
- pglogical パッケージのインストール
Database Migration Service 利用のために、pglogical パッケージのインストール が必要となります。
pglogical をインストールするためには、まず PosegreSQL がインストールされている OS 上へ、パッケージを導入します。インストール手順は こちらのサイト の Installation に詳細な記載がありますが、OS とPosegreSQL バージョンに依存する点に、注意が必要です。
$ sudo apt-get install postgresql-13-pglogical
パッケージ導入後は、PostgreSQL configファイルを修正し、PostgreSQL の再起動を行います。
# PostgreSQL configファイルを修正
$ cd /etc/postgresql/13/main/
$ sudo cp -p postgresql.conf postgresql.conf.tmp
$ sudo vi postgresql.conf
# 下記を追加
wal_level = logical
wal_sender_timeout = 0
shared_preload_libraries = 'pglogical'
# PostgreSQL を再起動
$ sudo systemctl restart postgresql
- 各データベースへのpglogical 拡張の追加
$ psql -U postgres
postgres=> CREATE EXTENSION IF NOT EXISTS pglogical;
CREATE EXTENSION
postgres=> \c mydb
You are now connected to database "mydb" as user "postgres".
mydb=> CREATE EXTENSION IF NOT EXISTS pglogical;
CREATE EXTENSION
- DMSで利用するユーザの権限を設定
mydb=> ALTER USER postgres with REPLICATION;
ALTER ROLE
その他、DMS で利用するユーザーは、パスワードでログイン出来ることを確認しましょう。
認証方式の設定は pg_hba.conf ファイルにて行います。
接続プロファイルの作成
DMS が移行元データベースへ接続する際の情報を、プロファイルとして作成します。
- Connection profile ページにて、[プロファイルの作成] を選択
- 接続情報を入力し、[作成] を選択

ユーザー名が “posetgres” となっていますが、”postgres” の誤りです
移行ジョブの作成、開始
移行ジョブを作成 し、実際の移行を開始します。
-
移行ジョブ ページにて、[移行ジョブを作成] を選択
-
移行ジョブの説明情報を入力し、[保存して続行] を選択

-
移行元の定義では、先程作成した接続プロファイルを入力し、[保存して続行] を選択

ユーザー名が “posetgres” となっていますが、”postgres” の誤りです -
宛先の作成にて、移行先 AlloyDB クラスタとプライマリインスタンスを作成するための、情報を入力


-
接続方法 を選択。今回の例の構成では、”VPC ピアリング” が該当。裏で AlloyDB クラスタの作成が開始されており、完了すると次の項目へ進める

-
移行ジョブのテストでは、[ジョブをテスト] を選択し、ソースデータベースへの接続状況や、前提となる設定が完了しているかを確認する

-
移行ジョブのテストが無事に通ったら、[ジョブを作成して開始] を選択して、移行ジョブを開始

移行ジョブのステータス確認
移行ジョブ ページから、ジョブのステータス を確認し、実行状況を確認します。
下記のように “CDC の処理中”と表示されていれば、初期のデータロードが完了し、継続的なレプリケーションが行われている状況です。

試しに AlloyDB インスタンスへ接続して、データが反映されているかを確認してみましょう。
( AlloyDB インスタンスのIPアドレスは クラスター ページにて確認できます。 )

$ psql -h 10.127.0.yyy -U postgres mydb -c "select * from t1;"
no | text
----+-------
1 | text1
2 | text2
(2 rows)
また移行元データベースへ挿入されたデータが、AlloyDB へ反映されることも確認してみます。
# 移行元データベースへデータを挿入
$ psql -U postgres mydb -c "insert into t1 values (3, 'text3');"
INSERT 0 1
# 挿入されたデータは、AlloyDBへも反映されている
$ psql -h 10.127.0.yyy -U postgres mydb -c "select * from t1;"
no | text
----+-------
1 | text1
2 | text2
3 | text3
(3 rows)
AlloyDB のプロモーション
AlloyDB の利用を開始する前には、プロモーションを行います。
プロモーションが行われると、継続的なレプリケーションが停止し、移行ジョブ配下で稼働していた AlloyDB は独立したクラスタとして利用できるようになります。
-
移行元データベースの更新を停止します
-
移行ジョブ ページにて、対象の移行ジョブを選択

-
レプリケーションの遅延を確認。継続的なレプリケーションは一定の遅延を伴って行われるため、遅延が移行元データベースの最終更新データが反映される範囲に収まっていることを確認

-
[プロモート] を選択
-
プロモートの完了を確認

まとめ
今回は新データベースサービス AlloyDB への移行手法について、紹介しました。
AlloyDB にご興味を持たれているみなさまにとって、こちらの記事が AlloyDB をご利用いただく際のご参考となっていれば幸いです。

Discussion