はじめに
変化が起きない時代よりも変化の激しい時代の方が面白いと感じているAIエンジニアです。
歴史的に見ると変化のスパン(感覚や周期)はどんどん短くなっているらしいです。
なかなか良い時代を生きている気がします。
取り残されないように注意しつつ、楽しんでいきたいと思います。
さて、生成AI活用に関するセミナーで開発用の設計を作成するツールを見て衝撃を受けました。
無性に作りたくなったのでアプリ開発の勉強をしつつ作ってみた、という感じの記事です。
フロントエンドはReact + TypeScriptを触って半年程度、バックエンドは初挑戦レベルの人の記事です。
私はGPTのAPI登録をしていないので、ローカルPCで動くLLMを使用します。
有償のAPI登録をしている方はバックエンドの生成部分でAPIを呼び出すことでより快適に利用できると思います。
LLMをローカルで動かしてみたい方や、フロントエンド・バックエンド両方に挑戦したい方には参考になると思います。
やりたい事
やりたいことはシンプルで
人(ユーザー)が設計の概要を入力したら、設計の詳細と処理の流れを作図するツールを作成することです。
デモ動画・完成イメージ
使用技術
使用技術と選定理由を以下にまとめます。
| 区分 | 使用技術 | 選定理由 |
|---|---|---|
| フロントエンド | React + TypeScript | ・業界標準の技術 ・保守性も含めた開発のしやすさ |
| バックエンド | Python(FastAPI) | ・LLMライブラリとの親和性 |
ディレクトリ構成
GPTに何個かアイディアを貰ったのですが、フロントエンドとバックエンドを分けて開発できるという利点を考慮し以下の構成を採用しました。
フロントエンドのコンポーネントはcomponents
バックエンドの本質的な処理の部分はservices
にまとめています。
app_name/
├── frontend/ # フロントエンド(React)
│ ├── src/ # アプリのコード(UI、設計の入力画面、mermaid図プレビューなど)
│ │ ├── components/ # 再利用可能なUIコンポーネント
│ │ ├── utils/ # 汎用ユーティリティ関数
│ │ ├── App.tsx # アプリエントリポイント
│ │ ├── index.tsx # Appのエクスポート用
│ │ └── styles.ts # Appのスタイル定義
│ ├── public/ # 静的ファイル(HTML, CSS, 画像など)
│ │ └── index.html # ReactのHTMLエントリー
│ └── config/ # フロントエンド用設定(環境設定、ビルド設定)
│
├── backend/ # バックエンド(APIサーバーなど)
│ ├── models/ # LLMファイル(.gguf等)
│ ├── lib/ # llama.cppなど外部バイナリ
│ ├── src/ # サーバーコード(データの処理、APIロジック)
│ │ ├── api/ # APIルーティング定義(APIRouterでエンドポイントをまとめる)
│ │ ├── controllers/ # コントローラー層(リクエストごとの処理)
│ │ ├── services/ # ビジネスロジック層
│ │ ├── models/ # PydanticモデルやDBモデル
│ └── config/ # バックエンド設定(DB接続設定、APIキーなど)
│
└── README.md # プロジェクト全体の概要
コンポーネント設計の方針
スタイルや型定義のファイルを分ける構成を採用しました。
初めてReactで開発する時に教わった方法ですが何がどこにあるのかわかりやすいので気に入っています。
Buttonというコンポーネントの場合以下のような構成で設計します。
Button/
├── index.tsx # Buttonをexportするためだけのファイル
├── types.ts # Buttonコンポーネントに関連する型定義を含むファイル
├── styles.ts # Buttonコンポーネントのスタイルを定義するファイル
├── Button.tsx # 見た目に関する部分
├── hooks.ts # ロジックに関する部分
|── components/
│ ├── SubComponentA/
│ ├── SubComponentB/
バックエンドの層ごとの責任分担
バックエンドで一般的に採用される方法をGPTに教えてもらい以下の構成を採用しました。
基本的な設計方針は他と同じで保守性を重視した構成にしています。
| 層 | 主な役割・責任 | 例・イメージ |
|---|---|---|
| api | ルーティング定義(URLと関数の紐付け) | 「入り口」 |
| controllers | in/outチェック、前処理・後処理 | 「窓口・受付」 |
| services | ビジネスロジック(本質的な処理) | 「頭脳・工場」 |
| models | データ型定義(Pydantic/DBモデル) | 「設計図」 |
(イメージまでまとめてくれて、初学者には有難い。)
参考_言語/フレームワークごとの違い
純粋な興味・関心で言語/フレームワークごとの違いをまとめてもらいました。
本質的な役割は同じだけどディレクトリ名やファイル名が微妙に変わるという点は面白いなという所感です。
(海軍では軍令部、陸軍では参謀本部と言うのと似たような感じかな?)
| 言語/フレームワーク | ルーティング/API定義 | コントローラー層 | サービス層 | モデル層 | 備考・特徴 |
|---|---|---|---|---|---|
| Python (FastAPI) | api/ | controllers/ | services/ | models/ | 役割ごとに明確に分割しやすい |
| Node.js (Express) | routes/ | controllers/ | services/ | models/ | routesでURL定義、controllerで処理 |
| Java (Spring Boot) | controller/ | controller/ | service/ | model/ (entity/) | controllerがルーティングも兼ねること多い |
| Ruby on Rails | config/routes.rb | controllers/ | services/ (optional) | models/ | ルーティングはroutes.rbで一元管理 |
| PHP (Laravel) | routes/ | controllers/ | services/ (optional) | models/ | サービス層は必要に応じて追加 |
| Go (Echo, Gin等) | routes/ (main.go等) | handlers/ (controllers/) | services/ | models/ | handler=controllerの役割 |
開発環境・セットアップ
使用するマシン
以下のマシンを使います。
| 項目 | 詳細 |
|---|---|
| マシン名 | MacBook Pro |
| チップ | Apple M1 Pro |
| メモリ | 16GB |
| OS | mac OS Sequoiaバージョン15.4.1 |
環境構築
conda環境+Node.js(nodeenv利用)で環境構築しました。
フロントエンドに関する部分はconda環境のnodeenvを使用して環境構築しました。
conda環境
conda create -n design_detailer python=3.10
フロントエンド用の環境構築
nodeenvの利用
nodeenv -p --node=20.18.0
node -v
で
v20.18.0
が出ればOKです。
ここまででconda環境内でNode.js(JavaScriptをサーバーやコマンドラインで動かすための実行環境)が使える状態になったので、あとはnpm(Node.jsのためのパッケージ管理ツール。Pythonでいうpip)コマンドで必要なパッケージをインストールしていくことでReact + TypeScript環境を構築できます。
# npmプロジェクト(Node.jsプロジェクト)の初期化
npm init -y
# ReactとReactDomのインストール
npm install react react-dom
# TypeScriptと型定義のインストール
npm install --save-dev typescript @types/react @types/react-dom
# React用のビルドツールやスクリプトのインストール
npm install react-scripts
# スタイル関係
npm install styled-components
npm install --save-dev @types/styled-components
ここまででReact+TypeScriptの基本的なものが入ります。
今回作成する私のアプリではmermaidを利用するのでインストールしておきます。
npm install mermaid
npm install --save-dev @types/mermaid
バックエンド用の環境構築
既にconda環境があるので必要なパッケージをpipコマンドでインストールしていきます。
まずはfastapi(APIフレームワーク本体)とuvicorn(FastAPI用の高速な開発サーバー)をインストールします。
pip3 install fastapi uvicorn
私はローカルで動くLLMも試したかったのでそれらを使用するためのライブラリもインストールしました。
Transformers対応モデルを使用する場合
torch(PyTorch本体)、transformers(Hugging Faceのトランスフォーマーモデル用)とaccelerate(高速化・最適化用)のライブラリをインストールします。
pip3 install torch
pip3 install transformers accelerate
llama_cpp対応モデルを使用する場合
MacのGPUを活用して、llama.cpp(ローカルPCで高速・省メモリで動かすためにC/C++で実装されたLLM)を高速に動かすための準備をします。
# cmake(C/C++などのプログラムをコンパイル・ビルドするためのツール)のインストール
brew install cmake
cd backend/lib
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
mkdir build
cd build
# AppleのMetal(MacのGPUを使う技術)を有効化
cmake -DLLAMA_METAL=on ..
# ビルド(最適化された実行ファイルへの変換)
cmake --build . --config Release
llama-cpp-python(Pythonからllama.cppを使うためのライブラリ)をインストールします。
pip3 install llama-cpp-python
ローカルでの起動方法
フロントエンド
cd frontend
npm start
バックエンド
cd backend
uvicorn src.main:app
※LLM利用時は--reloadは非推奨です。
設計
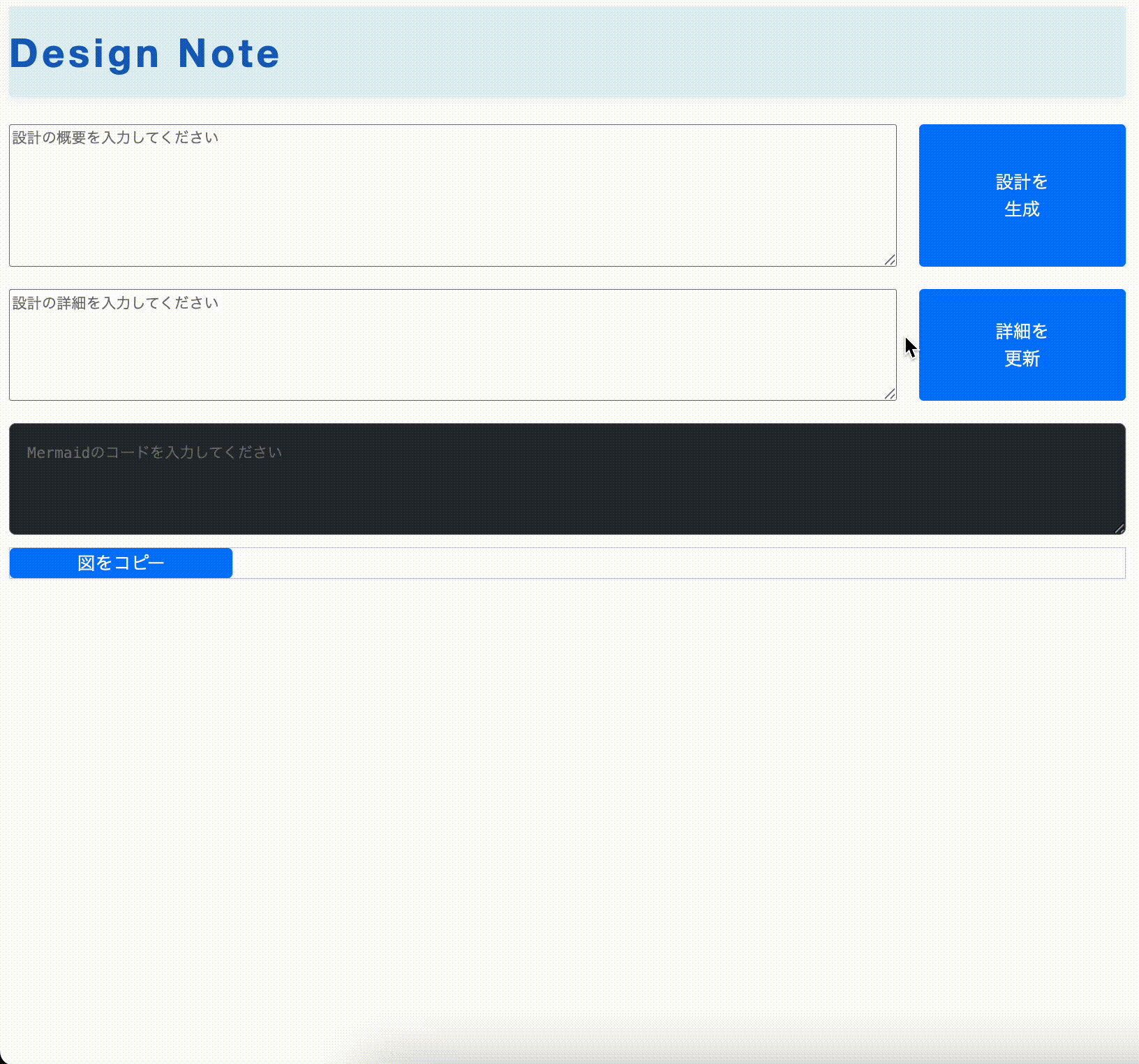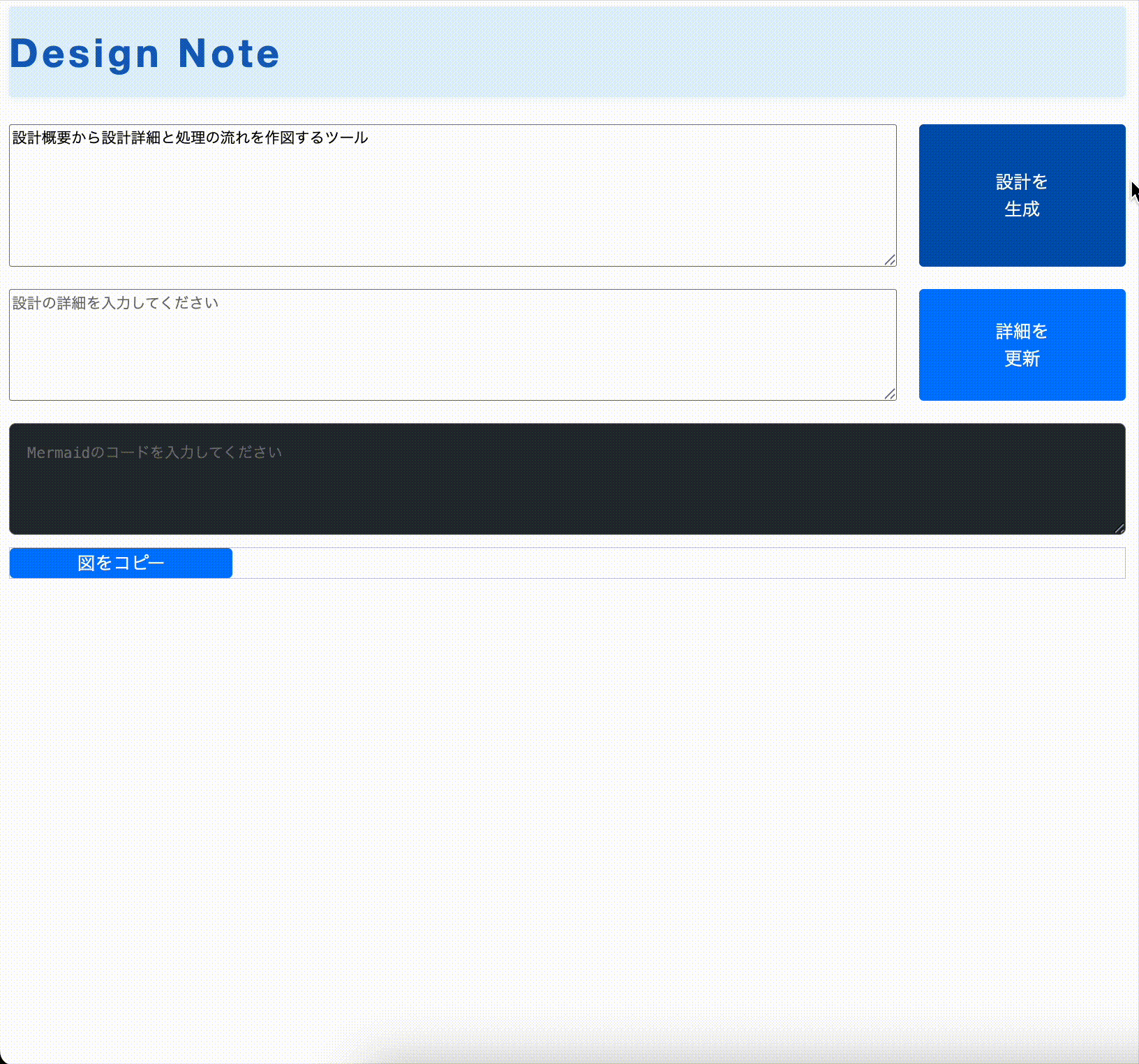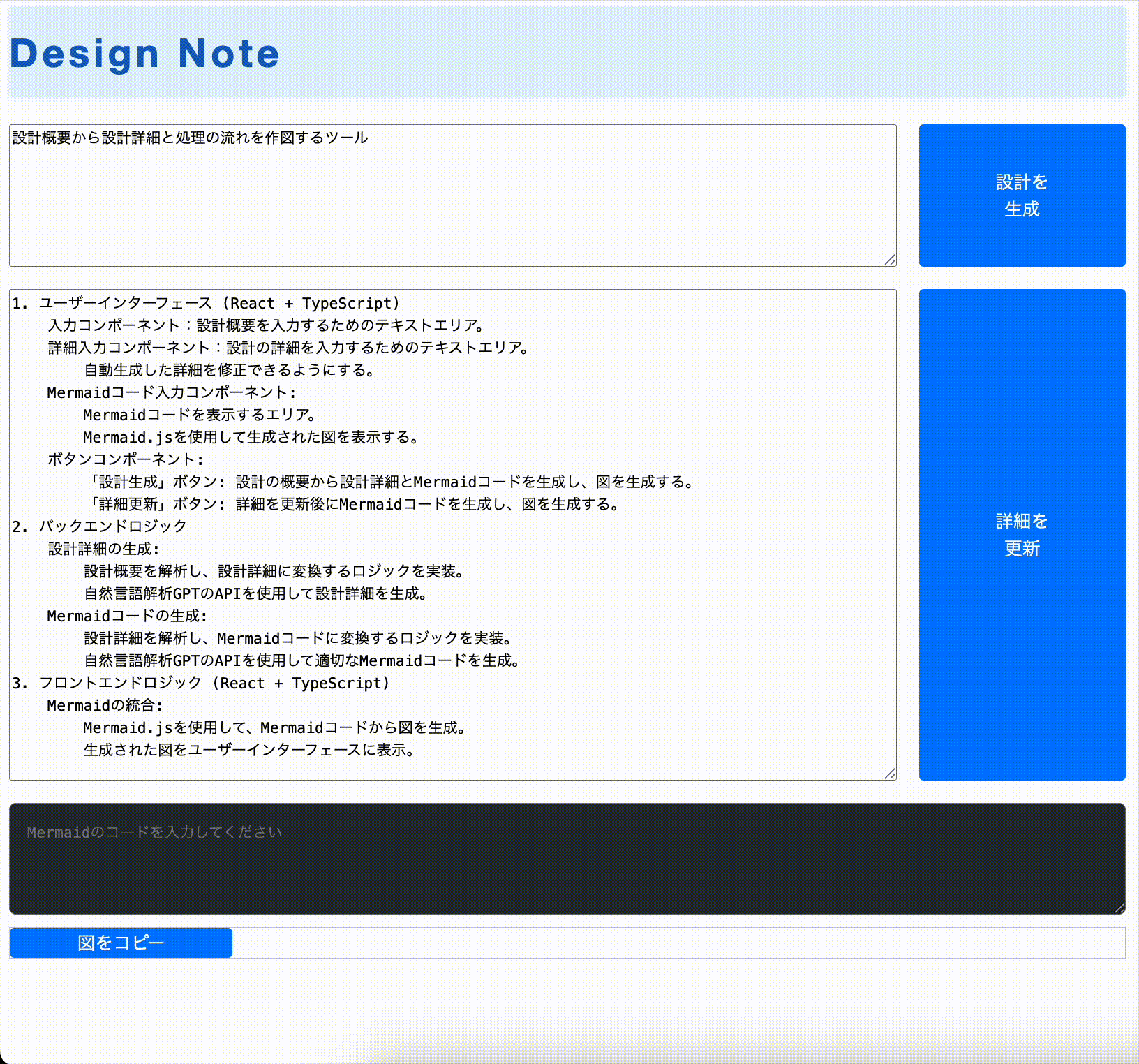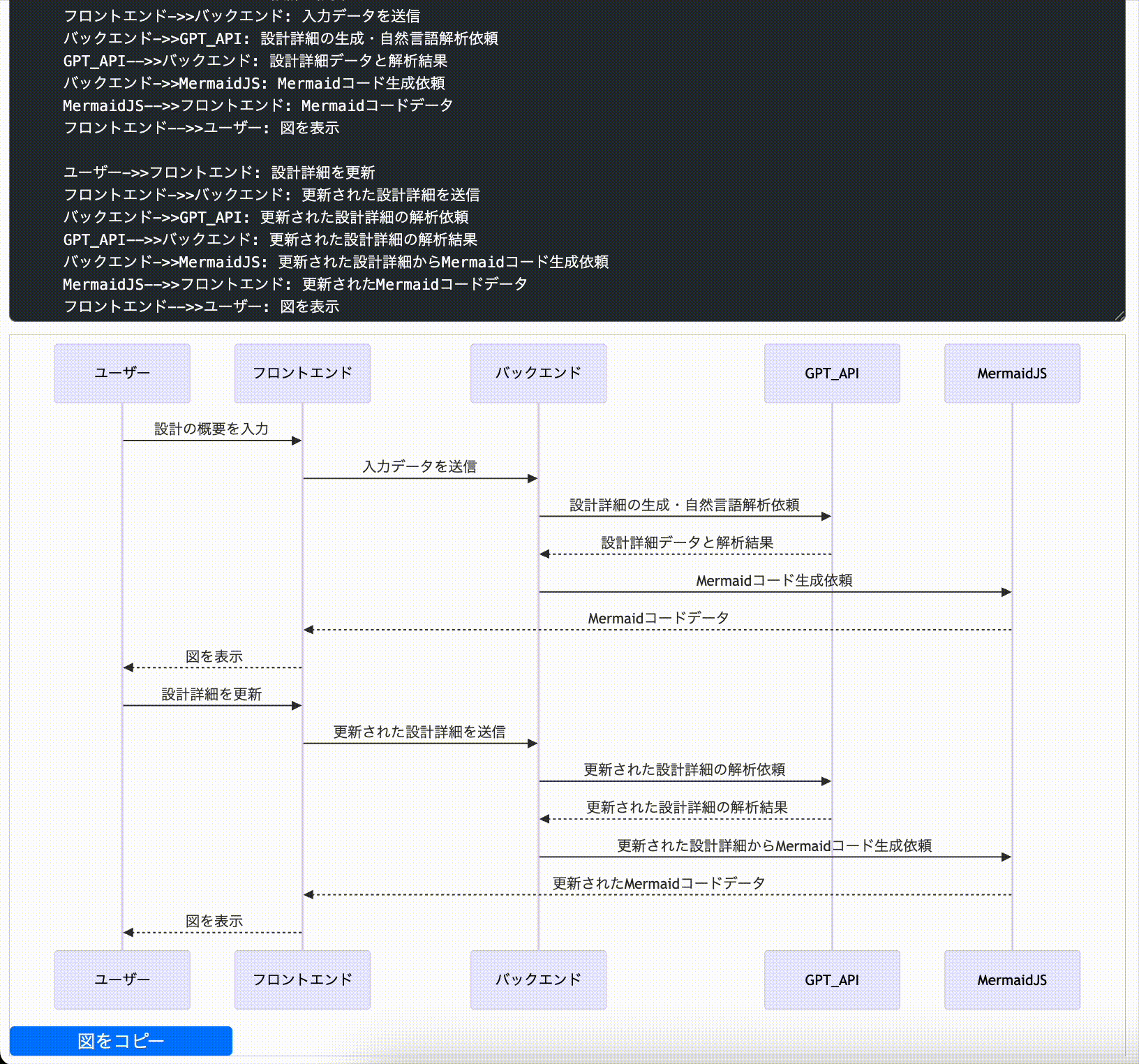
処理の概要
処理の概要を載せておきます。

API設計
| エンドポイント | メソッド | リクエスト内容 | レスポンス内容 | 説明 |
|---|---|---|---|---|
| /design_detail | POST | design_summary: str 設計の概要テキスト |
design_detail: str 設計の詳細テキスト |
設計概要から設計詳細を生成する |
| /mermaid | POST | design_detail: str 設計詳細テキスト |
mermaid: str Mermaidコード |
設計詳細からMermaidコードを生成する |
実装
文量が多くなるため一部のみ載せておきます。
全て見たい方、最新のコードをご覧になりたい方は以下のページからご確認ください。
フロントエンド
App.tsxでは全体の流れを書きます。
基本的にボタンが押されたら中のテキスト内容を引数にして処理するAPIを呼び出すだけです。
概要入力後のボタンでは、設計詳細とMermaidコードの作成までを行います。
import React, { useState } from 'react';
import { AppTitle } from './components/AppTitle';
import { DesignForm } from './components/DesignForm';
import { DesignDetailEditor } from './components/DesignDetailEditor';
import { MermaidEditor } from './components/MermaidEditor';
import { MermaidPreview } from './components/MermaidPreview';
import { generateDesignDetailText } from './utils/generateDesignDetailText';
import { convertDesignDetailTextToMermaidCode } from './utils/convertDesignDetailTextToMermaidCode';
import { AppContainer } from './styles';
export const App: React.FC = () => {
// 概要の入力欄のテキスト管理
const [designFormText, setDesignFormText] = useState('');
// 設計の詳細のテキスト管理
const [designDetailText, setDesignDetailText] = useState('');
// Mermaidのコード
const [mermaidCode, setMermaidCode] = useState('');
// 概要の入力欄のテキスト変更時の処理
const handleDesignFormChange = (event: React.ChangeEvent<HTMLTextAreaElement>) => {
setDesignFormText(event.target.value);
};
// 詳細の入力欄のテキスト変更時の処理
const handleDesignDetailEditorChange = (event: React.ChangeEvent<HTMLTextAreaElement>) => {
setDesignDetailText(event.target.value);
};
// 概要入力ボタンを押した時の処理
const handleConvertButtonClick = async () => {
// 概要の入力欄のテキストから詳細を生成
const generatedDesignDetailText = await generateDesignDetailText(designFormText);
setDesignDetailText(generatedDesignDetailText);
// 詳細の文章からMermaidのコードに変換
const newMermaidCode = await convertDesignDetailTextToMermaidCode(generatedDesignDetailText);
setMermaidCode(newMermaidCode);
};
// 詳細入力ボタンを押した時の処理
const handleDesignDetailEditorSubmit = async () => {
// 詳細の文章からMermaidのコードに変換
const newMermaidCode = await convertDesignDetailTextToMermaidCode(designDetailText);
setMermaidCode(newMermaidCode);
};
return (
<AppContainer>
<AppTitle title="Design Note"/>
<DesignForm
onSubmit={handleConvertButtonClick}
value={designFormText}
onChange={handleDesignFormChange}
/>
<DesignDetailEditor
onSubmit={handleDesignDetailEditorSubmit}
designDetailText={designDetailText}
onChange={handleDesignDetailEditorChange}
/>
<MermaidEditor
code={mermaidCode}
onChange={setMermaidCode}
/>
<MermaidPreview mermaidCode={mermaidCode} />
</AppContainer>
);
};
設計詳細を生成するAPIを呼び出す部分
/**
* 概要テキスト(設計の要約)から、設計詳細テキスト(より具体的な設計内容)を生成する
*
* @param designFormText - ユーザーが入力した設計の概要テキスト
* @returns 設計詳細テキスト(設計の各要素や手順が記述された文字列)
*/
export async function generateDesignDetailText(designFormText: string): Promise<string> {
// バックエンドAPIを呼び出して、設計の詳細を生成
const response = await fetch('http://127.0.0.1:8000/api/design_detail', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
design_summary: designFormText
}),
});
if (!response.ok) {
throw new Error('APIリクエストに失敗しました');
}
const data = await response.json();
return data.design_detail;
}
バックエンド
今回バックエンドで行う処理は大きく分けて以下の2つです。
- 設計概要から設計詳細を作成
- 設計詳細からMermaidコードを作成
LLMごとに得意領域が異なるので複数のモデルを使いたいところですが、メモリの都合があるので1つのモデルで両方とも処理することにします。
LLMのロードにはmodel_loader.pyを使用しています。
Transformers対応モデル、llama_cpp対応モデルのどちらでも使用できるようにします。
llama_cpp対応モデルを使用する場合、load時にcontext_window(トークン数)を指定する必要がありますが、事前にモデルのcontext_windowを調べるのは不便なため、
- 一度小さなwindowで指定して仮読み込み
- モデルの最大値を取得
- メモリ解放
- context_windowの最大値で再度読み込み
という処理にしています。
import torch
# Transformers対応モデルを使用する場合
from transformers import AutoModelForCausalLM, AutoTokenizer
# llama_cpp対応モデルを使用する場合
from llama_cpp import Llama
print("=== モデルロード開始 ===")
model_id = None # Transformers対応モデルを使用する場合に指定
model_path = None # llama_cpp対応モデルを使用する場合に指定
model_name = "elyza"
model_path = "models/elyza/Llama-3-ELYZA-JP-8B-q4_k_m.gguf"
# デバイス自動判定
if torch.backends.mps.is_available():
device = "mps"
elif torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
print(f"使用デバイス: {device}")
try:
if model_id:
# Transformers対応モデルを使用する場合
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16 if device != "cpu" else torch.float32,
device_map=device,
trust_remote_code=True,
)
max_ctx = tokenizer.model_max_length
# context_windowが大きすぎるとメモリーオーバーになるので4096に制限
context_window = min(max_ctx, 4096)
print(f"max_ctx: {max_ctx}")
print(f"context_window: {context_window}")
elif model_path:
# llama_cpp対応モデルを使用する場合
tokenizer = None # llama-cpp-pythonは独自のトークナイザーを内包
# 1. 仮の小さいn_ctxで一度ロード
tmp_model = Llama(model_path=model_path, n_ctx=512)
# 2. 最大値を取得(バージョンによって属性名が違う場合あり)
# 属性がn_ctx_trainの場合、n_ctxの場合、どちらもない場合があるので、全ての場合に対応できるようにする。
max_ctx = int(tmp_model.metadata.get("llama.context_length", 2048))
# 3. メモリ節約のため破棄
del tmp_model
# 4. 最大値で再度ロード
model = Llama(model_path=model_path, n_ctx=max_ctx, n_gpu_layers=32)
# context_windowが大きすぎるとメモリーオーバーになるので4096に制限
context_window = min(max_ctx, 4096)
print(f"max_ctx: {max_ctx}")
print(f"context_window: {context_window}")
else:
raise ValueError("model_id または model_path を指定してください")
except Exception as e:
print("モデルまたはトークナイザーのロードに失敗しました:", e)
raise
print("=== モデルロード完了 ===")
設計詳細を生成する処理は以下のようにしました。
プロンプトを複数用意して、モデルのcontext_window、入力トークン数に応じて使用するプロントを変更する仕様にしています。
モデルに適したプロンプトを使用できるようにするためにPROMPT_TEMPLATESというdictを用意し、選択できるようにしています。
import time
from transformers import PreTrainedTokenizerBase, PreTrainedModel
from llama_cpp import Llama
from config.config_loader import PROMPT_TEMPLATES
from .model_loader import tokenizer, model, model_name, context_window
def select_design_detail_prompt(
design_summary: str,
model_: PreTrainedModel | Llama,
tokenizer_: PreTrainedTokenizerBase | None,
context_window_: int,
design_detail_prompt_template: dict,
max_tokens: int = 1000,
) -> str:
"""
設計概要と各種パラメータに基づき、適切な設計詳細生成用プロンプトを選択する。
Parameters
----------
design_summary : str
設計の概要テキスト。
model_ : PreTrainedModel | Llama
トークナイズや推論に使用するモデルインスタンス。
tokenizer_ : PreTrainedTokenizerBase | None
トークナイズに使用するトークナイザー。llama-cppの場合はNone。
context_window_ : int
モデルのコンテキストウィンドウサイズ。
design_detail_prompt_template : dict
detailed, simple などのテンプレートを含むプロンプトテンプレート辞書。
max_tokens : int, default 1000
生成時に確保する最大トークン数。
Returns
-------
str
選択されたプロンプト文字列。
"""
detailed_prompt = design_detail_prompt_template["detailed"]["template"].format(design_summary=design_summary)
simple_prompt = design_detail_prompt_template["simple"]["template"].format(design_summary=design_summary)
if tokenizer_:
# Transformers対応モデルの場合
detailed_tokens = tokenizer_.encode(detailed_prompt)
print(f"detailed_tokens: {len(detailed_tokens)}")
simple_tokens = tokenizer_.encode(simple_prompt)
print(f"simple_tokens: {len(simple_tokens)}")
else:
# llama_cpp対応モデルの場合
detailed_tokens = model_.tokenize(detailed_prompt.encode("utf-8"))
print(f"detailed_tokens: {len(detailed_tokens)}")
simple_tokens = model_.tokenize(simple_prompt.encode("utf-8"))
print(f"simple_tokens: {len(simple_tokens)}")
# detailed_promptとmax_tokensの合計がcontext_window_を超える場合はsimple_promptを使用
if len(detailed_tokens) + max_tokens < context_window_:
print("detailed_promptを使用します")
return detailed_prompt
print("simple_promptを使用します")
return simple_prompt
def generate_design_detail(design_summary: str) -> str:
"""
設計概要テキストから設計詳細テキストを生成する。
Parameters
----------
design_summary : str
設計の概要テキスト。
Returns
-------
str
生成された設計詳細テキスト。
"""
if model_name in PROMPT_TEMPLATES["design_detail"]:
design_detail_prompt_template = PROMPT_TEMPLATES["design_detail"][model_name]
else:
print("モデル未指定時の設計詳細生成用プロンプトを使用します")
design_detail_prompt_template = PROMPT_TEMPLATES["design_detail"]["default"]
# design_detail_prompt_template = PROMPT_TEMPLATES["design_detail"][model_name]
max_tokens = 1000
prompt = select_design_detail_prompt(
design_summary=design_summary,
model_=model,
tokenizer_=tokenizer,
context_window_=context_window,
design_detail_prompt_template=design_detail_prompt_template,
max_tokens=max_tokens,
)
start = time.time()
print("=== 推論開始 ===")
if tokenizer:
# Transformers対応モデルを使用する場合
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
print(f"トークナイズ完了: {time.time() - start:.2f}秒")
outputs = model.generate(**inputs, max_new_tokens=max_tokens)
print(f"モデル推論完了: {time.time() - start:.2f}秒")
input_length = inputs['input_ids'].shape[1]
design_detail = tokenizer.decode(outputs[0][input_length:], skip_special_tokens=True)
print(f"デコード完了: {time.time() - start:.2f}秒")
else:
# llama_cpp対応モデルを使用する場合
outputs = model(prompt, max_tokens=max_tokens)
print(f"モデル推論完了: {time.time() - start:.2f}秒")
design_detail = outputs["choices"][0]["text"]
return design_detail
LLMごとの比較
参考までに私が試した量子化済みのLLMと使用した結果の感想をまとめておきます。
定量的な評価は行ってない点とプロンプトの工夫で結果が変わる可能性があるという点は先に断っておきます。
| モデル名 | 使用したモデルファイル名 | 説明・特徴 | 感想 |
|---|---|---|---|
| ELYZA-japanese-Llama-3-8b-instruct | Llama-3-ELYZA-JP-8B-q4_k_m.gguf | 日本語特化のLlama-3ベースモデル | 詳細生成、Mermaidコード出力共に安定しており実用的と感じた。 |
| ELYZA-japanese-Llama-2-7b-fast-instruct | ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf | 日本語指示応答に強い軽量モデル | 詳細生成、Mermaidコード出力共に安定しており実用的と感じた。 |
| tokyotech-llm/Swallow-MS-7b-instruct-v0.1 | tokyotech-llm-Swallow-MS-7b-instruct-v0.1-IQ4_NL.gguf | 東京工業大学開発の日本語指示応答モデル | 詳細生成、Mermaidコード出力共に安定しており実用的と感じた。 |
| RakutenAI/RakutenAI-7B-instruct | RakutenAI-7B-instruct-q3_K_M.gguf | 楽天AIによる日本語指示応答モデル |
ELYZA-japanese-Llama-3-8b-instructやtokyotech-llm/Swallow-MS-7b-instruct-v0.1と比較すると物足りない印象。 |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | DeepSeek-R1-Distill-Qwen-7B-Q4_K_M.gguf | 中国発の多言語モデル | 中国語が出てくる場面も多く、扱うには難易度が高い印象。 |
| ELYZA/PLaMo-13B | plamo-13b-Q4_K_M.gguf | 日本語・英語対応の大規模モデル |
RakutenAI/RakutenAI-7B-instructと比較しても物足りない印象。 |
まとめ
設計の概要から詳細や処理フロー図を自動生成するツールを開発しました。
ローカルで動作するLLMを活用することで、API登録不要・手元のPCで完結できる仕組みにしてみました。
16GBメモリのPCでも動くレベルのLLMの成長も個人的に嬉しかったです。
今後の成長にも期待したいと思いました。
本記事が、ローカルLLMや生成AIを活用した開発の参考になれば幸いです。
参考
・コード
・FastAPI

Discussion