これはなに?
時系列データの外れ値検出として、季節分解とTime Sliding Windowを組み合わせた手法を試してみました。背景として、飲食店で開催されるイベントやプロモーション日を、売上データから見つけることはできないか、というところで試してみました。
季節分解
季節分解はいつかの記事でも書いたのですが、時系列データを、以下の3成分に分けることです。
- 季節成分
時系列データの季節性を表す成分 - トレンド成分
時系列データの長期的な傾向を表す成分 - 残差成分
上記2成分で表せられなかった成分、ノイズや外れ値(イベント等も含む)
今回、季節分解をおこなった結果の残差成分は、元の時系列データから、季節成分やトレンド成分を取り除いたものであるので、原系列(元の時系列データ)をそのまま使用するよりも外れ値を検出しやすいのではないかと考えました。
Sliding Window
時系列データに対してウィンドウを移動させながら、統計量を計算していきます。今回は各ウィンドウで残差成分のZ-scoreを計算し、大きな変動を外れ値として検出します。
適用データ作成
今回は1日毎に記録した仮想の飲食店の売上データを作成します。
まずは必要なライブラリをインポートします。
import pandas as pd
import statsmodels.api as sm
import numpy as np
import matplotlib.pyplot as plt
外れ値を含むデータ系列を作成します。
やっていることは、三角関数を使用して週周期の波を作成し、それにランダム項とトレンドを追加した後、飲食店の売上変動を考慮し、金土曜日の値を増加させています。
def gen_sales_data():
# 乱数を固定
rand = np.random.RandomState(seed=44)
# データを生成
idx = pd.date_range(start='2024-01-01', end='2024-08-30', freq='D')
x = np.arange(len(idx))
sales_base = 5000 \
+ abs(np.sin(2 * np.pi * x / 7) * 2000) \
+ abs(rand.randn(len(x)) * 1000) \
+ rand.gamma(0.05, 20000, len(x)) \
+ x * 20
# 金曜日と土曜日の売上を増やす
sales = []
for i, day in enumerate(idx):
if day.dayofweek in [4, 5]: # 4: Friday, 5: Saturday
sales.append(sales_base[i] + 5000)
else:
sales.append(sales_base[i] )
# Create DataFrame
df = pd.DataFrame({'date': idx, 'sales': sales})
df.set_index('date', inplace=True)
return df
上記関数を呼ぶとデータが作成されます。こんな感じ。
df = gen_sales_data()
plt.figure(figsize=(14, 7))
plt.plot(df)
生成された時系列データには、急激に売上が高くなるスパイクがところどころあります。これが今回検出したいイベント時点となります。

検出
先ほど作成したデータに対してstatmodelsを用いて季節分解をおこないます。
この関数によって先ほど作成した売上データが3成分に分解されます。
def seasonal_decom(df):
# 季節分解
decomposition = sm.tsa.seasonal_decompose(df['sales'], model='additive', period=7)
df['trend'] = decomposition.trend
df['seasonal'] = decomposition.seasonal
df['residual'] = decomposition.resid
df['residual'].fillna(0, inplace=True)
return df
df_decom = seasonal_decom(df)
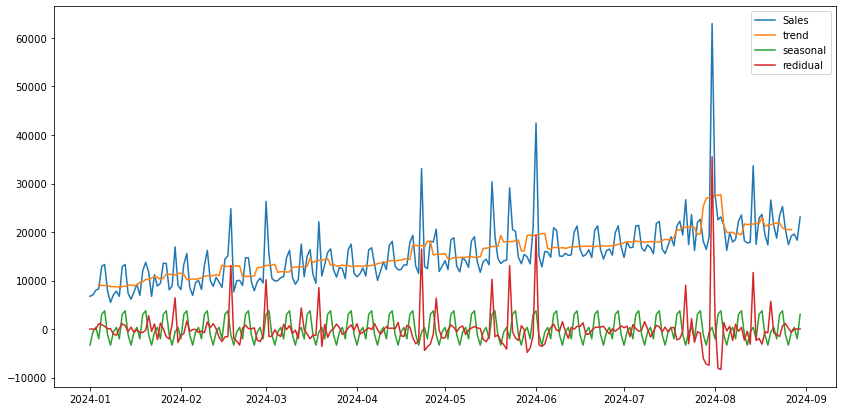
plt.figure(figsize=(14, 7))
plt.plot(df_decom.sales, label = 'Sales')
plt.plot(df_decom.trend, label = 'trend')
plt.plot(df_decom.seasonal, label = 'seasonal')
plt.plot(df_decom.residual, label = 'redidual')
plt.legend()
赤色で示される残差項が今回Sliding Windowでの外れ値検出に使用する系列データになります。
残差項は季節成分やトレンド成分が元の時系列データから引かれたものであるので、外れ値の検出により適しているのではないかと考えました。
sliding windowをおこなう関数を定義します。今回はウィンドウ内のデータに対してZ-scoreを計算し、閾値を超えた点をイベントや外れ値とみなすこととします。
def time_sliding_window(df, window_size, step_size):
events = []
# 残差についてsliding windowやる
for start in range(0, len(df) - window_size + 1, step_size):
end = start + window_size
window_data = df['residual'][start:end]
mean = window_data.mean()
std = window_data.std()
z_scores = (window_data - mean) / std
# Z-scoreが閾値を超えた場合、異常値
window_events = window_data[abs(z_scores) > 2.0]
events.extend(window_events.index.tolist())
return events
また、元の時系列データと、季節分解でできた残差項、検出された外れ値を可視化する関数を定義しておきます。
def visualization(df, events):
plt.figure(figsize=(14, 7))
# Plot original sales data
plt.plot(df.index, df['sales'], label='Sales', color='blue')
# Plot residuals
plt.plot(df.index, df['residual'], label='Residuals', color='green', linestyle='--')
# Mark detected outliers
plt.scatter(df.loc[events].index, df.loc[events]['sales'], color='red', label='Detected Events/Promotions (Sales)')
plt.xlabel('Date')
plt.ylabel('Sales/Residuals')
plt.legend()
plt.show()
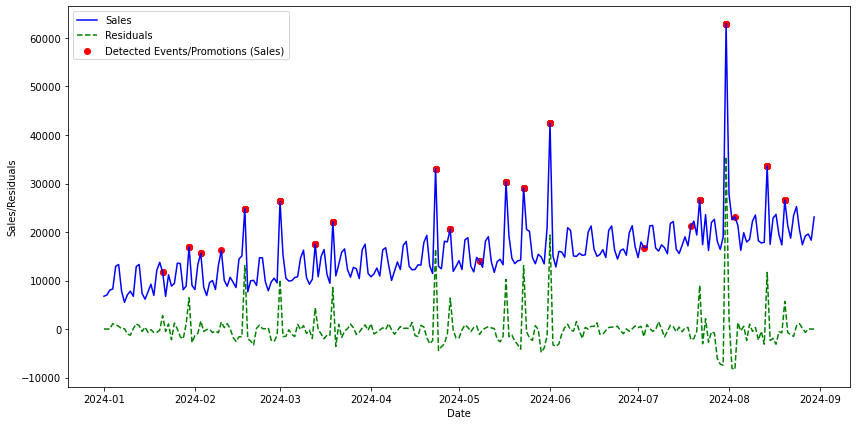
上で定義した関数に残差項とWindowサイズ、Windowをズラしていくステップを投げて検出タスクを実行した後、可視化します。赤点でマークされたものが検出されたデータ点となります。
events = time_sliding_window(df_decom, window_size=7, step_size=1)
visualization(df , events)
まとめ
時系列データを季節分解し、季節成分とトレンド成分で表すことができなかった、残差成分を使用した外れ値検出をおこないました。結果として残差が大きくなった時点をある程度は外れ値として検出できたかなと思います。

Discussion