短縮版入社エントリ
初めまして。2024年6月にGMOメディアに入社したホリノと申します!
ビッグデータの構築と分析を生業としてます。
何卒、よろしくお願いします〜〜
問題設定:ECサイトの月間アクセス日数の改善施策の評価
※データ分析は仮説を置かないと始まらないのでお付き合いください。何卒。
とあるM社は運営しているECサイトの「月間アクセス日数を向上させる施策」に取り組みました。
1ヶ月間のABテストを実施し、次のような結果が得られています。
A/Bテストの結果
| 指標 | A群 | B群 |
|---|---|---|
| 月間アクセス回数の平均値 | 15.9 | 16.3 |
| 月間アクセス回数の中央値 | 18.0 | 17.0 |
| 月間アクセス回数の標準偏差 | 11.11 | 9.54 |
| U検定の有意差:無し (p_value = 0.28) |
この結果を見て、担当者はどう判断したでしょうか?
もし、
「検定で有意差なし、平均値や中央値にも特に差がなさそうだ。ヨシ、施策効果なし!」
で終わらせてしまったら、この施策の重要な結果を見落としています。
より詳しくデータを見るには?
この結果を受けてパッとわかることの1つは、ABテストを評価する指標が少ないことです。
もしかしたら別の指標がこのAB群の差を明確にするかもしれませんが、今回はあらかじめ決めた1つの指標「月間アクセス日数」を深掘りしていきます。
分布に注目する
「平均値や中央値が近しいことは分かった。じゃあ、実際ユーザーはどんな動きをしていたの?」
を確認します。集計値では見えない傾向もあるわけです。
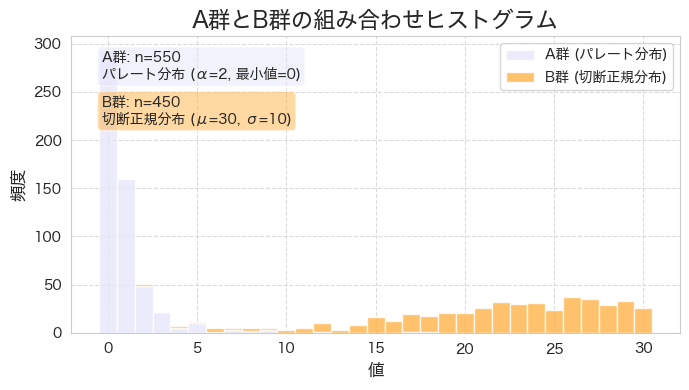
1000人のユーザーの値をヒストグラムで見ることで、より生データに近い粒度でデータを見ます。

見て欲しいのは赤枠の部分です。
この2群のユーザーの平均値・中央値・標準偏差には大きな差がありませんでしたが、
実際にはA群とB群ではユーザーの傾向が一部変化しており、ざっくり言うと
月に0~2回程度サイトに訪問していたユーザーが300人ほど減り、3~20回のアクセス頻度に広く分布するようになりました。
つまり、施策効果なしと評価してしまうのは勿体無く、
プラスに転じた要因をもっと深掘りすべきで、この施策が次に生かせる世界線もあるはずです。
まとめ
「リアルなデータ分析」と題して実際にあった話をダミーデータで表現しました。
以上の例を用いて言いたかったことは2点です。
1. データ確認時は、集計値・1グラフのみでは解釈を間違えやすい
平均値を時系列にAB色変えて比較して効果なし・・ではもったいないです。
あれ?と思ったらデータの粒度と視点を柔軟に変えてデータを見ていきましょう!
2. 施策を正しい指標で評価する
その指標で正しく施策が評価できますか?
別の指標が今回の施策の良し悪しを訴えているかもしれません。
裏話
A群とB群のダミーデータをどう用意したのかについて解説します。
実は、A群とB群には2種類の異なる属性のユーザー属性(i,j)を合成しています。
このように複数の分布を混ぜることを混合分布と言います。Pythonで実装できます。
ユーザー属性i:
0過剰のパレート分布になるようユーザーを定義してます。
つまり、サイトに月にほとんどアクセスしないユーザー属性です。
ユーザー属性j:
30を平均値、標準偏差が10の正規分布を定義し、最大値を30に制限しました。
切断正規分布と言います。毎日アクセスするユーザー属性です。
これを合成したのがA群で、完成したA群の平均値と標準偏差を元に正規分布で乱数を作成したのがB群でした。

Discussion