Datadog SLOで観測された不可解なエラーバジェット変動と、その解決策としての単一メトリクスの重要性
本記事では、私たちが経験したSLO設定における一見不可解な現象と、その原因究明、そしてDatadogサポートの助言を元にたどり着いた解決策について共有します。
特に、ログベースのカスタムメトリクスからSLOを構築する際の重要なポイントが明らかになりました。
エラーバジェットがマイナス? SLOデータに見る不可思議な挙動
私たちの監視ダッシュボードで、あるSLOに関連するエラーバジェットのグラフが奇妙な状態を示していました。
具体的には、「総イベント数 - 正常イベント数」として算出していた「異常イベント数」が、時折マイナスの値を取るという現象です。
▼ 実際に観測されたグラフ(イメージ)
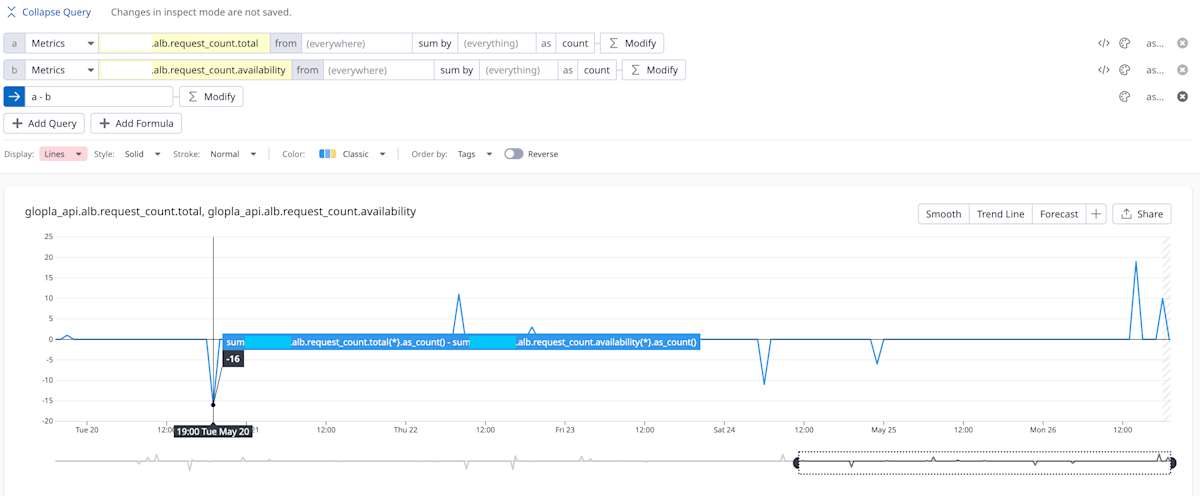
Error Budget Remaining もマイナス値を示しています。

正常イベント数が総イベント数を上回るということは、論理的にありえません。
この状態ではSLOの信頼性は担保できず、エラーバジェットに基づいたアラートや意思決定も正確性を欠いてしまいます。
分離されたメトリクスとその落とし穴
当初、SLOの分子(正常イベント数)と分母(総イベント数)は、ログベースのカスタムメトリクスを利用し、それぞれ別々のカスタムメトリクスとして定義していました。
Terraformによる定義の概要は以下の通りです。
# 分母用: 総リクエスト数をカウント
resource "datadog_logs_metric" "total_requests" {
name = "api.request_count.total"
filter {
query = "source:elb @service:my-api" # 実際にはより具体的なフィルタークエリ
}
compute { aggregation_type = "count" }
}
# 分子用: 正常リクエスト数 (例: HTTPステータス 200-499) をカウント
resource "datadog_logs_metric" "available_requests" {
name = "api.request_count.availability"
filter {
query = "source:elb @service:my-api @http.status_code:[200 TO 499]" # 同上
}
compute { aggregation_type = "count" }
}
# SLO定義で上記メトリクスを参照
resource "datadog_service_level_objective" "my_api_slo" {
# ...
query {
numerator = "sum:api.request_count.availability{*}.as_count()"
denominator = "sum:api.request_count.total{*}.as_count()"
}
# ...
}
定義上、available_requestsメトリクスはtotal_requestsメトリクスのサブセットとなるフィルター条件を持っており、一見すると論理的な矛盾はないように思われました。
原因の究明:Datadogサポートからの示唆
この不可解な現象の解決のためDatadogサポートに問い合わせたところ、原因に関する重要な示唆を得ることができました。
Datadogサポートからの回答(要点)
「Good Events と Bad Events(あるいはTotal Events)にそれぞれ別のメトリクスを使用されると、各メトリクスのデータポイントがDatadog内部で利用可能となる集計タイミングの微妙な差異によって、ご報告のようなSLOの誤判定(分子が分母を上回るなど)が発生する可能性があります。」
この回答から、独立したメトリクスを使用した場合、Datadogの分散システム内でのデータ処理のわずかなタイミングのずれが、SLO計算時のデータ不整合を引き起こす要因となりうることが明らかになりました。
解決策:単一メトリクスとタグを活用した堅牢なSLO構築
Datadogサポートは、この問題への対策として、SLOの計算には単一のカスタムメトリクスを使用し、そのメトリクスに付与されたタグによって分子と分母を区別するというアプローチを推奨しました。
具体的な実装手順は以下の通りです。
-
ログパイプラインでのカテゴリ化(Category Processorの活用
HTTPステータスコード(@http.status_code)のような高カーディナリティになり得る属性を、Datadogのログパイプラインに搭載されている「Category Processor」を用いて、より管理しやすい低カーディナリティのカテゴリ属性(例:status_category:2xx,status_category:3xx,status_category:4xx)に変換し、ログに付与します。 -
単一ログメトリクスの定義
上記で作成したカテゴリ属性(例:status_category)をgroup_byに指定し、単一のログメトリクスを定義します。
# 推奨される単一メトリクス定義(簡略版)
resource "datadog_logs_metric" "api_requests_by_category" {
name = "api.request_count_by_status_category" # 単一のメトリクス名
filter {
query = "source:elb @service:my-api" # 実際にはより具体的なフィルタークエリ
}
compute { aggregation_type = "count" }
group_by {
path = "@status_category" # Category Processorで生成した属性
tag_name = "status_category" # メトリクスに付与するタグ名
}
}
- SLOクエリの修正
SLO定義では、この単一メトリクスを参照し、status_categoryタグを用いて分子(成功イベント)と分母(総イベント)を構成します。
resource "datadog_service_level_objective" "slo" {
query {
# 成功イベント = 2xx系のカウント + (SLO定義に応じて)4xx系のカウント
numerator = <<EOT
sum:api.request_count_by_status_category{status_category:2xx}.as_count() +
sum:api.request_count_by_status_category{status_category:3xx}.as_count() *
sum:api.request_count_by_status_category{status_category:4xx}.as_count() # 実際の成功定義に合わせて調整
EOT
# 総イベント = 全てのカテゴリのカウント合計
denominator = "sum:api.request_count_by_status_category{*}.as_count()"
}
}
このアプローチにより、SLO計算の基となる全てのカウントが単一のメトリクスソースと共通の集計プロセスから派生するため、前述のタイミング問題による不整合が原理的に発生しにくくなります。
Datadogサポートも「基本的にSLOでは同じメトリクスのタグ違いにて組み合わせてご利用いただくことを想定しております」と、この理解を支持しています。
まとめ
今回の経験から得られた重要な教訓は以下の通りです。
- Datadogにおいて、ログベースのカスタムメトリクスを用いてSLOを構築する場合、分子と分母には単一のカスタムメトリクスを元にした、タグによる値の区別を利用することが強く推奨されます。
- 複数の独立したカスタムメトリクスをSLOの計算に用いると、Datadog内部のデータ集計タイミングのわずかな差異が原因で、SLOデータに予期せぬ不整合(例: 分子が分母を超える)が生じるリスクがあります。
- 単一メトリクスアプローチは、データの整合性を高め、より信頼性の高いSLO運用を実現します。必要に応じてログパイプラインのCategory Processorなどを活用し、カスタムメトリクスのタグカーディナリティを適切に管理することも、コスト効率とパフォーマンスの観点から重要です。
本記事が、DatadogでSLOを運用されている、あるいはこれから導入を検討されているエンジニアの皆様の一助となれば幸いです。

Discussion