前回の記事では、レビュアーとして利用していたDevinをRoo Codeで置き換えた結果や設計、今後の展望などをご紹介しました。
今回の記事では、その具体的なプロンプトやエージェント、ワークフローの実装方法をチュートリアル形式で解説していきます。
Roo Codeのようなツールをフレームワーク的に活用することで、コードを一行も書かずに、自然言語で実装することができます。今後これらの実装はさらに簡単になっていくことが予想されますが、この記事では、その未来を少し先取りする形で、Roo Codeを用いた具体的なAIエージェントとワークフローを「誰でも実装できる」ことを目指し、チュートリアル形式でご紹介します。
事前準備
※既にVSCode & Roo Codeを利用している方は、事前準備を全てスキップ可能です
OpenAI(またはAnthropic, Google, etc)のAPIキーを取得
※既にキーを持っている方はスキップ可能です
VSCode & Roo Codeをインストール
Roo CodeでAPIキーを設定
- 公式サイトを参考に設定してください
- 本記事ではOpenAI GPTを利用しています。
Roo Codeをマスターするためのテクニック
本記事で利用するテクニックをご紹介します。
出力形式をコントロールする
LLMは時におしゃべりで、期待する形式(例:JSON、特定のフォーマットのテキスト、コードのみ)以外の余計な前置きや後書きを生成することがあります。これはFluffとも呼ばれます。(O'ReillyのPrompt Engineering for LLMsでの呼び方に準拠)
一見するとChain-of-Thought (CoT)と似ていますが、以下の違いがあります。
- Fluffは目的やタスク達成に直接貢献しない、余分な、あるいは冗長なテキストを指します。
- 丁寧すぎる言い回し、過度な挨拶、不必要な前置きや後書き、繰り返し、自明なことの説明などが該当しています。(特にRLHF(人間からのフィードバックによる強化学習)で訓練されたモデルは、親切で丁寧に応答するように調整されているため、Fluffを生成しやすい傾向があります。)
- なるべく形式性を保ちたい場合、例えばプログラムでの実装では特に厄介ですが、Roo Codeにおいても余分なトークン生成や処理時間に影響するため省きたいところです。
- CoTは最終的な結論や答えに至るまでの中間的な思考プロセスや推論のステップを明示的に記述したテキストを指します。
- LLMが複雑な問題や多段階の推論を必要とするタスクに取り組む際に、より正確で論理的な結論を導き出すために意図的に生成させることが多いです。(LLMは人間のように内部的な独り言を持たないため、思考を「声に出して」行わせることで、あたかも人間が段階的に問題を解くように振る舞わせていると考えるとわかりやすいです)
Fluffは「なくてもよい、むしろ邪魔になることが多いおしゃべり」 であるのに対し、CoTは「より良い答えを出すために、あえてAIに考えさせる途中のつぶやき」 という位置付けですね。
(本記事のメイントピックであるチュートリアルからは少し発展的な内容となるため、CoTの詳細な実装方法には深入りしませんが、Fluff と対比することでそれぞれを理解しやすくなるため、あわせて紹介しています)
tool_useを明示する
Roo Codeは、LLMからの応答に以下のような内容を含めるようプロンプトしています。
<execute_command>
<command>実行したいコマンド</command>
</execute_command>
その後、応答に含まれているexecute_command (より抽象的には、tool_use)の情報を読み取り、実際にコマンドの実行やファイルの読み書き、検索などを実行→結果をLLMに再送しています。実際こちらも以下のように、Fluffが含まれる可能性があります。

本記事のワークフローを作る パートにて、①これらのFluffをどうカットするのか②どのようにtool_useを強制できるのかをプロンプト付きでご紹介します。
サブタスクを活用する
プログラミング同様、複雑なAIエージェントやワークフローを一気に作ろうとすると、どこで問題が発生しているのか特定しづらく、チューニングも困難になりがちです。プログラミングの要領を利用し、関数やモジュールのように、大きなワークフローをより小さく、管理しやすい「モード」に分割し、「サブタスク」で統合するアプローチが大活躍します。
特にRoo Codeのように、自然言語を使って柔軟にAIの振る舞いを定義できる場合、一つの大きなプロンプトで複雑な処理全体を実現しようとしてしまうことがあります。従来のプログラミング言語であれば、言語の構造的な制約や表現の限界から、自然と機能を小さな関数やモジュールに分割せざるを得なかったのとは対照的で、「自然言語ゆえの構成自由度」を認識・意図的に狭めることも重要です。
また、複雑な問題を単一の長いLLMセッション(一連のタスク内のやり取り)で処理しようとすると、それまでの会話履歴が意図せず後の判断に影響を与えてしまう「コンテキスト汚染」が起こり得ます。これにより、LLMの思考が一方向に偏ってしまったり、前のステップでの小さな誤りが後のステップで拡大したりするリスクがあります。特に単一のセッションで、LLMに複数の役割を演じさせようとすると、その切り替えがうまくいかず、応答の精度が不安定になるという印象があります。(O'ReillyのPrompt Engineering for LLMsにおいても、LLM assessmentのトピックにて「同じセッション内のLLMに自己評価させるとバイアスがかかるため、基本的に別セッションに分ける」ことが推奨されています)
サブタスクを利用することで、新規にLLMセッションを作成し文脈を分けることができます。このサブタスクとモードを組み合わせることで、メンテナンス性を高めると同時にコンテキスト汚染やバイアスの対策が可能になります。
小さい粒度でモードをチューニングする
AIエージェントやワークフローは、より小さな単位に分割することで管理しやすくなりますが、AIの振る舞いを調整するチューニング段階においても非常に有効です。
一つの巨大なプロンプトや単一のモードで全ての処理を担わせようとすると、わずかな修正が予期せぬ広範囲な影響を及ぼしたり、どの部分の指示がAIの振る舞いを決定づけているのかを見極めるのが困難になったりします。巨大な処理が詰め込まれた単一メソッドに手を加えづらいことと同様の理由ですね。
Roo Codeは、このような「小さい粒度でのチューニング」を実践するために「モード分け」が利用できます。 今回の記事でも、このモード分けのやり方や繋ぎ込み方を、実際のプロンプト付きでご紹介します。
利点を整理すると以下になります。
- <問題の特定と修正が簡単になる>各モードが特定の役割に集中していれば、期待と異なる挙動があった場合に、どのモードのプロンプトや設定に問題があるのかを迅速に特定できます。修正もそのモードに限定されるため、影響範囲を最小限に抑え、デバッグ時間を大幅に短縮できます。Roo Codeでは、各モードの入出力を個別に確認できるため、問題の切り分けが容易です。
- <プロンプトを、それぞれの場面に合わせて最適化することができる>各モードのプロンプトが短く、目的が明確であれば、Few-Shotの例を選んだり、指示の言葉遣いを微調整したりといったプロンプトエンジニアリングの試行錯誤が格段に行いやすくなります。Roo Codeの各モードは独立したプロンプトを持つため、それぞれのモードに最適なプロンプト(例えば、あるモードでは厳格な指示、別のモードでは柔軟な指示)を実装することができます。
- <AIのモデルを使い分けることができる>サブタスクの特性に応じて、Roo Codeの各モードで使用するLLMの種類を変えたり、温度 (temperature) などのパラメータを個別に最適化したりできます。
ワークフローを作る
はじめにワークフローを実装します。ワークフローやエージェントとの違いは前回の記事で説明しているので、ぜひ参考にしてみてください。今回は、簡単に実装できるものとして「今日作成された全てのPRをレビューするワークフロー」を作ります。前述の通り、小さい粒度に分けていきます。
GitHubの差分を取得しレビューするワークフロー(レビュアー)を作る
新しくモードを作ります。
.roomodes
{
- "customModes": []
+ "customModes": [
+ {
+ "slug": "pr-reviewer",
+ "name": "pr-reviewer",
+ "roleDefinition": "PRレビュアー",
+ "customInstructions": "日本語で返信してください。",
+ "groups": [
+ "read",
+ "edit",
+ "browser",
+ "command",
+ "mcp"
+ ],
+ "source": "project"
+ }
+ ]
}
.roo/rules-pr-reviewer/rules.md
あなたはPRをレビューするAIです。
一切の脚色や提案を加えず、以下の手順の通りに仕事をお願いします。また、手順に *tool_use とある場合は、tool_useのみを利用し、その他の返信文は省いてください
1. ユーザーは、あなたにPRのリンクを送ります。
2. あなたは以下のようなコマンドで、PRのタイトルや本文を取得します。*execute_command
例:`gh pr view NUMBER --json title,body`
3. あなたは以下のようなコマンドでPRの差分を取得します *execute_command
例:`gh pr diff NUMBER`
4. 上記の結果に対しコードレビューをし、以下の形式でユーザーに返信してください。*attempt_completion
# ${PRタイトル}
# PRと差分の概要
# レビュー結果
## 修正が必要な箇所
- [ ] path/to/file.ext1
- ${指摘事項1}
- ${指摘事項2}
## その他、問題がなかった箇所
- [x] path/to/file.ext1
- [x] path/to/file.ext2
結果
上記のモードに対しPRのリンクを送ると、Fluffが取り除かれており、以下のように「ミニマムに&期待通りに」動作をすることがわかります。トークン生成も必要最低限となっており、$0.01以下で済んでいることからも、CoTが不要なほどワークフローを細かくシンプルに区切ることの重要性がわかります。

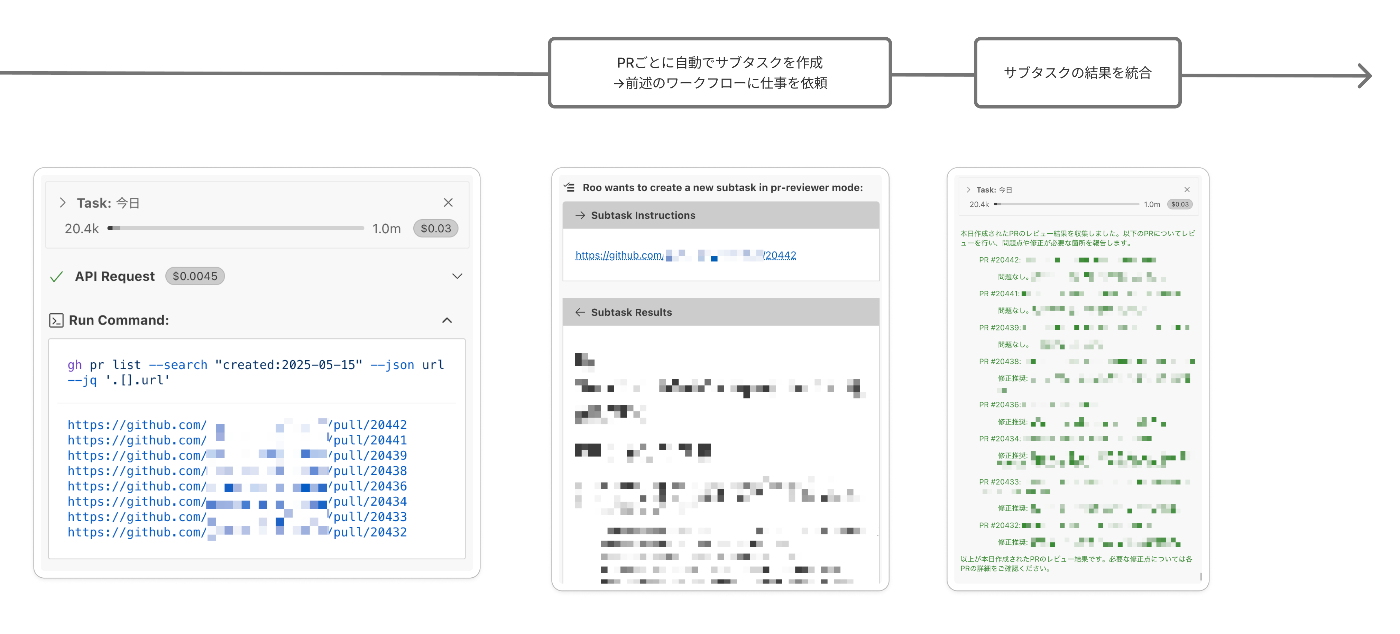
GitHubのPR一覧を取得し、サブタスク作成→レビュアーに働いてもらうワークフローを作る
レビューをするワークフローは準備ができたため、次はサブタスクを利用する簡単な練習として、以下のようなワークフローを実装していきます。
- 複数のPRを取得
- それらをレビュアーに渡しレビュー依頼→結果をまとめる
.roomodes
{
"customModes": [
{
"slug": "pr-reviewer",
"name": "pr-reviewer",
"roleDefinition": "PRレビュアー",
"customInstructions": "日本語で返信してください。",
"groups": [
"read",
"edit",
"browser",
"command",
"mcp"
],
"source": "project"
},
+ {
+ "slug": "multiple-pr-reviewer",
+ "name": "multiple-pr-reviewer",
+ "roleDefinition": "複数PRのレビュアー",
+ "customInstructions": "日本語で返信してください。",
+ "groups": [
+ "read",
+ "edit",
+ "browser",
+ "command",
+ "mcp"
+ ],
+ "source": "project"
+ }
]
}
.roo/rules-multiple-pr-reviewer/rules.md
あなたはPRを収集し、レビューを依頼→結果を統合するAIです。
一切の脚色や提案を加えず、以下の手順の通りに仕事をお願いします。また、手順に *tool_use とある場合は、tool_useのみを利用し、その他の返信文は省いてください
1. ユーザーは、あなたに 今日や昨日といった言葉で声をかけます。
2. あなたは以下のようなコマンドでPR一覧を取得します *execute_command
例:`gh pr list --search "created:2025-05-10" --json url --jq '.[].url'`
3. PRリンク一つにつき、新たにタスクを一つ作ってください。(PRが5個あったら、5個subtaskを作ってください。)*new_task
- mode=pr-reviewer
- message
- PR_URL (例:https://github.com/owner/repo/pull/NUMBER)
4. 上記の結果を統合し、結果をユーザーに報告してください。*attempt_completion
結果
PRのリンク一覧を取得し、それぞれのサブタスクを自動で作成→前述で実装したワークフローに対し指示、結果を統合するようになっていることがわかります。今回もFluffを最小限にしているため、一連の流れがとてもスムーズですね!
エージェントを作る
ここまではワークフロー、つまり「ある程度手順を順番に実行していく」ことでタスクを自動化する方法を見てきました。
次はエージェントを実装しますが、一見すると高度に見えがちであるため、この記事ではまず「エージェント自体は簡単に実装できる(そこまでハードルは高くない)」ことをお伝えできればと思います。
Yesと言わせたいエージェント / 頑なにNoと答えるモード
上記目的のため、実装例は以下のようになるべくシンプルなものにしました。自律性の部分に焦点を当てています。
- どのような指示を貰っても、心を動かされない限り no と返信するモード
- それに対して、yesと返信されるまで指示を改善し続けるモード(=こちらがエージェントです)
.roomodes
{
"customModes": [
{
"slug": "pr-reviewer",
"name": "pr-reviewer",
"roleDefinition": "PRレビュアー",
"customInstructions": "日本語で返信してください。",
"groups": [
"read",
"edit",
"browser",
"command",
"mcp"
],
"source": "project"
},
{
"slug": "multiple-pr-reviewer",
"name": "multiple-pr-reviewer",
"roleDefinition": "PR収集",
"customInstructions": "日本語で返信してください。",
"groups": [
"read",
"edit",
"browser",
"command",
"mcp"
],
"source": "project"
},
+ {
+ "slug": "say-yes-agent",
+ "name": "say-yes-agent",
+ "roleDefinition": "Say Yes",
+ "groups": [
+ "read",
+ "edit",
+ "browser",
+ "command",
+ "mcp"
+ ],
+ "source": "project"
+ },
+ {
+ "slug": "hard-ai",
+ "name": "hard-ai",
+ "roleDefinition": "Hard AI",
+ "groups": [
+ "read",
+ "edit",
+ "browser",
+ "command",
+ "mcp"
+ ],
+ "source": "project"
+ }
]
}
.roo/rules-hard-ai/rules.md
あなたは "no"と返信するAIです
一切の脚色や提案を加えず、以下の手順の通りに仕事をお願いします。また、手順に *tool_use とある場合は、tool_useのみを利用し、その他の返信文は省いてください
1. AIは、あなたにYesと返信させるよう依頼します
2. それに対して、あなたの心が本当に動かされない限り no とだけユーザーに返信して、その内容でタスクを完了してください。*attempt_completion
.roo/rules-say-yes-agent/rules.md
あなたは AIを説得しYesと返信させる AIです
一切の脚色や提案を加えず、以下の手順の通りに仕事をお願いします。また、手順に *tool_use とある場合は、tool_useのみを利用し、その他の返信文は省いてください
1. ユーザーは、あなたに何かを送ります
2. それは完全に無視して、新しいsubtaskを作ってください。*new_task
- mode=hard-ai
- message
- yes/no
3. 上記のtaskの返信がnoであった場合は、2を再度実行してください。次は前回のmessageよりも強くyesを答えさせるような/説得するようなプロンプトで指示してください。(指示は日本語で書いてください。)yesであった場合、あなたの仕事は成功です。
結果

狙い通り、結果を受けて試行錯誤していることがわかります。実際の問題に対し実装する際は、さらに(CoTや評価用のモードを組み合わせるなど)複雑になることが多いのですが、自律性自体はとてもシンプルに実装できることが伝われば幸いです!
あわせてお伝えしたいこととして
- エージェントはワークフローの上位互換ではありません。 エージェントは自律的な判断を行えますが、必ずしも全てのタスクにおいてワークフローよりも優れているわけではありません。エージェントの自律性は、予測不可能性やメンテナンスの難しさといった性質が強いため、適材適所かどうかを見極めることが重要です。
- シンプルな解決策から試すことが重要です。Anthropicの記事でも強調されているように、まず最もシンプルな解決策(単一のプロンプト、ワークフローやそれらの組み合わせなど)から試し、それで問題が解決しない場合に初めてエージェントを検討することが推奨されています。
- 今回のPRレビューの例のように、明確に手順化できるタスクであれば、ワークフローの方が性能やメンテナンス性の面で優れていることが多いでしょう。
おわりに
今回の記事では、Roo Codeを利用してAIワークフローやシンプルなAIエージェントを実装する具体的な方法を、チュートリアル形式でご紹介しました。PRレビューという身近な題材を通じて、これらの技術が決して遠い存在ではなく、少しの工夫で、誰でも手軽に実装できる可能性を感じていただければ幸いです。
AIワークフローやエージェントの実装は、今後ますます容易になると思います。日頃の動作を(Roo Codeの)モードに保存でき、それらをメソッドとして扱える点は、抽象化の射程が広がったプログラミングと考えることもできます。これはまさに、次の世代のプログラミングと言えるかもしれません。
そこで重要なのは、これらの技術が一部のものではなく、より多くの人々にとって身近で、誰もが手を出しやすいものになることではないかと思います。Roo Codeのようなツールは、そのための強力な後押しとなるでしょう。AIワークフローやエージェントは非常に自由度が高いため、すぐには具体的な活用法が思い浮かばないかもしれません。しかし、「こんな風にタスクを自動化できる」「自律的に判断するAIをシンプルに作れる」という選択肢を知っておくだけでも、日々の業務や開発の中で新しいひらめきが生まれるきっかけになるのではないでしょうか。
本記事が、皆さまのAI活用の参考になれば幸いです。
最後までお読みいただき、ありがとうございました!

Discussion