#達人に学ぶDB設計
達人に学ぶDB設計 徹底指南書 ~初級者で終わりたくないあなたへ(ミック)|翔泳社の本
第1章 データベースを制する者はシステムを制す
1-1 システムとデータベース
1-2 データベースあれこれ
1-3 システム開発の工程と設計
1-4 設計工程とデータベース
第2章 論理設計と物理設計
2-1 概念スキーマと論理設計
2-2 内部スキーマと物理設計
2-3 バックアップ設計
2-4 リカバリ設計
第3章 論理設計と正規化 ~なぜテーブルは分割する必要があるのか?
3-1 テーブルとは何か?
3-2 テーブルの構成要素
3-3 正規化とは何か?
3-4 第1正規形
3-5 第2正規形 ~部分関数従属
3-6 第3正規形 ~推移的関数従属
3-7 ボイス-コッド正規形
3-8 第4正規形
3-9 第5正規形
3-10 正規化についてのまとめ
第4章 ER図 ~複数のテーブルの関係を表現する
4-1 テーブルが多すぎる!
4-2 テーブル同士の関連を見抜く
4-3 ER図の描き方
4-4 「多対多」と関連実体
第5章 論理設計とパフォーマンス ~正規化の欠点と非正規化
5-1 正規化の功罪
5-2 非正規化とパフォーマンス
5-3 冗長性とパフォーマンスのトレードオフ
第6章 データベースとパフォーマンス
6-1 データベースのパフォーマンスを決める要因
6-2 インデックス設計
6-3 B-treeインデックスの設計方針
6-4 統計情報
第7章 論理設計のバッドノウハウ
7-1 論理設計の「やってはいけない」
7-2 非スカラ値(第1正規形未満)
7-3 ダブルミーニング
7-4 単一参照テーブル
7-5 テーブル分割
7-6 不適切なキー
7-7 ダブルマスタ
第8章 論理設計のグレーノウハウ
8-1 違法すれすれの「ライン上」に位置する設計
8-2 代理キー ~主キーが役に立たないとき
8-3 列持ちテーブル
8-4 アドホックな集計キー
8-5 多段ビュー
8-6 データクレンジングの重要性
第9章 一歩進んだ論理設計 ~SQLで木構造を扱う
9-1 リレーショナルデータベースのアキレス腱
9-2 伝統的な解法 ~隣接リストモデル
9-3 新しい解法 ~入れ子集合モデル
9-4 もしも無限の資源があったなら ~入れ子区間モデル
9-5 ノードをフォルダだと思え ~経路列挙モデル
9-6 各モデルのまとめ
付録 演習問題の解答
cf. 達人に学ぶDB設計 徹底指南書まとめ - Qiita
cf. 4ステップで作成する、DB論理設計の手順とチェックポイントまとめ - Qiita
cf. とあるクエリを2万倍速にした話 -データベースの気持ちになる- 前編 - dwango on GitHub
第1章 データベースを制する者はシステムを制す
言葉の定義
- Database、データベース、DBとは、データの集まり
- DBMSとは、Databaseを管理するシステム
- データとは、ある形式(フォーマット)に囲まれた事実
-
情報とは、データと文脈を合成して生まれてくるもの
データベースの種類
- リレーショナルデータベース(RDB)
- オブジェクト指向データベース(OODB)
- XMLデータベース(XMLDB)
- キーバリュー型ストア(KVS)
- 階層型データベース(Hierarchical Database)
-
データベースのモデルが異なれば、データフォーマットも異なる。モデルが
異なれば設計技法も異なる。 -
DBMS が異なっても、(基本的には)設計の方法は影響を受けない。
なぜデータベース設計が重要か
-
システムにおいて大半のデータ(少なくとも永続的に使用されるデータ)はデータベース内に保持される。そのため、普通、データ設計とはデータベース設計とほぼ同義である。
-
データ設計がシステムの品質を最も大きく左右する。ソフトウェアというのは、言ってみれば「データの流通機構」であって、どのようなプロ本書で取り上げるのは、こうしたサブ工程の一つである「データ設計」、特にデーグラムが必要になるかは、どのようなデータをどういうフォーマットで設計するかに左右される
3層スキーマ
- 外部スキーマ(外部モデル)=ビューの世界(ユーザーから見たデータベース)
- 概念スキーマ(論理データモデル)=テーブルの世界(開発者から見たデータベース)
- 内部スキーマ(物理データモデル)=ファイルの世界(DBMSから見たデータベース)
-
概念スキーマはデータ独立性を保証するためにある
データ独立性
- 論理的データ独立性とは、外部スキーマからの独立性
- 物理的データ独立性とは、内部スキーマからの独立性
第2章 論理設計と物理設計
論理設計とは
- 「物理層の制約にとらわれない」というニュアンス
- 物理層の制約とは、データベースサーバーの CPU パワーや、ストレージ(一般的にはハードディスク)のデータ格納場所
- DBMS で使えるデータデータ型や SQL の構文、といった、より具体的で実装レベルの条件のこと
- Q. なぜデータベース設計において論理設計が物理設計に先立つのか?
- 論理設計をするうえで、物理的制約には依存しないため
物理設計とは
- 論理設計の結果を受けて、データを格納するための物理的な領域や格納方法を決める工程
- ハードウェアや DBMS の個々の製品についての知識が求められる
論理設計の工程
-
- エンティティの抽出 -> 2. エンティティの定義 -> 3. 正規化 -> 4. ER図の作成
※ エンティティとは、データの集合体
※RDBでは、エンティティを「テーブル」=二次元表という物理的単位で格納する
- エンティティの抽出 -> 2. エンティティの定義 -> 3. 正規化 -> 4. ER図の作成
| id | name |
|---|---|
| 1 | alice |
| 2 | bob |
| 3 | charlie |
1. エンティティの抽出
- 要件定義と重なるところあり
- 顧客やシステム利用者と要件を詰めていく中で実施する
2. エンティティの定義
- データをどのような「属性(attribute)」=「列」として保持するか
3. 正規化
- 正規化とは、エンティティ(=テーブル)を細かく分割していく作業
- そのままではエンティティ同士の関係が把握しにくくなるという問題が起こり、開発の効率を下げる
- その解決策が「ER図の作成」=「エンティティの見取り図」だという
※正規化については、第3章 「論理設計と正規化 ~なぜテーブルは分割する必要があるのか?」にて深堀されている
4. ER図の作成
物理設計の工程
- 1.テーブル定義 -> 2.インデックス定義 -> 3.ハードウェアのサイジング -> 4.ストレージの冗長構成決定 -> 5.ファイルの物理配置決定
1.テーブル定義
- 論理設計で定義された概念スキーマをもとに、それを DBMS 内部に格納するための「テーブル」の単位に変換していく作業
- 論理設計で作られるERモデルを「論理モデル」
- このフェーズで作られるモデルを「物理モデル」
2.インデックス定義
- 「6-2 インデックス設計」にて後述
3.ハードウェアのサイジング
- サイジングはキャパシティとパフォーマンスの2つの観点から行なう。
- データベースの性能問題の8割はディスクI/Oによって起きる。
※データの整合性とパフォーマンスの間に強いトレードオフ
- 性能要件
- 処理時間、「どれだけ速いか」
- スループット、「どれだけ多いか」、Transaction Per Second(TPS)
4.ストレージの冗長構成決定
- データベースの RAIDは少なくともRAID5 で構成する。
- お金に余裕があればRAID10。
- RAID0 は論外。
5.ファイルの物理配置決定
- データベースに格納される5種類のファイル
- データファイル、インデックスファイル、システムファイル、一時ファイル、ログファイル
- 開発者がその存在を意識するのは、 データファイルとインデックスファイルだけ。このファイルは、いわゆる「テーブル」のデータと、テーブルに付与されたインデックスのデータが格納されることになる。
- 残りの3つはいずれも、DBMS の内部処理で使用されるファイルのため、通常は DBA(DB Administrator)が意識する。
バックアップの基本分類
- フルバックアップ(完全バックアップ)、差分バックアップ、増分バックアップ
リストア及びリカバリの手順
- リストア -> リカバリ -> ロールフォワード
- リストア: フルバックアップのファイルをデータベースに戻す
- リカバリ: 差分(または増分)バックアップしていたトランザクションログを適用する
- ロールフォワード: データベースサーバーに残っているトランザクションログを適用する
第3章 論理設計と正規化 ~なぜテーブルは分割する必要があるのか?
-
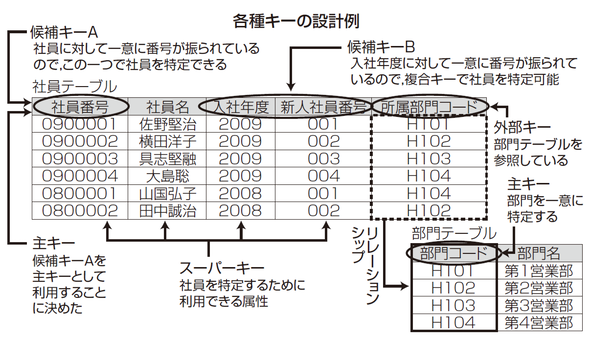
- テーブルに重複行は存在できない
- 外部キーが設定されている場合、データの削除は子から順に操作するのがセオリー
テーブルと列の命名規則
- テーブルと列に使える名前
- 半角のアルファベット
- 半角の数字
- アンダーバー( _ )
- 先頭はアルファベット
- 名前は重複NG
表データベースではなく、リレーショナルデータベース/表モデルと言う理由
-
関係には重複するレコードは存在してはならないが、表には存在しても良い。
-
関係のレコードは上下の順序を持たないが、表の行は上から下へ順序づけられている。
-
関係の列は左右の順序を持たないが、表の列は左から右へ順序づけられている。
-
-
正規化して複数に分割されたテーブルを、結合によって復元しようと試みたとき、元のテーブルにはなかった余計なレコードが付加された結果が出てきてしまった、という経験はないでしょうか。結合キーを正しく把握できていなかったときに起こるこの現象が、コネクション・トラップです。正しく正規化と結合をしていれば、こんな幽霊のようなレコードが現れることはありません。
-
このコネクション・トラップは、かつて網モデルや階層モデルのようにポインタを使って項目を結合させるシステムでは頻発していたエラーの一つでした。もちろん、上述のように関係モデルでも起こりえますし、それを根拠に関係モデルを批判する論者もいるそうですが、デイトの言葉を借りるなら、「そういう批判は、関係モデルについての悲しき無理解のゆえに、不適切なものであることは明白である。」
-
正規化
第1正規形
- 一つのセルの中には一つの値しか含まない
- 一つのセルに一つだけの値が含まれているとき、この値は「スカラ値(scalar value)」と呼ぶ
-
なぜ一つのセルに複数の値を入れてはダメなのか?
※他の正規化は略
第4章 ER図 ~複数のテーブルの関係を表現する
第8章 論理設計のグレーノウハウ
オートナンバリングをアプリケーションで実装するのは「車輪の再発明」。
cf.36. [後編] You have commit bit! w/ songmu | fukabori.fm
cf. Snowflake形式のIDを採用した場合の苦労ポイント - yoskhdia’s diary
cf. ID生成方法についてあれこれ