Neo4j×Pythonでケミカルサプライチェーンを可視化する
背景
2024年は多くの化学プラントでトラブルがありました(参考文献1~4)。化学プラントは原料をパイプラインで供給していることが多く、サプライチェーンの上流でトラブルが発生すると下流プラントにも影響する可能性が高いです。そのため、化学メーカーの原料購買部員はサプライチェーンを把握することが重要です。
やったこと
将来的にLangChainで参照することを想定して、この記事ではNeo4jにケミカルサプライチェーンデータを保存し可視化してみます。
環境
- Ubuntu 20.04.6 LTS
- neo4j 1:2025.01.0 (ソフトウェアとしてのバージョン)
- Python 3.10.9
- pandas 2.2.3
- neo4j 5.28.0 (Pythonライブラリとしてのバージョン)
手順
neo4jインストール
1. ソフトウェアをローカルPCにインストール
以下のURLを参照してインストールしました。Ubuntuのバージョンは異なりましたが、同じ手順で上手く行きました。
localhostにサーバーを立ち上げるときのコマンド
service neo4j start
サーバーを終了するときのコマンド
service neo4j stop
2. Pythonライブラリのインストール
pip install neo4j
以上で準備完了です。
データ準備
石油化学工業協会が公開しているサプライチェーンマップのp1の一部(下図、赤マーカー部)を、テストとして使用します。これは鹿島コンビナートで主に三菱ケミカル社を中心としたチェーンです。

データをエクセルで下図のように準備しました。
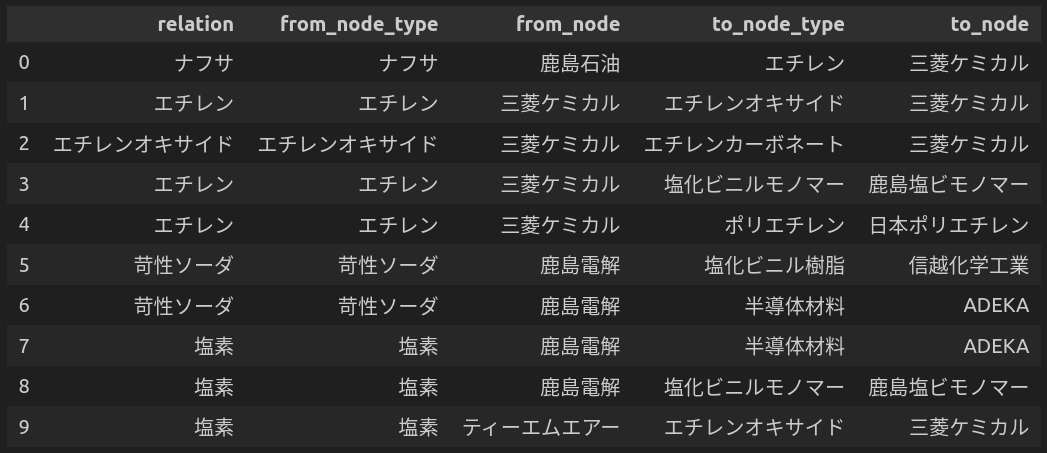
neo4jへのデータ登録
1. neo4jサーバーを起動
service neo4j start
2. 接続情報を.envに格納
NEO4J_URI=bolt://localhost:7687
NEO4J_USER=neo4j
NEO4J_PASSWORD=your_password
3. Pythonでデータ登録
import pandas as pd
from neo4j import GraphDatabase, basic_auth
from dotenv import load_dotenv
import os
load_dotenv()
NEO4J_URI = os.environ["NEO4J_URI"]
NEO4J_USER = os.environ["NEO4J_USER"]
NEO4J_PASSWORD = os.environ["NEO4J_PASSWORD"]
def add_nodes_and_relation(driver, name_from, product_from, relation, name_to, product_to):
driver.execute_query(
"MERGE (c1:Company { name: $name_from, product: $product_from})"
"MERGE (c2:Company { name: $name_to, product: $product_to})"
f"MERGE (c1)-[:{relation}]->(c2)",
name_from=name_from, product_from=product_from,
# relation=relation,
name_to=name_to, product_to=product_to,
database_="neo4j"
)
# 登録データの読込み
df = pd.read_excel("コンビナートデータ_サンプル.xlsx")
with GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD)) as driver:
for i, dat in df.iterrows():
input_data = {
"driver":driver,
"name_from":dat["from_node"],
"product_from":dat["from_node_type"],
"relation":dat["relation"],
"name_to":dat["to_node"],
"product_to":dat["to_node_type"],
}
add_nodes_and_relation(**input_data)
慣れれば大した実装ではありません。
ブラウザで確認
http://127.0.0.1:7474/browser/ にアクセスします。
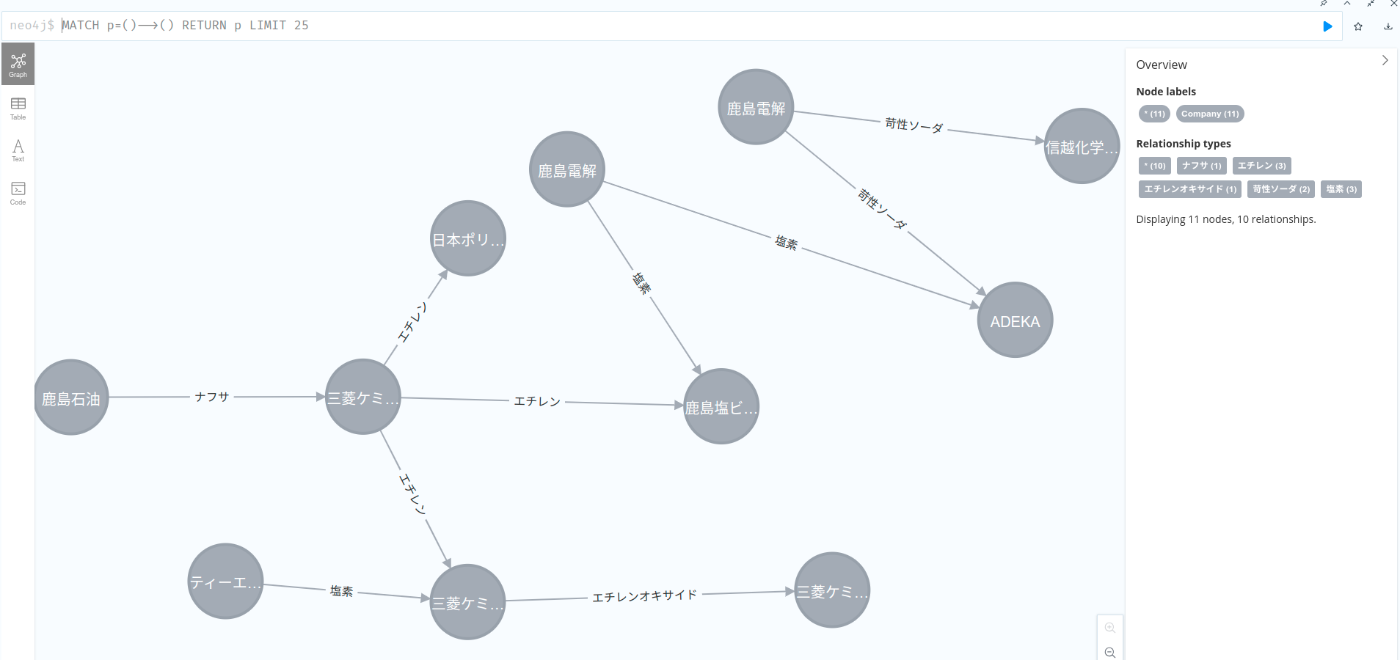
おおー、いい感じで可視化できたのではないでしょうか。こんな感じで、日本すべての化学プラントのサプライチェーンをデジタル化して可視化していきたいと思います。
サーバーとの接続を切断するときは、ターミナルで下記コマンド実行します。
service neo4j stop
Appendix
データ登録に失敗して全削除したい場合のコード
# 削除する場合
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD))
driver.execute_query("MATCH (n) DETACH DELETE n")
driver.close()
所感
RDBの経験はあったものの、Neo4jの書き方には若干苦戦しました。Pythonで実装したブログ記事をあまり見つけられなかったので、結局公式ドキュメントのQuick Startを参照しました。次回は、LangChainを使ってみたいと思います。
参考文献
- https://www.nikkei.com/article/DGXZQOUC017QH0R00C24A8000000/
- https://www.idemitsu.com/jp/information/2024/240702.pdf
- https://www.idemitsu.com/jp/business/factory/tokuyama/news/2024/240716.pdf
- https://chemicaldaily.com/archives/451740
- https://www.jpca.or.jp/files/trends/kakusha.pdf
- https://qiita.com/hoku/items/66ce12e928524d92958a
- https://neo4j.com/docs/api/python-driver/current/
Discussion