【YOLO】①YOLO12をPythonとFlaskで簡単に試してみる
はじめに
個人的に以前少し触っていた「YOLOv8」の開発元と同じ会社(Ultralitics)から最新版のモデルである「YOLO12」が発表されました。
試しとして「YOLO12」を使用した超シンプルな物体検出Webアプリケーションを作成しましたので、その過程を皆様に共有させていただこうと思います。
特に物体検出初学者の方に、こんなに簡単に実装できるのかと感じてもらえれば幸いです。
YOLOとは?
YOLO(You Only Look Once)とは、ディープラーニングに基づいた物体検出アルゴリズムの内の1つです。
他のアルゴリズムと比較しても処理速度と精度のバランスが高水準で、また使用デバイスのリソースに合わせたモデル選択が可能な点で汎用性が高いことからも、リアルタイム物体検出の分野では最も人気のあるアルゴリズムだと言われています。
2016年5月にJoseph Redmon氏によりYOLOv1が発表されて以降、数多のバージョンアップを経て、先日2025年2月にUltralitics社から発表されたYOLO12が最新版です。
参考リンク
https://qiita.com/tfukumori/items/519d84bf3feb8d246924#1-yolov1
YOLOシリーズの特徴として、バージョンによって著者が異なる点が挙げられます。
当然その著者ごとにモデルの発表形式も異なるのですが、個人的にUltralitics社の公式リポジトリの説明が分かりやすく、パッケージの利用も簡単なため好きです。
YOLO12の変更点
公式サイトを参照/要約し記載いたします。
YOLO12では物体検出に使用されるメカニズムが変更されました。
先代までは「CNN」(Convolutional Neural Network:畳み込みニューラルネットワーク)と呼ばれる検出手法を採用し、またその改良に重点が置かれていましたが、YOLO12からは「Attention機構」が導入されました。
CNNが「入力画像を局所的に捉え特徴を抽出する」仕組みに対し、Attention機構は「画像全体を捉え重要な部分に注目する」仕組みを持っています。
これによりAttention機構は物体間の関係性の理解に強く、物体の位置や形状をより正確に認識できる点がメリットですが、CNNと比較し計算速度の遅さがネックとされています。
YOLO12では上記課題点に対し、以下のようなアプローチが行われました。
-
「Area Attention」メカニズムの導入
- 入力画像を等しい大きさの領域に分割し、大きな受容野を効率的に処理することで計算コストを削減。
-
「R-ELAN」(残留効率的レイヤ集約ネットワーク)の導入
- 特徴集約モジュールを改良し、特に大規模なモデルでの最適化を強化
-
アーキテクチャの最適化
- 大規模モデルでの学習安定化のため、ブロックレベルでの残差接続を導入
- メモリアクセスのオーバーヘッドを最小限に抑えるためのFlashAttentionの導入
- 位置エンコーディングの削除による処理速度の向上
- MLP比率の調整による注意層とフィードフォワード層間の計算バランスの最適化
- スタックブロックの深さの削減によるモデルの最適化と効率化
- 適切な箇所での畳み込み演算の活用による計算の効率化
上記改良により、最小モデルのYOLO12nにおいても、先代モデルのYOLO11nと比較してmAP(mean Average Precision)が1.2%向上しています。
ーーーー
物体検出に詳しいわけではない(素人)ため、細かい部分は正直ふ~ん...?という感じです。
しかし、元々高精度かつ計算リソースが抑えられた最軽量モデルにおいて、1.2%の検出精度向上は大きな改善だと思います。
インストールの前提
YOLO12のインストールの前に、筆者の実行環境(EC2)を以下に記載します。
| 項目名 | 設定値 |
|---|---|
| インスタンスタイプ | c5.xlarge |
| AMI(OS) | Amazon Linux 2023 |
| cpu | 4コア |
| メモリ | 8GB |
| ディスク | 30GB |
本稿では最も軽量なモデルを使用して物体検出を行うため、サーバリソースはそれほど重要ではありませんが、少し余裕を持たせるために上記構成としました。
また、前提パッケージとしてOpenGLライブラリ(libGL)をインストールしておきます。
これがないとyoloコマンド実行時にインポートエラーが発生します。
$ sudo dnf search libgl
$ sudo dnf install -y mesa-libGL mesa-libGL-devel
ultraliticsライブラリのインストール
YOLOモデルおよび関連コマンドを使用するために、ultraliticsライブラリのインストールが必要です。
今回はPythonの仮想環境上にライブラリのインストールを行い、YOLOの実行環境を作成します。
- python仮想環境作成(適当な作業ディレクトリに移動後実行)
※コマンド内「yolo12」はどんな名称でも構いません。
$ python3 -m venv yolo12
- 仮想環境有効化
$ source yolo12/bin/activate
- 作成した「yolo12」ディレクトリに移動し、ultraliticsライブラリをインストール
$ cd yolo11
$ pip install ultralytics
以上でYOLOを実行する準備が整いました。
テスト実行
アプリを作成する前に、yolo単体で動作を確認しておきましょう。
以下コマンドを実行してください。
$ yolo predict model=yolo12n.pt source='https://ultralytics.com/images/bus.jpg'
簡単に上記コマンドを解説します。
・yolo predict:yoloで物体検出を実行する
・model=yolo12n.pt:yoloの学習済みモデルを指定する。今回は最軽量の「Nano(n)」モデルを指定
・source=:推論を実行する対象(画像/動画)を指定する。今回は公式リポジトリ内のテスト用画像を指定
model= で指定できるモデルは多数あり、上位になるほど検出精度が向上しますが、その分推論時間が長くなり使用するリソース量も多くなります。実装の際はご利用のサーバスペックと相談の上で適当なモデルを選択しましょう。
コマンド実行後、カレントディレクトリ内に runs/detect/predict が作成され、その内部にバウンディングボックスおよびラベル、信頼度が付与された bus.jpgが格納されます。
実際に検出処理後の画像が以下です。
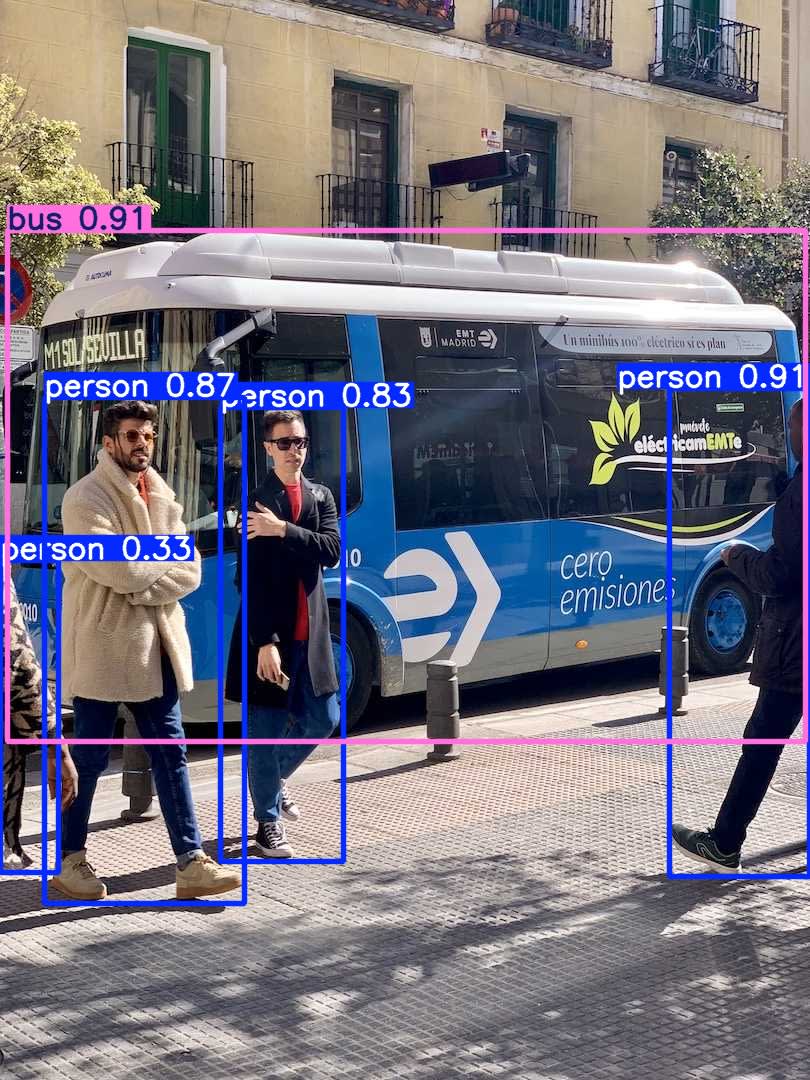
アプリ作成
ではアプリを作成していきましょう。
アプリの動作としては、Webブラウザ上からアップロードした画像に対してYOLOモデルによる物体検出を実行し、検出後の画像を表示させるだけのシンプルな内容です。
pythonコードの作成は自力のみでは力不足だったため、生成AIさまにご助力いただきました。ご承知おきください。
(改善点があればコメントにてご教示いただけますと幸いです。)
ディレクトリ構成
ディレクトリ構成は以下の通りです。
── testapp_imageonly/
├── app.py
├── templates/
│ ├── display.html
│ ├── upload.html
├── result/ (自動作成)
├── upload/ (自動作成)
├── runs/ (自動作成)
メインとなる「app.py」および、アップロード画面の「upload.html」、結果表示画面の「display.html」を作成します。
「upload.html」と「display.html」は「templates/」ディレクトリ内に配置します。
前提パッケージ
アプリはFlaskでホストするため、事前にFlaskのインストールが必要です。
$ pip install flask
app.py
「app.py」にメインの処理を記述します。
大まかな処理の流れは以下の通りです。
① 処理で使用する各ディレクトリを初期化
② ブラウザからアップロードされた画像のファイル名を安全な形式に変換(例:../../etc/passwd → etc_passwd)
③ YOLOによる物体検出処理を実行
④ 処理後の画像を表示
from flask import Flask, request, render_template, send_from_directory
from werkzeug.utils import secure_filename
from ultralytics import YOLO
import os
import shutil
app = Flask(__name__)
# 各種ディレクトリの設定
upload_dir = 'upload' # ユーザーがアップロードした画像を保存するディレクトリ
result_dir = 'result' # 推論結果の画像を保存するディレクトリ
detected_dir = 'runs/detect' # YOLOの推論結果が保存されるディレクトリ
# YOLOモデルの読み込み(最小のyolo12n.ptを使用)
model = YOLO("yolo12n.pt")
def initialize_directories():
"""
必要なディレクトリを初期化(存在する場合は削除して再作成)
"""
for directory in [upload_dir, result_dir, detected_dir]:
if os.path.exists(directory):
shutil.rmtree(directory) # 既存のディレクトリを削除
os.makedirs(directory) # 新しくディレクトリを作成
# 初期化処理を実行
initialize_directories()
@app.route('/', methods=['GET', 'POST'])
def upload_file():
"""
画像アップロード処理と推論処理を行う
"""
if request.method == 'POST':
# ファイルが送信されているか確認
if 'file' not in request.files:
return 'No file part'
file = request.files['file']
# ファイルが選択されているか確認
if file.filename == "":
return 'No selected file'
if file:
# ファイル名を安全な形式に変換し、保存
filename = secure_filename(file.filename)
upload_path = os.path.join(upload_dir, filename)
file.save(upload_path)
# 既存の推論結果ディレクトリを削除(アプリ起動後に複数回アップロードを実行する場合に必要な処理)
if os.path.exists(detected_dir):
shutil.rmtree(detected_dir)
# YOLOモデルを実行し、推論結果を保存
results = model(upload_path, save=True, save_txt=True)
# YOLOが生成した推論結果のディレクトリ
detect_predict_dir = os.path.join(detected_dir, 'predict')
# 推論結果ディレクトリ内のファイルを取得
all_files = os.listdir(detect_predict_dir)
predicted_files = [f for f in all_files if os.path.isfile(os.path.join(detect_predict_dir, f))]
# 推論結果画像を結果ディレクトリに移動
predicted_filename = predicted_files[0]
predicted_path = os.path.join(detect_predict_dir, predicted_filename)
destination_path = os.path.join(result_dir, predicted_filename)
shutil.move(predicted_path, destination_path)
# 推論結果ページを表示
return render_template('display.html', user_image=predicted_filename)
# 画像アップロードページを表示
return render_template('upload.html')
@app.route('/display/<filename>')
def display_file(filename):
"""
結果ディレクトリのファイルを表示する
"""
return send_from_directory(result_dir, filename)
if __name__ == "__main__":
# Flaskアプリを起動(デバッグモード有効)
app.run(host='0.0.0.0', port=5000, debug=True)
upload.html
アップロード画面のhtmlです。
できる限りシンプルにしました。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<!-- フォームを作成 -->
<form method="post" enctype="multipart/form-data">
<!-- ファイル選択ボタンを作成 -->
<input type="file" name="file">
<!-- アップロードボタンを作成 -->
<input type="submit" value="Upload">
</form>
</body>
</html>
display.html
処理後の画像を表示する画面のhtmlです。
こちらも同様にできる限りシンプルな設計にしました。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<div>
<!-- 推論後の画像を表示する -->
<img src="{{ url_for('display_file', filename=user_image) }}" alt="User Image" width="512">
</div>
<div>
<!-- 戻るボタンを表示する -->
<a href="{{ url_for('upload_file') }}" class="back-button">Back to Upload</a>
</div>
</body>
</html>
所定の階層に上記3ファイルの配置が完了できれば、アプリの作成は完了です。
アプリ実行
以下コマンドを実行し、作成した「app.py」を実行しましょう。
問題がなければFlask上でアプリのホストが開始されます。
$ python3 app.py
正常に実行できましたら、「localhost:5000」もしくは「サーバのグローバルIP:5000」にアクセスし、以下のアップロードページが表示されることを確認してください。

「ファイルを選択」から画像を選択し、「Upload」を押下することで解析処理が始まります。
処理完了後、自動で画面遷移し、バウンディングボックスおよび信頼度スコアが付与された結果画像が表示されます。
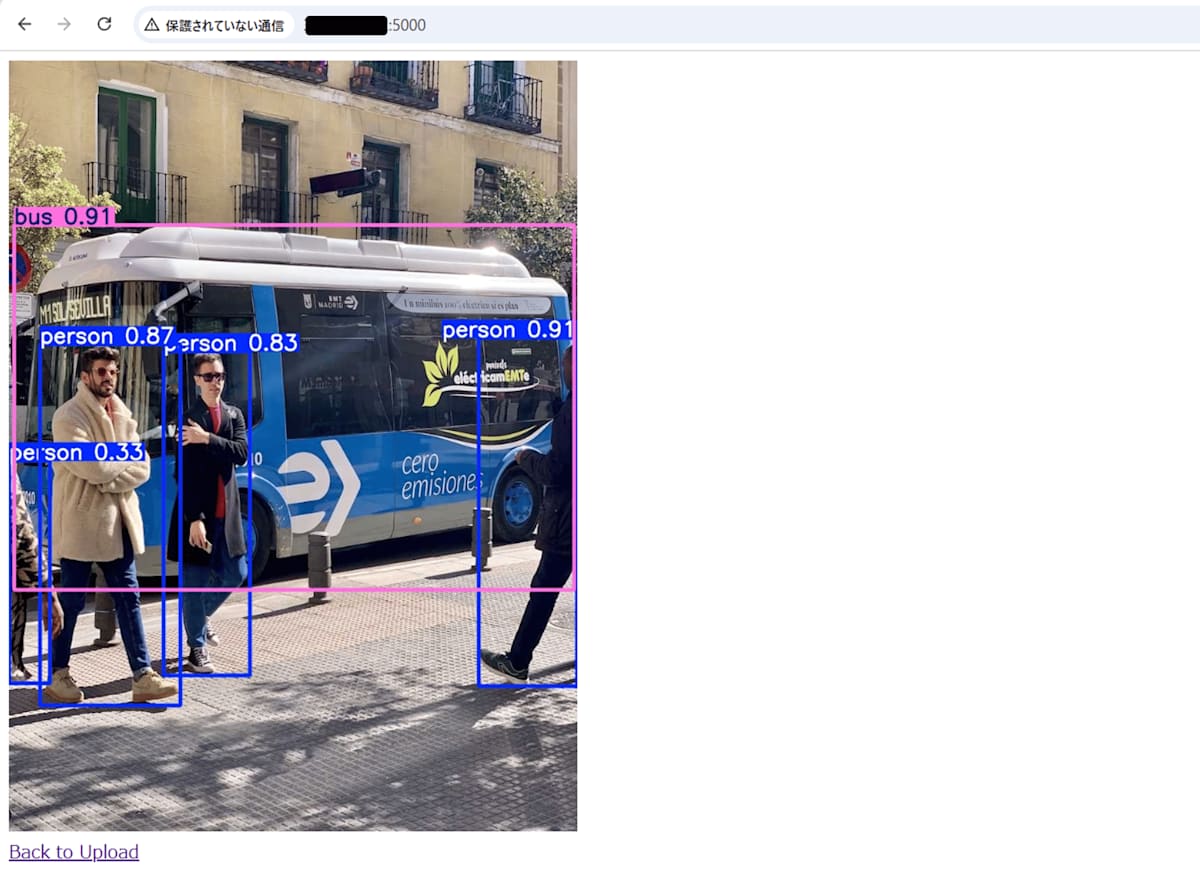
処理後の画像が表示されましたら動作確認完了です!
おわりに
ultralitics社のライブラリが優秀なため非常に簡単に物体検出のハンズオンが実施できました。
この記事を機に物体検出への参入者さまが少しでも増えれば嬉しく思います。
今回はGPUの無いEC2上で操作を実施しましたが、より上位のモデルを試したい・動画解析を行いたい、と思われた方はGPUを搭載したマシン上で実行することをおすすめします。
参考として今回のハードウェア構成の場合、15秒程度の動画(ファイルサイズ4MB)を解析するのに1分強かかりました。
「Google Colab」というサービスを利用すると、制限はありますが無料でGPU搭載のマシン上に実行環境を作成することができるためおすすめです。(EC2より断然)
今回は以上になります。
次回は今回のアプリをコンテナ化し、AWS ECS上で実行する方法について記載したいと考えております。
よろしければぜひご覧ください。
ここまでお付き合いいただきありがとうございました。
参考
Discussion