

はじめに
本記事は社内勉強会の一環である輪読会で読み進めている、以下の書籍の第1章についての要約・読書感想です。
Data Management at Scale, 2nd Edition
第1版については、日本語の書籍が出版されていますが、「抽象度が高く読みにくい」という評価が多かったようで、初版出版から数カ月で第2版が出版されています。
大規模データ管理 ―エンタープライズアーキテクチャのベストプラクティス
要約
大規模データ管理における課題
- データ分析の使用ケースが多様化し、データ環境が分断されている
- 新しいソフトウェア開発方法論がデータの管理を困難にしている
- クラウドコンピューティングと高速なネットワークはデータ環境が分断されている
- プライバシー、セキュリティ、規制上の懸念に注意を払う必要があり、取り扱うデータの急増と消費により運用システムが限界を向かている
- データの収益化にはエコシステム間のアーキテクチャが必要
大規模データ管理における2つのアプローチ
- データメッシュは、大規模な組織において分散型のデータアーキテクチャおよび組織設計のアプローチです。これは、データを分散して管理し、異なるビジネスドメインが独自のデータを所有し、管理することを目指している。データメッシュの主な目的は、組織全体でのデータのアクセシビリティと品質の向上、およびデータ管理のスピードアップです。
- データファブリックは、データメッシュとは対照的で、異種のデータソースを統合し、データ管理の自動化を提供する統合型データアーキテクチャです。これは、様々なデータシステムとアプリケーションを横断してデータを接続し、管理します。これは、一元化されたメタデータを使用し、データの簡単なアクセス、統合、プロビジョニング、利用のためのエンドツーエンドの統合層(ファブリック)を備えたアーキテクチャビジョンです。データファブリックの目的は、組織全体でデータの簡単なアクセス、分析、および管理を提供することです。
- 両者は、大規模なデータ環境において効率的なデータ管理とアクセスを提供するという共通の目的を持ちながら、アプローチにおいて異り、個々の技術として見るべきではない。実際には、両方のアプローチが共存し、既存の運用データストア、データウェアハウス、データレイクへ投資することが期待される。
- データドリブン型への移行では、中央集権と分散化のインパクトのバランスを取るためにトレードオフが発生する。2つのアプローチをフレームワークと捉え、データ管理戦略を選択する。
データマネジメントの定義
データマネジメントという用語は、データ管理に使用される一連のプロセスと手順を指す。
DMBOK による詳細な定義は、以下の通り。「ライフサイクルを通じてデータや情報資産の価値を提供、管理、保護、強化する計画、方針、プログラム、実践の開発、実行、監督」
データガバナンスを中心にデータマネジメントの 11 の機能領域を特定している。
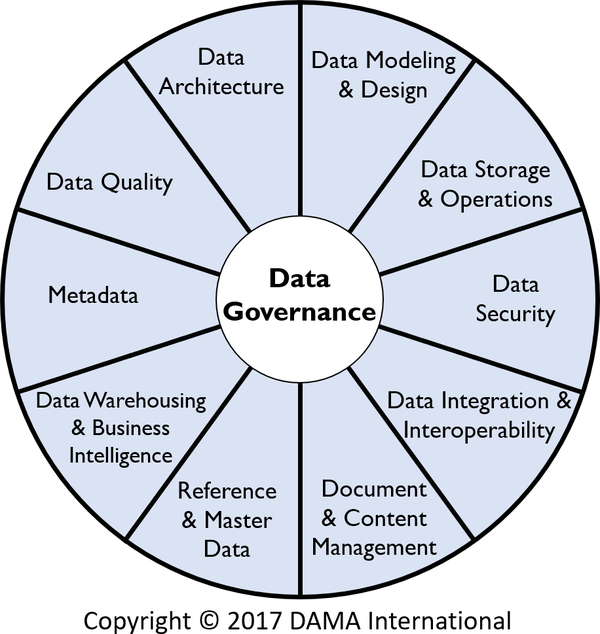
-
データガバナンス
対応するすべての資産を含むデータの管理に関する権限と管理の実施と実施に関するすべての活動を含む。
-
データ・アーキテクチャ
ブループリント、リファレンス・アーキテクチャ、将来状態ビジョン、依存関係を含む、データのマスタープランの定義が含まれる。これらを管理することで、組織は意思決定を行うことができる。
-
データモデリングとデザイン
特定のコンテキストと特定のシステム内でデータを構造化し、表現すること。データ要件の発見、設計、分析はすべてこの分野の一部。
-
データの保存と運用
データの価値を最大化するためのデータベース設計、正しい実装、サポートの管理。
-
データ・セキュリティ
安全な認証、認可、およびデータへのアクセスを提供するすべての規律と活動。
-
データ統合と相互運用性
あるコンテクストから別のコンテクストへデータを効率的に移動させるために、データの移動、収集、統合、結合、変換に関連するすべての分野と活動を指す。データ相互運用性とは、アプリケーションの特性に関する知識をほとんど、あるいはまったく必要としない方法で、さまざまなアプリケーション間で通信したり、機能を呼び出したり、データを転送したりする能力のこと。一方、データ統合とは、異なる(複数の)ソースからのデータを統一されたビューに統合すること。レプリケーションや ETL(抽出、変換、ロード)ツールなどの追加ツールによってサポートされる。
-
ドキュメントとコンテンツの管理
非構造化のメディアとデータ形式で保存されたデータの管理。
-
リファレンスおよびマスターデータ管理
データがアクセス可能で、正確で、安全で、透明性があり、信頼できるものであることを確認するために、重要なデータを管理すること
-
データウェアハウスと ビジネスインテリジェンス管理
ビジネス上の洞察を提供し、意思決定をサポートするすべての活動
-
メタデータ管理
データを分類し記述するすべてのデータを管理すること。メタデータは、データを理解しやすくし、統合の準備を整え、セキュアにするために使用し、データの品質を保証する。
-
データ品質管理
データを確実に利用できるようにするためのデータ品質管理に関連するすべての活動
技術開発と業界トレンドの影響
ソフトウェア開発手法における2つのトレンド
-
DevOps
- ソフトウェア開発(Dev)と運用(Ops)を組み合わせて、システム開発のライフサイクルを短縮し、高いソフトウェア品質で継続的なデリバリーを提供する
- より多くの自律性、オープンなコミュニケーション、信頼、透明性、分野横断的なチームワークを受け入れる新しい文化を必要とする
-
アプリケーション開発規模
- アプリケーションをより小さな分解されたサービスに変換することで、柔軟性と開発スピードの向上を実現する
- マイクロサービス、コンテナ、Kubernetes、ドメイン駆動設計、サーバーレス・コンピューティングなど
モノリシック・アプリケーションから分散型アプリケーションへの転換の影響により様々なデータ管理上の課題が発生する
- ネットワーク通信の増加
- データのリードレプリカの必要性
- 多数のデータセットを結合する必要性
- データの一貫性の問題
- 参照整合性の問題
クラウドの発展がデータ管理に与える影響
ネットワークがボトルネックではなくなったので、環境間でデータを素早く移動させて利用することが可能になった。
データをコピー(複製)して、クラウドデータセンターなど別の施設の計算能力に持ち込むので、データ環境をさらに断片化する。
集中型アーキテクチャは多くの組織にとってボトルネックとなる
エンタープライズ・データウェアハウスは、複数のアプリケーションの統合データベースとして機能する。中央集権化がデータ管理の解決策だと思われがちだが、一元化されたアーキテクチャでは、異なるアプリケーション間に多くの相互依存関係があるため、ある変更が他の変更の波及効果を引き起こす可能性を考慮しつつ、変更を慎重に行う必要がある。
-
敏捷性の欠如
データウェアハウスは特定のソリューションやテクノロジーに密接に結びついており、異なる読み取りパターンを必要とする利用者は、データを他の環境に移す必要が出てくる。そうなるとベンダーやデータベースの種類が変化する中で、データウェアハウスは中央リポジトリとしての効果を失って、ハードウェアコストだけが重くなってくる。
-
ライフサイクル管理
統一データウェアハウスは正確なアーカイブと考えられているが、これが問題を生むこともある。特に、データウェアハウスに保存されるデータは、元の形を失い、データを提供した分析チームが認識できない形式に変換されることがあります。この場合、再度データの変換、結合、統合するのに時間がかかるため、データの即時利用が困難になる。
-
データ品質
データの所有権が不明瞭な場合、システムから破損したデータが提供された際に、その責任を誰が負うかが問題になる。
実際には、中央のエンジニアリングチームが他のチームによって引き起こされたデータ品質の問題を解決することが多いが、この対応は、信頼性の高い ETL プロセスの一部ではないスクリプトによる修正が多数行われることになり、データリネージの追跡が困難になる。
データ戦略の定義
データ戦略を定義するためのステップ
- ビジネス目標と戦略に集中する。最新テクノロジーの誇大広告に踊らされないこと。
- データが会社のビジョンをどのように後押しするかを考え適応される。
- ビジネス上の課題に対してデータが果たせる役割を決める
- ビジネスインパクトを定量化する
- 3 年後以降のコアビジネス戦略を定義する
- 守りと攻めのバランスを考える。
- 管理と柔軟性のバランスを決める。
- 明確で測定可能なマイルストーンを設定する。成果を測定するための指標と KPI を定義する
- 戦略を組織全体に伝達するための、コミュニケーションプランを作成する。
- 最初の重点分野を決める。研究開発、規制遵守、コスト削減、収益増加など。
- 成功を阻む可能性のある組織内の障壁を特定し、回避する方法を探す
- 人材戦略を再考し、データが十分に活用できる組織であるかどうかを判断する
- データ主導の文化を定義する。必要なスキルや教育を明確にする。非エンジニアにどの程度自由にデータ利用の許可を与えるのか?データを他社と共有する予定があるか?
- 既存のデータ活用状況について整理する。データがどこで作成され、どのように分散し、利用されているかを把握する。
- ソフトウェア開発手法を変化させる必要があるか判断する。
- ハイレベルな技術選択を定義する。スケーラブルなクラウドを活用するのか、ベンダーに捉われない技術を活用するのか、ベンダーロックインのリスクを承知でネイティブサービスを利用するのか。
- 最も重要な要素を盛り込んだエグゼクティブプレゼンテーションを作成し、「なぜ」「何を」「ギャップ」「ロードマップ」「投資ケース」などをまとめる。
- 予算と目標およびユースケースを整合させ、コスト管理戦略を立てる。データ管理への投資意欲と見直し計画を決定する。
データ・ドリブン戦略は、組織の目的、事業の規模や種類、計画されている資金調達や投資、既存の文化や成熟度、基本的な事業目標によって異なるものになる。
例えば、ビジネス目標が組織全体であまり密接に一致していない場合、標準化と統合の必要性は少ないし、最近、データ漏洩というトラウマ的な出来事を経験したのであれば、おそらくデータ防御に強い関心を持つ。
最も重要なポイントは、データ戦略を現在および将来のビジネスニーズに合致させること
第 1 章のまとめ
データ戦略のすべての要件と野心に合致するアーキテクチャを設計することは、移行の最も難しい部分。組織構造、アプリケーション、プロセス、データ環境の全体像を把握する必要があり、柔軟性、オープン性、管理、時間、実現コスト、リスクなどのバランスをとりながら、さまざまなシナリオの可能性を検討する。単純なビジュアライゼーションの作成にとどまらず、戦略的方向性と将来の方向性の設定は、ビジネスからトップダウンで始まるはず。
データ戦略の重要な側面は、集中化と分散化のバランスを取ること。ドメインの分割と境界の設定が分散化の最も難しい部分。
感想
データメッシュやデータファブリックという単語自体は聞いたことがあったが、大規模データ管理に対する真逆のアプローチだったのは、初めて知った。
エンジニアになる前の職場では、職場ごとにデータ管理ツールやシステムが別々のベンダーのものだったので、カオスと言っていい状態だったことを思い出した。データの連携ができないのでトレンドグラフをハードコピーして、さらにそれをスキャンして取り込んでいたなど、もはやデータを管理していたとさえ言えない職場もあったな。
現在のプロジェクトでも、マルチクラウド構成を採用していることもあり、データの環境が分断し、データの管理が複雑になっていることを日々感じているところなので、本書を引き続き読み進めて、データマネジメントについて学んでいきたい。
余談だが、データ管理というと「物理データの保管方法」を指していて、データマネジメントというと「データに関する包括的な管理体制」を指すようなイメージがあるのは私だけだろうか。

Discussion