はじめに
最近の生成AIは、基本的にマルチモーダルな対話が可能になってきていますね。それどころか、入力だけでなく出力までもテキスト以外に対応していて、変化の勢いがすごいです。
ですが、これらの多くは外部APIの力を借りることがほとんどです。ローカルのパワーだとどうしても計算リソースやレスポンスに難があるためです。それをなんとかローカル環境だけで頑張って構築してみました。
ソースコードは本記事にも記載しますが、一応リポジトリは以下です。
イメージは、以下のLangChainが公開しているドキュメントを参考にしています。
フロー図
- 入力ファイルを
Unstructuredライブラリを使って、非構造データをOCRしたテキストと画像データに分解します - テキストをベクトル化して、ベクトルDBを作成します
- 画像データはVLMを使って、画像の説明文を生成しておきます
- 入力プロンプトを同様にベクトル化して、作成済みのベクトルDBのリソースを類似度検索します
- 検索により得られた類似性の高いリソースを使って、回答を生成します
実行環境
- PC
MacOS: 15.6.1
チップ: Apple M4
メモリ: 24GB // 16GBだと今回使用するLLMやVLMの動作が厳しいかも..
- 生成AIモデル(ストレージが約30GB必要)
// 生成AIモデル
LLM: gpt-oss:20b // サイズ: 14GB
VLM: mistral-small3.2:24b // サイズ: 15GB
Embedding Model: bge-m3:567m
- Python
Python == 3.11.11
uv == 0.8.17
- Ollama
ollama == 0.11.11
環境構築手順
リポジトリTOPのREADMEに記載しています。
uvを使ったPythonの環境構築と、Ollamaの環境構築手順の2つを記載しており、それ以外の準備は不要かと思います。
マルチモーダルRAGの詳細
リポジトリのsrcディレクトリに、今回作成したソースコードがあります。
1. PDFデータの抽出
-
unstructuredライブラリを使って、PDFデータを抽出する - 抽出したデータを、OCRしたテキストと画像(テーブルデータを含む)に分類する
- OCRしたテキスト: 細かくテキストが分解されてしまうので、タイトル単位で区切るように良い感じにテキストを結合しています
- 画像: base64にエンコードされています
-
mistral-small3.2を使って、画像データの説明文をテキストで生成させる- 今回使用したPDFファイルからは28枚の画像が抽出され、テキスト生成にトータルで40分ほどかかりました(画像サイズ次第ですが、1枚あたり約1.5分)
- メモリ24GBでこれなので、それ以下のメモリの環境においては、もう少し軽量なVLMの検討が必要だと思います
該当ソースコード
class PDFParser:
"""PDFファイルの解析クラス"""
def __init__(self) -> None:
self.llm = LLM()
os.environ["EXTRACT_IMAGE_BLOCK_CROP_HORIZONTAL_PAD"] = "50" # 左右に切り抜き用のパディングを追加
def extract_pdf_content(self, pdf_path: str) -> list[Element]:
"""PDFファイルからコンテンツを抽出する
"Args":
pdf_path: PDFファイルのパス
"Returns":
抽出されたコンテンツ
"""
logger.info("Analyzing PDF file ...")
elements = partition_pdf(
filename=pdf_path,
languages=["jpn"],
infer_table_structure=True,
extract_images_in_pdf=True,
strategy="hi_res",
extract_image_block_types=["Image", "Table"],
extract_image_block_to_payload=True,
)
log_msg = f"Extracted {len(elements)} elements by {Path(pdf_path).name}"
logger.info(log_msg)
return elements
def annotate_content(self, elements: list[Element]) -> list[Content]:
"""抽出したコンテンツを整備する
"Args":
elements: PDFファイルから抽出したコンテンツ
"Returns":
整備したコンテンツ
"""
logger.info("Formatting contents ...")
annotated_contents: list[Content] = []
text_content = ""
for elem in elements:
match elem.category:
case "Title":
if text_content == "":
text_content += elem.text.strip()
continue
annotated_contents.append(Content(category="text", content=text_content))
text_content = elem.text.strip()
case "Image" | "Table":
image_content: str = elem.metadata.image_base64
annotated_contents.append(Content(category="image", content=image_content))
case _:
text_content += elem.text.strip()
if text_content != "":
annotated_contents.append(Content(category="text", content=text_content))
logger.info("Done")
return annotated_contents
def flatten_content_to_text(self, annotated_contents: list[Content]) -> list[Resource]:
"""抽出して整備したコンテンツを全てテキストに均す
"Args":
annotated_contents: テキストとエンコードされた画像が混ざったコンテンツ
"Returns":
全てテキストに変換したコンテンツ (画像はテキストに要約している)
"""
resource_contents: list[Resource] = []
for annotated_content in tqdm(annotated_contents):
cat: Literal["text", "image"] = annotated_content.category
content: str = annotated_content.content # text or image encoded base64
if cat == "image":
summarized_text = self.llm.summarize_image(content)
resource = Resource(category=cat, text=summarized_text, image_base64=content)
else:
resource = Resource(category=cat, text=content, image_base64=None)
resource_contents.append(resource)
return resource_contents
2. ベクトルDBの作成
- langchainで定義されている
Documentスキーマに合わせるように、テキストデータを整形する -
chromadbライブラリを使って、bge-m3のEmbeddingモデルにてChromaの形式でベクトルDBを作成する - 画像データと生成した画像の説明文のペアを作成する(なくても良い)
- 画像と説明文の組み合わせを残すことで、ベクトル検索時の精度検証で裏付けがしやすいので
- 3.で作成したペアをバックアップとしてpklファイルに出力する
- これでいつでも画像と説明文の組み合わせを確認できるようになりました
該当ソースコード
class VectorDB:
"""ベクトルデータベースを操作するクラス"""
def __init__(self) -> None:
self.persist_directory_summarized_images = DATABASE_PATH / "summarized_images.pkl"
self.llm = LLM()
def _create_documents_from_texts(self, resource_contents: list[Resource], pdf_path: str) -> list[Document]:
"""テキストコンテンツからDocumentオブジェクトを作成する
"Args":
text_contents: 全てテキストに均したコンテンツ
pdf_path: コンテンツ抽出で使用したPDFファイルのパス
"Returns":
Documentオブジェクトに合わせたコンテンツ
"""
logger.info("Creating 'Document' objects ...")
documents: list[Document] = []
for i, resource in enumerate(resource_contents):
pdf_file_name: str = Path(pdf_path).name
doc = Document(
page_content=resource.text,
metadata={"source": pdf_file_name, "chunk_id": i, "chunk_size": len(resource.text)},
)
documents.append(doc)
logger.info("Done")
return documents
def _create_pairs_text_and_image(self, resource_contents: list[Resource]) -> None:
"""base64の画像と対応する要約文のペアを作成する
"Args":
resource_contents: 前処理済みのリソースデータ
"""
pairs: dict[str, str] = {}
for resource in resource_contents:
cat: Literal["text", "image"] = resource.category
if cat == "image":
summarized_text: str = resource.text
image_base64: str = resource.image_base64
pairs[summarized_text] = image_base64
with self.persist_directory_summarized_images.open(mode="wb") as wf:
pickle.dump(pairs, wf)
def create(self, resource_contents: list[Resource], pdf_path: str) -> None:
"""ベクトルデータベースを作成する
"Args":
text_contents: 文字列に変換済みのコンテンツ
pdf_path: PDFファイルのパス
"Returns":
パス
"""
logger.info("Creating vector store ...")
documents: list[Document] = self._create_documents_from_texts(resource_contents, pdf_path)
self.llm.create_vector_db(documents)
self._create_pairs_text_and_image(resource_contents)
logger.info("Done")
3. RAGの実施
- Chromaで作成したデータをロードする
- ユーザークエリをベクトル検索する
-
gpt-ossを使って、ベクトル検索で取得したリソースを基に回答を生成する
該当ソースコード
class RAG:
"""RAGを実施するクラス"""
def __init__(self) -> None:
self.client = OllamaLLM(model=LLM_NAME)
self.db = DB()
self.db.load_chroma_db() # 事前に準備しているDBを呼び出す
def generate_answer(self, base_prompt: str, query_text: str, *, verbose: bool = True) -> str | None:
"""RAGを使って回答を生成する
"Args":
base_prompt: ベースプロンプト
query_text: ユーザーからの入力
"Returns":
生成された回答
"""
# ベクトル検索の結果を取得する
results: dict | None = self.db.search(query_text, verbose=verbose)
if results is None:
logger.error("Not found similarity resources")
return None
resource_docs: list[str] = results["documents"]
logger.info(results)
prompt_template = f"""以下のコンテキストを参考にして、質問に回答してください。
{base_prompt}\n\n
コンテキスト:\n{resource_docs}\n
質問: {query_text}\n
回答:"""
return self.client.invoke(prompt_template)
実際に試してみる
今回使用したPDFファイルは、「デジタル庁職員による生成AIの利用実績に関する資料」というデジタル庁が公開しているPDFを使用させていただきました。
リンクは以下。
PDFファイルから画像を抽出して、その画像を説明させた結果はこんな感じ。

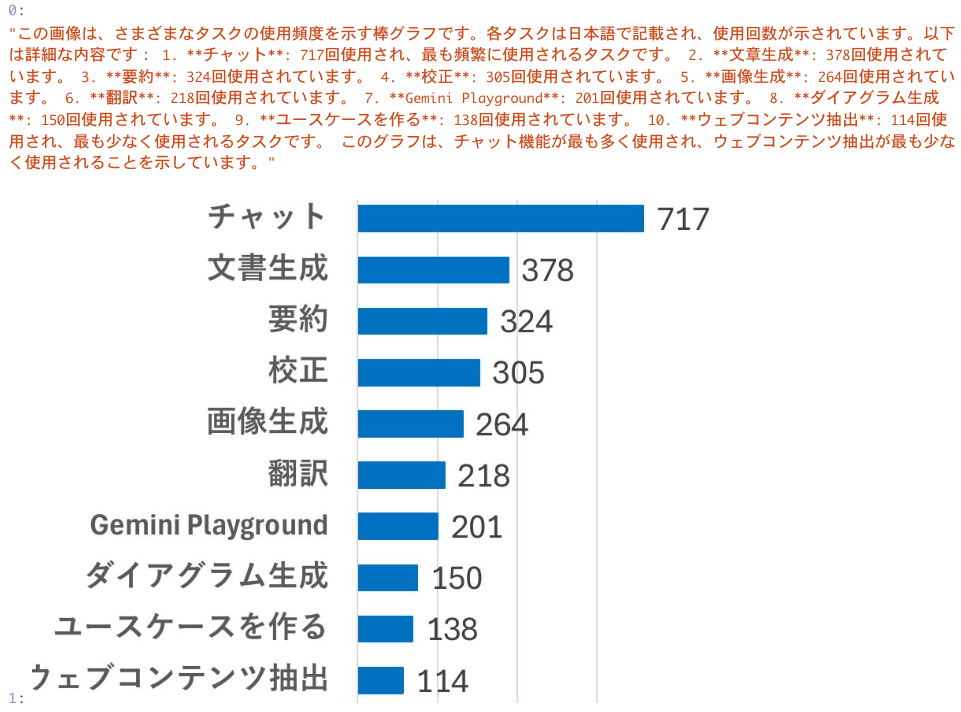
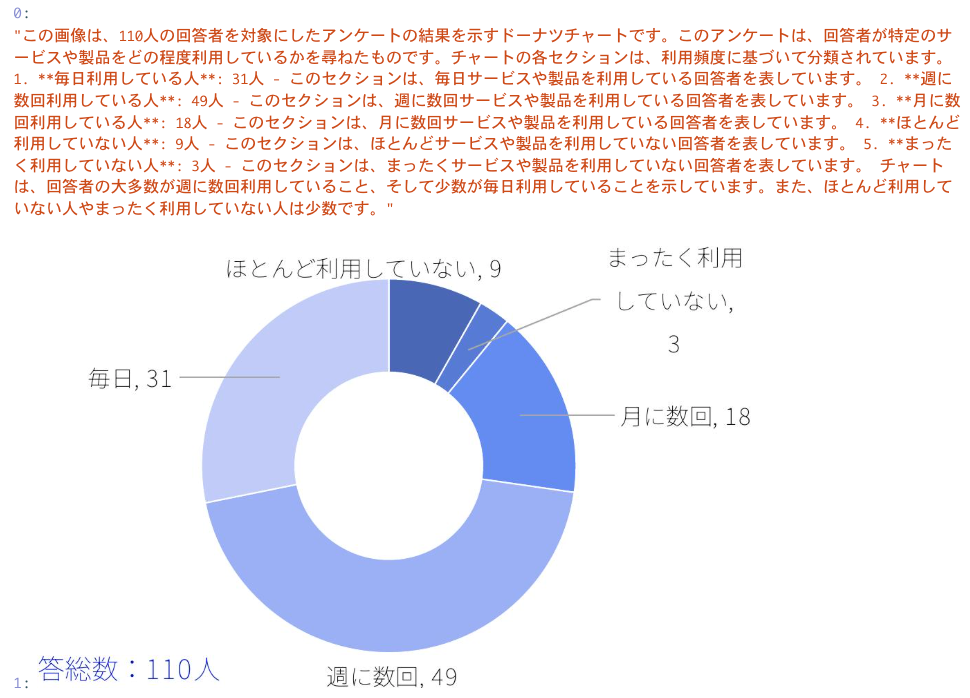

これはunstructuredライブラリに依存するところですが、そこそこ画像データが抽出できているような気がします。ただし、一部切れてしまっている画像や、記号的な画像を抽出してしまっています。
見切れている画像に関しては、unstructuredにて取得範囲のパラメータを設定可能ですが、不要な画像データに関しては制御が難しいです。
マルチモーダルRAGを実施した結果はこんな感じ。

「この画像は~~」で始まる文章は画像の説明文で、そうでない文章はOCRしたテキストのようです。良い感じにマルチモーダルRAGが実現できていそうです。
よくみると、「この画像は~~」で始まる2つの文章がほとんど同じ内容になっていますが、使用したPDFファイルを確認すると、同じグラフが2回登場していたことが原因のようです。この辺りのリソースの重複はベクトル検索時にノイズになりかねないので、ここもうまく制御する仕組みづくりができるとさらに良くなりそうです。

回答を見てみると、利用実績に関する情報は、画像から説明文に変換した内容がテーブルデータにてまとめられています。これに関しては、今回使用したVLMであるmistral-small3.2がかなり優秀だと感じています。ローカルで動作するモデルで、ここまで日本語への対応力があるとは。
また、今後の課題に関する言及では、ベクトル検索時に取得したリソースとは全く関係のない内容になっています。これはgpt-ossが内容を補完しているようですが、正確な情報でないですね。ベクトル化したリソースの分類や、ユーザークエリで複数の質問をしない、という工夫が必要かもしれません。
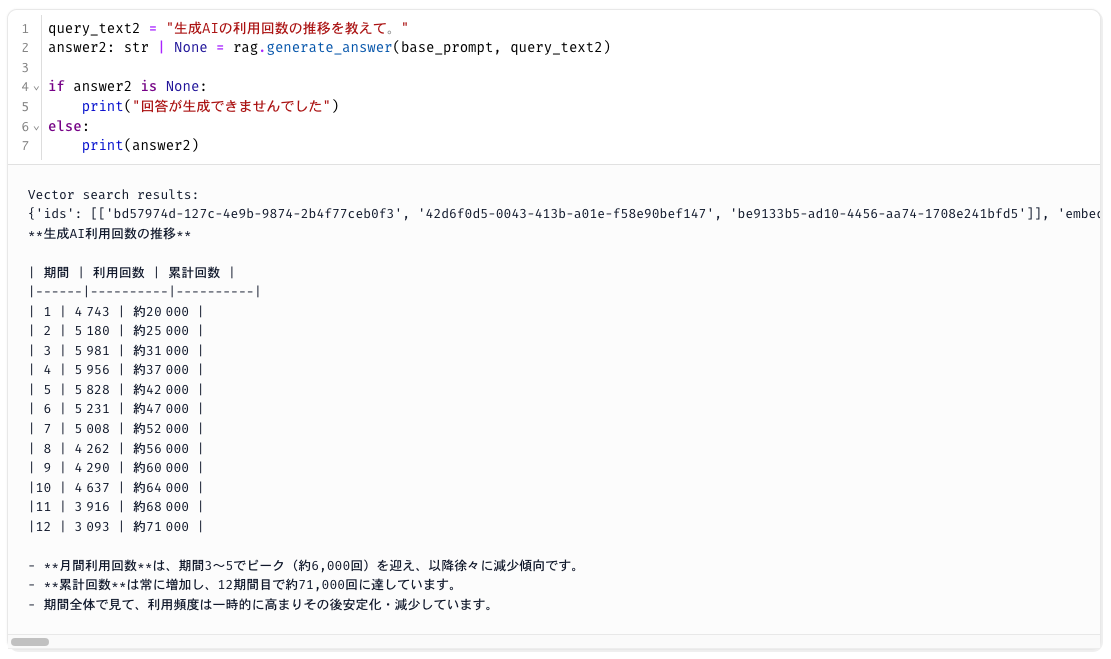
他にもクエリを投げてみました。良い感じです。
おわりに
ローカル環境だけでマルチモーダルRAGを実装してみました。想定よりも精度感が良いと感じました。
ただし、メモリ24GBの今回の場合、リソース画像の要約文生成や回答生成が1件あたり1分くらいかかるので、応答速度の観点では芳しくない結果になりました。
応答速度を上げるためにパラメータ数が10B未満のLLMも試してみましたが、かえって日本語に対する精度がガクっと下がってしまい、正確性が減少してしまいました。
これらは、あくまでOllamaを使っての話になるので、例えばHugging Faceに公開されているような日本語のファインチューニングモデルなどを使うことで、もしかすると良くなる可能性はあると思います。
また、ローカル上でマルチモーダルRAGを実現したい場面としては、以下のような場面(特に前者)が考えられそうです。
- 外部への情報漏洩のリスクを最小限にしたい
- OpenAIをはじめとするAPI利用は、学習にしようされないと明言されているものの、実態はブラックボックス化されているため不安
- 画像情報もRAGで使用したい
- 特にグラフやテーブルの情報は、OCRによってテキストだけを抽出すると見た目が失われてしまうため、本来の意図がLLMに曲解される可能性がある
- グラフ情報の場合、棒グラフなのか円グラフなのかわからなくなる
- テーブル情報の場合、カラムの関係性が失われる
- 特にグラフやテーブルの情報は、OCRによってテキストだけを抽出すると見た目が失われてしまうため、本来の意図がLLMに曲解される可能性がある
今回の実装において、いくつか改良したい点があるので、最後にメモ。
- ベクトル検索の評価指標をコサイン類似度に変更
- ChromaDBにてデフォルトがL2距離だったので、今回はL2距離のまま
- RAGのリソース検索の手法をハイブリッド検索に変更
- 日本語でのキーワード検索に対応させ、ハイブリッド検索にすることで、専門性のあるドキュメントに対する精度向上を図りたい
- 複数ファイルに対応できるように変更
- 今回はPDFファイル1つに対するRAGの構築でしたが、複数のファイルに対応するRAGを実現したい
(余談)
最近、Pythonの開発環境を色々と見直しているんですが、今回導入してみて良かったと感じたモノが3つあったので、簡単に紹介。
-
uv
- Pythonの仮想環境とライブラリ管理が一括でできるので非常に便利
- これまではずっとRyeを使っていたのですが、いつの間にかuvがRyeのポジションを完全に包含していました
- どちらも同じAstral社が開発を手掛けていることもあってか、コマンドがほとんど同じで、Ryeからuvへの移行は楽でした
-
ruff
- Pythonのlinterとして結構ルールが厳しい印象を受けていますが、どれもロバスト性を高めるためのルールだとしっかり納得できます
- ただし、少し古めなルールややっかいなルールもあるので、それはお好みで除外した方が良いです
- 個人的な設定は、基本的に全てのルールを適用しながら、
["D100", "D104", "D107", "D400", "D415", "D203", "D213", "COM812", "ISC001", "ANN201", "S101", "T201"]をignoreするようにしています- こちらを参考にさせていただき、ちょっとだけカスタムしています
-
marimo
- Jupyter Notebookの代替として使用しましたが、面白かったです
- AIコーディングをサポートしていて、notebook形式のファイルを
.pyファイルとして保存可能な点も魅力的に感じました - 画像の出力をする際にPILやcv2を使う必要がなく簡単に出力できて、結構便利でした
Givery AI Labのご紹介
Givery AI Labが独自保有するフリーランス・副業の高単価AI案件や、随時開催しているセミナーやパーティなどのイベントにご興味ございましたら、ぜひTrack Worksのアカウント登録いただき、最新情報を受け取ってください!
「Track Works」とは?
Givery AI Labの運営会社である株式会社ギブリーが提供する、AI時代のフリーランスエンジニアとして「スキル」と「実績」を強化できる実践的なAI案件を、ご経歴やスキルに合わせてご紹介するフリーランスエンジニア案件マッチングサービスです。Givery AI Labが独自保有するフリーランス・副業案件を紹介したり、AI関連技術やエンジニアのキャリアに関するイベントを随時開催しています。
また、Givery AI Labメンバーとして就職・転職をご検討いただく場合は、下記からご応募くださいませ! (運営会社である株式会社ギブリーのエンジニア向け求人一覧ページです)
【企業のご担当者様へ】
Givery AI Labでは、PoCで終わらせない「AIの社会実装」を実現するため、AI開発プロジェクトのPoCから本格実装・運用まで、幅広く伴走支援しております。ぜひお気軽にお問合せください。
・AI開発プロジェクト伴走支援サービス:https://givery.co.jp/services/ai-lab/
・生成AI技術に関するお悩み解決サービス「Givery AI 顧問」:https://givery.co.jp/services/ai_advisor/

Discussion