前置き
本記事はPart1の位置付けで、以下記事がPart2になります。
次の図は、Part1とPart2で構築するRAGパイプラインです。
スキル1〜3はPart1(本記事)で、スキル4はPart2で作成できます。
基本手順
本記事では、Azure Portal上からノーコードでOCR文書レイアウト解析(Document Layout Skill)〜RAG環境構築までを行う方法をご紹介します。
※Document Layout Skillとは、Azure Portal内のAI Searchメニュー上からDocument IntelligenceをAI Searchの前処理として設定できる機能です。
⚠️ 2025/03/06時点では、AI SearchのJapanリージョンは未対応で、EastUSリージョンでの利用になります。
事前設定
- Blob Storage ストレージアカウントの作成

- Blob Storageに適当なダミーデータを入れておく
- マルチサービスアカウント(EastUS)の作成

手順

画面1:「データのインポートとベクター化」を選択

画面2:「Azure Blob Storage」を選択

画面3:データソースの設定とDocument Layout Skillの有効化を行います
🔴 参照先のBlob Storageを選択
🔵 Document Layout Skillを有効化する場合はチェック(※事前にマルチサービスアカウントの作成が必要)
🟢 Blob Storageの削除追跡を有効化する場合にのみチェック
🟡 認証設定:「マネージドID」か「システム割り当て」を選択可能
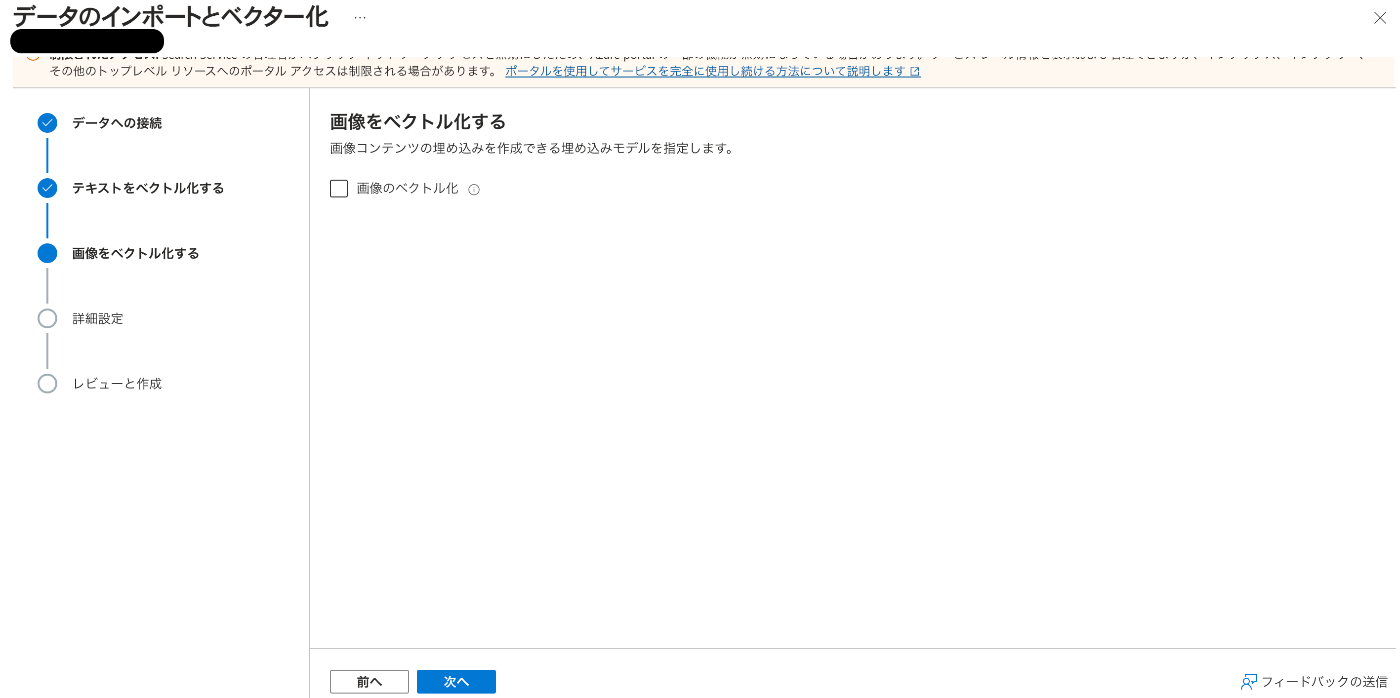
画面4:Azure OpenAIを設定

画面5:画像のベクトル化(今回はスキップ)

画面6:セマンティックランカーの設定やインデックスフィールドの設定
⚠️ Blob Storageの削除追跡をOnにする場合は、「プレビューと編集」から別途設定が必要
詳細は手順(削除追跡あり) を参照

画面7:「オブジェクト名のプレフィックス」に任意の名前を設定し、作成ボタンを押す
ここで設定したオブジェクト名のプレフィックスが、Indexの名前になる。
また、自動生成されるデータソース、スキルセット、インデクサーもこれに準じた名前になる。
例:「test」にした場合、それぞれ「test-datasource」「test-skillset」「test-indexer」となる
手順(削除追跡あり)
Blob Storageの設定
Blob StorageとAI Searchどちらも、Blobのネイティブ論理削除をOnにする設定を行う

「ストレージアカウント」-->「データ保護」から「BLOB の論理的な削除を有効にする」にチェック
AI Searchの設定
詳細は手順の画面3を参照してください。
⚠️ 追加で以下の画面からBlob Storageのmetadata_storage_last_modeifiedをメタデータとして継承をする必要がある

「インデックス フィールド」—> 「プレビューと編集」を押す
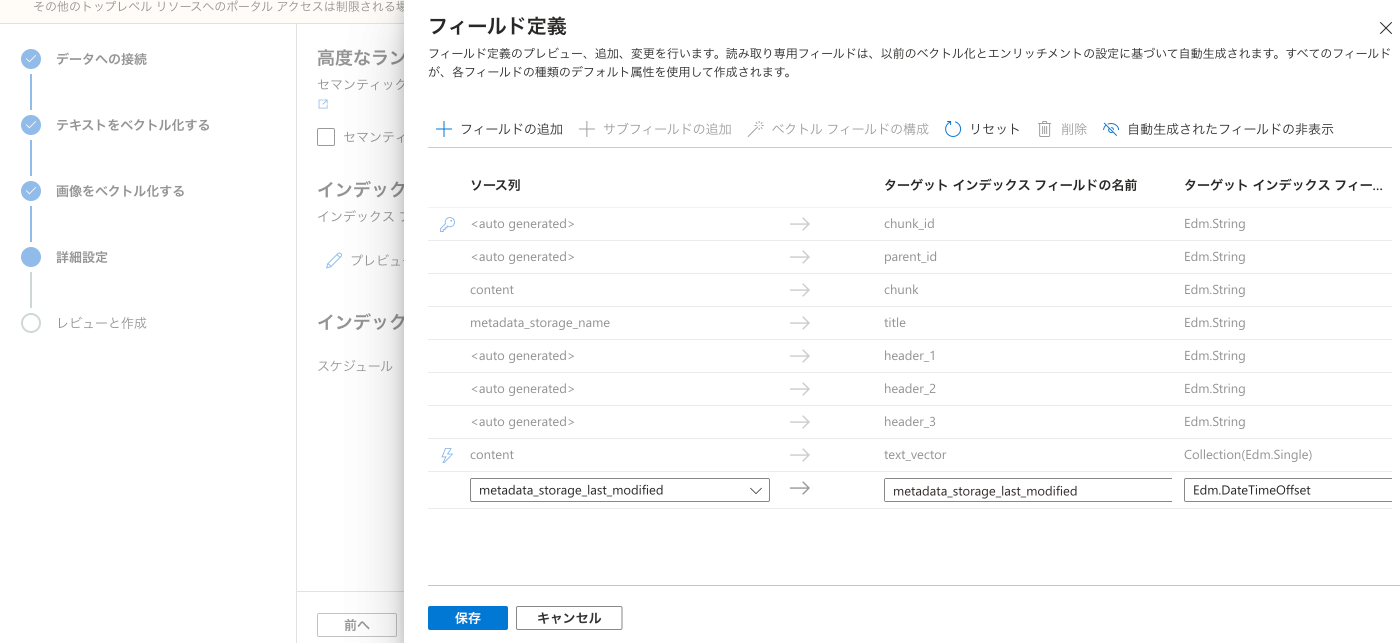
「+ フィールドの追加」からmetadata_storage_last_modifiedを追加
閉域化している場合
閉域化している場合、上記手順で進めると、インデクサー実行時に以下のエラーで停止します。
Web Api response status: 'Forbidden', Web Api response details: '{"error":{"code":"403","message": "Access denied due to Virtual Network/Firewall rules."}}'
Azure Portal 上で、AI Search —> ID
- 「システム割り当てマネージド ID」をオンにします
- 続いて以下のロールを割り当てます
- ストレージ BLOB データ共同作成者
- スコープ:ストレージ
- Cognitive Services OpenAI User
- スコープ:リソースグループ
- ストレージ BLOB データ共同作成者
共有プライベートリンクの作成
① AI Searchのネットワーク⇒共有プライベートアクセス⇒共有プライベートリンクを追加する
② 接続先のAOAI、Document Intelligence、Blob Storageなどを指定
- AI Search → AOAI、Document Intelligence、Blob Storage全てに設定するのが無難
- 設定後、それぞれのリソースのネットワーク設定画面で承認をする必要がある
Storage Accoutをネットワーク制限していた場合には例外として「信頼されたサービスの一覧にある Azure サービスがこのストレージ アカウントにアクセスすることを許可します」にチェックが入っていればマネージドIDの認証で接続が可能
③ AOAI側のネットワーク⇒プライベートエンドポイント接続⇒承認
インデクサーの再実行
①インデクサーのJSONで以下のパラメーターを設定する
"parameters": {
"configuration": {
"executionEnvironment": "private"
}
}
インデクサーJSON全体
```python
{
"@odata.context": "https://xxxxxx.search.windows.net/$metadata#indexers/$entity",
"@odata.etag": "\"xxxxxxxxxx\"",
"name": "xxxxxxx-indexer",
"description": null,
"dataSourceName": "xxxxxxxx-datasource",
"skillsetName": "xxxxxxxxx-skillset",
"targetIndexName": "xxxxxxxxx",
"disabled": null,
"schedule": null,
"parameters": {
"batchSize": null,
"maxFailedItems": null,
"maxFailedItemsPerBatch": null,
"base64EncodeKeys": null,
"configuration": {
"executionEnvironment": "private",
"dataToExtract": "contentAndMetadata",
"parsingMode": "default"
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "title",
"mappingFunction": null
}
],
"outputFieldMappings": [],
"cache": null,
"encryptionKey": null
}
```
② インデクサーを実行 成功すればOK
デバッグセッション
Azure AI Searchのデバッグセッションは、スキルセットとインデクサーの動作を視覚的に確認し、問題を特定・修正するためのツールです。
- ユースケース例
- スキルセット内でエラーが起こっている場合の問題箇所特定
- 変更をテストしてから、本番環境に適用
- スキルセットの各段階での中間処理結果の確認
デバッグセッションを使用することで、Azure AI Searchのインデクサーとスキルセットの動作を詳細に把握し、効率的に問題解決や最適化を行うことができます。

デバッグセッションの場所

デバッグセッション例
デバッグセッションでは、画面左側にIndexerのワークフローがグラフ形式で表示、画面右側に各ノードでの変数情報が表示されます。
まとめ
本記事では、Azure Portalを利用してノーコードでOCR文書レイアウト解析からRAG環境構築までの手順を解説しました。
-
事前設定:
- Blob Storageのストレージアカウントを作成し、ダミーデータを用意します。
- EastUSリージョンでのマルチサービスアカウントを作成します。
-
手順の概要:
- データのインポートとベクター化を行い、Azure Blob Storageを選択します。
- Document Layout Skillを有効化し、必要に応じてBlob Storageの削除追跡を設定します。
- Azure OpenAIの設定を行い、セマンティックランカーやインデックスフィールドを設定します。
-
削除追跡の設定:
- Blob StorageとAI Searchの両方で、Blobのネイティブ論理削除を有効にします
- Blob Storageから必要なメタデータを継承します。
-
閉域化対応:
- 閉域化環境でのエラーを回避するため、システム割り当てマネージドIDをオンにし、必要なロールを割り当てます。
- 共有プライベートリンクを作成し、各リソースのネットワーク設定を承認します。
-
デバッグセッション:
- Azure AI Searchのデバッグセッションを活用し、スキルセットとインデクサーの動作を視覚的に確認することで、問題の特定と修正を効率的に行うことができます。
以上の手順を通じて、Azure環境でのOCR文書解析とRAG環境の構築がノーコードで行えるようになります。
Givery AI Labが独自保有するフリーランス・副業の高単価AI案件や、随時開催しているセミナーやパーティなどのイベントにご興味ございましたら、ぜひTrack Worksのアカウント登録いただき、最新情報を受け取ってください!
「Track Works」とは?
Givery AI Labの運営会社である株式会社ギブリーが提供する、AI時代のフリーランスエンジニアとして「スキル」と「実績」を強化できる実践的なAI案件を、ご経歴やスキルに合わせてご紹介するフリーランスエンジニア案件マッチングサービスです。Givery AI Labが独自保有するフリーランス・副業案件を紹介したり、AI関連技術やエンジニアのキャリアに関するイベントを随時開催しています。
また、Givery AI Labメンバーとして就職・転職をご検討いただく場合は、下記からご応募くださいませ! (運営会社である株式会社ギブリーのエンジニア向け求人一覧ページです)
【企業のご担当者様へ】
Givery AI Labでは、PoCで終わらせない「AIの社会実装」を実現するため、AI開発プロジェクトのPoCから本格実装・運用まで、幅広く伴走支援しております。ぜひお気軽にお問合せください。
・AI開発プロジェクト伴走支援サービス:https://givery.co.jp/services/ai-lab/
・生成AI技術に関するお悩み解決サービス「Givery AI 顧問」:https://givery.co.jp/services/ai_advisor/
参考

Discussion