こんにちは、Givery AI Lab所属のAIエンジニア、ホウと申します。
今回は、知識蒸留(Knowledge Distillation, KD)とファインチューニング(Fine-Tuning, FT)技術について、そのコアコンセプト、LLM時代のアプローチ、比較評価、そして実際のコード例を交えて解説いたします。
1. 技術定義とコアコンセプト
1.1 モデル蒸留(Knowledge Distillation, KD)
知識蒸留(Knowledge Distillation、KD)は、教師モデル(Teacher Model)が学生モデル(Student Model)の学習を指導し、大規模モデルの能力を小規模モデルにできるだけ再現させるための知識転移技術です。Hintonらによって2015年に提案されたこの概念の核心は、教師モデルの出力分布(Soft Targets)を活用し、単なるラベルではなく、より豊かな情報を学生モデルに伝えることです。
技術ポイント
-
Soft Targetsと温度スケーリング(Temperature Scaling)
教師モデルの出力確率分布(Soft Targets)は、サンプル間の細かな関係情報を提供します。温度パラメータ Tを調整することで、Softmax計算を滑らかにし、教師モデルの「暗黙の知識」を学生モデルが学びやすくします。
-
蒸留方式
-
応答マッチング(Response-Based KD):
教師と学生の出力確率分布間のKLダイバージェンス(Kullback-Leibler Divergence)を最小化し、学生モデルが教師モデルの最終出力(logits)を模倣します。
-
特徴マッチング(Feature-Based KD):
学生モデルが教師モデルの中間層特徴表現を学習し、モデルの表現能力を向上させます。
-
関係マッチング(Relation-Based KD):
教師モデルがサンプル間の類似性や層間関係を学習し、より深い知識を捉えることを目指します。
-
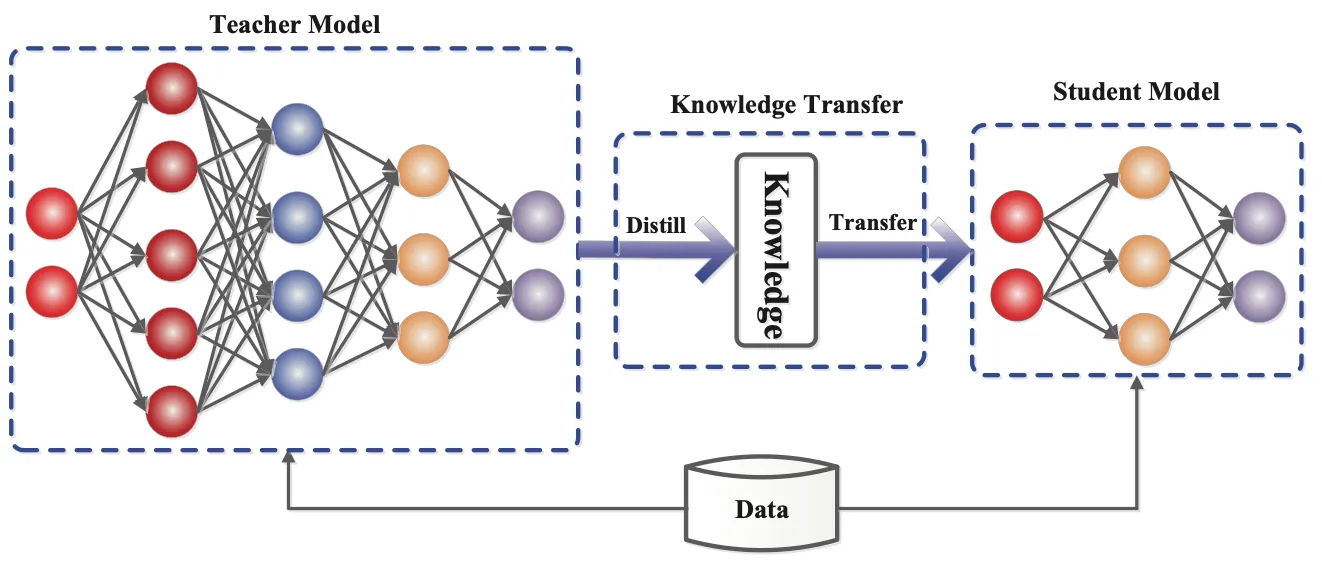
1.2 LLM時代の知識蒸留
LLM時代において、知識蒸留の目的は、モデル圧縮からより豊かな知識転移へと拡大しています。単にモデルサイズを小さくするだけでなく、教師モデルの推論戦略、文脈理解能力、および多段階推論能力を引き継ぐことを目指しています。
LLM蒸留の4段階パイプライン
LLMの知識蒸留は、通常以下の4つのコアステージに分けられます:
-
ステージ1:目標スキルまたはドメインの決定(Domain Steering)
- まず、明確な指令またはテンプレート
I
- まず、明確な指令またはテンプレート
-
ステージ2:シード知識の入力(Seed Knowledge Input)
- 次に、教師モデルに特定のシード知識(Seed Knowledge)を入力します。通常、これは小規模ながら関連性の高いデータサンプル
s
- 次に、教師モデルに特定のシード知識(Seed Knowledge)を入力します。通常、これは小規模ながら関連性の高いデータサンプル
-
ステージ3:蒸留知識の生成(Knowledge Generation)
- 教師モデルは指令とシード知識に基づいて詳細な知識出力
o D_I^{(kd)}
- 教師モデルは指令とシード知識に基づいて詳細な知識出力
-
ステージ4:学生モデルの学習(Student Model Training)
- 最後に、生成されたデータセット
D_I^{(kd)}
- 最後に、生成されたデータセット
蒸留パイプラインの数式による表現と原理解析
上記のプロセスは、以下の数式で抽象的に表現できます:
- 知識生成プロセスの数式(Knowledge Elicitation)
-
D_I^{(kd)} = \{ \text{Parse}(o, s)\ |\ o \sim p_T(o|I \oplus s),\ \forall s \sim S \} -
I -
s \sim S -
o \sim p_T(o|I \oplus s) p_T s I (I\oplus s) -
\text{Parse}(o,s)
-
- 教師モデルが高品質な知識サンプルを豊富に生成することが求められます。その知識サンプルは後続の蒸留プロセスに使用されます。
-
- 学生モデルの学習目標の数式(Learning Objective):
-
\mathcal{L} = \sum_{I}\mathcal{L}_I(D_I^{(kd)};\theta_S) -
\mathcal{L}_I(\cdot;\cdot) I -
\theta_S - 複数のタスクやドメイン知識を同時に蒸留する場合、全てのタスクの損失を合計することで、学生モデルが様々なスキルを習得できるように調整されます。
-
-
数式に込められた本質的な意味(Intuition)
- 知識生成の数式は条件付き生成プロセスを表現しています。教師モデルは、指令とシード知識の組み合わせを元に、高品質で詳細な知識サンプルを生成します。これにより、教師モデルの推論能力や細かい知識を正確に捉えることが可能です。
- 学習目標の数式は、教師モデルと学生モデルの間の差異を定量化し、教師モデルが持つ知識を学生モデルへ効果的に転移することを目的としています。この監督学習的なアプローチにより、学生モデルは特定のスキルにおいて教師モデルに近づくことができます。
1.3 事前学習モデルのファインチューニング
ファインチューニング(FT)とは、事前学習モデルを基に、特定のタスクやドメインのデータを用いてモデルを最適化し、新しいアプリケーションシナリオに適応させる手法を指します。モデルをゼロから訓練するのではなく、事前学習モデルが既に学習した一般的な表現を活用するため、少量のデータと計算コストで効率的な転移学習が可能です。典型的な例として、BERTのGLUEタスクでのFTや、GPTシリーズモデルにおける指示追従タスク(Instruction Tuning)の最適化があります。
LLM時代のFT方式
- LLMの時代において、FTの方式は主に次の2つに分類されます:
- 全量FT(Full Fine-Tuning)
- パラメータ効率FT(Parameter-Efficient Fine-Tuning, PEFT)
1.4 全量FT(Full Fine-Tuning)
全てのモデルパラメータを解凍し、対象タスクのデータで訓練を続行することで、モデルのすべての層を新しいタスクに最適化します。この方法は通常、最も優れた性能を提供できますが、代わりに以下の問題があります:
-
各タスクごとにモデル全体を個別に保存する必要がある。
例として、GPT-3(175B)をFTする場合、全てのパラメータを更新する必要があり、膨大なストレージと計算コストを必要とします。
1.5 PEFT:Parameter-Efficient Fine-Tuning
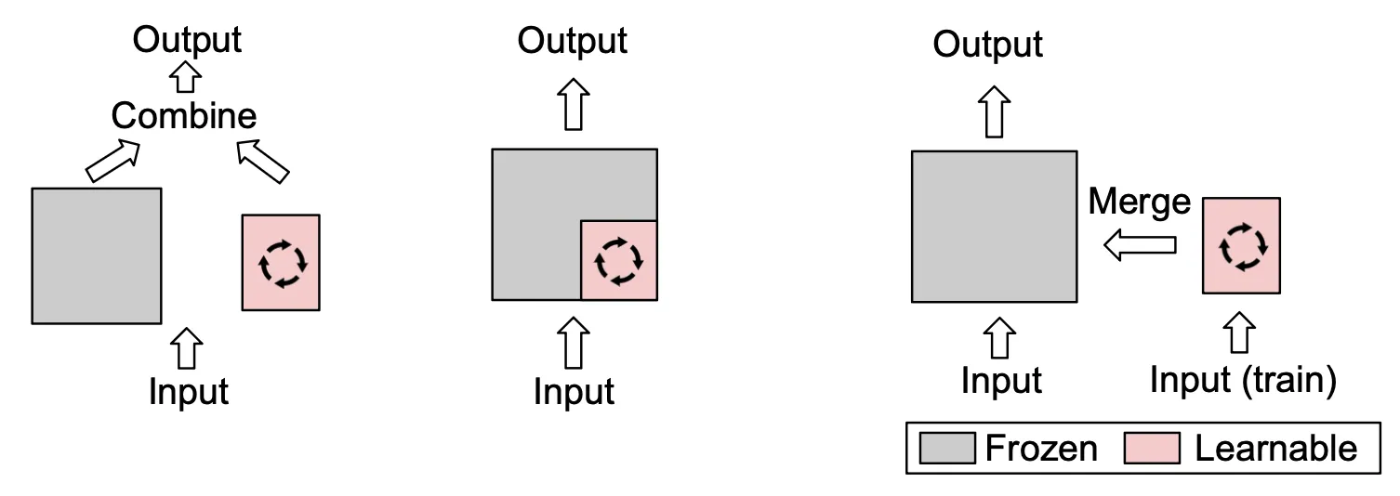
事前学習モデルの大部分のパラメータを固定し、一部のパラメータのみを調整するか、少量の新しいパラメータを追加することで、ストレージと計算コストを大幅に削減する方法です。PEFT技術は、大規模モデルの適応に広く利用されており、主に次のような手法が含まれます:
1. LoRA(低ランク適応:Low-Rank Adaptation)
-
Transformerの各層の重み行列に小規模な学習可能な低ランク行列を挿入し、この部分のみを最適化します。
元のモデルの重みは変更されません。
-
全量FTと比較して、LoRAは学習するパラメータを数千倍削減でき、性能は全量FTに近い状態を保持できます。
-
応用例: Meta社は2023年に QLoRA を提案しました。これは 4ビット量子化 とLoRAを組み合わせた技術で、1台のGPU上で65BモデルのFTを可能にし、ChatGPTの99%の性能を達成(GPT-3.5)しました。
(参考:下図右側の図)
2. Adapterモジュール(Adapter Modules)
- Transformerの特定の層に小規模なボトルネックネットワーク(例:down-project → up-project 構造)を挿入し、FT時にはこれらのAdapter層のみを調整します。
-
利点:
- 異なるタスクごとに異なるAdapterモジュールを使用でき、単一の基盤モデルで複数のタスクに適応できる。
- 基本モデルを何度も訓練する必要がなく、効率的にタスクを追加できます。
- 応用例: Adapter技術は、機械翻訳、多タスク学習、クロスドメイン適応などのタスクで良好な結果を示しています。
(参考:下図中央の図)
3. Prompt Tuning / Prefix Tuning
-
Prompt Tuning:
モデルに追加の学習可能な埋め込みベクトル(Prompt Tokens)を学習させ、それを入力の一部として利用します。モデル自体の重みは調整しません。
-
Prefix Tuning:
Transformerの隠れ層に学習可能な前置きベクトル(Prefix Vectors)を追加し、推論全体のプロセスに影響を与えます。
-
利点:
- 調整するパラメータはごく少量(数十から数百の追加パラメータ)で済む。
- 特に GPT-3 以降の巨大モデルに適用する際に有効で、FTコストを大幅に削減可能。
(参考:下図左側の図)
2. 知識蒸留とFT技術の比較
知識蒸留とFT技術を体系的に比較するために、以下の3つの側面から検討を行います:実現方式、性能の比較、および実際の導入。
2.1 技術の実現
実現フローにおいて、知識蒸留とFTは大きく異なります。以下の図は、それぞれの典型的なフローを示しています:
-
主な違い
- KD の利点は、モデルの圧縮にあり、計算コストの削減が可能です。
- FT は、特定のドメインへの迅速な適応が可能で、特に性能を重視する場合に有効です。
2.2 性能面の比較(Performance & Efficiency)
以下に、TinyBERTやDistilBERTに関する論文での結果を例として比較を行います。
モデル精度の比較(GLUE Benchmark)
| モデル例 | GLUE Benchmark のスコア |
|---|---|
| BERT-base (教師モデル) | 基準(100%) |
| TinyBERT (4層) | 約 96.8%(BERT-baseより約3.2%低い) |
| TinyBERT (6層) | BERT-base と同等(~100%) |
| DistilBERT | 約 97%(BERT-baseより約3%低い) |
効率の比較(パラメータ数と推論速度)
| モデル例 | パラメータ数 | 推論速度 |
|---|---|---|
| BERT-base | 110M (100%) | 基準 (1x) |
| DistilBERT | 66M (約60%) | BERT-base より約60%高速 (1.6x) |
| TinyBERT (4層) | 15M (約13%) | - |
パフォーマンス評価のポイント:
-
知識蒸留 (KD):
精度と効率のバランスを提供します。特に、リアルタイム推論やエッジデバイスでの利用に適しています。
-
FT (ファインチューニング):
限定的なパラメータ調整で高精度を維持できますが、速度と計算資源の最適化においてはKDに劣る場合があります。
2.3 実際の導入における考慮すべきポイント
ハードウェアコスト
-
知識蒸留 (KD):
モデルサイズを大幅に削減できるため、メモリ消費や計算リソースの要求を大幅に軽減できます。特に、モバイルデバイスやエッジコンピューティングに適しています。
-
全量FT (Full FT):
完全なモデル(例:GPT-3)のロードが必要で、メモリやハードウェアリソースの要求が非常に高い。
-
パラメータ効率FT (PEFT):
大部分のパラメータを固定することで、少量のパラメータのみを調整し、計算とストレージのコストを大幅に削減。
3. 技術選択
蒸留と微調整を効果的に使い分けるため、以下の意思決定ツリーを作ってみました。
技術選択の基準
-
知識蒸留 (KD):
モデルを小型化しつつ、大規模モデルの能力をできる限り保持する場合に適しています。
例:GPT-3をモバイルデバイスに蒸留することで、元のモデルに近い性能を保ちながら、展開コストを削減することができます。
-
ファインチューニング(FT):
特定のドメインに新たな知識を注入する必要がある場合に最適です。
例:医療分野におけるQAモデルで、モデルを新しいデータで訓練し、対象ドメインに正確に適応させることができます。
-
直接使用または圧縮方法:
元のモデル能力を維持する必要も、新しい知識を追加する必要もない場合には、事前学習モデルを直接使用するか、プルーニングや量子化 などの圧縮手法を適用することが推奨されます。
4. サンプルコード
知識蒸留
ステップ1:教師モデルの準備(Teacher Model)
from transformers import GPT2LMHeadModel, GPT2TokenizerFast
import torch
teacher_model_name = 'gpt2-large'
teacher_model = GPT2LMHeadModel.from_pretrained(teacher_model_name)
teacher_tokenizer = GPT2TokenizerFast.from_pretrained(teacher_model_name)
teacher_model.eval()
-
解釈
- 事前学習済みの大規模言語モデル(GPT2-large) を教師モデルとしてロードします。
-
GPT2LMHeadModelはテキスト生成や確率計算に適した言語モデルです。 - モデルを
eval()に設定することで評価モードに切り替え、蒸留中のパラメータ更新を防ぎます。
ステップ2:学生モデルの準備(Student Model)
student_model_name = 'distilgpt2'
student_model = GPT2LMHeadModel.from_pretrained(student_model_name)
student_tokenizer = GPT2TokenizerFast.from_pretrained(student_model_name)
-
解釈
- 小規模な学生モデル DistilGPT2 をロードします。これは GPT2 の圧縮版であり、パラメータが少なく推論効率が高いです。
- この学生モデルは、教師モデルによって提供されるソフトターゲット(soft targets)を学習するように訓練されます。
ステップ3:蒸留損失の定義(Distillation Loss)
import torch.nn.functional as F
def distillation_loss(student_logits, teacher_logits, temperature=2.0):
student_probs = F.log_softmax(student_logits / temperature, dim=-1)
teacher_probs = F.softmax(teacher_logits / temperature, dim=-1)
loss = F.kl_div(student_probs, teacher_probs, reduction='batchmean') * (temperature ** 2)
return loss
-
解釈
- この関数は蒸留損失の計算を行います。
- 核となるのは KL散度(Kullback-Leibler Divergence) を用いた比較です。
- 計算手順:
- 教師モデルと学生モデルの出力 (
logits) を温度パラメータ (temperature) で調整。 - 学生モデルは
log_softmax、教師モデルはsoftmaxにより確率分布を生成。 -
F.kl_divを使用して両者の確率分布の差異を測定。 - 損失値に温度の平方を掛けることで、勾配のスケールを安定化させます。
- 教師モデルと学生モデルの出力 (
- 温度 (
T) が高いほど、教師モデルの出力分布が平滑化され、学生モデルが学習しやすくなります。
ステップ4:蒸留トレーニングループ(Training Loop)
from torch.optim import AdamW
optimizer = AdamW(student_model.parameters(), lr=5e-5)
temperature = 4.0
epochs = 3
texts = ["Knowledge distillation transfers knowledge from large models to smaller ones."] # サンプルデータ
inputs = student_tokenizer(texts, return_tensors='pt', padding=True)
for epoch in range(epochs):
student_model.train()
optimizer.zero_grad()
with torch.no_grad():
teacher_outputs = teacher_model(**inputs).logits
student_outputs = student_model(**inputs).logits
loss = distillation_loss(student_outputs, teacher_outputs, temperature)
loss.backward()
optimizer.step()
print(f"Epoch {epoch + 1}/{epochs}, Distillation Loss: {loss.item():.4f}")
-
解釈
- AdamWオプティマイザ を使用して学生モデルのパラメータを更新。
- 各エポックで以下を実行:
- 教師モデルはパラメータ更新なしで
logitsを生成。 - 学生モデルは
logitsを生成し、教師モデルの出力との損失を計算。 - 損失を逆伝播して学生モデルのパラメータを更新。
- 教師モデルはパラメータ更新なしで
- 繰り返し学習することで、学生モデルは教師モデルに近い性能を得られるようになります。
パラメータ効率FT(PEFT)サンプルコード(LoRAを用いたGPT-2のFT)
ステップ1:PEFTライブラリのインストール
pip install peft transformers datasets
- Hugging Face の PEFT ライブラリ(LoRA などの手法をサポート)
- transformers ライブラリ(モデルのロードとトレーニング)
- datasets ライブラリ(データセットの処理)
ステップ2:事前学習モデルとデータセットのロード
from transformers import GPT2LMHeadModel, GPT2TokenizerFast, Trainer, TrainingArguments
from peft import LoraConfig, get_peft_model
from datasets import load_dataset
model_name = 'gpt2'
tokenizer = GPT2TokenizerFast.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
dataset = load_dataset('wikitext', 'wikitext-2-raw-v1', split='train[:1%]')
def tokenize_function(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length', max_length=128)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
tokenized_dataset.set_format('torch', columns=['input_ids', 'attention_mask'])
-
解釈
- 事前学習済みのGPT-2モデル をロードして、FTのベースモデルとします。
- 小規模なWikiTextデータセットをサンプルとしてロードし、トークン化(tokenize)処理を行います。
- トークン化されたデータセットは
input_idsとattention_maskの形式に変換され、後のトレーニングに使用されます。
ステップ3:LoRAパラメータの設定
lora_config = LoraConfig(
task_type="CAUSAL_LM",
r=8, # 低ランク行列のランク、値が小さいほど学習パラメータが少なくなる(例:4〜16が一般的)
lora_alpha=32, # LoRA の学習効果を制御するパラメータ
lora_dropout=0.1, # 過学習を防ぐためのドロップアウト率
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
-
解釈
- LoRA の設定を行い、モデルに適用する準備を整えます。
-
r(ランク値) が小さいほど、学習パラメータが減少し、効率が向上します。 -
lora_alphaは学習速度と性能に影響を与え、通常は10〜100の範囲で調整されます。 -
lora_dropoutは学習時の過学習を防止するために使用されます。 -
get_peft_model()を使用することで、既存のモデルに LoRA の低ランク行列を追加できます。 -
model.print_trainable_parameters()は LoRA の適用後に訓練対象となるパラメータの数を表示し、通常は元のモデルの 0.1% 〜 1% に抑えられます。
ステップ4:FTトレーニングループ
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)
training_args = TrainingArguments(
output_dir="./gpt2-lora",
num_train_epochs=3,
per_device_train_batch_size=8,
learning_rate=2e-4,
logging_steps=10,
save_total_limit=2,
save_strategy='epoch'
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
data_collator=data_collator,
)
trainer.train()
-
解釈
-
DataCollatorForLanguageModelingはトレーニング用のデータをバッチ化するための補助クラスです。-
tokenizerは事前にロード済みのGPT2TokenizerFastです。 -
mlm=Falseは マスクド言語モデル (Masked Language Modeling) を使わないことを意味します。- これはGPT系モデル(例:GPT-2)が 因果言語モデル (Causal Language Modeling) であるためです。
- 因果言語モデルでは、トークンの出力が前のトークンにのみ依存するように学習されます。
-
-
Trainerクラスを使用してモデルのトレーニングを行います。 -
TrainingArgumentsの設定:-
num_train_epochs:エポック数。ここでは3回のトレーニングを行います。 -
per_device_train_batch_size:1つのデバイス(GPUまたはCPU)で使用するバッチサイズ。 -
learning_rate:学習率。 -
save_total_limit:保存するモデルのバージョン数を制限。 -
save_strategy:モデル保存のタイミングを設定。エポックごとに保存されます。
-
-
参考
DistilBERT, a distilled version of BERT
TinyBERT: Distilling BERT for Natural Language Understanding
LoRA: Low-Rank Adaptation of Large Language Models
QLoRA: Efficient Finetuning of Quantized LLMs
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
A Survey on Knowledge Distillation of Large Language Models
最後に、Givery AIラボでは、最新の生成AI技術を活用し、PoCやAI導入支援など、さまざまなニーズにお応えするソリューションを提供しています。ご興味がある方は、ぜひ以下よりお問い合わせください。
Givery AI Labが独自保有するフリーランス・副業の高単価AI案件や、随時開催しているセミナーやパーティなどのイベントにご興味ございましたら、ぜひTrack Worksのアカウント登録いただき、最新情報を受け取ってください!
「Track Works」とは?
Givery AI Labの運営会社である株式会社ギブリーが提供する、AI時代のフリーランスエンジニアとして「スキル」と「実績」を強化できる実践的なAI案件を、ご経歴やスキルに合わせてご紹介するフリーランスエンジニア案件マッチングサービスです。Givery AI Labが独自保有するフリーランス・副業案件を紹介したり、AI関連技術やエンジニアのキャリアに関するイベントを随時開催しています。
また、Givery AI Labメンバーとして就職・転職をご検討いただく場合は、下記からご応募くださいませ! (運営会社である株式会社ギブリーのエンジニア向け求人一覧ページです)
【企業のご担当者様へ】
Givery AI Labでは、PoCで終わらせない「AIの社会実装」を実現するため、AI開発プロジェクトのPoCから本格実装・運用まで、幅広く伴走支援しております。ぜひお気軽にお問合せください。
・AI開発プロジェクト伴走支援サービス:https://givery.co.jp/services/ai-lab/
・生成AI技術に関するお悩み解決サービス「Givery AI 顧問」:https://givery.co.jp/services/ai_advisor/

Discussion