Closed12
100日チャレンジ day16 (ElasticSearchをつかったポケモン図鑑)
昨日
100日チャレンジに感化されたので、アレンジして自分でもやってみます。
やりたいこと
- 世の中のさまざまなドメインの簡易実装をつくり、バックエンドの実装に慣れる(dbスキーマ設計や、関数の分割、使いやすいインターフェイスの切り方に慣れる
- 設計力(これはシステムのオーバービューを先に自分で作ってaiに依頼できるようにする
- 生成aiをつかったバイブコーティングになれる
- 実際にやったことはzennのスクラップにまとめ、成果はzennのブログにまとめる(アプリ自体の公開は必須ではないかコードはgithubにおく)
できたもの
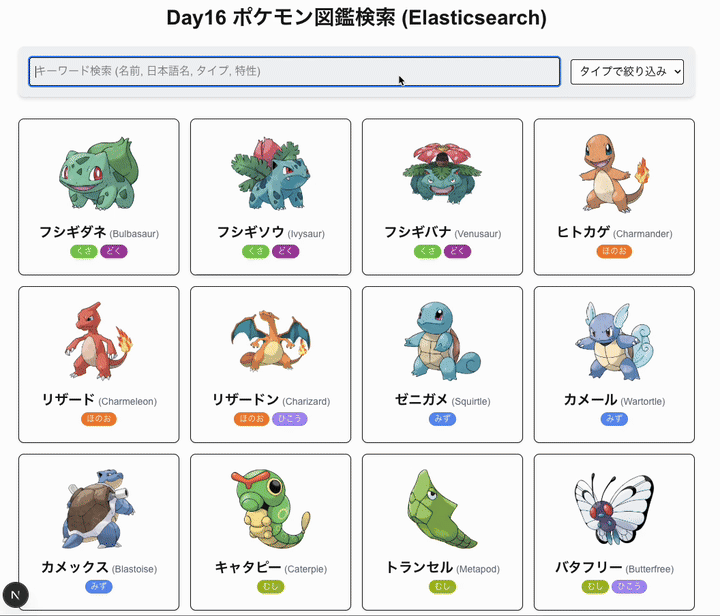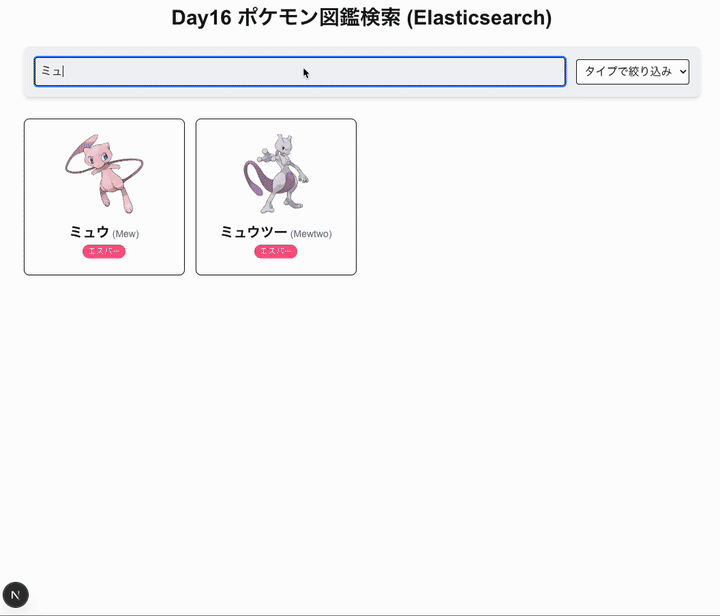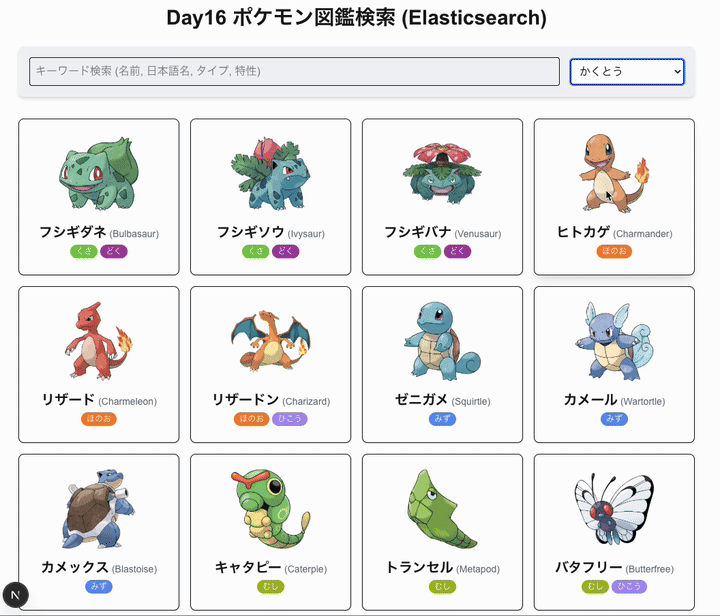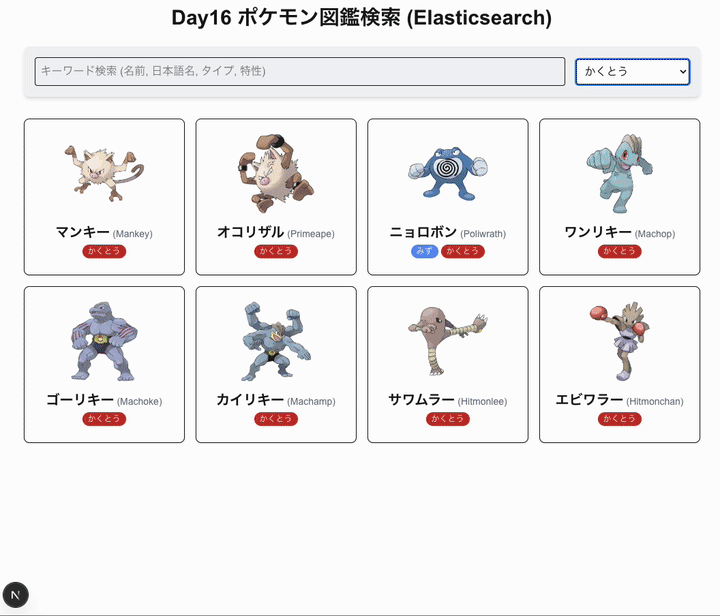
今日は elastic search を使いたい。
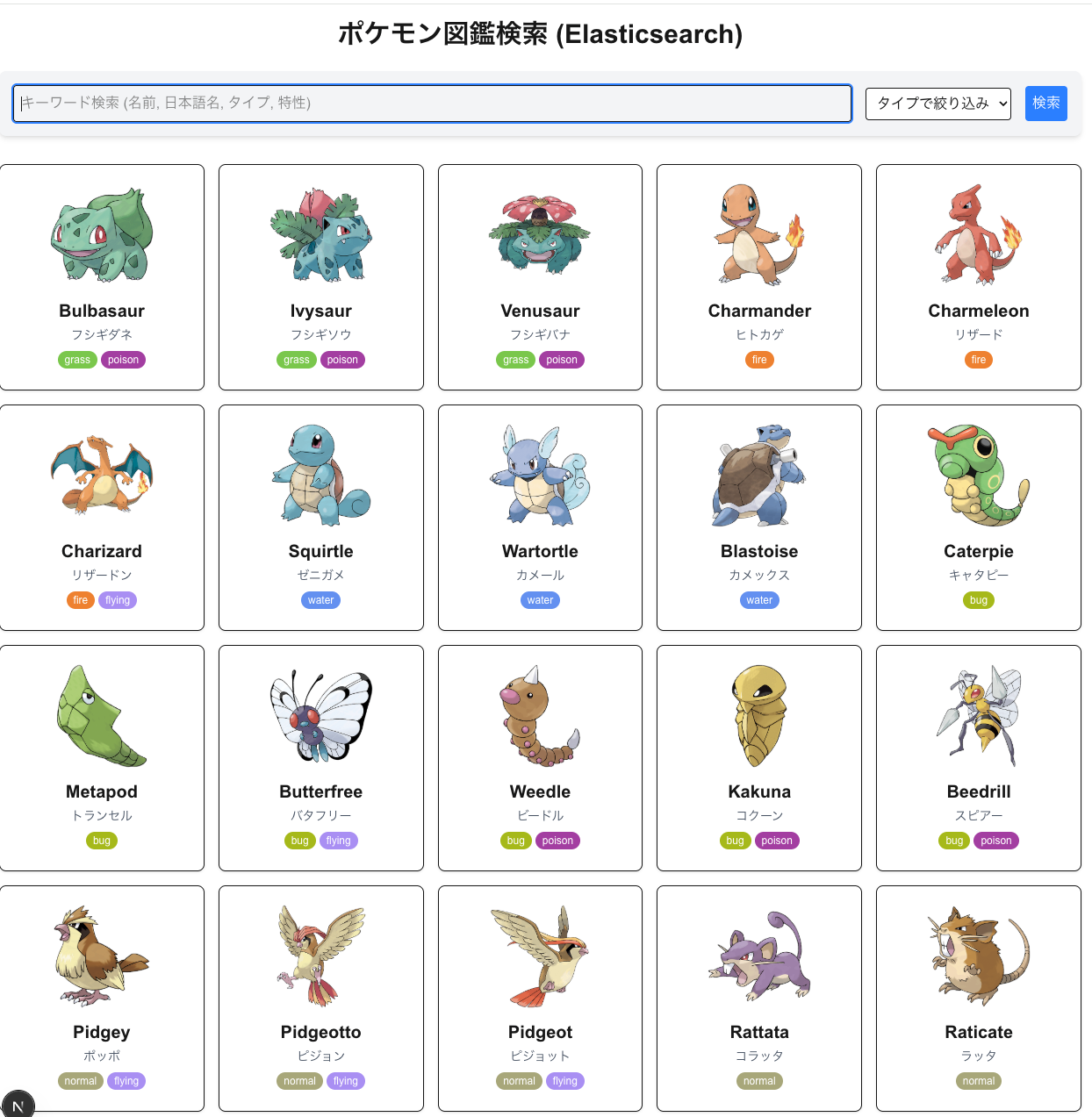
ポケモンを検索できるようにしよう
Day 16: ポケモン図鑑検索アプリ開発 (Elasticsearch 活用)
概要
Next.js (App Router), TypeScript, Prisma, SQLite, Tailwind CSS, そして Elasticsearch を使用して、ポケモン図鑑検索アプリケーションを開発します。
要件
- データソース: PokeAPI (@https://pokeapi.co/docs/v2#pokemon-species ) からポケモンデータを取得します。
- データ永続化: ポケモンの基本情報(ID, 英語名, 日本語名, タイプ, 特性, 画像URLなど)を SQLite に保存します(Prisma を使用)。
-
検索エンジン: SQLite のデータを Elasticsearch にインデックスし、検索機能を提供します。日本語での検索も可能にします。
- GET https://pokeapi.co/api/v2/pokemon-species/{id or name}/ などを使って日本語で取得してください
- 対象のポケモンは id1~151 に絞ってください
-
機能:
- ポケモン一覧表示(ページネーション付き)
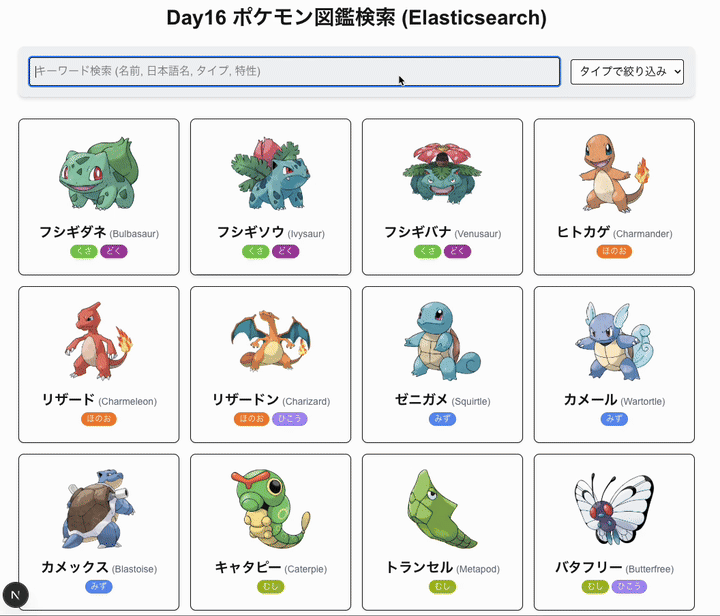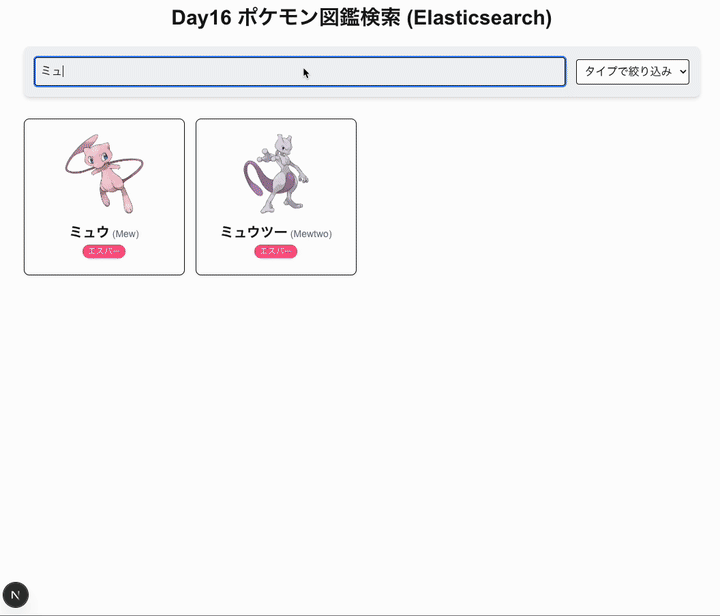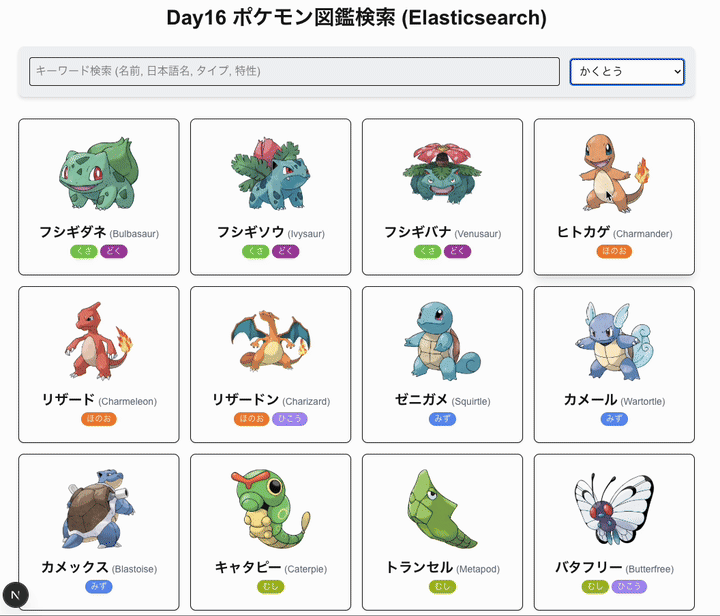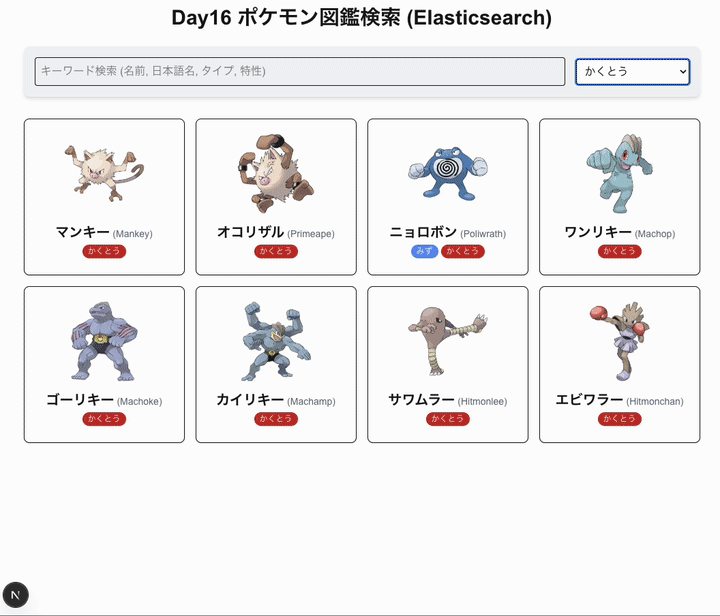
- キーワード検索(名前、日本語名、タイプ、特性などで検索 - Elasticsearch)
- タイプによる絞り込み検索(Elasticsearch)
- UI: Tailwind CSS を使用したシンプルな検索インターフェースと結果表示。
- API: Next.js Route Handlers を使用して検索 API を実装します。
-
Elasticsearch:
- ローカル環境の Docker で Elasticsearch (例: 8.14.0) が
http://localhost:9200で動作させてください (xpack.security.enabled=false)。 - Elasticsearch クライアントライブラリ (
@elastic/elasticsearch) を使用します。 - 日本語検索のために適切なインデックスマッピングとアナライザー (例:
kuromoji) を設定します。
- ローカル環境の Docker で Elasticsearch (例: 8.14.0) が
開発ステップ
-
プロジェクト初期化:
-
templateディレクトリをコピーしてday16_pokemon_searchディレクトリを作成します。 -
package.jsonのnameをday16_pokemon_searchに変更します。 - elasticsearch の準備、起動(npm コマンドへの追加)
-
README.mdを今回のアプリの概要で更新します。 - 必要な依存関係 (
@elastic/elasticsearch, 必要ならaxios等) をインストールします。
-
-
データモデリング (Prisma):
-
schema.prismaにPokemonモデルを定義します。 -
npx prisma migrate deployを実行してDBスキーマを適用します。
-
-
データ取得・永続化スクリプト:
- PokeAPI から必要なポケモンデータを取得し、Prisma を使って SQLite に保存するスクリプト (
scripts/seed.tsなど) を作成します。 - このスクリプトを実行して初期データを投入します。
- PokeAPI から必要なポケモンデータを取得し、Prisma を使って SQLite に保存するスクリプト (
-
Elasticsearch インデックス作成・データ投入スクリプト:
- Elasticsearch に
pokemonsインデックスを作成します。適切なマッピング(特に日本語テキストフィールド用のアナライザー指定)を設定します。 - SQLite のデータを読み込み、Elasticsearch に一括投入 (bulk index) するスクリプト (
scripts/indexToEs.tsなど) を作成します。 - このスクリプトを実行して Elasticsearch にデータを投入します。
- Elasticsearch に
-
API実装:
-
/api/pokemons(GET): ポケモン一覧取得 API (任意: SQLite から取得、ページネーション) -
/api/pokemons/search(GET): ポケモン検索 API (Elasticsearch を使用。queryパラメータでキーワード、typeパラメータでタイプ絞り込み)
-
-
UI実装:
- ルートページ (
/) または/searchページを作成。 - 検索キーワード入力欄、タイプ選択ドロップダウン(またはチェックボックス)を設置。
- 検索結果を一覧表示するコンポーネントを作成。
- ルートページ (
-
フロントエンドと API の連携:
- UI から検索 API を呼び出し、結果を表示します。
-
テスト:
- API を
curlでテストします。 - UI 操作を Playwright でテストします(必要に応じて)。
- API を
-
ドキュメント:
-
README.mdを最終化します。 -
.cursor/rules/knowledge.mdcに Day 16 のエントリを追加します。
-
その他指示
- 既存のカスタム指示 (
<custom_instructions>) に従ってください。 - 不明点があれば質問してください。
- Elasticsearch のクエリはまずシンプルな
matchクエリから始め、必要に応じてboolクエリなどを組み合わせてください。
ポケモン情報を取得する api があるのか、すごいな
npm run dev も cursor にやらせたらサーバのエラーログもみてくれるようになった。
最高
もうできた

sqlite から es に import するスクリプト
なるほどこうやるのか
import { Client } from "@elastic/elasticsearch";
import { PrismaClient } from "../app/generated/prisma";
// import dotenv from 'dotenv'; // dotenv 関連削除
// import path from 'path';
// dotenv.config({ path: path.resolve(__dirname, '../.env') });
// console.log('ELASTICSEARCH_URL after dotenv.config():', process.env.ELASTICSEARCH_URL);
const prisma = new PrismaClient();
// .env ファイルから Elasticsearch の URL を読み込む
// const ELASTICSEARCH_URL = process.env.ELASTICSEARCH_URL;
const ELASTICSEARCH_URL = "http://localhost:9200"; // URL を直接指定
if (!ELASTICSEARCH_URL) {
console.error(
"Elasticsearch URL not found. Please set ELASTICSEARCH_URL in your .env file."
);
process.exit(1);
}
const client = new Client({ node: ELASTICSEARCH_URL });
const INDEX_NAME = "pokemons";
async function main() {
console.log("Indexing data to Elasticsearch...");
// インデックスが存在しない場合に作成する関数 (main 内に移動)
async function createIndexIfNotExists() {
const indexExists = await client.indices.exists({ index: INDEX_NAME });
if (!indexExists) {
console.log(`Index '${INDEX_NAME}' does not exist. Creating...`);
await client.indices.create({
index: INDEX_NAME,
settings: {
analysis: {
analyzer: {
kuromoji_analyzer: {
type: "custom",
tokenizer: "kuromoji_tokenizer",
filter: [
"kuromoji_baseform",
"kuromoji_part_of_speech",
"cjk_width",
"kuromoji_stemmer",
"lowercase",
],
},
},
},
},
mappings: {
properties: {
id: { type: "integer" },
name: { type: "keyword" },
nameJa: {
type: "text",
analyzer: "kuromoji_analyzer",
fields: {
keyword: {
type: "keyword",
ignore_above: 256
}
}
},
types: { type: "keyword" },
abilities: { type: "keyword" },
typesJa: { type: "keyword" },
abilitiesJa: { type: "keyword" },
imageUrl: { type: "keyword", index: false },
height: { type: "integer" },
weight: { type: "integer" },
},
},
});
console.log(`Index '${INDEX_NAME}' created.`);
} else {
console.log(`Index '${INDEX_NAME}' already exists.`);
}
}
// Bulk API でポケモンデータを投入する関数 (main 内に移動)
// biome-ignore lint/suspicious/noExplicitAny: Prisma の型推論を使うため引数の型を any に
async function bulkIndexPokemons(pokemons: any[]) {
console.log(`Bulk indexing ${pokemons.length} Pokemon...`);
const operations = pokemons.flatMap((doc) => [
{ index: { _index: INDEX_NAME, _id: doc.id.toString() } },
{
...doc,
types: typeof doc.types === 'string' ? JSON.parse(doc.types) : doc.types,
abilities: typeof doc.abilities === 'string' ? JSON.parse(doc.abilities) : doc.abilities,
typesJa: doc.typesJa && typeof doc.typesJa === 'string' ? JSON.parse(doc.typesJa) : doc.typesJa,
abilitiesJa: doc.abilitiesJa && typeof doc.abilitiesJa === 'string' ? JSON.parse(doc.abilitiesJa) : doc.abilitiesJa,
},
]);
const bulkResponse = await client.bulk({ refresh: true, operations });
if (bulkResponse.errors) {
const erroredDocuments: { status: number, error: any, operation: any, document: any }[] = [];
// biome-ignore lint/complexity/noForEach: エラー処理
bulkResponse.items.forEach((action: any, i: number) => {
const operation = Object.keys(action)[0] as keyof typeof action;
if (action[operation]?.error) {
erroredDocuments.push({
status: action[operation]?.status ?? 0,
error: action[operation]?.error,
operation: operations[i * 2],
document: operations[i * 2 + 1],
});
}
});
console.error("Bulk indexing failed for some documents:", JSON.stringify(erroredDocuments, null, 2));
} else {
console.log(`Successfully indexed ${pokemons.length} Pokemon.`);
}
const count = await client.count({ index: INDEX_NAME });
console.log(`Total documents in index '${INDEX_NAME}': ${count.count}`);
}
try {
// 1. インデックス存在チェックと作成
await createIndexIfNotExists();
// 2. SQLite からデータ取得
console.log("Fetching data from SQLite...");
const pokemons = await prisma.pokemon.findMany();
console.log(`Fetched ${pokemons.length} Pokemon from SQLite.`);
if (pokemons.length === 0) {
console.log("No Pokemon data found in SQLite. Run `npm run seed` first.");
return;
}
// 3. Elasticsearch へ Bulk Index
await bulkIndexPokemons(pokemons);
console.log("Indexing finished.");
} catch (error) {
console.error("Error during indexing:", error);
process.exit(1);
} finally {
await prisma.$disconnect();
}
}
main();
これが es へのクエリ
// biome-ignore lint/suspicious/noExplicitAny: ESクエリは複雑になりがち
const esQuery: any = {
bool: {
must: [], // AND 条件
should: [], // OR 条件 (スコアに影響)
filter: [], // AND 条件 (スコアに影響しない)
},
};
// キーワード検索条件
if (query) {
// bool クエリの should 句で各フィールドに対する match クエリを OR 条件で指定
esQuery.bool.should = [
{ match: { name: { query: query } } }, // 英語名 (boost 削除)
{ match: { nameJa: { query: query, boost: 2 } } }, // 日本語名 (match クエリ, boost=2)
{ term: { types: { value: query } } },
{ term: { abilities: { value: query } } },
{ term: { typesJa: { value: query } } },
{ term: { abilitiesJa: { value: query } } }
];
// should 句のいずれか一つにマッチすればよいため、minimum_should_match を 1 に設定
esQuery.bool.minimum_should_match = 1;
} else {
// キーワードがない場合は should 句は空
}
// タイプ絞り込み条件
if (typeFilter) {
esQuery.bool.filter.push({
term: {
types: typeFilter,
},
});
}
// 最終的なクエリを組み立て
let finalQuery;
if (esQuery.bool.must.length === 0 && esQuery.bool.filter.length === 0 && esQuery.bool.should.length === 0) {
// 条件が何もない場合は全件検索
finalQuery = { match_all: {} };
} else {
finalQuery = esQuery;
}
console.log("Executing ES Query:", JSON.stringify(finalQuery, null, 2)); // デバッグログ追加
try {
const result = await client.search({
index: INDEX_NAME,
query: finalQuery, // 修正したクエリを使用
size: 100,
sort: [
{ _score: { order: "desc" } },
{ id: { order: "asc" } },
],
});
// _source のみを抽出して返す
// biome-ignore lint/suspicious/noExplicitAny: SearchHit の型推論のため -> 不要に
const hits = result.hits.hits.map((hit) => hit._source); // 型注釈を削除して推論させる
console.log(`Search API returned ${hits.length} results.`);
return NextResponse.json(hits);
} catch (error: any) {
console.error("Error searching Elasticsearch:", error.meta?.body || error);
return NextResponse.json(
{ error: "Failed to search Pokemon data", details: error.message },
{ status: 500 }
);
}
なるほどなー sqlite の fts よりシンプルにクエリかけるな。
あっちは SQL で書かないといけないので結構辛かったけど、こっちは柔軟性がある
このスクラップは4ヶ月前にクローズされました