Google Cloud Next '25 をみる
一次資料をあたるのが一番なんだけど、まあ大枠が知れればいいので楽をする
Google Cloud Next '25 速報レポート - キーノート(1日目) - G-gen Tech Blog
感想
- AI 自体の進化を目玉にしている
- AIの周辺環境の整備と、プラットフォーマーとして勝つにはどうすべきか?から生まれたプロダクトの発表という感じだった
- そのため必要ではあるんだけどあんまりワクワクはしなかった(もちろん1つ1つはすごいし便利になってる)
- Spanner 登場!みたいなセンセーショナルさはないかな
今回の基調講演では、Google Cloud が「マルチエージェントのためのフルスタックプラットフォーム」であると強調されました。従来、Google Cloud は特にデータ分析の領域や Google Workspace を始めとするアプリケーションレイヤのサービス提供において、競合と比べた強みがあると考えられていました。しかし、初日のキーノートでスンダー・ピチャイが最初に発表したのは、Cloud WAN という、Google のバックボーンネットワークを企業がクラウド形式で利用可能にするサービスでした。
これだけみると AI はまだ自信ないけど、AI動かすベースの環境はめっちゃあるよ!って印象をうけた。
ちょっと気になったので動画をみる(といってもテキスト化したので実質みてないが)
内容としてはいろんなAIだしてるよ〜〜〜っていう感じ。既存のもののレベルアップがメイン。
Cloud WAN (Cloud Wide Area Network)
Cloud WAN (Cloud Wide Area Network) は、Google Cloud が提供する、Google のグローバルプライベートネットワークを企業がクラウド形式で利用可能にするフルマネージド型のエンタープライズバックボーンサービスです。 Google が長年、Gmail、YouTube、Google 検索などの大規模サービスを支えてきた、信頼性が高く、安全な世界規模のネットワークインフラストラクチャを活用しています
Cloud WAN: AI 時代に適したネットワークでグローバル企業をつなぐ | Google Cloud 公式ブログ
Cloud WAN は、既存サービスである Cloud Interconnect、Cross-Cloud Interconnect、Network Connectivity Center(NCC)、および新発表の Network Connectivity Center Gateway(NCC Gateway。プレビュー開始は第2四半期 = 2025年4月からの3ヶ月間)で構成されます。Cross-Cloud Interconnect により、Google Cloud と他のパブリッククラウド(AWS、Azure、OCI 等)を接続し、Cloud Interconnect により Google Cloud とオンプレミス拠点を接続します。
こうして Google Cloud に接続されたすべてのサイトは、Google Cloud のバックボーンネットワークにより L2 層で相互に接続されるほか、Network Connectivity Center により、L3 層でのルーティングを制御できます。また新発表の NCC Gateway により、Security Service Edge(SSE)が提供され、Broadcom や Palo Alto Networks と統合したセキュリティ層が提供されます。これは、ファイアウォール、ルーティング、DNS 等の横断的な設定を可能にするソリューションであるとみられます。

とにかく自分の強みを活かして使ってもらおう感を感じる
Anywhere Cache
Anywhere Cache を使用すると、ワークロードと同じゾーンにキャッシュを作成できます。ゾーンにキャッシュを作成すると、ゾーンから発信されたデータ読み取りリクエストは、バケットではなくキャッシュによって処理されます。各キャッシュは、キャッシュと同じゾーン内のクライアントにサービスを提供します。データは、キャッシュと同じゾーンにある VM によって読み取られた場合にのみ、バケットからキャッシュに取り込まれます。メタデータはキャッシュに保存されず、オブジェクト メタデータのリクエストはキャッシュではなくバケットで処理されます。
Anywhere Cache はフルマネージド サービスであり、常に一貫したデータを返します。
Anywhere Cache は、主に次の 2 つの方法で役立ちます。
データへのアクセスを高速化: Anywhere Cache は、コンピューティング リソースの近くにある高性能ストレージ デバイスにデータを配置します。短いネットワーク パスと高性能デバイスにより、ワークロードはより多くのスループットを獲得し、読み取りをより迅速に完了し、読み取りの Time to First Byte レイテンシを短縮できます。
マルチリージョン データ転送料金を回避する: マルチリージョン バケットを使用して Cloud Storage データをクエリする場合は、Anywhere Cache を使用して、Compute Engine などの他のプロダクトのデータ転送料金を回避できます。
へ〜覚えておこう
Rapid Storage
業界をリードする 1 ミリ秒未満のランダム読み取りおよび書き込みレイテンシ、20 倍高速なデータ アクセス、6 TB/秒のスループット、他の主要なハイパースケーラーと比較して 5 倍低いランダム読み取りおよび書き込みレイテンシを実現する新しい Cloud Storage ゾーン バケット。
従来はどこに書き込むかを都度判断するステートレスな処理だったが、オーバーヘッドが大きいので書き込み先と常時接続を行うステートレスな機構に変わった。
GKE Inference Gateway
Gemini と同じ技術で作られた LLM である Gemma を代表とする生成 AI オープンモデルは、GKE クラスタ上のマイクロサービスとして AI 推論を提供することができます。
Gemini 等の大規模モデルを API で使用する代わりに、Gemma のような軽量モデルを GKE 上で実行することで、以下のようなメリットを享受することができます。
- API ベースで Gemini モデルを利用する場合のように、リクエストの増加に比例してコストが大きくなる心配がない(コストの予測が容易)。
- 他の利用者によるリクエストによって推論のパフォーマンスが低下する心配がない。
- リクエスト送信元のアプリケーションが同じクラスタ上に展開されている場合、レイテンシが抑えられる。
- モデルのカスタマイズ性が高い。
- AI 推論ワークロードをオンプレミスのクラスタに移行できる。
しかし、自社専用の環境として生成 AI による推論ワークロードを展開したい場合、モデルを実行するサーバやアクセラレータの選定、スケーリング、トラフィック分散、パフォーマンスモニタリングのように、開発から運用にわたって様々な課題があります。
LLM系って毎度 GPT 系サービスに飛ばす以外の方法しらんかったけど、確かに推論を自前の Pod でやらせると価格読みやすくてよいなあ。なるほど。
Google Workspace Flows
Google Workspace Flows は、AI エージェントが、さまざまな繰り返しタスクを自動化する機能です(Preview)。承認作業や市場調査、メールの整理、アジェンダの準備などが挙げられています
Google Workspace のコンテンツを使ったワークフローが簡単に組める
Google Maps によるグラウンディング
VertexAI x google map で地図情報やレビューを利用した回答が可能に。
これは1ユーザとしてGoogleMapにそのうち入りそうな機能だなと思う。
というか入ってほしい
Agent Development Kit(ADK)
マルチエージェントシステムを開発するためのオープンソースフレームワークである Agent Development Kit(ADK)が発表されました。
ADK は、複数のステップのタスクをこなすエージェントを開発するためのフレームワークです。ADK を使用することで、「100行未満の直感的なコードで AI エージェントを構築」できるとされています。また、ADK は MCP(Model Context Protocol)をサポートしています。Google から発表されるソリューションで、MCP への対応を謳ったのは初めてとみられます。これにより、Gemini 等のモデルから一般的に公開される MCP サーバーを利用することができると考えられます。
- https://cloud.google.com/blog/products/ai-machine-learning/build-and-manage-multi-system-agents-with-vertex-ai?hl=en
- https://google.github.io/adk-docs/
エージェント開発キット(ADK)は、 AIエージェントの開発と導入のための柔軟でモジュール化されたフレームワークです。ADKは、一般的なLLMやオープンソースの生成AIツールと併用でき、GoogleエコシステムおよびGeminiモデルとの緊密な統合に重点を置いて設計されています。ADKは、 GeminiモデルとGoogle AIツールを搭載したシンプルなエージェントを簡単に使い始めることができるだけでなく、より複雑なエージェントアーキテクチャとオーケストレーションに必要な制御と構造も提供します。
Python なのか
🧩 例:ユーザーが「東京の天気は?」と聞いたとき
1. ユーザー入力:「東京の天気は?」 (adk run / adk web)
2. Agent が LLM に入力を渡す (加えて agent が持っている関数情報も伝える)
3. LLM が get_weathaher(city="Tokyo") を呼ぶように判断(実行すべきコマンドを送ってくる)
{
"tool_calls": [
{
"tool_name": "get_weather",
"parameters": {
"city": "Tokyo"
}
}
]
}
4. ツール関数 get_weather が呼ばれ、返答「晴れです」を返す
5. LLM がそれを使って最終返答を生成
6. Agent がユーザーに返答を返す
adk-samples を動かしてみる
いろいろやったが m3 mac で python うごかすのがエラー大量にでてきて諦めた。
Keynote 2日目
Cloud Logging において出てきたエラーを investigation ボタン押すと、修正までつくってデプロイしてくれるやつが紹介されていた。
しかし公演中にバグだすってのすごいなw
A2A プロトコル

openai / anthropic / microsoft がパートナーにいない。。
ガチガチの競合
MCP補完とはいってるけど、この領域は譲らんってことかな。
A2Aは、基盤となるフレームワークやベンダーを問わず、エージェント同士が連携するための標準的な方法を提供するオープンプロトコルです。パートナーと共同でプロトコルを設計するにあたり、以下の5つの主要原則を遵守しました。
- エージェントの能力を活用する:A2Aは、エージェントが記憶、ツール、コンテキストを共有していなくても、自然で非構造的なモダリティで連携できるようにすることに注力しています。エージェントを「ツール」に限定することなく、真のマルチエージェントシナリオを実現します。
- 既存の標準に基づいて構築:このプロトコルは、HTTP、SSE、JSON-RPC などの既存の一般的な標準に基づいて構築されているため、企業が日常的に使用している既存の IT スタックとの統合が容易になります。
- デフォルトで安全: A2A は、起動時に OpenAPI の認証スキームと同等のエンタープライズ グレードの認証と承認をサポートするように設計されています。
- 長時間実行タスクのサポート: A2Aは柔軟性を備え、簡単なタスクから、人間が関与すると数時間、あるいは数日かかるような詳細な調査まで、あらゆるシナリオに対応できるように設計されています。このプロセス全体を通して、A2Aはユーザーにリアルタイムのフィードバック、通知、状態の更新を提供します。
- モダリティに依存しない:エージェントの世界はテキストだけに限定されません。そのため、A2A はオーディオやビデオのストリーミングを含むさまざまなモダリティをサポートするように設計されています。
MCP との使い所
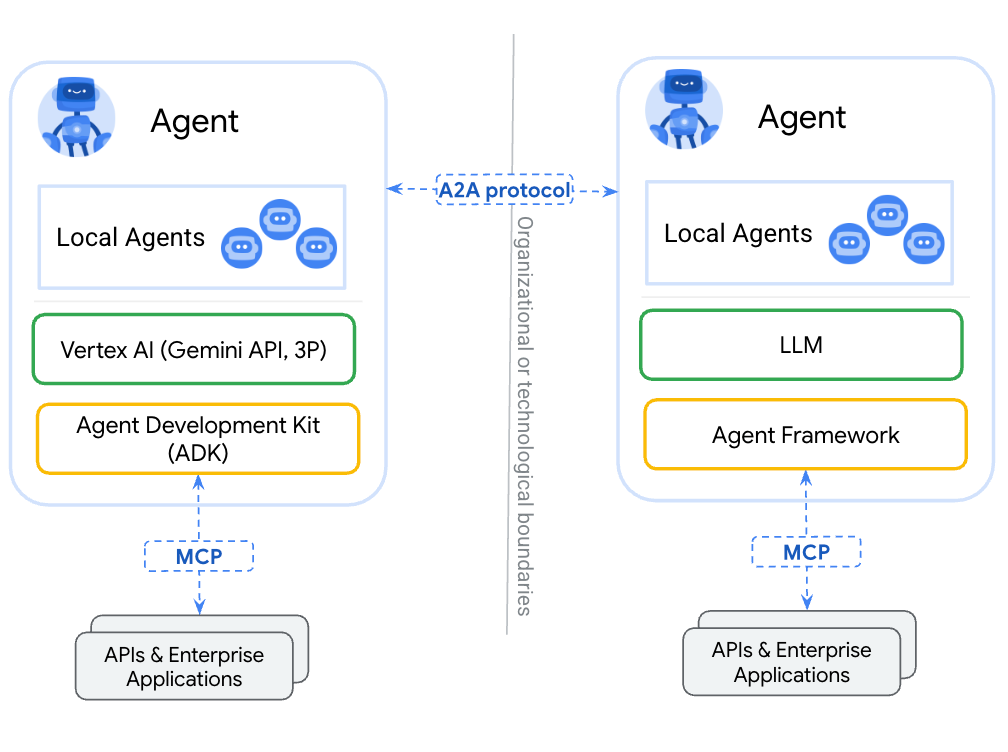
JSON Schema があるのでこれをやり取りするってだけかな。
Model Armor
生成 AI のプロンプトやレスポンスをスクリーニングし、悪意あるコンテンツが生成 AI にインプットされたり、ユーザーに返されることを防ぐためのフルマネージドサービス

Model Armor は、テキスト形式と PDF 形式をサポートしています。PDF では、Model Armor はテキスト コンテンツのみをスキャンします。
Azure
Cloud Run
- Cloud Run 上で Cloud Storage バケットをローカルファイルシステムのようにマウントする機能が提供されました。
- Angular、Next.js、Nest、Astro といったフレームワークを用いて Cloud Run にデプロイを行う際に、Firebase App Hosting を使用することで、より容易にデプロイを行うことが可能となりました。
- Cloud Run Worker Pools
- pull ベースのワークロード
- リージョンレベルの分散が可能に
IAM and Org Policy
Keyless access to Google Cloud APIs using X.509 certificates
いままでは ServiceAccount の秘密鍵を持たせたり、IdP を使用した OIDC のフローなどを使わないといけなかったが X.509 のクライアント証明書を作り、それを Google Cloud 側で検証することで API にアクセスできるようになる。
Managed Workload Identity
Compute Engine にユニークなクライアント証明書を発行できる。
これにより mTLS (マシンレベル)が簡単にできるように。
Gemini-powered-Role Picker
Gemini を用いて自然言語で必要なロールの特定が可能となり
便利。名前頑張って覚えてた。
Automatic ReAuth for 11 sensitive actions
ユーザーが機密性の高いアクションを行った際に、ユーザーに再認証を強制することができます。(現在は11個の機密性の高いアクションが対象)
機密性の高いアクションを繰り返し実施するユースケースを考慮し、再認証後15分間は機密性の高いアクションを行ったとしても再認証は不要とする設定も行うことができます。