Findy Team+のシステムアーキテクチャ
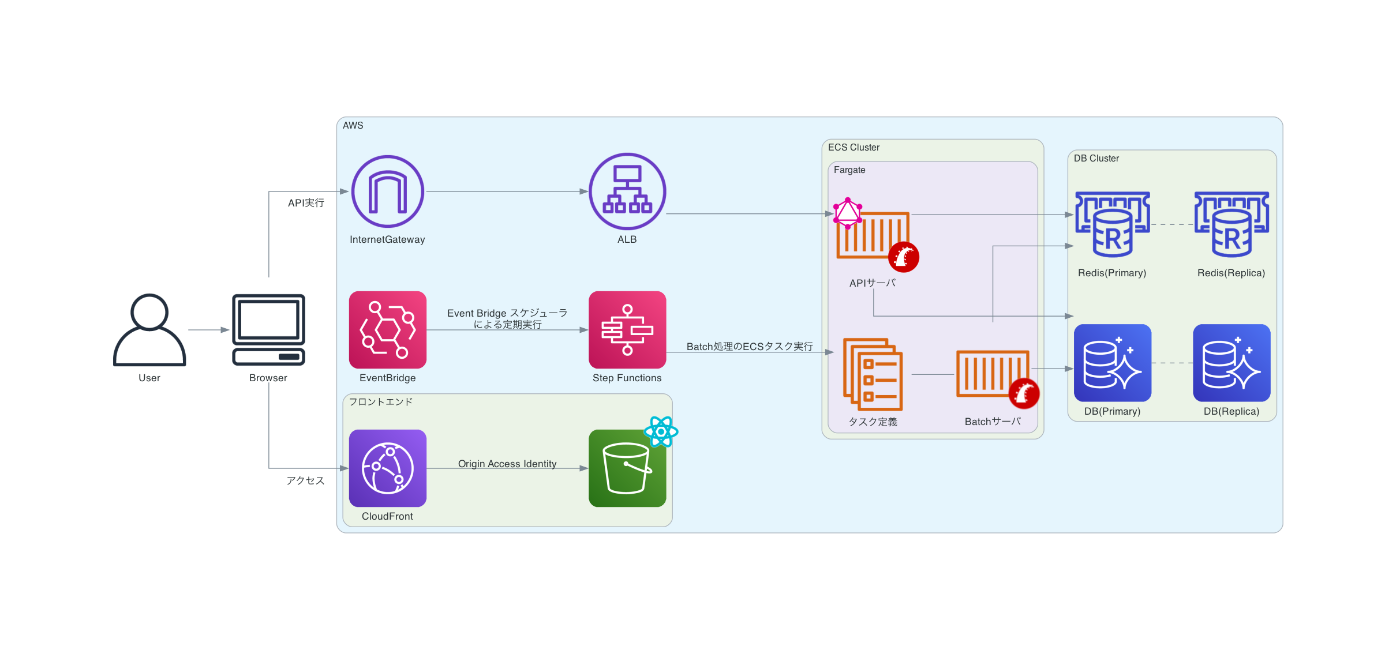
Findy Team+は以前までAWSのElastic Beanstalkを使用し、APIサーバやWorkerサーバをEC2上に構築するアーキテクチャとなっていました。
Findy Team+は外部ツールと連携し、データを収集して分析するプロダクトの特性上、データ収集のBatch処理が長時間実行されることがあります。WorkerサーバでBatch処理を実行中にデプロイを行うとBatch処理のプロセスが中断されてしまうため、処理が動いていないタイミングを見計らってデプロイする必要があり、スピーディなデプロイを行うことが出来なかった点が当時の課題でした。
現在のアーキテクチャでは、EventBridge スケジューラによってスケジュールでStep Functionsを実行し、そこからBatch処理のECSタスクを起動しています。WorkerサーバとBatch処理を別個のECSタスクで管理することが可能となり、それぞれの処理を独立して稼働させることに成功しました。
これにより実行中のBatch処理をリリースの際に気にする必要がなくなりデプロイ頻度の向上へと繋がったのです。
現在のアーキテクチャの課題と今後の改善予定
今後の展望として、トラフィックやデータ量が数十倍に増加しても問題なく処理できるアーキテクチャを目指しています。
現在のアーキテクチャでは、アクセスが集中したり、Batch処理などで一時的に高負荷がかかる場合に自動でスケールする仕組みが整っていません。
そのため、高負荷を想定し、事前に高スペックのECSタスクやDBインスタンスを稼働させていますが、スケールアップだけではパフォーマンスの頭打ちがきたり、高負荷に合わせたスペックにしていることによるコスト増加などの課題が発生しています。
これらの課題を解決するため、今後は負荷に応じて自動でスケールアウト・スケールダウンできる仕組みを構築するなど、コストの最適化や、トラフィックやデータ量の増加にも対応できるアーキテクチャを実現していきたいと思ってます。
気になったこと
1. GitHub からのデータをどこで持ってきてるんだろう
Batch サーバでやってるのかな?
現在のアーキテクチャでは、アクセスが集中したり、Batch処理などで一時的に高負荷がかかる場合に自動でスケールする仕組みが整っていません。

これは SQS をいれて、バッチを複数台起動がいいのかな。裏側の構成がわからないからパラレルにできるかわからないけれど。
2. GraphQL だ、なんでだろう。
Webしかないからそんなに旨味はなさそうだけど
Findy 本体では REST から移行したらしい
API レスポンスに対しても手作業で型付けを行っていましたが、API の仕様が複雑であったりドキュメントと同期するのが難しかったことから、後に REST API から GraphQL に移行し、GraphQL Code Generator による型生成が採用されるようになります。
Findy Tool は初めから GraphQL
なので、組織的に GraphQL に倒したのかな。
3. フロントはSSG + Fetch か
使ったことあるけど、基本はチームやユーザの統計データを取得するのが大半だからこの構成なのかな。
印象だが記事を見た感じはインフラやバックエンドよりもフロントが強い会社のイメージ
※単に情報量の問題かもしれないけど
組織としてはこう