100日チャレンジ day22 (分散キャッシュシステム)
昨日
100日チャレンジに感化されたので、アレンジして自分でもやってみます。
やりたいこと
- 世の中のさまざまなドメインの簡易実装をつくり、バックエンドの実装に慣れる(dbスキーマ設計や、関数の分割、使いやすいインターフェイスの切り方に慣れる
- 設計力(これはシステムのオーバービューを先に自分で作ってaiに依頼できるようにする
- 生成aiをつかったバイブコーティングになれる
- 実際にやったことはzennのスクラップにまとめ、成果はzennのブログにまとめる(アプリ自体の公開は必須ではないかコードはgithubにおく)
できたもの
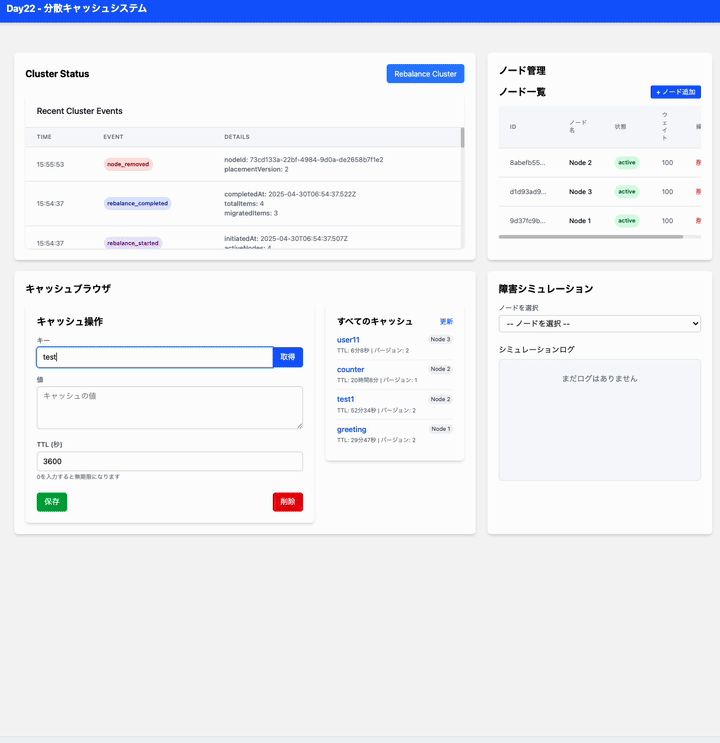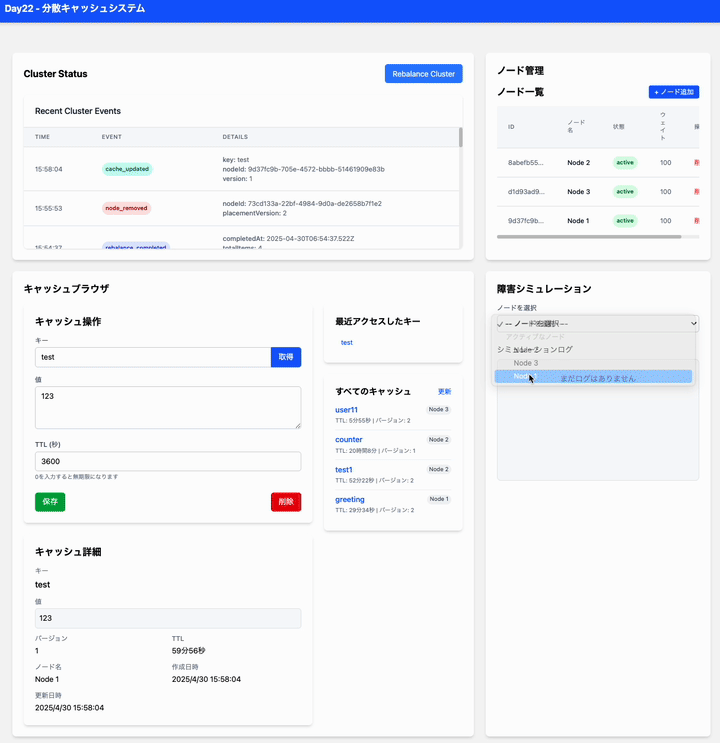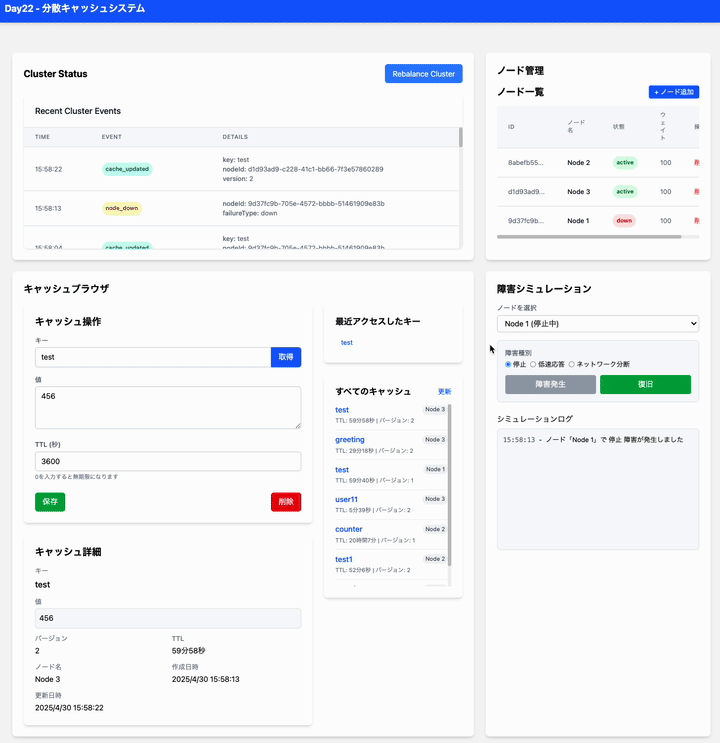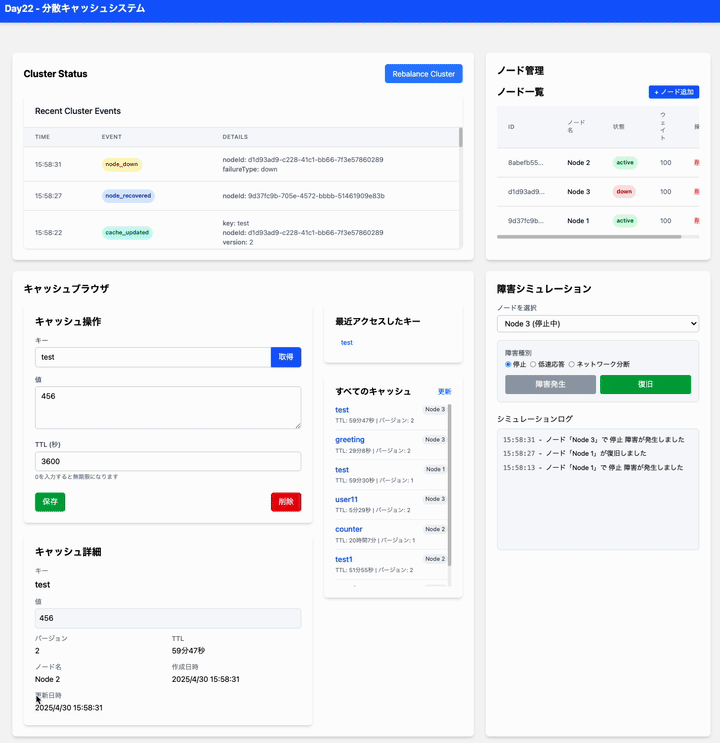
今日は 分散キャッシュシステム をつくる
分散キャッシュシステムは以下のようなイメージで作成できます:
分散キャッシュシステムの構成イメージ
-
中核機能:
- 複数のノード間でキャッシュデータを分散保存
- シンプルな key-value ストア API (GET/SET/DELETE)
- データの有効期限 (TTL) 管理
- 一貫性保証の仕組み (eventual consistency)
-
アーキテクチャ:
- クラスタ管理コンポーネント (ノードの追加/削除を管理)
- データ分散アルゴリズム (一貫性ハッシュ等)
- レプリケーション機能 (データの冗長化)
- 障害検知・復旧メカニズム
-
UI/フロントエンド:
- キャッシュの状態可視化ダッシュボード
- キャッシュデータ操作インターフェース
- パフォーマンスモニタリング画面
- ノード管理画面
-
実装方針:
- Next.js でノードサーバーとWebインターフェースを構築
- SQLite で永続化データを管理
- WebSocket でノード間通信を実現
- メモリ内データ構造でキャッシュを実装
-
シミュレーションモード:
- 複数の仮想ノードを単一サーバー上で動作させる
- 障害シナリオをシミュレート (ノードダウン、ネットワーク分断等)
- 負荷テストや一貫性テストを視覚的に表示
実際のユースケースとして、APIリクエスト結果をキャッシュする簡易アプリケーションも含め、キャッシュパフォーマンスを体験できる設計にします。
なるほど、もう少し詳細に書ける?設計レベルのものが欲しい
分散キャッシュシステムの詳細設計
1. システム構成
コンポーネント構成
- キャッシュノード: 実際にデータを保存する各ノード
- クラスタマネージャ: ノードの管理・監視を行う中央コンポーネント
- クライアントライブラリ: アプリケーションからキャッシュを利用するためのAPI
- 管理UI: システム全体の監視・操作インターフェース
通信プロトコル
- クライアント-ノード間: RESTful API (HTTP)
- ノード間通信: WebSocket (リアルタイム同期用)
- クラスタ管理通信: HTTP + Server-Sent Events (状態更新通知)
2. データ分散メカニズム
一貫性ハッシュアルゴリズム
- 仮想ノード概念を導入(各物理ノードが複数の仮想ノードを担当)
- キーのハッシュ値をリング状に配置
- ノード追加/削除時のデータ再配置を最小化
レプリケーション戦略
- 各データは N個のノードに複製(設定可能なレプリケーションファクター)
- 書き込み時: 設定可能なクォーラム方式(W ノードの確認で成功)
- 読み取り時: 設定可能なクォーラム方式(R ノードから読み取り、最新を採用)
3. 一貫性とCAP定理
一貫性レベル設定
- 強一貫性モード: 全レプリカの更新を待機(速度↓、整合性↑)
- 結果整合性モード: バックグラウンドで同期(速度↑、一時的な不整合あり)
- 読み取りクォーラム: 複数ノードからの読み取りで最新データ保証
競合解決
- バージョンベクトル/タイムスタンプによる変更検出
- 最終更新勝利 (LWW) または カスタム競合解決関数のサポート
4. データ管理機能
キャッシュポリシー
- TTL (Time To Live): キー単位での有効期限設定
- LRU (Least Recently Used): メモリ使用量上限時の破棄戦略
- 条件付き操作: CAS (Compare-And-Swap) による楽観的ロック
パーティショニング
- シャードキー設計(データのグループ化)
- ホットスポット回避のためのキー分散戦略
5. 障害対応機構
障害検知
- ハートビートによるノード死活監視
- ゴシッププロトコルによるクラスタ状態の分散共有
自動復旧
- ノード復帰時のデータ再同期プロセス
- 自動スケールアウト/インのサポート
6. 実装詳細
データ構造
- ノード内メモリストア: JavaScript Map またはカスタムデータ構造
- 永続化層: SQLite によるスナップショット保存
APIエンドポイント
-
GET /api/cache/:key- キャッシュ値取得 -
POST /api/cache/:key- キャッシュ値設定 -
DELETE /api/cache/:key- キャッシュ値削除 -
GET /api/stats- 統計情報取得 -
GET /api/nodes- ノード情報取得
管理API
-
POST /api/cluster/nodes- ノード追加 -
DELETE /api/cluster/nodes/:nodeId- ノード削除 -
PUT /api/cluster/rebalance- データ再配置の手動トリガー
7. シミュレーションモード
テストシナリオ
- ノード追加/削除時のデータ移行シミュレーション
- ネットワーク分断時の動作シミュレーション
- 高負荷時のスループット測定
可視化
- データ分布のヒートマップ表示
- ノード間通信の視覚的表現
- キャッシュヒット率などのリアルタイムメトリクス
8. デモアプリケーション
サンプルユースケース
- 外部APIレスポンスのキャッシュ
- セッションデータの分散保存
- 計算コストの高い処理結果のキャッシュ
この設計を元に、Next.jsとPrismaを使用して、シミュレーションモードでの分散キャッシュシステムを実装することが可能です。実際の複数サーバー構成ではなく、単一サーバー上で複数の仮想ノードをシミュレートする形で学習目的を達成します。
結構な工数かかりそうだけど、サーバとしては何種類つくるの
分散キャッシュシステムの実装では、工数を考慮して以下のサーバー種類に絞ることができます:
実装するサーバー種類
-
メインサーバー (Next.js)
- フロントエンドUI提供
- APIエンドポイント提供
- 仮想ノードの管理
- 管理インターフェース
-
仮想キャッシュノード
- 実際には別プロセスではなく、メインサーバー内の分離されたコンテキスト
- Node.js Worker Threadsまたはメモリ内オブジェクトとして実装
- 各ノードは独自のキャッシュストアを持つ
実質的には単一のNext.jsアプリケーション内で、複数の仮想ノードをシミュレートする形になります。別々の物理サーバーを用意する必要はなく、1つのアプリケーションで分散環境をシミュレーションします。
これにより工数を大幅に削減しつつ、分散キャッシュの概念や仕組みを学ぶことができます。必要に応じて後から拡張することも可能です。
なるほど。私が恐れているのは複雑な構成のアプリをLLMの1コンテキストで実施すると、途中でバグが色々でて終わらないんじゃないかというものです。
たとえばIF定義を先に作り、それを実装する、それを利用する みたいな形で区分するとLLMに負担が少ないかなと思っています。
あなたの意見を教えてください。
おっしゃる懸念は非常に的確です。複雑なシステムを1つのコンテキストで実装しようとすると、途中で一貫性が崩れ、バグが発生しやすくなります。
LLMの特性を考慮した段階的なアプローチとして、以下のように分割する方法が効果的だと思います:
段階的実装のアプローチ
-
インターフェース定義フェーズ
- API仕様書の作成(OpenAPI/Swagger形式)
- データモデルとスキーマ定義
- コンポーネント間の通信プロトコル定義
-
コア機能実装フェーズ
- シンプルなキャッシュストア機能の実装
- 単一ノードでの基本操作(GET/SET/DELETE)
- TTL、LRU等の基本機能
-
分散機能実装フェーズ
- 一貫性ハッシュ実装
- ノード間データ同期メカニズム
- クラスタ管理機能
-
UI・デモ実装フェーズ
- 管理ダッシュボード
- 可視化コンポーネント
- デモアプリケーション
この方法には複数のメリットがあります:
- 各フェーズで明確な成果物が得られる
- 各段階でテスト可能な中間成果物ができる
- LLMが特定の機能に集中できるため、品質が向上する
- バグが発生しても特定・修正が容易
さらに、極力シンプルな機能から始め、動作確認しながら段階的に複雑な機能を追加していくことで、プロジェクト全体の成功確率が高まります。
このアプローチでやるべきだと思います。
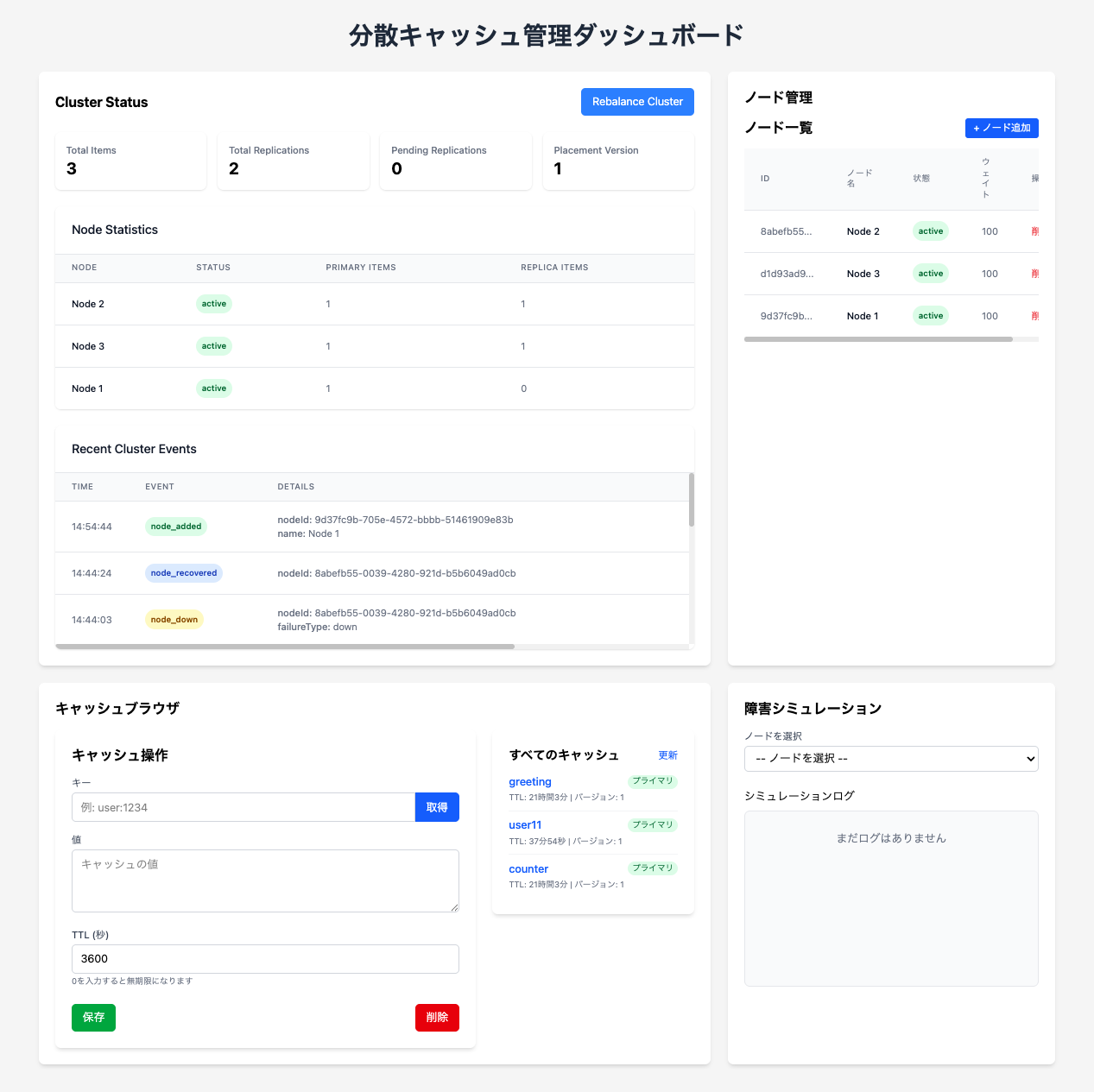
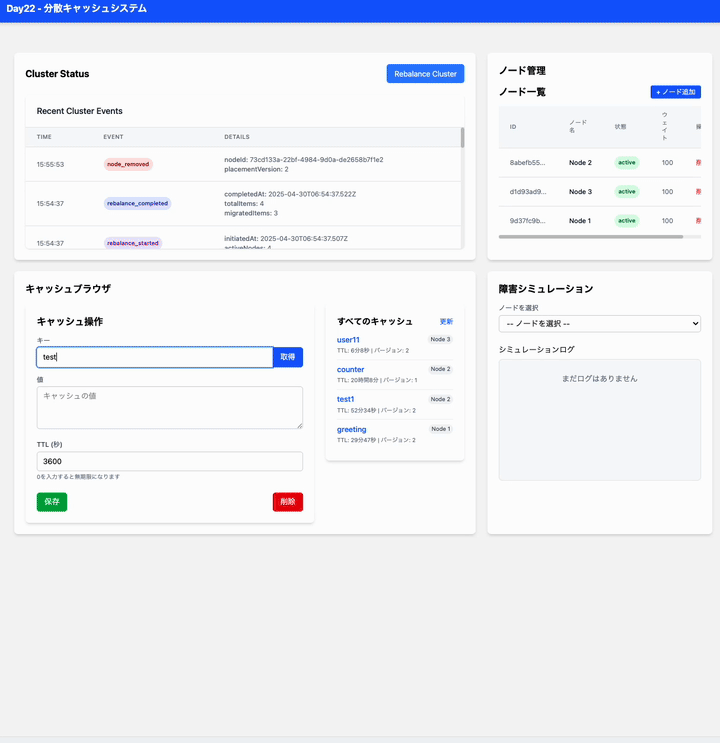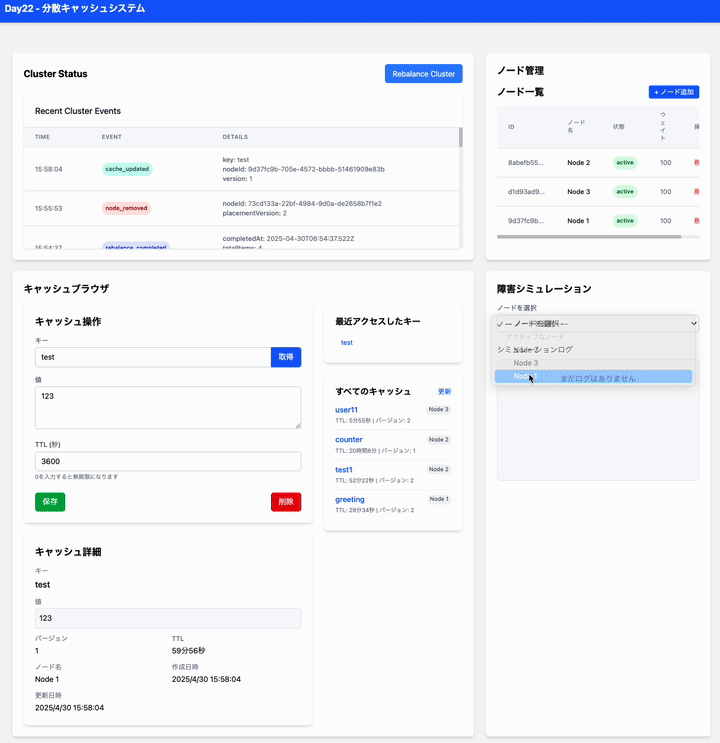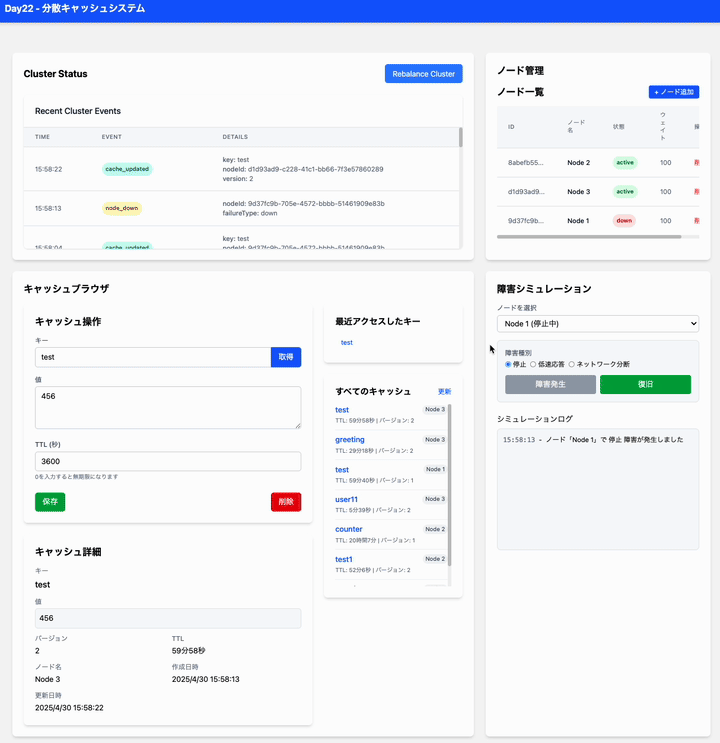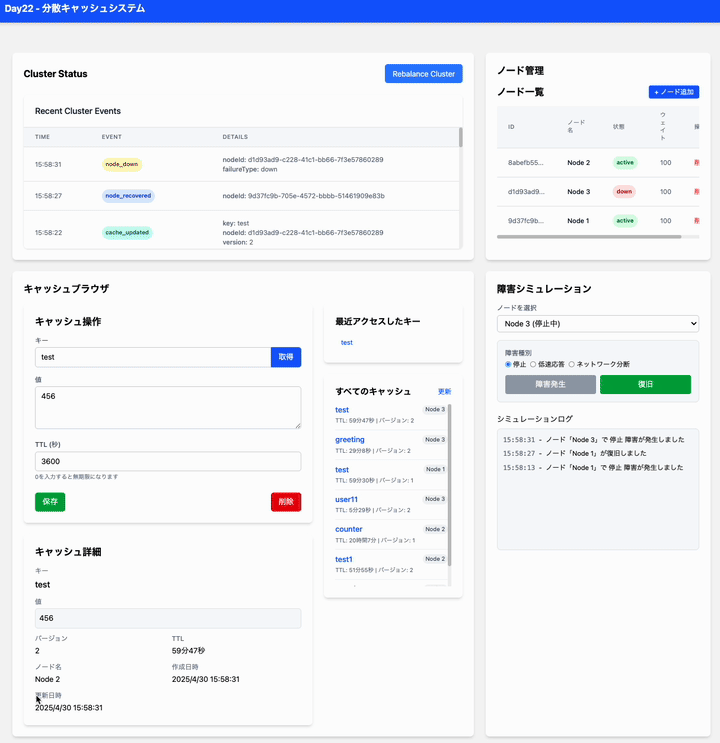
なるほど、このアプリケーションでどのようなシミュレーションができるか、ですね。
この分散キャッシュシステムシミュレータでは、主に以下の点を観察・体験できます。
-
ノード障害の影響:
-
特定のノードを停止 (Down) させてみる:
- そのノードが担当していたキャッシュキー (プライマリデータ) へのアクセスはどうなりますか? (キャッシュブラウザで GET してみる)
- レプリカを持っている他のノードからデータが読み込まれますか? (キャッシュブラウザで取得したデータのメタデータ
sourceを確認) - システムは自動的に停止したノードのデータを他のノードに再配置 (リバランス) しようとしますか? (Cluster Status のイベントログやノード別統計を確認)
-
特定のノードを低速応答 (Slow) にしてみる:
- このシミュレーションでは、実際の応答遅延は実装されていませんが、ノードの状態が
slowに変わることを確認できます。実際のシステムでは、このようなノードを一時的に切り離すなどの制御が行われることがあります。
- このシミュレーションでは、実際の応答遅延は実装されていませんが、ノードの状態が
-
特定のノードをネットワーク分断 (Partition) させてみる:
- 停止(Down) と同様に、そのノードへのアクセスができなくなります。分断されたノードが持つデータへの影響を確認できます。
-
特定のノードを停止 (Down) させてみる:
-
ノード復旧時の動作:
- 障害シミュレーションで停止させたノードを「復旧」させてみます。
- 復旧したノードはクラスタに再参加し、再びキャッシュの割り当て対象になりますか? (Cluster Status のノード別統計や状態を確認)
- 停止中に他のノードに移っていたデータは、復旧したノードに適切に再配置されますか? (少し時間を置いてから、キャッシュブラウザでキーを取得し、プライマリノードを確認)
-
ノード追加・削除時のリバランス:
- ノード管理セクションから新しいノードを追加してみます。
- 追加後、システムはキャッシュデータを新しいノードを含めて再配置しますか? (Cluster Status のノード別統計で、新しいノードにアイテムが割り当てられるか確認。リバランスはバックグラウンドで行われるため少し時間がかかる場合があります)
- 同様に、アクティブなノードを削除してみます。そのノードが持っていたデータは他のノードに引き継がれますか?
具体的なシミュレーション手順例:
- 初期状態: 3つのノード (Node1, Node2, Node3) がアクティブな状態です。
-
データ準備: キャッシュブラウザでいくつかキーと値 (例:
key1=value1,key2=value2,key3=value3) を保存します。 - プライマリ確認: Cluster Status の Node Statistics で、各ノードがどのくらいのプライマリ/レプリカアイテムを持っているか確認します。(どのキーがどのノードかは現状では直接見れませんが、分散具合を確認できます)
- 障害発生: 障害シミュレーションで Node1 を選択し、「障害発生」ボタンで「停止 (down)」させます。
-
状態確認: Cluster Status で Node1 の状態が
downになったこと、イベントログにnode_downが記録されたことを確認します。 -
データアクセス試行: キャッシュブラウザで
key1,key2,key3を GET してみます。- Node1 がプライマリだったキーも、他のノードのレプリカから取得できるはずです (メタデータの
sourceがreplicaになる)。 - 取得に失敗するキーはありますか?
- Node1 がプライマリだったキーも、他のノードのレプリカから取得できるはずです (メタデータの
- 復旧: 障害シミュレーションで Node1 を選択し、「復旧」ボタンを押します。
-
状態確認: Cluster Status で Node1 の状態が
activeに戻ったこと、イベントログにnode_recoveredが記録されたことを確認します。 - 再バランス確認: 少し時間を置いてから、再度キャッシュブラウザでキーを取得したり、Cluster Status の統計を確認したりして、データが Node1 に戻ってきているか(あるいはリバランスされているか)を確認します。
このように、各機能を操作しながら Cluster Status やキャッシュブラウザでのデータの状態を観察することで、分散キャッシュシステムがどのように障害に対応し、データを維持しようとするのかをシミュレーションできます。
はい、現在の実装では、ノードが追加されたときに自動的にキャッシュのリバランス処理 (scheduleDataRebalancing) がバックグラウンドで実行されるようになっています。
具体的には、lib/cluster-manager.ts 内の addNode メソッドの最後で this.scheduleDataRebalancing() が呼び出されています。
// lib/cluster-manager.ts 内の addNode メソッド
public async addNode(...) {
try {
// ... (ノード作成、ハッシュリング更新など) ...
// データのリバランスをスケジュール (await を外してバックグラウンド実行)
this.scheduleDataRebalancing(); // ← ここで呼び出される
// ... (イベントログ記録) ...
return nodeData;
} catch (error) {
// ...
}
}
この scheduleDataRebalancing 関数は、現在存在するすべてのキャッシュアイテムを確認し、新しいノードが追加されたことによって担当ノードが変わるべきアイテムがあれば、適切なノードにデータを移行する処理を行います。
ただし、ノードの削除時やノードの復旧時には、この scheduleDataRebalancing は明示的には呼び出されません。これらの場合は、削除/復旧するノードに関連するデータのみを対象とした、個別のデータ移行処理 (removeNode や handleNodeRecovery 内のロジック) が実行されます。
はい、現在の実装では、データが保存(set)された後、別のノードへのデータのコピー(レプリケーション) が行われますが、それは 即時ではなく、非同期 で行われます。
具体的な流れは以下のようになっています。
-
データ保存 (
set):- クライアントがキャッシュブラウザなどからキーと値を「保存」すると、API (
/api/cache/[key]/route.tsの POST) が呼ばれます。 - API は
cacheStore.setを呼び出し、最終的にclusterManager.setが実行されます。 -
clusterManager.setは、まずキーに基づいて担当となる プライマリノード を決定します。 - 決定したプライマリノードのデータベース (
CacheItemテーブル) にデータが書き込まれます(または更新されます)。 - この時点でクライアントへのレスポンスは返されます (保存処理は完了したように見えます)。
- クライアントがキャッシュブラウザなどからキーと値を「保存」すると、API (
-
レプリケーションのスケジュール:
- プライマリノードへの書き込みが成功した後、
clusterManager.setの中でthis.scheduleReplication(key, sourceNodeId, cacheItemId)が呼び出されます。 -
scheduleReplicationは、そのキーを担当すべき レプリカノード (ハッシュリングに基づいて決定されます。デフォルトでは隣のノードなど) を特定します。 - 特定されたレプリカノードごとに、「キー
keyをプライマリノードsourceNodeIdからレプリカノードtargetNodeIdへコピーする」というタスクが、内部のreplicationQueue(タスクキュー) に 追加 されます。
- プライマリノードへの書き込みが成功した後、
-
レプリケーションの実行 (非同期):
-
clusterManagerは、初期化時にstartReplicationSyncJobを開始しています。これは 一定間隔 (デフォルトではreplicationInterval = 5000ミリ秒、つまり5秒) でprocessReplicationQueueを実行します。 -
processReplicationQueueは、replicationQueueに溜まっているタスクを取り出し、replicateItem関数を呼び出して実際のレプリケーション処理 (プライマリノードからデータを読み取り、レプリカノードのReplicationテーブルに書き込む処理) を行います。
-
結論:
データが保存されると、まずプライマリノードに書き込まれ、その後 レプリケーションタスクがキューに追加 されます。実際のレプリケーション (別のノードへのコピー) は、バックグラウンドで定期的に実行される同期ジョブによって、少し遅れて非同期で行われます。
そのため、保存直後にレプリカノードを参照しても、まだデータがコピーされていない可能性があります (結果整合性)。
Redis Cluster の場合
鋭いご質問ありがとうございます。まさに分散システムにおける重要な課題ですね。
現在のシミュレーション実装における一貫性について
ご指摘の通り、現在の day22_distributed_cache の実装では、リバランス中(特に scheduleDataRebalancing が実行中)の書き込みに対する一貫性の保証は弱いです。
-
リバランスの仕組み: ノード追加時に
scheduleDataRebalancingが実行されます。これは、すべてのキャッシュアイテムをチェックし、担当ノードが変わるべきアイテムを新しいノードにコピーし、その後古いノードから削除する、という素朴な方法です。 -
競合の可能性:
- あるキー
KがノードAからノードBへ移行中に、クライアントからKへの書き込みリクエストが来た場合、タイミングによっては以下のような問題が起こりえます。- 書き込みリクエストが古いノードAに行く -> データ更新
- リバランス処理が古いデータをノードBにコピー
- 書き込みリクエストが新しいノードBに行く前に、古いノードAのデータが削除される -> データ喪失の可能性
- あるいは、リバランス処理が古いデータをノードBにコピーした後に、書き込みリクエストがノードBに行ってデータを更新 -> この場合は比較的安全ですが、一時的に古いデータが見える可能性はあります。
- あるキー
- 読み込みの問題: 移行中のキーを読むと、一時的にデータが見つからない可能性があります。
-
バージョン: 現在の実装では
set時にバージョンをインクリメントしますが、リバランス(migrateCacheItem)は元のバージョンをそのままコピーするため、競合が発生するとバージョンが古くなる可能性もあります。 - レプリケーション: レプリケーションも非同期で行われるため、プライマリとレプリカ間には常に若干の遅延があり、強い一貫性はありません(最終的な一貫性)。
Redis Cluster など、実際の分散キャッシュでのアプローチ
実際の Redis Cluster のようなシステムでは、リバランス中の一貫性をより高度な仕組みで担保しようとしています。
- スロット管理 (Slot Management): Redis Cluster は、すべてのキーを 16384 個の「スロット」に分割し、各スロットを特定のマスターノードに割り当てます。リバランスは、このスロット単位で行われます。
-
移行中の状態管理 (MIGRATING/IMPORTING State): スロットを移行する際、移行元ノードはそのスロットを
MIGRATING(移行中) 状態に、移行先ノードはIMPORTING(受け入れ中) 状態にします。 -
クライアントリダイレクト:
- クライアントが
MIGRATING状態のスロットにあるキーにアクセスしようとすると、ノードはそのキーがローカルにあるか、既に移行済みかを確認します。 - もしキーがローカルにあれば処理しますが、既に移行済み、または移行プロセス中の場合、クライアントに対して「このキーは現在ノードX (IMPORTING 状態のノード) が担当しようとしているよ」と伝え、リダイレクトさせます (
-ASKリダイレクト)。 - 書き込みの場合は、リダイレクト前に特別なコマンド (
ASKING) を送るよう指示することもあります。 -
IMPORTING状態のノードは、ASKINGコマンドを伴うリクエストや、移行元からのデータ転送のみを受け付けます。
- クライアントが
-
移行完了: スロットの移行が完了すると、クラスタ全体の情報が更新され、クライアントは次回から新しい担当ノードに直接アクセスするようになります (
-MOVEDリダイレクト)。
まとめ
現在のシミュレーション実装は、リバランスの基本的な概念を理解するためのものであり、本番環境レベルの厳密な一貫性保証は実装されていません。特にリバランス中の書き込みには競合のリスクがあります。
Redis Cluster などの実際のシステムでは、スロット管理、状態管理、クライアントリダイレクトといった仕組みを組み合わせることで、リバランス中でも可能な限り一貫性を保ち、データ損失のリスクを低減しています。(それでも、分散システムではネットワーク分断なども考慮する必要があり、完全な一貫性を常に保証するのは非常に困難です。)