100日チャレンジ day29 (簡易ETLパイプライン)
昨日
100日チャレンジに感化されたので、アレンジして自分でもやってみます。
やりたいこと
- 世の中のさまざまなドメインの簡易実装をつくり、バックエンドの実装に慣れる(dbスキーマ設計や、関数の分割、使いやすいインターフェイスの切り方に慣れる
- 設計力(これはシステムのオーバービューを先に自分で作ってaiに依頼できるようにする
- 生成aiをつかったバイブコーティングになれる
- 実際にやったことはzennのスクラップにまとめ、成果はzennのブログにまとめる(アプリ自体の公開は必須ではないかコードはgithubにおく)
できたもの
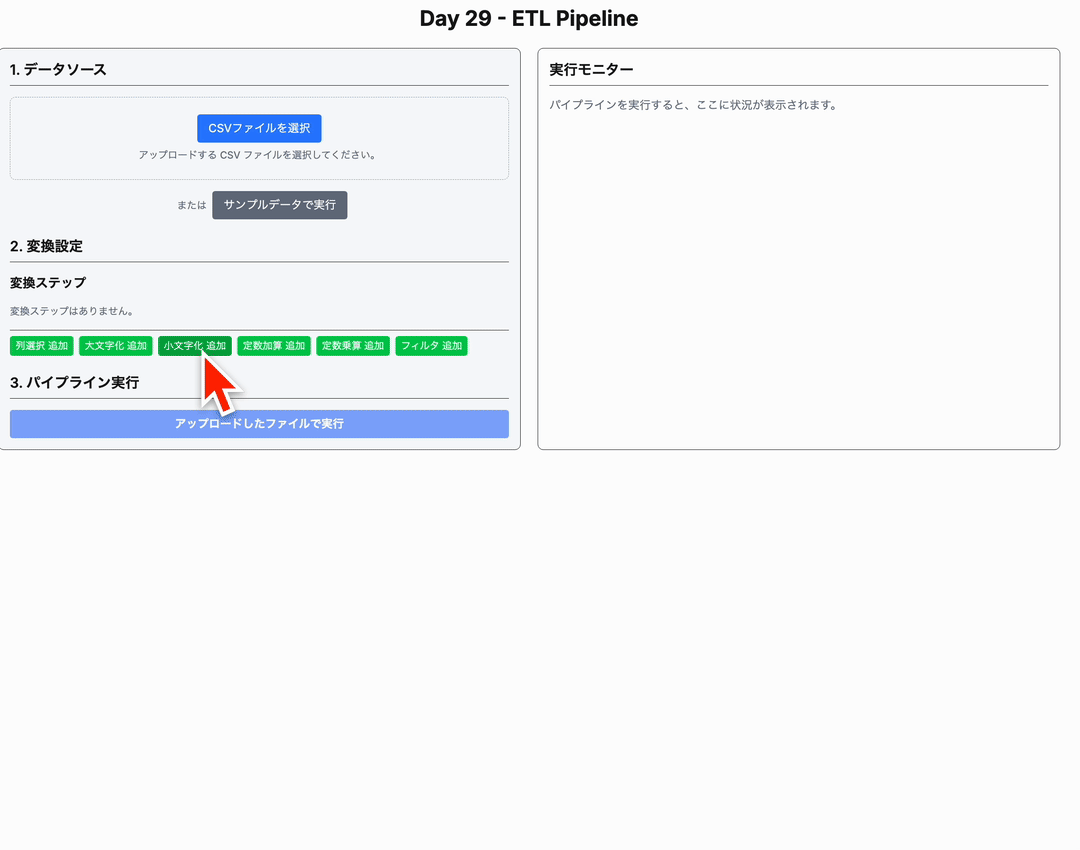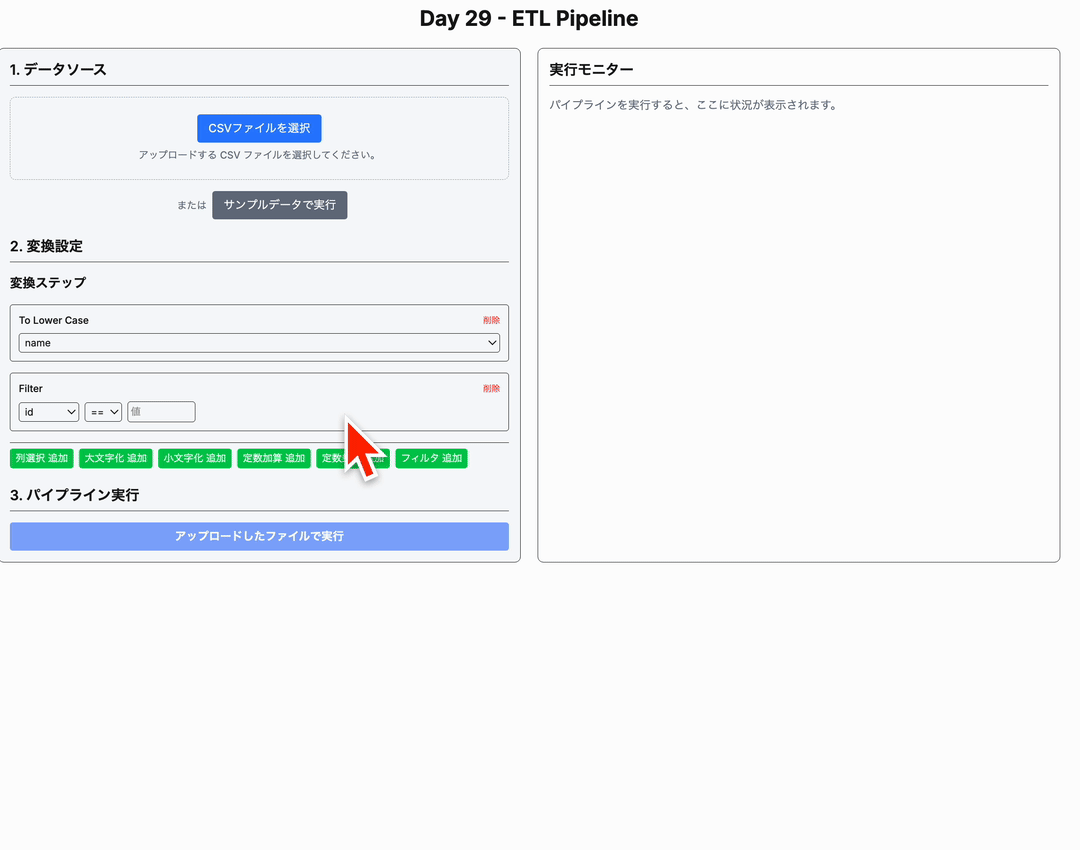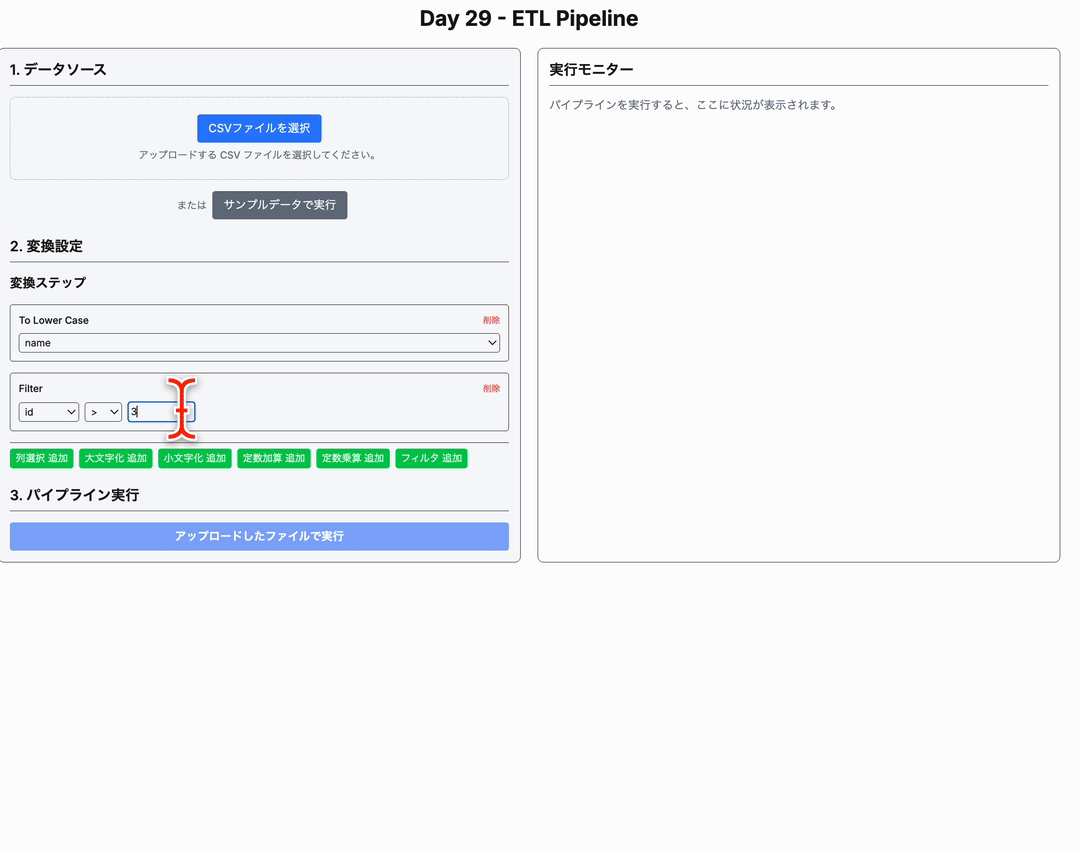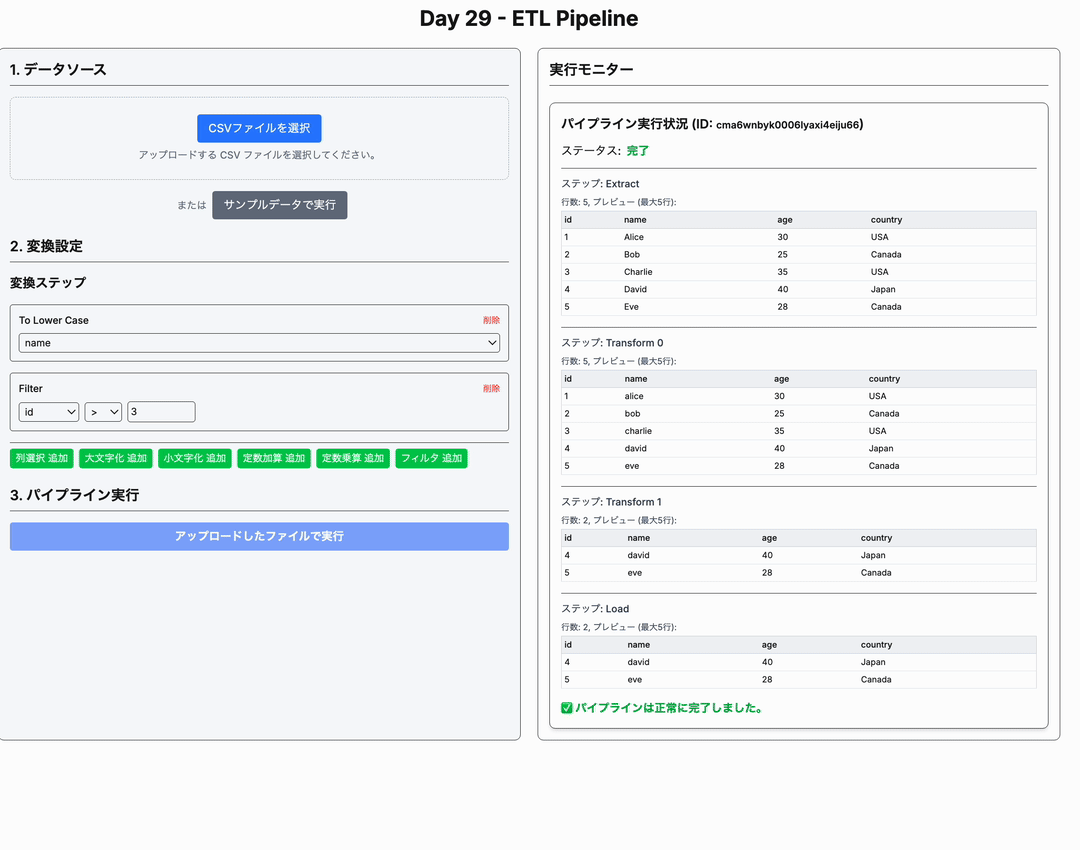
簡易ETLパイプライン を作る
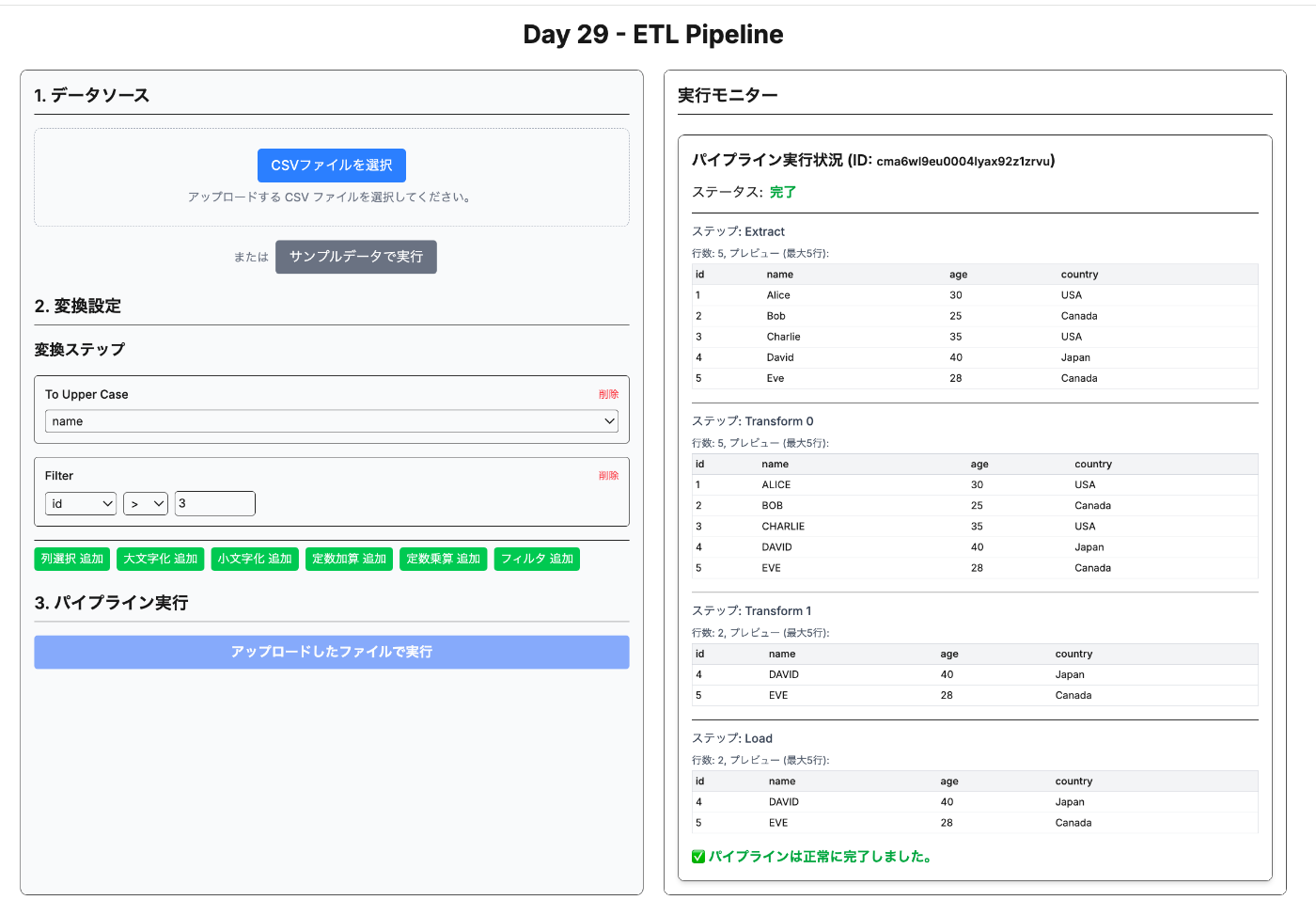
承知いたしました。Day 29 の開発として「簡易ETLパイプライン」を作成します。データの流れを視覚的に表現することに重点を置きます。
Day 29: 簡易 ETL パイプライン 仕様書案
1. 目的
CSV ファイルを入力とし、ユーザーが定義した簡単な変換処理を経て、データベースにデータをロードする一連の ETL (Extract, Transform, Load) パイプラインを Web UI 上で実行・可視化できるようにする。特に、各ステップでデータがどのように変化していくかをユーザーが追跡できるようにする。
2. 機能要件
-
データソース (Extract):
- ユーザーはローカルから CSV ファイルをアップロードできる。
- アップロードされた CSV のヘッダー行を自動で認識する。
-
変換 (Transform):
- ユーザーは UI を通じて、以下の変換ステップを定義できる (複数ステップ可):
- 列選択: 処理対象とする列を選択する。
-
データ加工:
- 指定した文字列型の列を大文字または小文字に変換する。
- 指定した数値型の列に定数を加算・乗算する。
-
フィルタリング: 指定した列の値に基づいて行をフィルタリングする (例:
age > 30,country == 'Japan')。
- 変換ステップは順番に適用される。
- ユーザーは UI を通じて、以下の変換ステップを定義できる (複数ステップ可):
-
ロード (Load):
- 変換後のデータを SQLite データベースの特定のテーブル (
ProcessedData) に保存する。 - テーブルには、どのパイプライン実行によってロードされたかを示す識別子 (
pipelineRunId) と、元のファイル名、処理時刻などのメタ情報を含める。
- 変換後のデータを SQLite データベースの特定のテーブル (
-
可視化:
- パイプラインの各ステージ (Extract, Transform Step 1, Transform Step 2, ..., Load) を UI 上で明確に表示する。
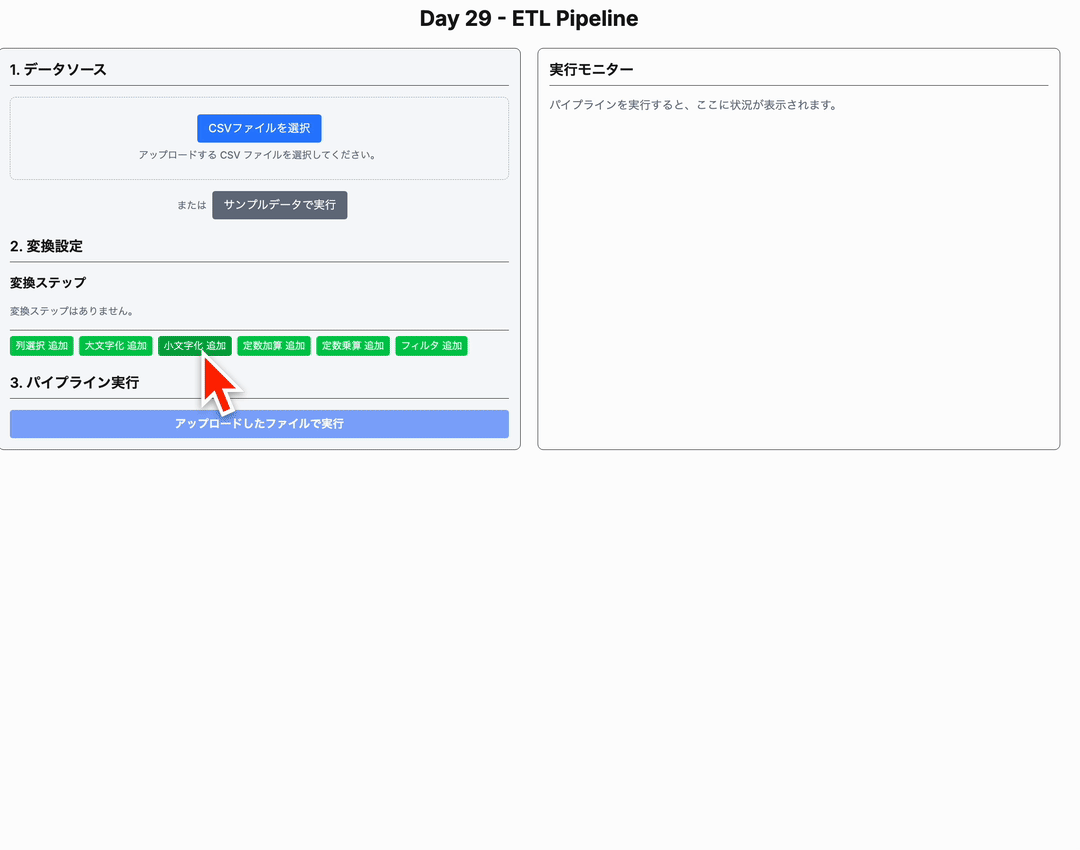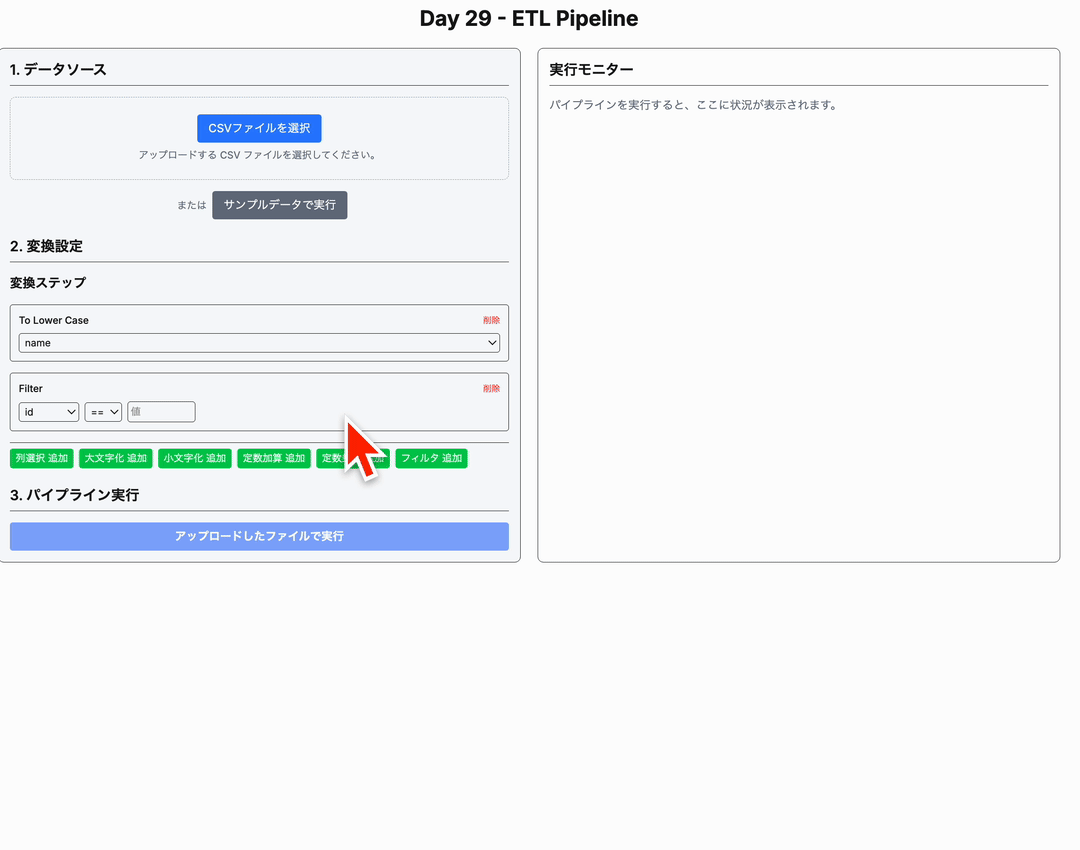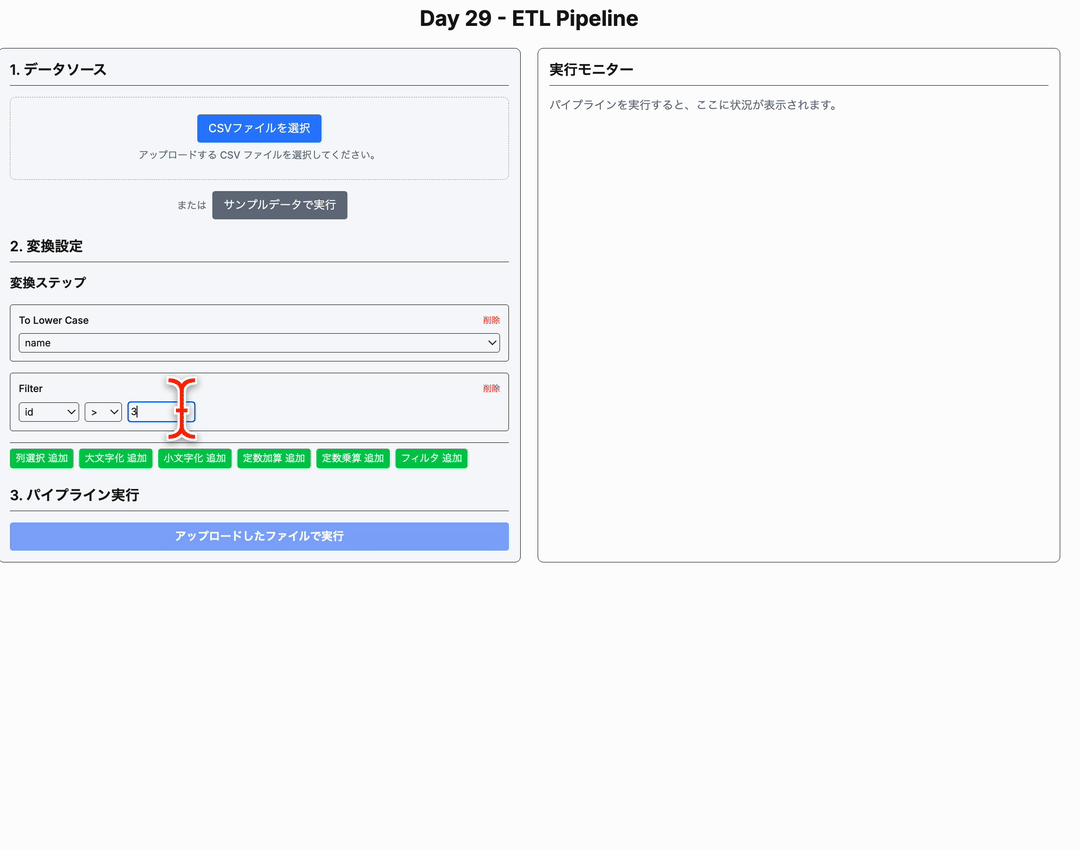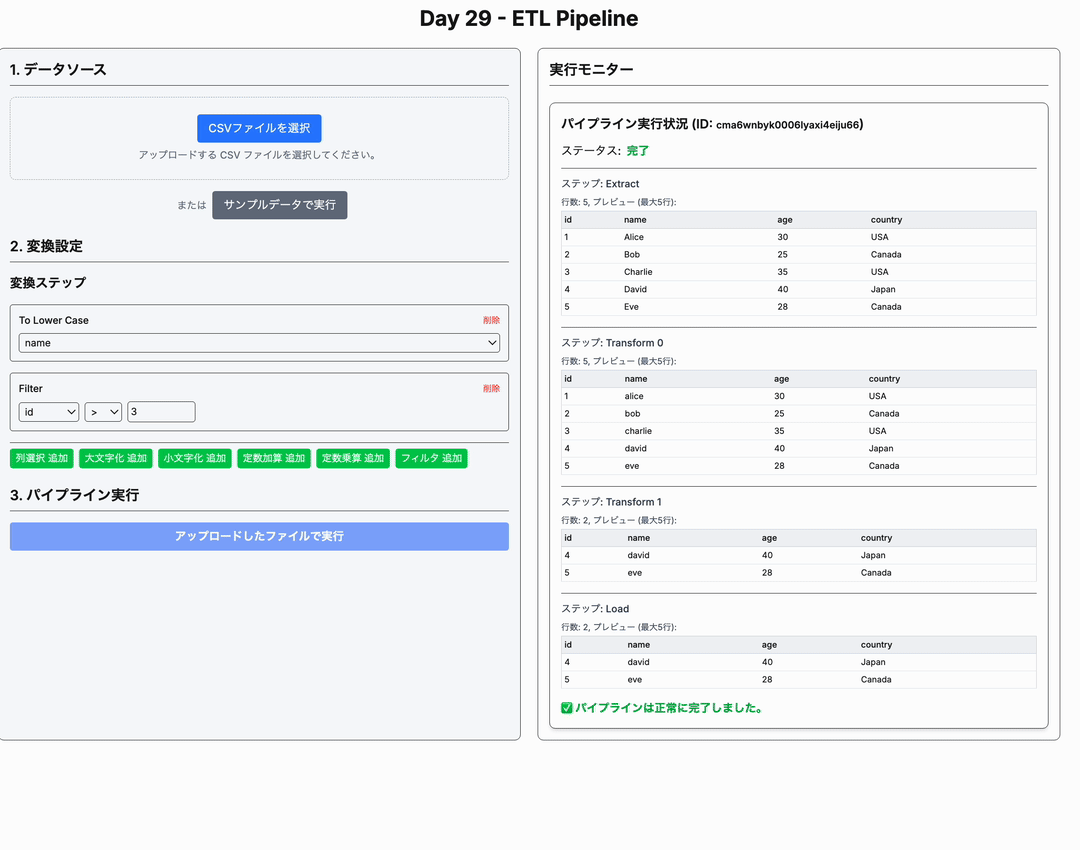
- 各ステージ完了時に、処理されたデータの一部 (例: 最初の 5 行) をプレビュー表示する。
- パイプライン全体の実行ステータス (実行中, 完了, エラー) を表示する。
-
ユーザー識別:
- 今回はシンプル化のため、ユーザー認証は行わない。パイプライン実行ごとの一意な ID でデータを管理する。
-
UI デザイン:
- ミニマリズムを基調とする。
- データの流れが直感的に理解できるよう、ステップごとに状態とデータプレビューを表示するデザインを採用する。
3. 技術スタック
- フレームワーク: Next.js (App Router)
- 言語: TypeScript
- データベース: SQLite
- ORM: Prisma
- スタイリング: Tailwind CSS
-
CSV パース:
papaparseまたは同様のライブラリ - 状態管理: React Context API または Zustand (必要に応じて)
4. データモデル (prisma/schema.prisma)
model ProcessedData {
id Int @id @default(autoincrement())
pipelineRunId String // パイプライン実行を識別するID
originalFilename String // 元のCSVファイル名
processedAt DateTime @default(now())
// 動的に変化するデータ列 (JSON形式で保持するのがシンプルか?)
data Json
}
// パイプラインの実行履歴と状態を管理するモデル (オプション)
model PipelineRun {
id String @id @default(cuid())
filename String
status String // 'running', 'completed', 'failed'
config Json // 実行時の変換設定
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
// 各ステップのプレビューデータなどを保存する場合 (Json or 別モデル)
// previewData Json?
}
補足: ProcessedData の data カラムを Json 型にするか、あるいはパイプラインごとに動的にテーブルを作成するかはトレードオフがあります。今回はシンプルにするため、Json 型で保持し、ロード時に構造を解釈する方針とします。パイプライン実行履歴 (PipelineRun) も追加して状態を管理します。
5. API エンドポイント (app/api/...)
-
POST /api/etl/run:- リクエストボディ:
multipart/form-data(CSV ファイルと変換設定 JSON) - レスポンス:
pipelineRunId - 処理: CSV を受け取り、変換設定を保存し、非同期で ETL パイプラインを開始する。
PipelineRunレコードを作成。
- リクエストボディ:
-
GET /api/etl/status/[pipelineRunId]:- レスポンス: パイプラインの現在のステータス、各ステップのプレビューデータ、最終結果 (完了時)。
- 処理: 指定された
pipelineRunIdの実行状況と関連データを取得して返す。
6. UI 構成 (app/(pages)/page.tsx, components/)
-
ルートページ (
/):- CSV アップロードエリア。
- 変換設定を行う UI (列選択、加工ルールの追加・編集・削除)。
- 「パイプライン実行」ボタン。
- 実行中のパイプラインのステータスとデータプレビューを表示するエリア。
- 過去の実行履歴一覧 (オプション)。
-
コンポーネント:
-
FileUpload: CSV ファイルアップロード用コンポーネント。 -
TransformConfigurator: 変換ステップを設定する UI。 -
PipelineMonitor: パイプラインの実行状況とデータプレビューを表示するコンポーネント。
-
7. 作業順序
-
プロジェクト初期化:
templateをコピーし、package.json、README.mdを更新。基本レイアウト作成。 -
データモデリングと DB 設定:
prisma/schema.prismaを定義し、prisma migrate deployを実行。 -
API エンドポイント実装:
POST /api/etl/runとGET /api/etl/status/[pipelineRunId]の基本的な骨組みを作成。 -
ETL コアロジック実装 (
app/_lib/etl.tsなど):- CSV パース (Extract)。
- 設定に基づいたデータ変換 (Transform)。
- DB への書き込み (Load)。
- 状態とプレビューデータを
PipelineRunに記録する処理。
-
UI コンポーネント実装:
FileUpload,TransformConfigurator,PipelineMonitorを作成。 -
ページ実装 (
app/page.tsx): UI コンポーネントを統合し、API と連携させる。 -
デバッグとテスト:
curlで API をテストし、ブラウザで一連の流れを確認。 -
ドキュメント作成:
README.mdとknowledge.mdcを更新。
上記仕様で進めてよろしいでしょうか? 問題なければ、プロジェクトの初期化から開始します。
なんかいまは gemini2.5の調子よくないな
ETLは、データ分析やデータウェアハウジングにおいて、データをある場所から別の場所へ移動し、利用可能な形式に整えるための一般的なプロセスです。以下の3つのステップで構成されます。
-
Extract (抽出)
- 役割: 元となるデータソースからデータを取り出す(抽出する)ステップです。データソースは、データベース、ファイル(CSV, JSON, XMLなど)、API、ログファイルなど様々です。
-
今回のアプリでの実装:
- ユーザーがアップロードしたCSVファイル、またはサーバー上に用意されたサンプルCSV (
public/sample.csv) を読み込みます。 -
papaparseライブラリを使ってCSVの内容を解析し、ヘッダー行をキーとしたJavaScriptオブジェクトの配列に変換します (app/_lib/etl.tsのrunEtlPipeline関数内)。 - この段階では、まだ元のデータに近い状態です。
- ユーザーがアップロードしたCSVファイル、またはサーバー上に用意されたサンプルCSV (
-
Transform (変換)
-
役割: 抽出したデータを、最終的な格納先(ロード先)や分析に適した形式に加工・変換するステップです。最も複雑になりがちな部分で、以下のような処理が含まれます。
- クリーニング: 不要なデータの削除、欠損値の補完、表記揺れの統一など。
- 構造化: データの形式変更(例: 日付フォーマットの統一)、列の分割・結合、集計など。
- エンリッチメント: 他のデータソースと結合して情報を付加するなど。
- フィルタリング: 特定の条件に合うデータのみを選別する。
-
今回のアプリでの実装:
- ユーザーがUI (
TransformConfigurator) で定義した変換ルール (TransformConfig) に基づいて、データを順番に加工します。 - 実装されている変換ルールには、列選択 (
selectColumns)、大文字/小文字変換 (toUpperCase,toLowerCase)、定数加算/乗算 (addConstant,multiplyConstant)、フィルタリング (filter) があります (app/_lib/etl.tsのapplyTransformStep関数)。 - 各変換ステップ完了後のデータの一部はプレビュー用に保持されます。
- ユーザーがUI (
-
役割: 抽出したデータを、最終的な格納先(ロード先)や分析に適した形式に加工・変換するステップです。最も複雑になりがちな部分で、以下のような処理が含まれます。
-
Load (ロード)
- 役割: 変換されたデータを、最終的なターゲットシステム(データベース、データウェアハウス、データレイクなど)に書き込む(ロードする)ステップです。
-
今回のアプリでの実装:
- 変換後のデータ(JavaScriptオブジェクトの配列)を、SQLiteデータベースの
ProcessedDataテーブルに保存します (app/_lib/etl.tsのrunEtlPipeline関数内)。 -
prisma.processedData.createManyを使用して、効率的に複数行をデータベースに挿入します。 - どのパイプライン実行によってロードされたデータかを示す
pipelineRunIdやファイル名などのメタ情報も一緒に保存されます。
- 変換後のデータ(JavaScriptオブジェクトの配列)を、SQLiteデータベースの
今回のアプリケーションでは、これら ETL の各ステップの間に「可視化」の要素を加えています。PipelineMonitor コンポーネントが、各ステップ(Extract, Transform 0, Transform 1, ..., Load)完了時点でのデータの一部をプレビュー表示することで、データがどのように変化していくかを追跡できるようにしています。これは純粋な ETL プロセスには含まれませんが、学習やデバッグに役立ちます。
本番の倍
はい、今回の簡易 ETL パイプラインは学習目的で基本的な流れを実装したものですが、本番環境で堅牢かつ大規模なデータを扱うには、専用の ETL ツールやデータパイプラインオーケストレーションツール(例: Apache Airflow, Prefect, Dagster, AWS Glue, Azure Data Factory, Google Cloud Dataflow など)を利用することが一般的です。
それらのツールが解決してくれる、あるいは本番環境でより深く考慮すべきポイントは主に以下の点です。
-
スケーラビリティとパフォーマンス:
- 課題: 今回の実装は単一の Node.js プロセスで、比較的小さな CSV をメモリ上にロードして処理しています。データ量が GB、TB 単位になったり、処理が複雑になったりすると、メモリ不足や処理時間の増大で破綻します。
-
考慮点:
- 分散処理: 大量データを複数のマシンやノードで並列処理する仕組み (例: Apache Spark, Dask)。
- ストリーミング処理: データを一括ではなく、継続的に発生するものとして逐次処理する仕組み (例: Apache Kafka, Flink, Spark Streaming)。
- リソース管理: 処理に必要な計算リソース (CPU, メモリ) を効率的に割り当て、管理する。
- 効率的な I/O: データベースやストレージへの読み書きを最適化する (バルクインサート、適切なファイルフォーマット選択など)。
-
信頼性とフォールトトレランス:
- 課題: 今回の実装では、処理の途中でエラーが発生した場合、中途半端な状態で停止し、手動でのリカバリが必要です。データの欠損や重複が発生する可能性があります。
-
考慮点:
- リトライ機構: 一時的なネットワークエラーなどで失敗した場合、自動的に再試行する。
- チェックポインティング: 長時間かかる処理の途中で状態を保存し、失敗時に途中から再開できるようにする。
- デッドレターキュー: 処理に失敗したデータを隔離し、後で調査・再処理できるようにする。
- 冪等性 (Idempotency): 同じ処理を複数回実行しても、結果が常に同じになるように設計する(再試行しても問題ないように)。
- トランザクション管理: 特に Load ステップで、データの整合性を保つ(例: 一部だけロードされて終わらないように)。
-
モニタリングとアラート:
- 課題: 今回はブラウザ UI で簡易的に状況を表示していますが、本番ではバックグラウンドで自動実行されることが多く、実行状況の把握が不可欠です。
-
考慮点:
- 実行ログの詳細化: 各ステップの開始・終了、処理件数、エラー詳細などを構造化ログとして出力する。
- メトリクス収集: 実行時間、スループット、エラー率などの指標を収集し、可視化する (例: Prometheus, Grafana, Datadog)。
- アラート通知: パイプラインの失敗、遅延、異常なメトリクスなどを検知し、関係者に通知する (例: Slack, PagerDuty)。
-
スケジューリングとオーケストレーション:
- 課題: 今回は手動実行のみです。本番では定期実行(例: 毎日深夜)や、他のパイプライン完了をトリガーにした実行など、複雑な依存関係の管理が必要です。
-
考慮点:
- ジョブスケジューラ: 定期実行や時間ベースのトリガーを設定する。
- ワークフローエンジン: 複数の処理ステップやパイプライン間の依存関係を定義し、実行順序を制御する (Airflow などがこれを提供)。
-
データ品質とバリデーション:
- 課題: 入力データの形式が想定外だったり、値が異常だったりする場合の考慮が不足しています。
-
考慮点:
- スキーマバリデーション: 期待されるデータの構造(列名、型など)を検証する。
- データプロファイリング: データの統計情報(最小値、最大値、NULL率、ユニーク数など)を計算し、異常を検知する。
- 品質ルール: ビジネスルールに基づいたチェック(例: 特定の列の値が範囲内か、特定のフォーマットか)を行う。
- エラーデータのハンドリング: 検証でエラーとなったデータをどう扱うか(処理停止、隔離、ログ記録など)を定義する。
-
セキュリティ:
- 課題: データソースやロード先への接続情報、処理中のデータなどのセキュリティが考慮されていません。
-
考慮点:
- 認証・認可: データソース、ロード先、ETLツール自体へのアクセス制御。
- 認証情報管理: パスワードや API キーなどの機密情報を安全に管理する (例: Secrets Manager)。
- データ暗号化: 通信経路 (in transit) や保存時 (at rest) のデータを暗号化する。
- マスキング・匿名化: 個人情報などの機密データを処理中にマスキング・匿名化する。
-
スキーマ変更への対応 (Schema Evolution):
- 課題: データソースのスキーマ(列の追加・削除・型変更など)が変わった場合にパイプラインが追随できません。
-
考慮点:
- スキーマ変更を自動検知する仕組み。
- 変更に対してパイプラインが柔軟に対応できる設計(例: 互換性のある変更は許容、破壊的な変更はエラーにするなど)。
- ターゲットスキーマの更新とマイグレーション。
これらはほんの一部ですが、本番環境の ETL パイプラインを構築・運用する上で非常に重要な観点です。専用ツールはこれらの多くを支援する機能を提供しています。
はい、本番環境でよく利用される代表的な ETL / データパイプライン関連ツールをいくつかご紹介します。それぞれ得意分野や特徴が異なります。
-
データパイプラインオーケストレーションツール:
-
Apache Airflow:
- Python でパイプライン(DAG: 有向非巡回グラフ)をコードとして定義し、スケジューリング、実行、モニタリングを行う業界標準的なオープンソースツール。豊富なオペレーター(連携用プラグイン)があり、様々なシステムと連携可能。拡張性が高い反面、設定や運用に学習コストがかかることも。
-
Prefect:
- Airflow と同様に Python ベースのワークフローオーケストレーションツール。Airflow よりも動的なパイプライン定義やモダンな UI/UX を目指している。ローカル実行からクラウド版 (Prefect Cloud) まで提供。
-
Dagster:
- データパイプラインの開発、テスト、デプロイ、運用に焦点を当てた比較的新しいツール。データアセット(パイプラインが生成/利用するテーブルやファイルなど)の概念や、ローカルでの開発体験、テスト容易性を重視している。
-
Apache Airflow:
-
分散データ処理エンジン:
-
Apache Spark:
- 大規模データ処理のための高速な統合エンジン。バッチ処理、ストリーミング処理、機械学習、グラフ処理などを単一のフレームワークで扱える。SQL ライクな API (Spark SQL) や DataFrame API を提供し、多くの言語 (Scala, Java, Python, R) から利用可能。Airflow などから Spark ジョブをキックすることが多い。
-
Apache Spark:
-
クラウドプラットフォームのフルマネージドサービス:
-
AWS Glue:
- AWS のサーバーレス ETL サービス。データカタログ機能と ETL ジョブ実行機能(内部的に Spark を利用)を提供。他の AWS サービスとの連携が容易。
-
Azure Data Factory (ADF):
- Microsoft Azure のクラウドベース ETL およびデータ統合サービス。GUI ベースでパイプラインを構築でき、多数のデータソース/シンクへのコネクタを持つ。内部的に Spark (Data Flows) や SQL Server Integration Services (SSIS) を利用可能。
-
Google Cloud Dataflow:
- Google Cloud のストリーミングおよびバッチデータ処理のためのフルマネージドサービス。Apache Beam SDK を使用してパイプラインを定義し、Dataflow がリソース管理や実行を自動で行う。
-
Google Cloud Dataproc:
- Apache Spark や Hadoop クラスタを簡単にデプロイ・管理できる Google Cloud のマネージドサービス。Spark ジョブを実行する基盤として利用される。
-
AWS Glue:
-
データ統合プラットフォーム (ELT/ETL 特化型):
-
Fivetran / Stitch (Talend):
- 主にデータソースからデータウェアハウスへのデータロード(ELT: Extract, Load, Transform)を自動化することに特化した SaaS。多数のコネクタを提供し、設定のみでデータ連携を開始できることが多い。
-
Talend / Informatica:
- エンタープライズ向けの老舗データ統合プラットフォーム。GUI ベースの開発環境で複雑な ETL プロセスを設計・実行できる。オンプレミス/クラウド両対応。
-
Fivetran / Stitch (Talend):
ツールの選択:
どのツールを選ぶかは、データの規模、処理の複雑さ、既存の技術スタック(特にクラウド環境)、チームのスキルセット、予算(オープンソースか商用/マネージドか)などによって異なります。
小〜中規模で Python が得意なチームなら Airflow, Prefect, Dagster + Spark (必要なら) が選択肢になりますし、特定のクラウドプラットフォームに深く依存しているなら、そのクラウドのマネージドサービス (AWS Glue, ADF, Dataflow) が有力候補となることが多いです。単純なデータ同期なら Fivetran などが適している場合もあります。