Closed7
100日チャレンジ day19 (ジョブスケジューラー)
昨日
100日チャレンジに感化されたので、アレンジして自分でもやってみます。
やりたいこと
- 世の中のさまざまなドメインの簡易実装をつくり、バックエンドの実装に慣れる(dbスキーマ設計や、関数の分割、使いやすいインターフェイスの切り方に慣れる
- 設計力(これはシステムのオーバービューを先に自分で作ってaiに依頼できるようにする
- 生成aiをつかったバイブコーティングになれる
- 実際にやったことはzennのスクラップにまとめ、成果はzennのブログにまとめる(アプリ自体の公開は必須ではないかコードはgithubにおく)
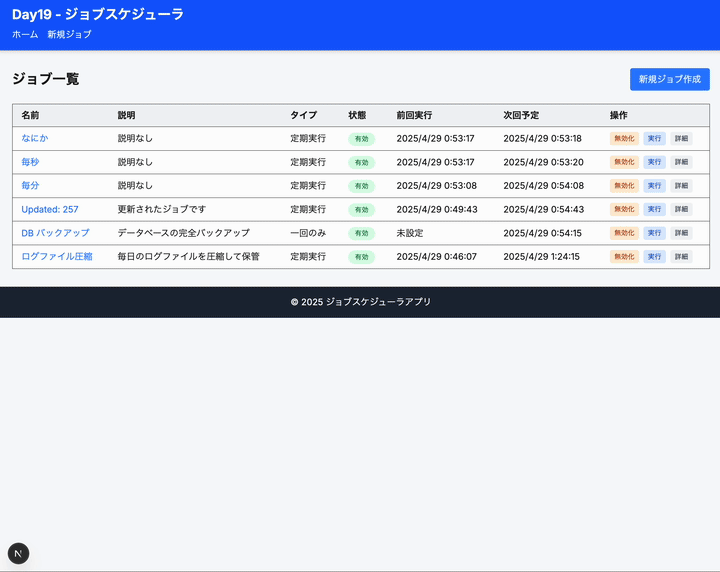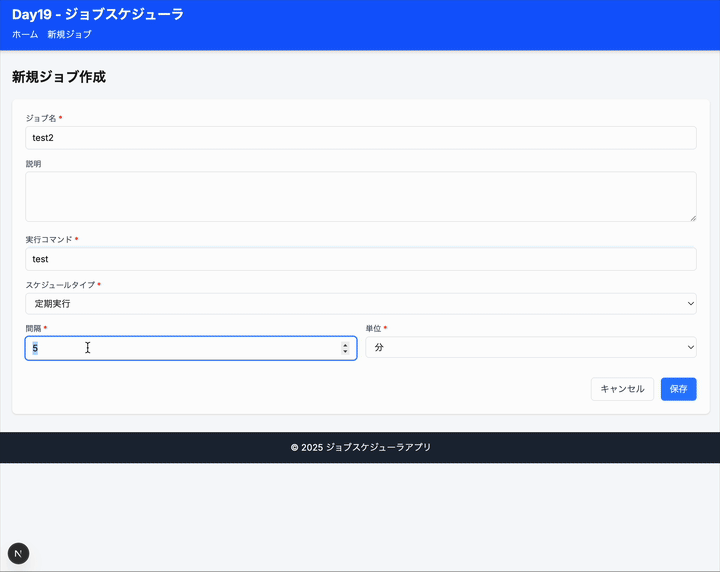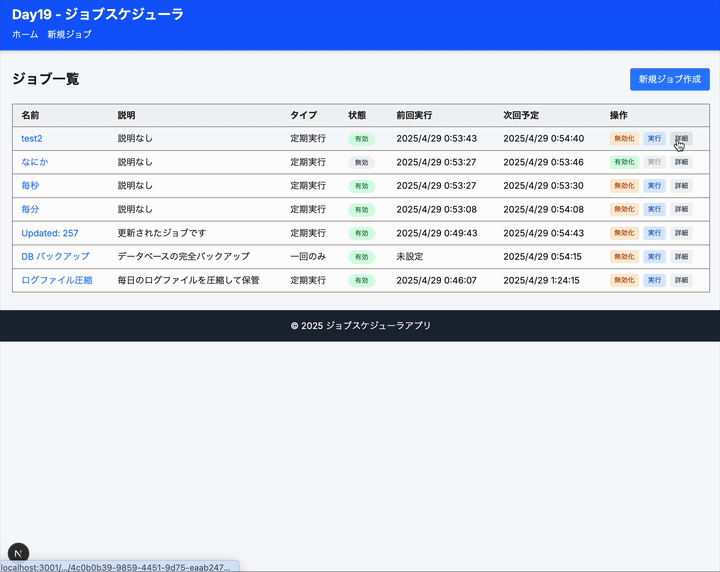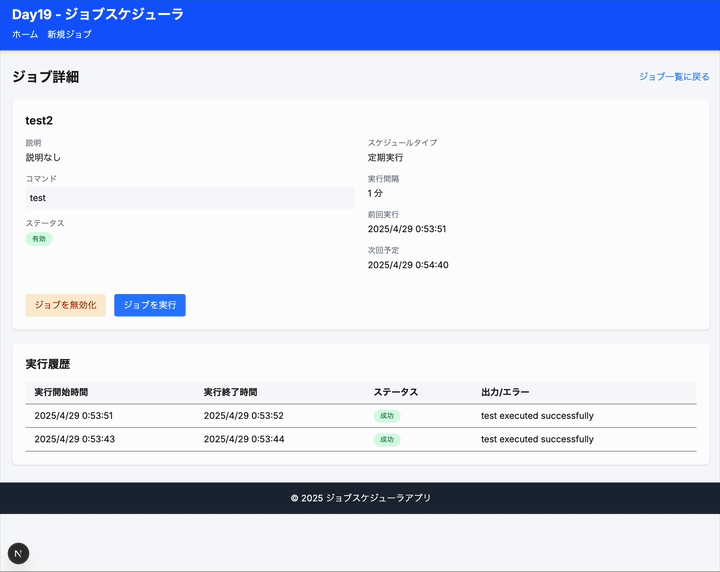
できたもの
はい、DBに保存する形で実装します。以下に修正した要件定義を示します:
ジョブスケジューラ要件定義(DB保存版)
1. 概要
シンプルなジョブスケジューラシステムを開発します。ユーザーがタスクを登録し、一定の時間間隔または特定の時間に実行されるようスケジュールできるアプリケーションです。すべてのデータはSQLiteデータベースに永続化されます。
2. 主要機能
2.1 ジョブ管理
- ジョブの作成・編集・削除(SQLiteに保存)
- ジョブ名、説明、コマンド(シミュレーション用)の設定
- ジョブの有効/無効切り替え
2.2 スケジュール設定
- 実行タイプ:一回のみ実行、定期実行(時間間隔指定)
- 一回のみ:特定の日時を指定
- 定期実行:分/時間/日単位での実行間隔指定(例:10分ごと、1時間ごと)
2.3 ジョブ実行と状態管理
- ジョブ実行のシミュレーション(実際のコマンド実行ではなく状態変更のみ)
- ジョブの状態管理(待機中、実行中、成功、失敗)
- 実行履歴のDB保存と表示(開始時間、終了時間、ステータス)
2.4 ユーザーインターフェース
- ジョブ一覧表示(状態、次回実行時間を含む)
- ジョブ作成・編集フォーム
- 実行履歴の閲覧
- シンプルなダッシュボード表示
3. データモデル(Prisma Schema)
3.1 Job(ジョブ)
model Job {
id String @id @default(uuid())
name String
description String?
command String
scheduleType String // 'once' または 'interval'
scheduledAt DateTime? // 一回のみ実行の場合の予定時刻
interval Int? // 定期実行の場合の間隔(数値)
intervalUnit String? // 'minute', 'hour', 'day'
isActive Boolean @default(true)
lastRunAt DateTime? // 最後に実行された時刻
nextRunAt DateTime? // 次回実行予定時刻
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
histories JobHistory[]
}
3.2 JobHistory(実行履歴)
model JobHistory {
id String @id @default(uuid())
job Job @relation(fields: [jobId], references: [id], onDelete: Cascade)
jobId String
startedAt DateTime
finishedAt DateTime?
status String // 'running', 'success', 'failed'
log String?
createdAt DateTime @default(now())
}
4. 技術的実装詳細
- SQLite + Prisma を使用してデータを永続化
- フロントエンドから定期的なAPIポーリングによるジョブ状態更新チェック
- サーバーサイドでジョブの次回実行時間の計算と更新
- API経由で実行状態の変更と履歴の記録
- 実際のジョブ実行はシミュレーションのみ(ランダムな成功/失敗と所要時間)
5. 実装範囲と制約
- 実際のコマンド実行はシミュレーションのみ
- ユーザー認証なし(シンプルなUIで操作)
- 30分以内で実装可能な機能に限定
これでよろしいでしょうか?
もうできた
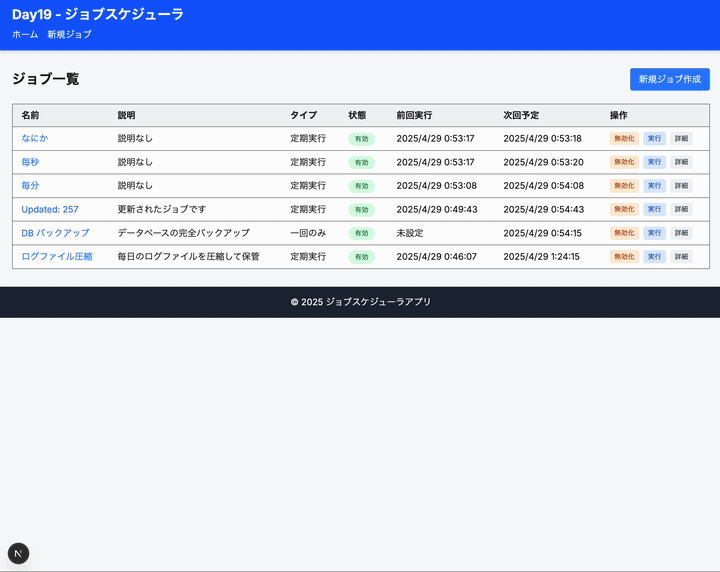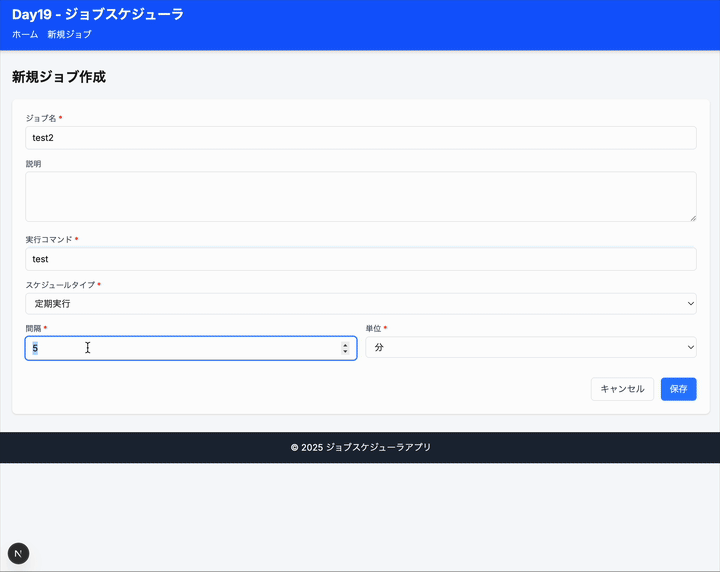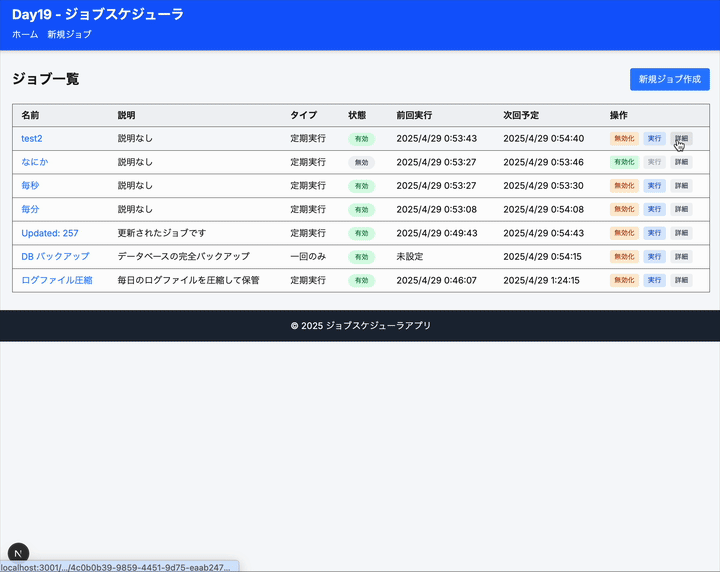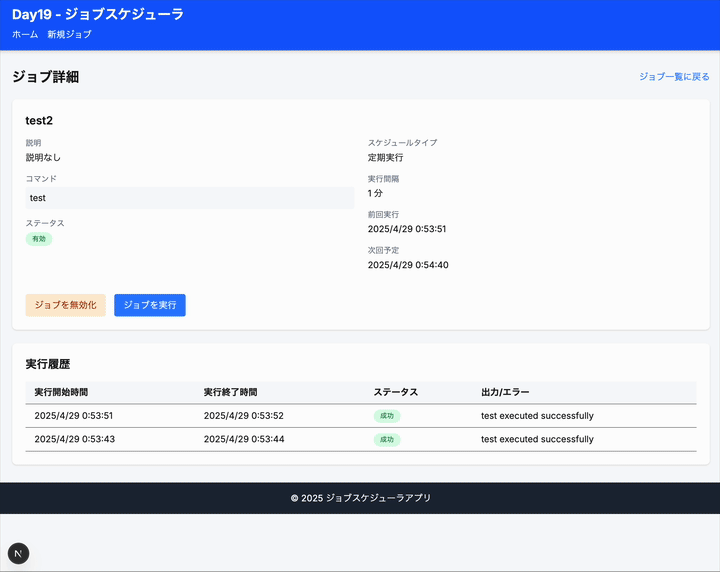
これジョブがもっと大量になってきたらどう捌くんだろう。k8s の cronjob に登録するやり方もあるだろうけど、それがないときは DB にいれておいて、定期的にサルベージしてキューに突っ込んで実行なのかなあ。
スケーラビリティを担保したジョブ基盤の設計について説明します。
スケーラブルなジョブスケジューラの設計
1. アーキテクチャの基本概念
-
分散キューシステム
- RabbitMQ、Kafka、Redisなどのメッセージキューを活用
- ジョブはメタデータとして保存され、実行時にキューに投入
-
ワーカープール
- 複数のワーカーノードで構成
- 各ワーカーはキューからジョブを取得して処理
- 水平スケーリングが可能
-
マスター/スケジューラノード
- ジョブのスケジューリングと監視を担当
- 複数のスケジューラノードをリーダー選出方式で冗長化
2. 具体的な実装戦略
-
ジョブの保存と管理
- DBはジョブのメタデータと設定の保存に使用
- 実行予定ジョブはDBから定期的に読み取り、実行時間が近づいたものをキューに投入
-
分散処理とフェイルオーバー
- ジョブ実行はワーカープールに分散
- ワーカーの死活監視と自動復旧機能
- 実行失敗時の再試行戦略(指数バックオフなど)
-
スケーリング手法
- 垂直分割: ジョブタイプ別にキューを分割
- 水平分割: ジョブのシャーディング(例:ユーザーIDによる分散)
- ワーカー動的割り当て: 負荷に応じてワーカー数を自動調整
3. 具体的な実装例
ジョブスケジューラ
↓
DBから実行予定ジョブを取得
↓
メッセージキュー(RabbitMQ/Kafka)にエンキュー
↓
複数ワーカーがデキュー
↓
ジョブ実行&結果保存
4. 考慮すべき点
- 耐障害性: 単一障害点を排除
- べき等性: 同じジョブが複数回実行されても問題ないよう設計
- モニタリング: ジョブ実行状況の可視化と異常検知
- リソース管理: CPUやメモリ使用率の制限とバランシング
5. オープンソース選択肢
- 分散処理: Apache Airflow, Temporal, Celery
- 専用ツール: JobRunr, ShedLock, Quartz Scheduler
- Kubernetesベース: CronJob + カスタムオペレーター
大規模システムでは、単一のサーバーでジョブを実行するのではなく、分散システムとキューイングを組み合わせた堅牢な設計が必要です。
ジョブスケジューラにおける時間管理の仕組みは主に以下の部分で実装されています:
-
ジョブの次回実行時間(nextRunAt)の計算
-
calculateNextRunTime関数で実装 - ジョブのスケジュールタイプ(once/interval)に基づいて次回実行時間を計算
- 間隔実行の場合は単位(秒/分/時間/日)と値に基づいて計算
-
-
実行すべきジョブの検索
-
checkAndRunDueJobs関数内で実装 - 現在時刻と比較して実行時間を過ぎたジョブを検索
const dueJobs = await prisma.job.findMany({ where: { isActive: true, nextRunAt: { lte: now } } }); -
-
ジョブ実行後の次回実行時間更新
- ジョブ実行後に
updateNextRunTime関数で次回実行時間を更新 - 一度だけ実行の場合は実行後にジョブを無効化
- ジョブ実行後に
-
定期的なチェック処理
- APIエンドポイント(
/api/scheduler/check)を定期的に呼び出す - 実運用では通常、外部のcronジョブやタイマー(Node.jsの
setIntervalなど)で数分ごとに呼び出し
- APIエンドポイント(
現在のデモ実装では正確な時間管理が厳密ではありませんが、本番環境では以下のアプローチが考えられます:
- 専用のスケジューラープロセスを作成
- 分散環境での時間同期のために分散ロックを使用
- ジョブの遅延・ずれを防ぐために時間のドリフト補正
大規模システムでは、時間精度に加えて耐障害性も考慮した設計が必要です。
このスクラップは2025/05/03にクローズされました