100日チャレンジ day34 (自作RDBMSとREPL、B+Treeビジュアライザー)
昨日
100日チャレンジに感化されたので、アレンジして自分でもやってみます。
やりたいこと
- 世の中のさまざまなドメインの簡易実装をつくり、バックエンドの実装に慣れる(dbスキーマ設計や、関数の分割、使いやすいインターフェイスの切り方に慣れる
- 設計力(これはシステムのオーバービューを先に自分で作ってaiに依頼できるようにする
- 生成aiをつかったバイブコーティングになれる
- 実際にやったことはzennのスクラップにまとめ、成果はzennのブログにまとめる(アプリ自体の公開は必須ではないかコードはgithubにおく)
できたもの
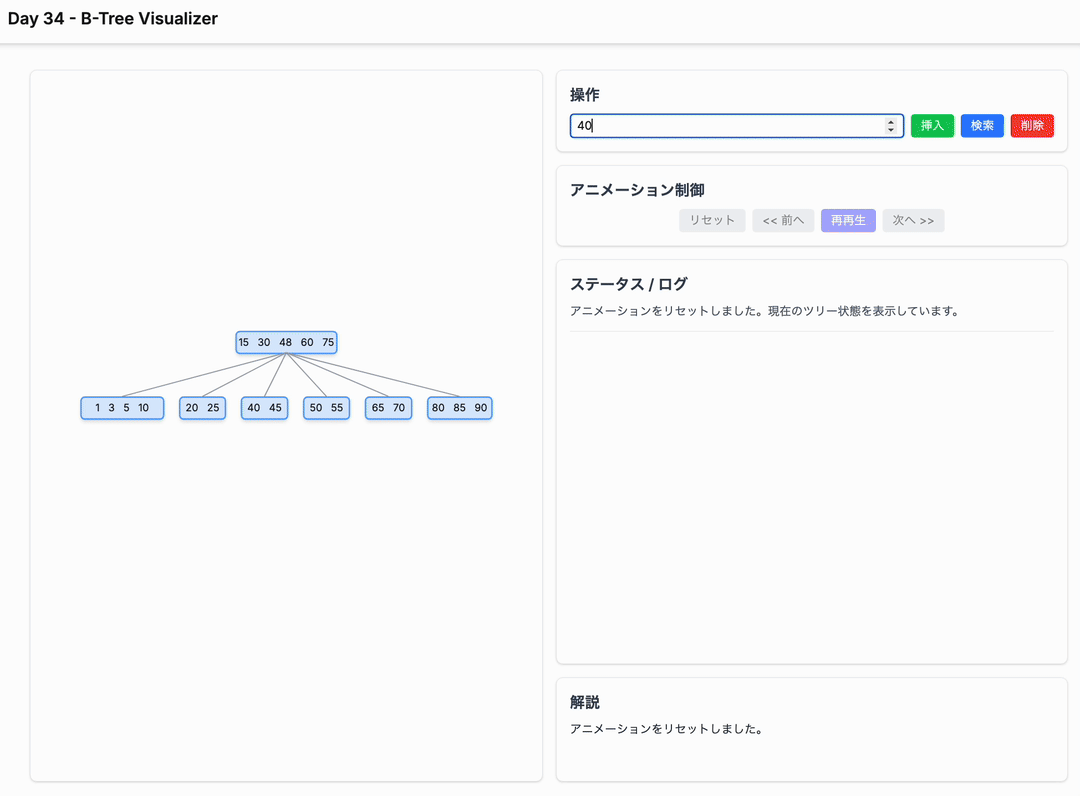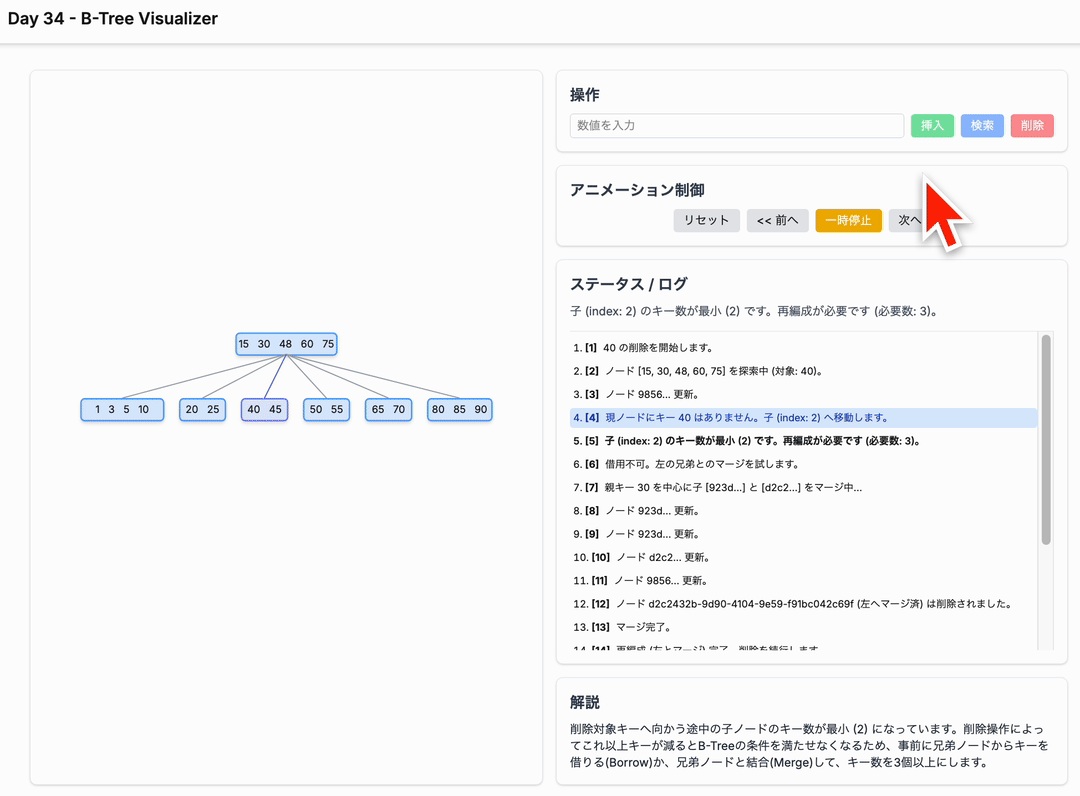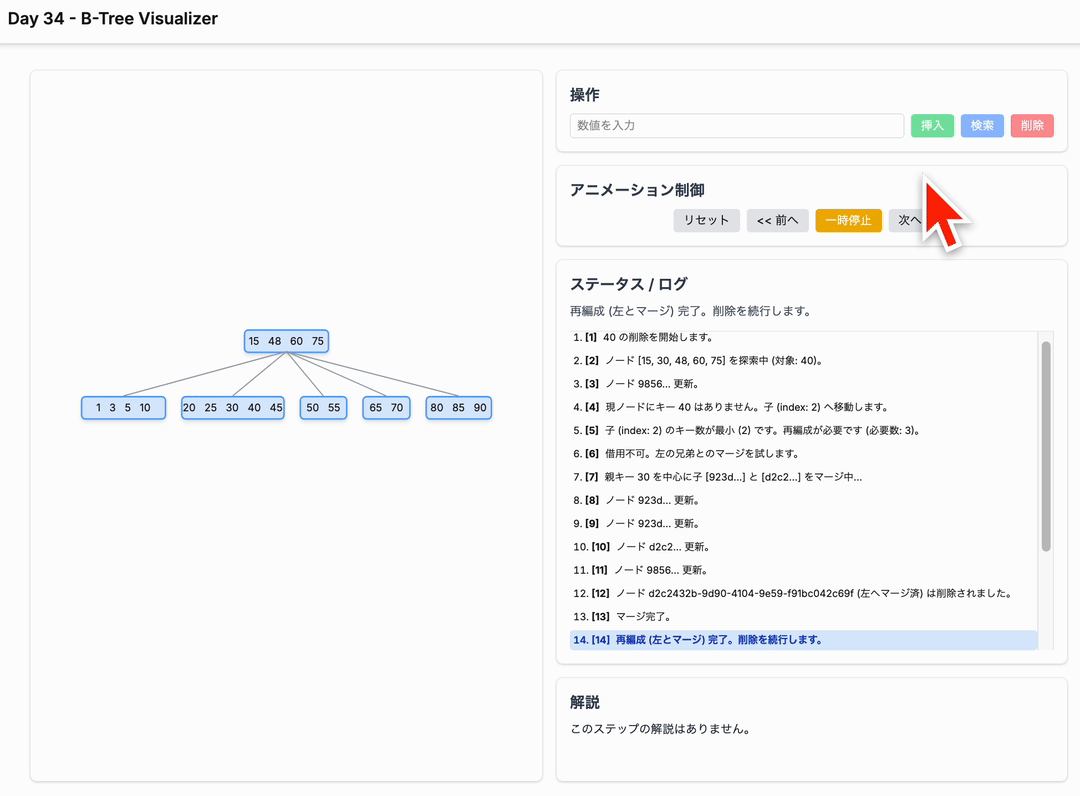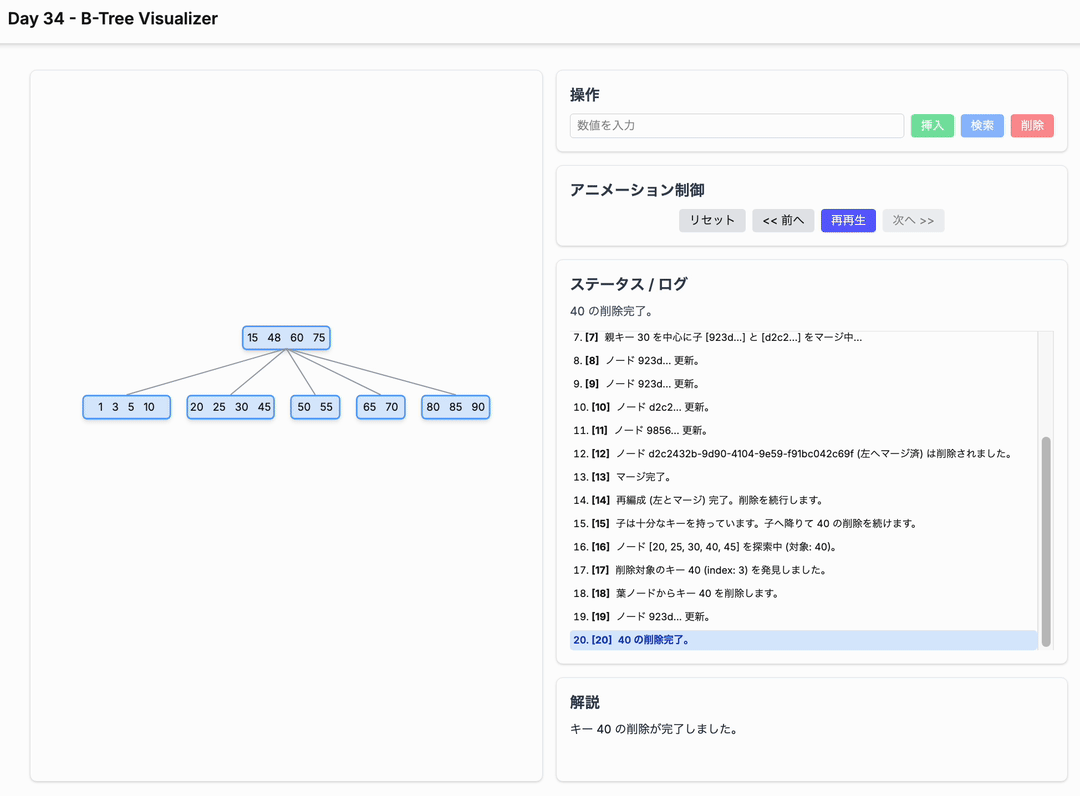
100day_challenge_backend/day34_btree_db at main · lirlia/100day_challenge_backend
RDBMS を作る
RDBMSを1から作るのは、データベースの内部構造を深く理解する上で非常に興味深く、学習効果の高いテーマですね!ストレージエンジン、クエリパーサー、オプティマイザ、トランザクション管理など、学ぶべき要素は多岐にわたります。
ただ、本格的なRDBMSの実装は非常に大規模で複雑なプロジェクトになります。100日チャレンジの1日という限られた時間の中では、ごく一部の機能(例えば、非常に単純なSQLパーサーとインメモリでのデータ操作)を実装するのが現実的な範囲になりそうです。
もし、データベースの内部実装に焦点を当てるのであれば、以下のような、よりスコープを絞ったテーマはいかがでしょうか?
- シンプルなKey-Valueストアの実装: B+Treeなどのデータ構造を用いて、基本的なCRUD操作(作成、読み取り、更新、削除)を実装する。永続化はファイルに行う。
-
SQLサブセットパーサー&実行エンジン:
SELECT * FROM table WHERE id = ?やINSERT INTO table VALUES (...)のような、ごく限られたSQL構文のみを解釈し、インメモリまたは単純なファイルベースでデータを操作するエンジンを作成する。 - ログ構造化マージツリー (LSM Tree) ベースのストレージエンジン: LSM Tree の基本的な概念(メモリテーブル、SSTable、コンパクション)を実装し、書き込み効率の高いストレージエンジンを体験する。
これらのテーマであれば、1日である程度の形にしつつ、データベースのコアな技術要素に触れることができるかと思います。
RDBMSの自作というアイデア自体は非常に面白いので、もし上記の縮小案にご興味があれば、どれかを選んで進めましょう。あるいは、もし全く別のテーマが良いようでしたら、それも遠慮なくお申し付けください!
rdbms のうち焦点に当てたいのは b+tree によるデータの格納と基本的なcrud 操作です。(発展として where / order / join なども欲しい)
また parser は前つく他ので既存のライブラリで良いです。
言語は go で構いません。
これだとスコープとしてどうでしょうか
なるほど、B+Tree によるデータ格納と基本的なCRUD操作にフォーカスし、パーサーは既存ライブラリを活用する、という方針ですね。言語がGoという点も承知しました。
そのスコープであれば、1日のチャレンジとして非常に良いバランスだと思います!
スコープの詳細化:
-
コア目標:
- GoでB+Treeのノード構造(キー、子ポインタ/データポインタ、次数など)を定義します。
- キーと値(ペイロード)を格納できるB+Treeを メモリ上 に構築します。
- 挿入 (Insert): キーと値をB+Treeに挿入するロジックを実装します。ノードがいっぱいになった場合の ページ分割 処理も含みます。
- 検索 (Search): 指定されたキーに対応する値をB+Treeから検索するロジックを実装します。
- 削除 (Delete): 指定されたキーと値を持つエントリをB+Treeから削除するロジックを実装します。(時間があれば、ノードのマージや再配布などのリバランス処理も考慮しますが、まずは単純な削除を目指しましょう。)
-
テーブル表現: 単純な
map[string]*BTreeのような形で、テーブル名をキーとしてB+Treeインスタンスを管理する構造を考えます。
-
パーサー連携:
- GoのSQLパーサーライブラリ(例えば
github.com/xwb1989/sqlparserやgithub.com/pingcap/tidb/parserなど、比較的シンプルなものを選定)を導入します。 - 非常に基本的なSQLクエリ (
INSERT INTO table (id, name) VALUES (...),SELECT name FROM table WHERE id = ...,DELETE FROM table WHERE id = ...) をパースし、上記のB+Tree操作(Insert, Search, Delete)に変換する処理を実装します。
- GoのSQLパーサーライブラリ(例えば
-
発展的な目標 (時間があれば):
- 永続化: B+Treeのノードを固定サイズの「ページ」としてファイルに書き出し、読み込む基本的な仕組みを実装します。(ページキャッシュなどは一旦考えません)
-
範囲検索:
SELECT name FROM table WHERE id > ... AND id < ...のような基本的な範囲検索をB+Treeのリーフノード走査で実装します。 -
全件スキャン:
SELECT * FROM tableのような全件スキャンを実装します。
WHERE句、ORDER BY句、JOIN句について:
-
WHERE: 上記の通り、主キー(B+Treeのキー)に基づく単純な等価比較 (
=) や範囲比較 (>,<) はスコープに含められそうです。複合条件や非キー列での検索は除外します。 -
ORDER BY: B+Treeはキー順にデータが格納されているため、主キーでの
ORDER BYは暗黙的に実現されますが、明示的なORDER BY句の処理や他の列でのソートはスコープ外とします。 - JOIN: 複数のB+Tree(テーブル)を組み合わせるJOINは、実装の複雑さが格段に上がるため、明確にスコープ外とします。
このスコープで進めることで、RDBMSのコアであるストレージエンジン(特にインデックス構造)とクエリ処理の基本的な流れを体験できると考えられます。
作業順序案:
-
プロジェクト初期化:
-
day34_btree_dbディレクトリを作成し、Goプロジェクトを初期化します (go mod init ...)。 - READMEに今回の目標を記載します。
-
-
B+Tree 実装 (メモリ上):
- ノード構造 (
Node,LeafNodeなど) を定義します。 - Insert, Search, Delete の基本操作を実装します。まずはメモリ上で動作確認します。
- ノード構造 (
-
テーブル管理:
- テーブル名とB+Treeインスタンスを紐付ける簡単な管理機構を実装します。
-
SQLパーサー導入と連携:
- SQLパーサーライブラリを選定・導入します。
- 基本的な
INSERT,SELECT (WHERE id = ...),DELETE (WHERE id = ...)をパースし、B+Tree操作を呼び出す処理を実装します。
-
(発展) 永続化:
- B+Treeノードをページとしてファイルに読み書きする処理を追加します。
-
(発展) 範囲検索・全件スキャン:
- 必要に応じて実装します。
-
動作確認:
- 簡単なテストコードや
main関数でCRUD操作やSQL実行をテストします。
- 簡単なテストコードや
-
ドキュメント更新:
- READMEを完成させ、実装した内容や使い方を記述します。
-
knowledge.mdを更新します。
この計画で進めてよろしいでしょうか?
ちなみに作るかどうかは置いといて、rdbms の基本としてほかにどの分野や機能がある?
RDBMSは非常に多くのコンポーネントと機能から成り立っています。B+Treeによるデータ格納と基本的なCRUD操作以外に、主要なものを挙げると以下のようになります。
-
クエリプロセッサ (Query Processor):
- パーサー (Parser): ユーザーが入力したSQL文の文字列を解析し、コンピュータが理解できる内部的なデータ構造(通常は抽象構文木: AST)に変換します。文法的に正しいかをチェックします。
- オプティマイザ (Optimizer): ASTを受け取り、そのSQLクエリを実行するための最も効率的(と推測される)な方法(実行計画: Execution Plan)を決定します。どのインデックスを使うか、テーブルをどの順序で結合するかなどを決定します。統計情報などを基にコストを見積もることが多いです(コストベースオプティマイザ)。
- 実行エンジン (Executor): オプティマイザが生成した実行計画に従って、実際にストレージエンジンからデータを読み書きし、加工(フィルタリング、ソート、結合など)して最終的な結果を生成します。
-
ストレージエンジン (Storage Engine):
- ページ/バッファ管理 (Buffer Management): ディスク上のデータは「ページ」という単位で管理され、頻繁にアクセスされるページはメモリ上の「バッファプール」にキャッシュされます。ディスクI/Oを最小限に抑えるための重要な機能です。どのページをメモリに残し、どのページをディスクに書き戻すかなどを管理します (LRUアルゴリズムなどが使われます)。
- インデックス管理 (Index Management): B+Tree以外にも、ハッシュインデックス、全文検索インデックス、空間インデックスなど、様々な種類のインデックス構造があり、クエリの種類に応じて最適なインデックスを提供します。
- 永続化とログ記録 (Persistence & Logging): データの変更を安全にディスクに記録するための仕組みです。多くの場合、Write-Ahead Logging (WAL) という技術が使われ、データの変更内容をまずログファイルに書き込んでから、実際のデータページを更新します。これにより、システムクラッシュ時にもデータの一貫性を保ち、復旧(リカバリ)が可能になります。
-
トランザクション管理 (Transaction Management):
- 同時実行制御 (Concurrency Control): 複数のユーザー(トランザクション)が同時にデータベースにアクセスしても、互いの処理が干渉せず、データの一貫性が保たれるように制御します。ロック (共有ロック、排他ロックなど) やMVCC (Multi-Version Concurrency Control) といった技術が使われます。
- リカバリ (Recovery): システム障害(電源断、ソフトウェアのクラッシュなど)が発生した場合でも、コミットされたトランザクションの結果は失われず、中途半端な状態のトランザクションは取り消される(ロールバックされる)ことを保証します。WALなどのログを使って復旧処理を行います。
- ACID特性の保証: トランザクションが持つべきとされる4つの特性(原子性: Atomicity、一貫性: Consistency、独立性: Isolation、永続性: Durability)を保証するための様々な仕組みの総称です。
-
メタデータ管理 (Metadata Management):
- テーブル定義、列のデータ型、インデックス、ビュー、ユーザー権限などの、データベース自身の構造に関する情報(スキーマ情報)を管理します。これらは通常、「データディクショナリ」や「システムカタログ」と呼ばれる特別なテーブルに格納されます。
-
その他:
- アクセス制御/セキュリティ: ユーザー認証や、どのユーザーがどのデータにアクセスできるかといった権限を管理します。
- ネットワークインターフェース: クライアントアプリケーションからの接続を受け付け、SQLを受け取り、結果を返すためのプロトコル(例: MySQLプロトコル, PostgreSQLプロトコル)を実装します。
- ユーティリティ: バックアップ、リストア、統計情報の収集などの管理用ツール。
今回のチャレンジでは、主にストレージエンジンの中核であるB+Treeと、クエリプロセッサのごく一部(簡単なパーサー連携と直接的な実行)に焦点を当てることになりますね。
承知しました。将来的にトランザクション機能を導入することを見据えて、設計段階から考慮に入れます。
具体的には、以下の点を意識して実装を進めます。
-
Write-Ahead Logging (WAL) の導入準備:
- データベースに対する変更操作(
INSERT,DELETEなど)を行う際、直接データ構造(B+Tree)を変更する前に、その変更内容を記録する「ログエントリ」を作成する仕組みを設けます。 - このログエントリには、どのトランザクションによる操作かを示すID、操作の種類、対象データなどの情報を含めます。
- まずはログエントリをメモリ上に保持するか、単純なファイルに追記する形で実装し、将来的に本格的なWALファイル管理やリカバリ処理を追加できるようなインターフェースを意識します。
- データベースに対する変更操作(
-
操作の遅延適用:
- SQLの
INSERTやDELETEが実行された時点ではログエントリを作成するに留め、実際のデータ構造(B+Tree)への反映は、トランザクションがCOMMITされたタイミングで行う、という流れを基本とします。(あるいは、ログ先行書き込み後に即時反映する方式もありますが、まずはCommit時反映を検討します。) -
ROLLBACK時には、そのトランザクションが生成した未反映のログエントリを破棄することで、変更を取り消します。
- SQLの
-
ページ指向の設計:
- B+Treeのノードを、ディスク上の固定長「ページ」に対応付けることを意識した設計にします。各ノード(ページ)に一意なIDを持たせるなど、将来のバッファ管理や永続化をしやすくします。
-
トランザクションコンテキスト:
-
BEGIN,COMMIT,ROLLBACKといったコマンドを受け付けられるようにし、現在のトランザクションの状態(アクティブかどうか、トランザクションIDなど)を管理する簡単な仕組みを設けます。
-
これにより、まずはメモリ上での動作が中心となりますが、将来的に永続化、リカバリ、同時実行制御(ロックやMVCC)といった本格的なトランザクション機能を段階的に追加していくための基礎構造を作ることができます。
完全なACID特性を持つトランザクションシステムの実装は非常に複雑ですが、このアプローチでその第一歩を踏み出せるかと思います。
それでは、この方針で day34_btree_db プロジェクトの作成を開始します。よろしいでしょうか?
承知いたしました。まずは day34_btree_db プロジェクトの仕様を固め、README に記載します。
以下に仕様案を示します。
# Day34 - B+Tree Based Simple DB
## 1. 目的
このプロジェクトの目的は、リレーショナルデータベースマネジメントシステム (RDBMS) のコアコンポーネントであるストレージエンジン、特に **B+Tree** インデックス構造の基本的な実装を通じて、データベース内部のデータ格納とアクセス方法への理解を深めることです。また、SQLパーサーと自作ストレージエンジンを連携させる基本的な流れを体験し、将来的なトランザクション機能の導入を見据えた基礎設計を行うことも目的とします。
## 2. 主要機能
### 2.1 コア機能
- **テーブル作成:**
- 単純な `CREATE TABLE table_name (id INTEGER PRIMARY KEY, column1 TEXT, column2 INTEGER)` 形式のSQLをサポートします。
- 主キーは `id` という名前の INTEGER 型で、自動的にB+Treeのキーとして使用されます。
- テーブル定義(スキーマ情報)はメモリ上に保持します。
- **データ挿入:**
- `INSERT INTO table_name (id, column1, ...) VALUES (?, ?, ...)` 形式のSQLをサポートします。
- 指定された `id` をキー、他のカラムデータをシリアライズしたものをバリューとしてB+Treeに格納します。
- **データ検索 (主キー):**
- `SELECT column1, column2 FROM table_name WHERE id = ?` 形式のSQLをサポートします。
- B+Treeを検索し、該当するキーのバリューをデシリアライズして返します。
- **データ削除 (主キー):**
- `DELETE FROM table_name WHERE id = ?` 形式のSQLをサポートします。
- B+Treeから指定されたキーのエントリを削除します。
### 2.2 発展機能 (時間があれば実装)
- **データ検索 (全件スキャン):**
- `SELECT * FROM table_name` 形式のSQLをサポートします。
- B+Treeのリーフノードをすべて走査して全データを返します。
- **データ検索 (範囲スキャン):**
- `SELECT * FROM table_name WHERE id > ? AND id < ?` (または `>=`/`<=`) 形式のSQLをサポートします。
- B+Treeのリーフノードを範囲指定で走査します。
- **永続化:**
- B+Treeのノードデータを「ページ」としてファイルに保存・読み込みする機能を追加します。
- 起動時にデータファイルを読み込み、`COMMIT` 時または定期的に変更をファイルに書き戻します。
- **トランザクション管理 (基礎):**
- `BEGIN`, `COMMIT`, `ROLLBACK` SQLコマンドを認識します。
- Write-Ahead Logging (WAL) の概念に基づき、変更操作をまずログエントリとして記録する仕組みを導入します (まずはメモリ上または単純なファイル追記)。
- `COMMIT` 時にログに基づいて実際のB+Treeに変更を反映させます。
- `ROLLBACK` 時に関連するログエントリを破棄します。
### 2.3 スコープ外
- 複雑な `WHERE` 句 (複数条件のAND/OR、非主キー列でのフィルタリング)
- `ORDER BY` (主キー以外の列でのソート)
- `JOIN` 操作
- セカンダリインデックス
- 高度な同時実行制御 (ロックの詳細な管理、MVCC)
- 完全なリカバリ機能
- ネットワークインターフェース (クライアント/サーバーモデル)
- データ型チェックの詳細 (TEXT, INTEGER以外のサポート)
## 3. 技術スタック
- **言語:** Go
- **SQLパーサー:** `github.com/xwb1989/sqlparser` または同等のシンプルなGoライブラリ
- **データ構造:** 自作のB+Tree (メモリ上、発展としてファイル永続化)
- 次数 (degree) を設定可能にする。
- ページ分割、削除時のマージ/再配布 (基本的なもの) を実装。
- **データシリアライズ:** Go標準の `encoding/gob` または `encoding/json`
- **インターフェース:** コマンドラインインターフェース (CLI)。標準入力からSQLを受け付け、結果を標準出力に表示する。インタラクティブなシェルは必須ではない。
- **テスト:** Go標準の `testing` パッケージ
## 4. データモデル (B+Tree)
- 各テーブルに対して、独立したB+Treeインスタンスを生成します。
- **キー:** テーブルの主キー (`id` カラムの `INTEGER` 値)。
- **バリュー (ペイロード):** 主キー以外のカラム名と値をマップ (`map[string]interface{}`) にし、それをシリアライズしたバイト列 (`[]byte`)。
- **ノード構造:**
- 内部ノード: キーの配列、子ノードへのポインタ(またはページID)の配列を持つ。
- リーフノード: キーの配列、対応するバリュー(ペイロード)の配列、隣接リーフノードへのポインタを持つ。
- ノードは固定サイズの「ページ」として管理されることを意識した設計(特に永続化を考慮する場合)。
## 5. 将来的な拡張の考慮点
- **Write-Ahead Logging (WAL):** 変更操作はまずログに記録し、`COMMIT` 時にデータページに反映する流れを基本とする。ログエントリにはトランザクションIDを含める。
- **ページ管理:** B+TreeのノードをページIDで管理し、将来的なバッファプール導入の基礎とする。
- **トランザクションコンテキスト:** 現在のトランザクションの状態を管理する構造を用意する。
## 6. 開発手順案
1. **プロジェクト初期化:** `go mod init`, README作成。
2. **B+Treeコア実装 (メモリ):** ノード構造定義、Insert, Search, Delete実装。
3. **テーブル管理:** テーブル名とB+Treeを紐付ける `map` を用意。スキーマ情報も管理。
4. **シリアライズ:** バリューのシリアライズ/デシリアライズ処理実装。
5. **SQLパーサー連携:** パーサー導入、`CREATE`, `INSERT`, `SELECT`, `DELETE` をB+Tree操作に変換。
6. **CLIインターフェース:** 標準入力からSQLを受け取り、実行して結果を表示する `main` 関数作成。
7. **(発展) 範囲/全件スキャン実装**
8. **(発展) 永続化実装**
9. **(発展) トランザクション基礎実装** (ログエントリ生成、`BEGIN`/`COMMIT`/`ROLLBACK` 処理)
10. **テストとドキュメント:** 単体テスト作成、README完成、`knowledge.md` 更新。
この仕様でプロジェクトを開始してもよろしいでしょうか?承認いただければ、ディレクトリ作成と go mod init を行い、この内容で README.md を作成します。
順調に進んでる。
ついでに bree 勉強のために visualizer も並行でつくってもらってる
go のファイル、コード行数が長くなると明確に劣化するな。
これは rules に入れるべきだ
## `edit_file` 効果的な利用ガイドライン
大規模ファイル (> 300-500行目安) や複雑な変更 (複数箇所、広範囲リファクタリング) で `edit_file` が失敗することがあります。以下を試してください:
1. **スコープ限定:** 指示は「関数 `X` を修正」「構造体 `Y` を変更」のように具体的に限定する。
2. **変更量削減:** 複数の変更は、関連性の高い1-2個ずつ複数回の `edit_file` に分割する。
3. **適切なコンテキスト:** 変更箇所の特定に必要な最小限の周辺コード (`// ... existing code ...` の前後) を含める。
4. **(根本対策) ファイル分割:** 可能であれば、ファイルをより小さく機能的に分割する。
Btree を学ぶやつ(完全に別でつくってる)

おー自作のRDBMSが動いた
❯ go run .
Simple B+Tree DB CLI
Enter SQL commands or type 'exit' to quit.
> CREATE TABLE users (id INTEGER PRIMARY KEY, name TEXT, age INTEGER);
Table 'users' created successfully.
Table 'users' created successfully.
> INSERT INTO users (id, name, age) VALUES (1, 'Alice', 30);
INSERT INTO users (id, name, age) VALUES 1 row inserted.
> (2, 'Bob', 25);
INSERT INTO users (id, name) VALUE1 row inserted.
> S (3, 'Charlie');
SELECT name, age FROM users WHER1 row inserted.
> E id = 1;
SELECT * FROM users WHERE id = 2;
SELECTResult:
name: Alice
age: 30
> Result:
id: 2
name: Bob
age: 25
> name FROM users WHERE id = 3;
DELETE FROM users WResult:
name: Charlie
> HERE id = 1;
SELECT * FROM users WHERE id = 1;
INS1 row deleted.
> Error: error searching for id 1 in table 'users': row with id 1 not found in table 'users'
> ERT INTO users (id, name, age) VALUES (1, 'Alice V2', 31);
SELECT * FROM users WHERE id = 1;
DELETE 1 row inserted.
> Result:
id: 1
name: Alice V2
age: 31
> FROM users WHERE id = 99;
Error: error deleting row with id 99 from table 'users': failed to delete row with id 99 from table 'users': key 99 not found in leaf
> exit
Exiting.
永続化が全然うまくいかない・・
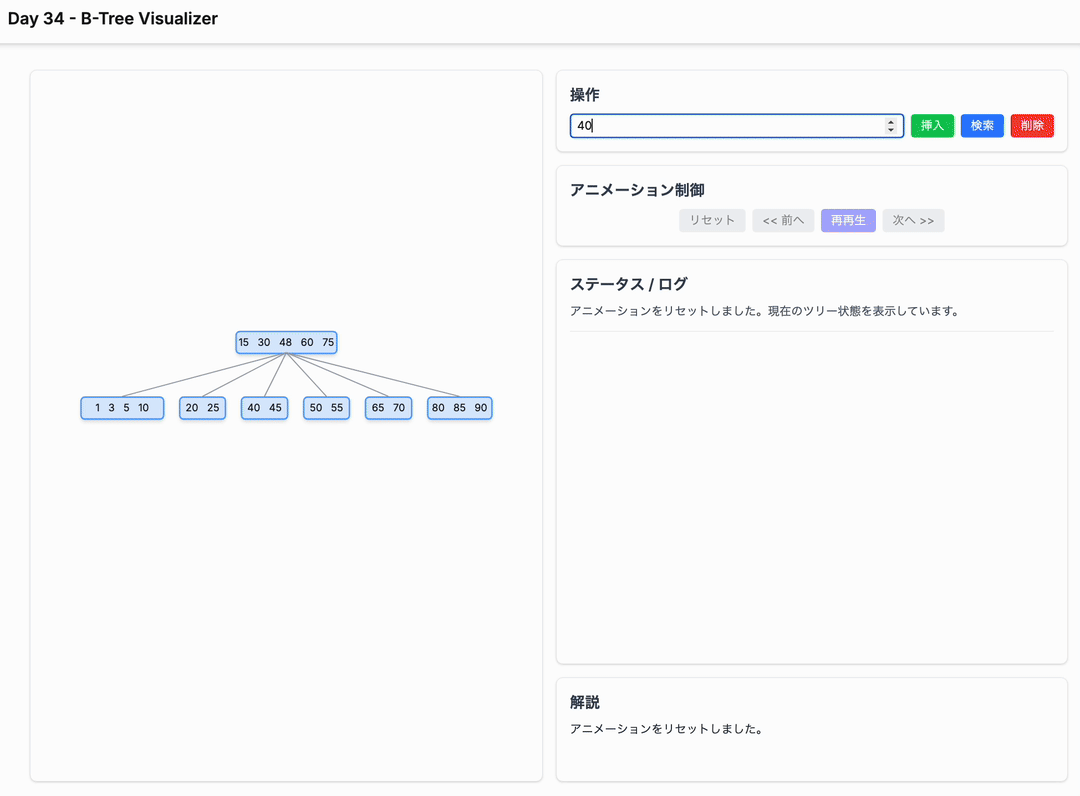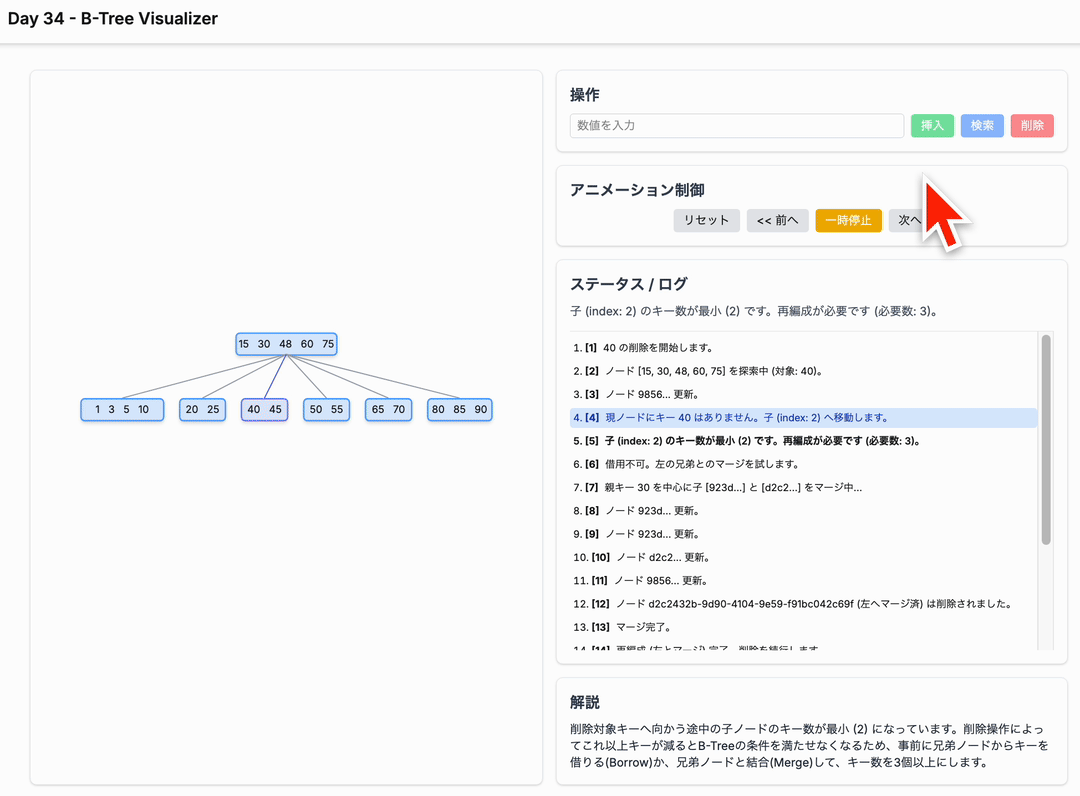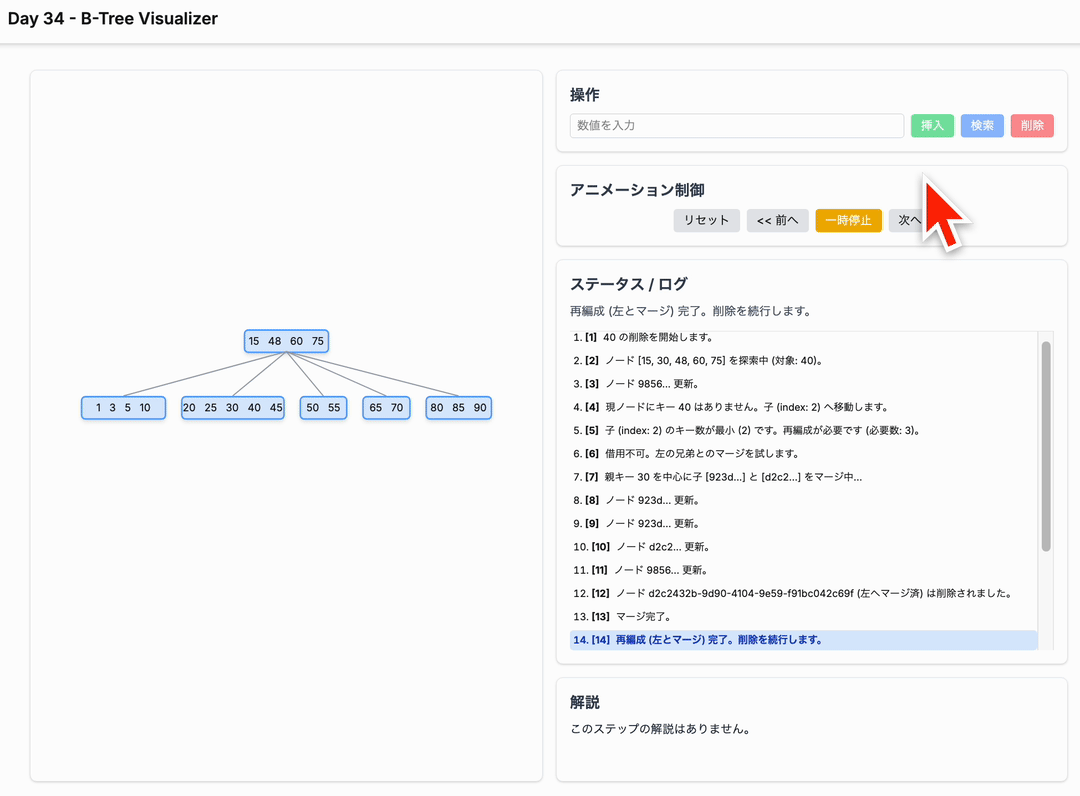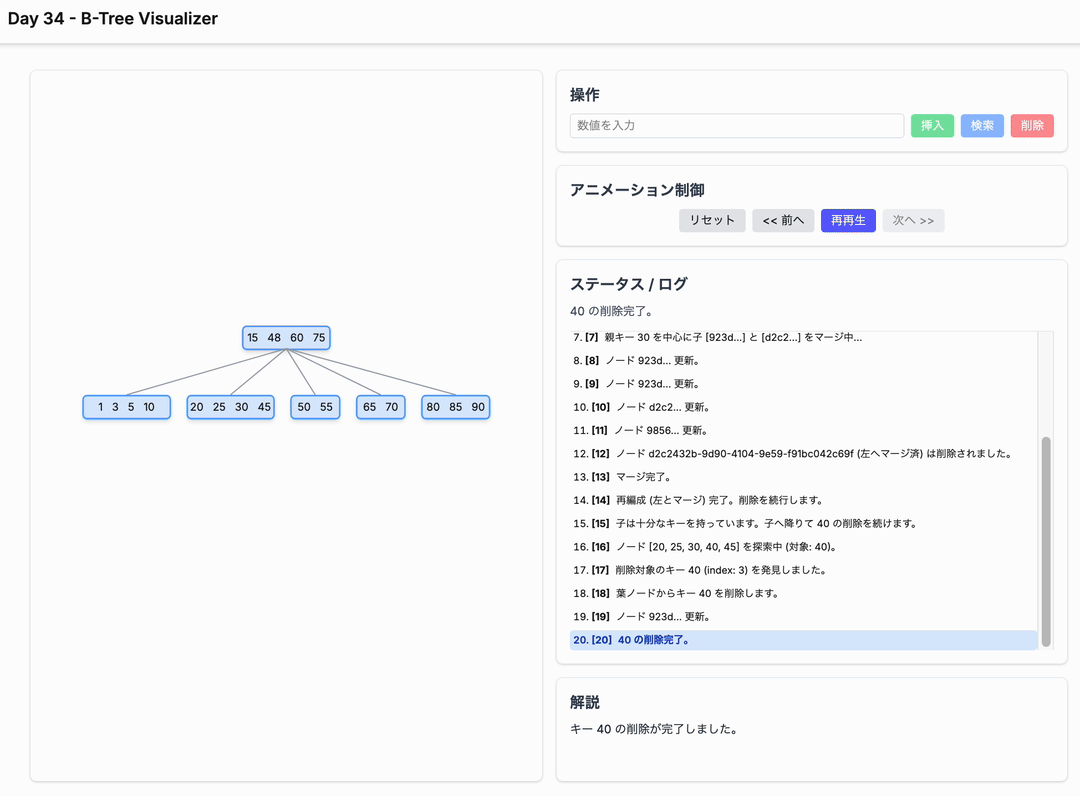
RDBMS 実装 (day34_btree_db) の永続化処理 (Disk Manager と B+Tree の連携) は一通り実装されましたね。お疲れ様です。
アプリケーション作成の流れに沿って、残りの工程を整理します。
完了・進行中の工程:
- 0. プロジェクトの仕様決定: 完了 (B+Tree ベースのシンプルな RDBMS)
- 1. プロジェクト初期化: 完了 (Go プロジェクトとしてセットアップ済み)
-
2. データモデリングとDB設定: 完了 (DiskManager, B+Tree ノード構造定義、テーブルスキーマ管理 (
Database構造体)) - 3. APIエンドポイント実装: (CLI アプリのため不要)
- 4. ユーザー識別機構: (CLI アプリのため不要)
-
6. 主要業務フロー実装: ほぼ完了 (SQL 実行フロー (
executor.go), DB 操作 (db.go)) -
7. デバッグとテスト: 進行中 (基本的なテストは PASS したが、
TestBTreeDeleteの複雑なケースはコメントアウト中)
残っている主要な工程:
-
B+Tree Delete の安定化 (最優先):
- 現在コメントアウトされている
TestBTreeDeleteのテストケース (Leaf_Delete_causes_Borrow,Leaf_Delete_causes_Merge_and_Root_Change) が PASS するように、deleteRecursiveを中心とした再平衡化ロジック (Borrow/Merge) とルートノード処理をデバッグ・修正する必要があります。これは B+Tree のコア機能として非常に重要です。
- 現在コメントアウトされている
-
CLI インターフェースの実装 (
main.go):- ユーザーが対話的に SQL を入力できる REPL (Read-Eval-Print Loop) を作成します。
- ライブラリ
go-promptを利用して、入力補完やヒストリ機能を持つ使いやすいインターフェースを提供します。 - 入力された SQL 文字列を
db.ExecuteSQLに渡し、実行します。 -
ExecuteSQLから返された結果 (文字列) を整形してコンソールに出力します。 -
QUITやEXITといった終了コマンドを実装します。 - 起動時にデータベースファイルへのパスをコマンドライン引数で受け取れるようにします。
-
Disk Manager の改善 (Free List 永続化):
- 現在
DeallocatePageはメモリ上のフリーリストに追加するだけです (// TODO: Implement actual free list persistence.)。これをファイルに永続化し、AllocatePageがまずフリーリストからページを探し、なければ新規に割り当てるように修正します。これにより、削除されたページの領域を再利用できるようになります。
- 現在
-
機能拡張と改善 (オプション/余裕があれば):
-
UPDATE 文の実装:
executor.goにUPDATE文のパーシングと実行ロジック (db.UpdateRowを利用) を追加します。 -
DROP TABLE 文の実装:
executor.goにDROP TABLE文のパーシングと実行ロジック (テーブルスキーマ、ルート情報、関連ページの削除) を追加します。 - エラーハンドリング強化: Executor や DiskManager でのエラーハンドリングをより詳細かつユーザーフレンドリーにします。
- トランザクションサポート: より本格的な RDBMS に近づけるための大きな機能追加です。
-
UPDATE 文の実装:
-
ドキュメント作成:
-
README.mdの更新: アプリケーションの概要、ビルド・実行方法、サポートしている SQL 構文、制限事項などを記載します。 -
.cursor/rules/knowledge.mdcの更新。
-
次のステップとして推奨されること:
まずは最優先課題である 1. B+Tree Delete の安定化 に取り組み、コメントアウトされたテストを修正することをお勧めします。Delete が安定しないと、データベースとしての信頼性が確保できません。
それが完了したら、2. CLI インターフェースの実装 に進むのが良いでしょう。これにより、実際に SQL を対話的に実行できるようになり、達成感が得られます。
どの工程から進めますか?
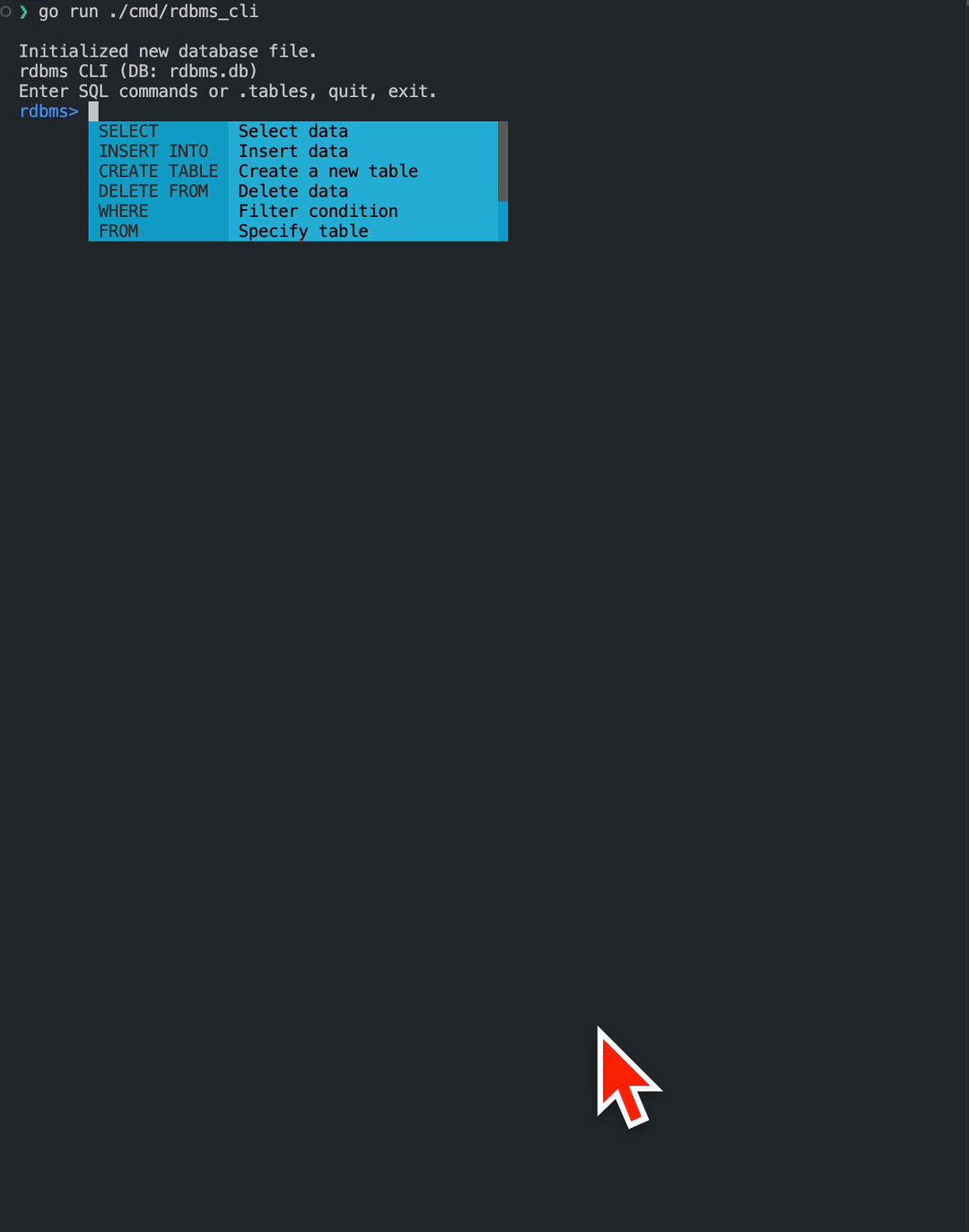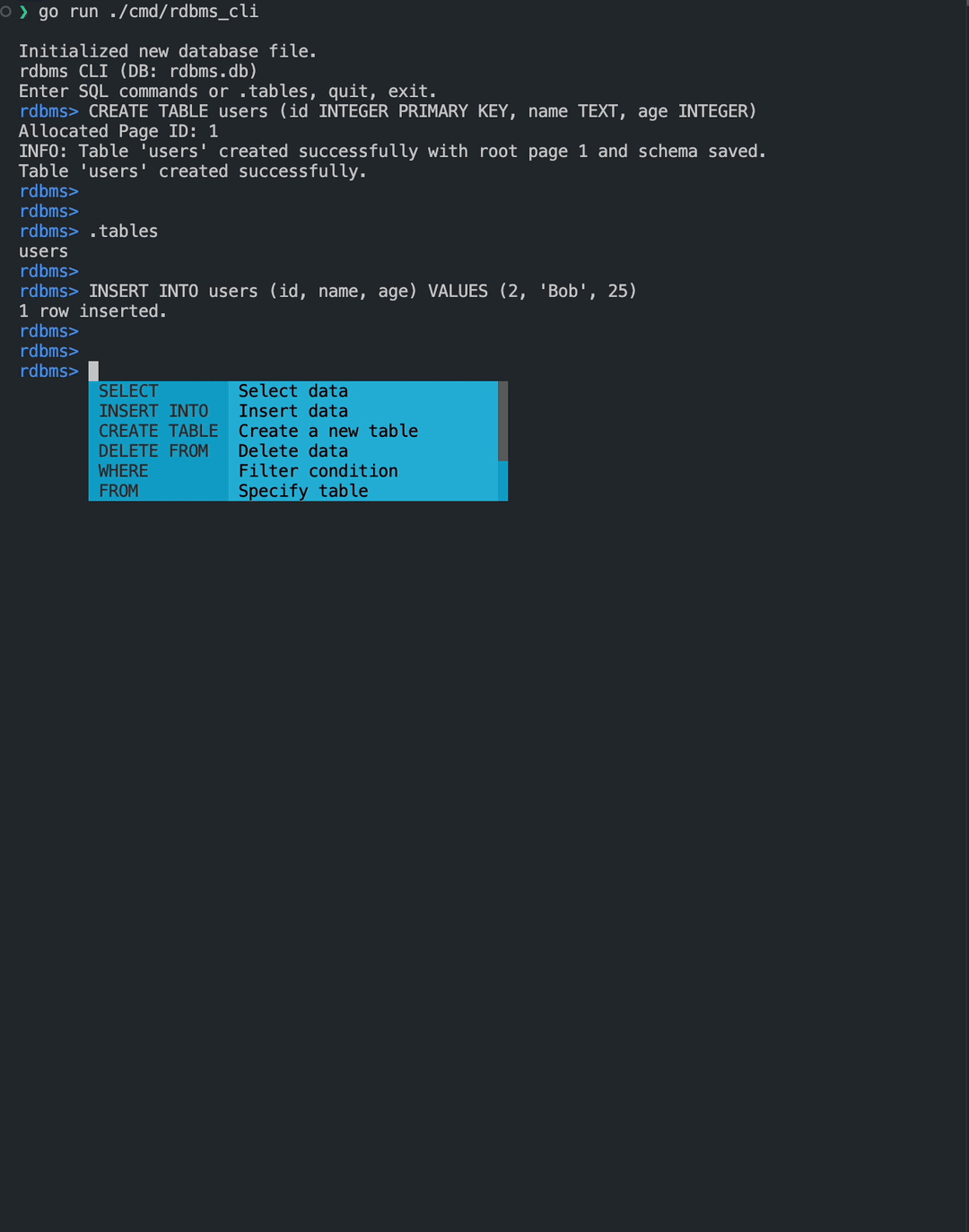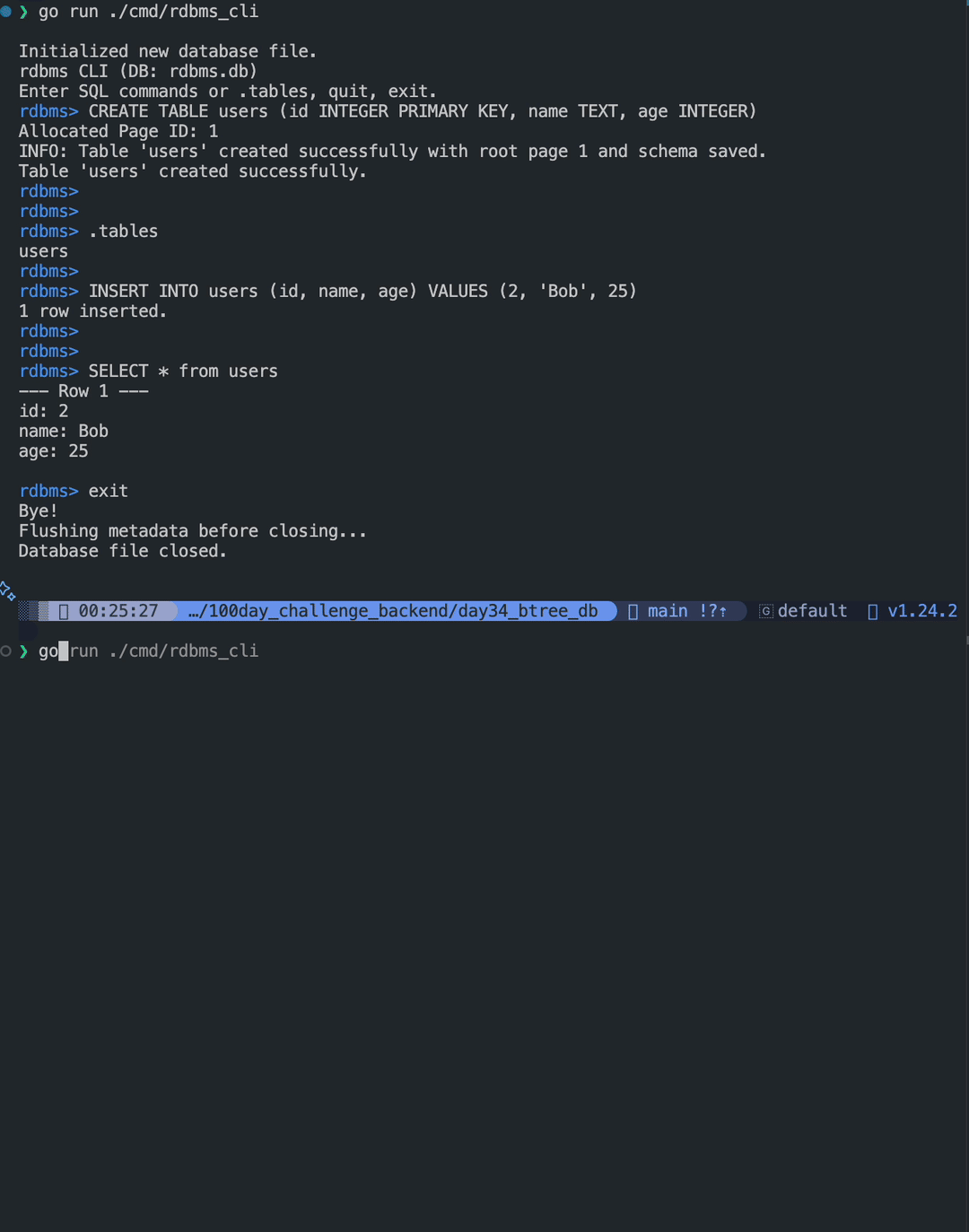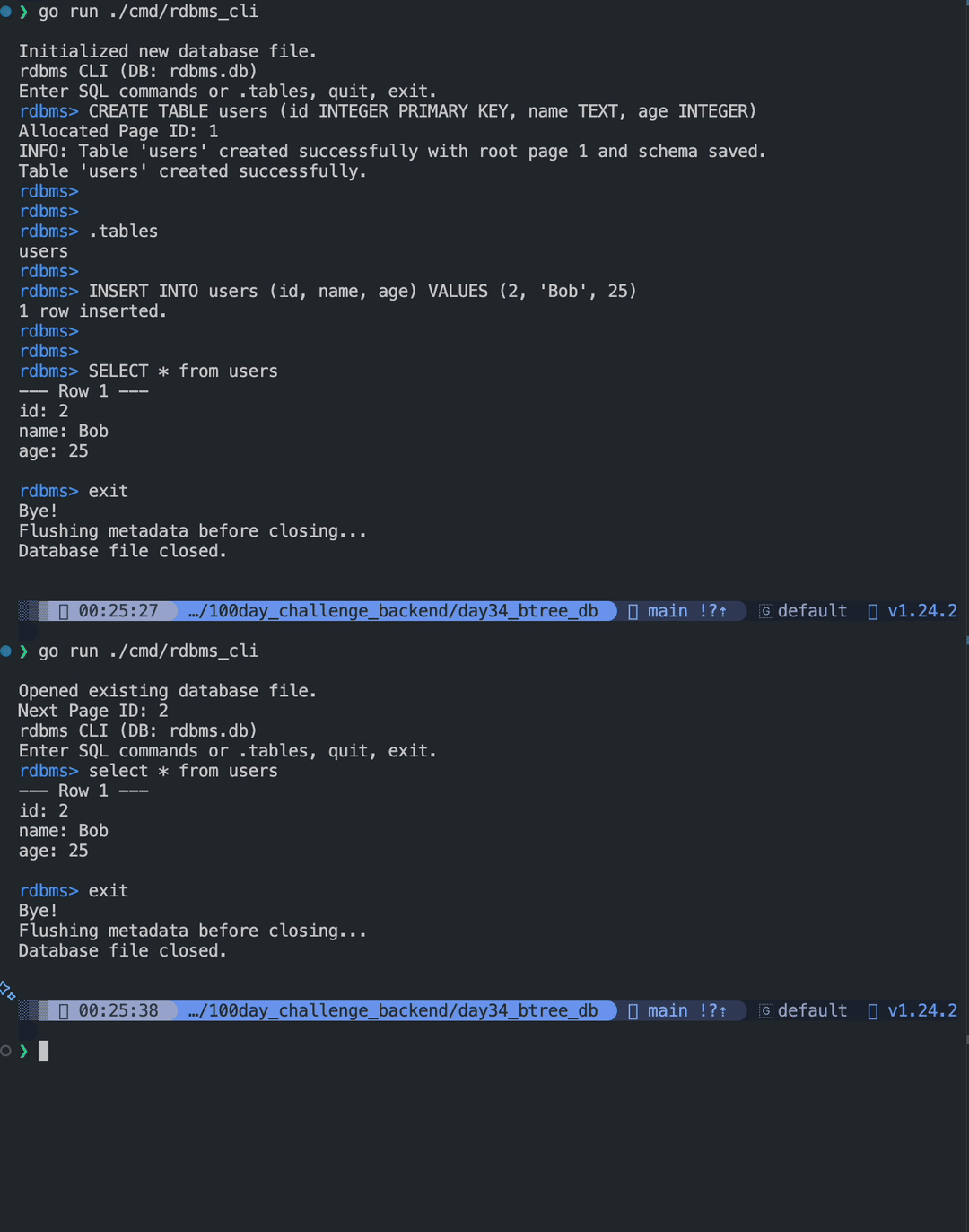
とりあえず CLI 経由でデータ保存できるようになった。。。やっと。。。
これを人力で勉強する人たちがいるとは。。
とりあえず、CLI&永続化できた。。。
❯ /bin/rm rdbms.db ; \
echo "CREATE TABLE test (id INTEGER PRIMARY KEY, value TEXT);" \
| ./rdbms_cli && echo "INSERT INTO test (id, value) VALUES (10, 'hello');" \
| ./rdbms_cli && echo "SELECT id, value FROM test WHERE id = 10;" \
| ./rdbms_cli | cat
Initialized new database file.
Allocated Page ID: 1
INFO: Table 'test' created successfully with root page 1 and schema saved.
Table 'test' created successfully.
Closing database...
Flushing metadata before closing...
Database file closed.
Opened existing database file.
Next Page ID: 2
1 row inserted.
Closing database...
Flushing metadata before closing...
Database file closed.
Opened existing database file.
Next Page ID: 2
--- Row 1 ---
id: 10
value: hello
Closing database...
Flushing metadata before closing...
Database file closed.
つぎはトランザクション
day34 として RDBMS をつくっています。いまから transaction を作りたいです。
作業の流れは以下の通りです。
実装→テスト→テストOKならコミット→次のステップへ の順番で最後まで作り切ってください。
- [ファイル名] : 主な作業対象ファイル
- 目的: そのステップで達成すること
- 作業: 具体的なコーディング内容
- テスト: 対応するテストコードの内容
- コミット: コミットメッセージ例
フェーズ 1: WAL (Write-Ahead Log) 基盤
-
WAL ログレコード定義 ([wal_log.go] 新規作成)
- 目的: WALに書き込むログ情報の構造 (型、定数) とシリアライズ/デシリアライズ方法を定義します。
-
作業:
-
LogType定数 (LogTypeBegin,LogTypeCommit,LogTypeAbort,LogTypeUpdatePage) を定義。 -
LogRecord構造体 (TxID, Type, PageID, Data など) を定義。 -
LogRecordを Gob エンコード/デコードするヘルパー関数 (encodeLogRecord,decodeLogRecord) を実装 (エラー処理含む)。
-
-
テスト ([wal_log_test.go] 新規作成):
- 各種
LogRecordを作成し、エンコード → デコード → 元データと比較するテストケースを実装。
- 各種
-
コミット:
feat: Define WAL log record structure and serialization
-
WAL ファイル I/O 基本操作 ([wal_file.go] 新規作成)
- 目的: WAL ファイルへのバイト列の追記、読み込み、切り捨て、同期など、物理ファイル操作の基本機能を提供します。ログレコードの解釈は行いません。
-
作業:
-
WalFile構造体 (filePath string,file *os.File,mu sync.Mutexなど) を定義。 -
NewWalFile(filePath string): ファイルを追記・作成モードで開く。 -
AppendBytes(data []byte): バイト列をファイル末尾に追記。 -
Sync(): ファイルの内容をディスクに同期 (file.Sync())。 -
ReadAllBytes() ([][]byte, error): ファイル全体を読み込み、レコード単位と思われるバイト列のスライスで返す (単純な固定長 or 区切り文字ベースなど、後のデコード処理を考慮した分割が必要かも。シンプルに一旦全バイト列を返す形でも良い)。 => 修正: レコード境界の判断が難しいため、ReadAllBytes()はファイル全体のバイト列[]byteを返す形にする。デコードは次のステップで行う。 -
Truncate(): ファイルを空にする。 -
Close(): ファイルを閉じる。
-
-
テスト ([wal_file_test.go] 新規作成):
- ファイル作成 → 追記 → 同期 → 読み込み → 内容検証 → 切り捨て → 空確認、の一連のファイル操作をテスト。
-
コミット:
feat: Implement basic WAL file I/O operations
-
WAL マネージャー (ログレコード処理) ([wal_manager.go] 新規作成)
-
目的:
WalFileを使用し、LogRecordのエンコード/デコードと追記、TxID管理を行います。 -
作業:
-
WalManager構造体 (内部にwalFile *WalFile,nextTxID uint64など) を定義。 -
NewWalManager(filePath string): 内部でNewWalFileを呼び出す。nextTxIDを初期化 (最初は 1)。 -
AppendLogRecord(record *LogRecord):-
encodeLogRecordでバイト列に変換。 -
walFile.AppendBytesで追記。 -
walFile.Syncで同期。
-
-
GetNextTxID(): TxID をアトミックにインクリメントして返す。 -
ReadAllLogRecords() ([]*LogRecord, error):-
walFile.ReadAllBytesで全バイト列取得。 - 取得したバイト列を先頭から
decodeLogRecordを使って順次デコードし、LogRecordのスライスを作成して返す (デコードエラー処理含む)。
-
-
TruncateLog(): 内部でwalFile.Truncateを呼び出す。 -
Close(): 内部でwalFile.Closeを呼び出す。
-
-
テスト ([wal_manager_test.go] 新規作成):
-
NewWalManager→AppendLogRecord(複数) →Close。 - 追記後に
ReadAllLogRecordsで正しく読み込めるか検証。 -
TruncateLogの動作確認。 -
GetNextTxIDの動作確認。
-
-
コミット:
feat: Implement WAL manager for log record handling
-
目的:
フェーズ 2: トランザクション状態とロギングの統合
-
トランザクション状態管理 (
Database拡張) ([db.go] 変更, [transaction.go] 新規作成)-
目的:
DatabaseでWalManagerを管理し、トランザクションの状態 (inTransaction,currentTxID) と基本操作 (Begin,Commit,Rollback) を提供します。 -
作業:
-
db.go:Database構造体にwal *WalManager,currentTxID uint64,inTransaction boolを追加。NewDatabaseでWalManager初期化、状態変数初期化。Closeでwal.Close()呼び出し。 -
transaction.go(新規):Databaseのメソッドとして以下を実装:-
BeginTransaction(): 状態チェック、wal.GetNextTxID(),wal.AppendLogRecord(BEGINログ), 状態更新。 -
CommitTransaction(): 状態チェック、wal.AppendLogRecord(COMMITログ), 状態リセット。 -
RollbackTransaction(): 状態チェック、(任意: ABORTログ記録)、状態リセット。 -
IsInTransaction(),GetCurrentTxID()。
-
-
-
テスト ([transaction_test.go] 新規作成):
-
NewDatabase→Begin→ 状態確認 →Commit→ 状態確認、の流れをテスト。Rollbackも同様。 - 不正な状態遷移 (二重Begin、Tx外Commitなど) がエラーになることをテスト。
- 各操作で期待されるログ (BEGIN, COMMIT) が WAL に記録されることを確認。
-
-
コミット:
feat: Add transaction state management and basic operations
-
目的:
-
ページ書き込み箇所への TxID/WAL 引数渡し (インターフェース変更) ([disk_.go], [btree_.go], [operations.go] etc.)
-
目的: データページやメタデータページを書き込む可能性のある関数に、現在のトランザクション情報 (
txID,*WalManager) を渡せるようにシグネチャを変更します。この時点ではまだWALへの記録は実装しません。 -
作業:
- 影響範囲調査:
dm.WriteNode,dm.WritePage,dm.writeMetadataInternal(およびその呼び出し元) を呼び出している箇所を特定 (grep などで)。主に B+Tree 操作 (Insert,Delete,splitNode,mergeChildrenなど) やCreateTable,Closeなどが対象。 -
段階的変更:
-
disk_node_io.goのWriteNode→WriteNode(node Node, wal *WalManager, txID uint64)に変更。 -
disk_metadata.goのwriteMetadataInternal→writeMetadataInternal(wal *WalManager, txID uint64)に変更。(writeMetadataも同様) - 上記関数の呼び出し箇所を特定し、呼び出し元にも
wal,txIDを引数として追加していく。Databaseから最上位の操作 (e.g.,InsertRow) に渡し、そこからBTree.Insert-> ... ->dm.WriteNodeへとバケツリレー的に渡していく。トランザクション外の操作はtxID = 0を渡す。
-
- 影響範囲調査:
- テスト: コンパイルが通るように修正し、既存のテストが全て PASS することを確認 (動作は変わらないはず)。
-
コミット:
refactor: Propagate WalManager and TxID args to page writing functions(このコミットは複数のファイル変更を含む可能性があります)
-
目的: データページやメタデータページを書き込む可能性のある関数に、現在のトランザクション情報 (
-
WAL への変更ログ記録実装 ([disk_node_io.go], [disk_metadata.go])
- 目的: 実際にページ書き込み前に、トランザクション中の変更を WAL に記録します。
-
作業:
-
disk_node_io.goのWriteNode内:dm.WritePageの 前 にif txID > 0 { wal.AppendLogRecord(UPDATE_PAGEログ) }を追加。 -
disk_metadata.goのwriteMetadataInternal内:dm.dbFile.WriteAtの 前 にif txID > 0 { wal.AppendLogRecord(UPDATE_PAGEログ) }を追加。
-
-
テスト ([wal_integration_test.go] 新規作成 or 拡張):
-
Begin→ データ変更操作 (INSERT等) →Commit。 - WAL を読み、BEGIN, UPDATE_PAGE (正しいTxID, PageID, Data), COMMIT ログが記録されていることを検証。
- Tx外での操作では UPDATE_PAGE ログが記録されないことを確認。
-
-
コミット:
feat: Log page modifications to WAL before writing pages
フェーズ 3: SQL コマンドとリカバリ (Redo)
-
SQL コマンド (
BEGIN,COMMIT,ROLLBACK) 実装 ([executor.go])- 目的: SQL レベルでトランザクションを操作できるようにします。
-
作業:
-
executor.goのExecuteSQLでBEGIN,COMMIT,ROLLBACKを解釈し、対応するDatabaseメソッドを呼び出す。 -
executeInsert,executeDeleteなどデータ変更を行う SQL のハンドラ冒頭でif !db.IsInTransaction() { return error }を追加 (当面は明示的なトランザクションが必須とする)。
-
-
テスト ([executor_test.go] 拡張):
-
BEGIN,COMMIT,ROLLBACKSQL の動作確認。 - Tx外での DML がエラーになることの確認。
-
BEGIN-> DML ->COMMITの成功フロー確認。
-
-
コミット:
feat: Execute BEGIN, COMMIT, ROLLBACK SQL commands
-
リカバリ用ページ書き込み関数 ([disk_manager.go])
- 目的: リカバリ処理中に、WAL ログを記録せずにデータページを直接書き込むための関数を用意します。
-
作業:
-
disk_manager.goにwritePageRecovery(pageID PageID, data []byte) errorを実装。中身はdm.dbFile.WriteAtを呼び出すだけ (既存のWritePageから WAL ロギングを除いたもの、または直接WriteAtを使う)。
-
- テスト: (単体テストは難しい場合がある。次のリカバリテストで間接的に検証)
-
コミット:
feat: Add recovery-specific page writing function to DiskManager
-
リカバリロジック実装 (Redo) ([recovery.go] 新規作成)
- 目的: データベース起動時に WAL を読み込み、コミット済みトランザクションの変更を再適用 (Redo) します。
-
作業:
-
recovery.goにrecoverDatabase(dm *DiskManager, wal *WalManager) errorを実装。 -
wal.ReadAllLogRecordsでログ取得。 - コミット済み TxID セットを特定。
- ログを順に見て、コミット済み TxID の UPDATE_PAGE ログがあれば、
dm.writePageRecoveryを使ってデータページを復元。 - 完了後
wal.TruncateLog。
-
-
テスト ([recovery_test.go] 新規作成):
- クラッシュシミュレーション:
Commit後 Close せずに終了 → 再起動 → データ復旧確認。 - 未コミット Tx の変更は反映されないことを確認。
- クラッシュシミュレーション:
-
コミット:
feat: Implement WAL-based recovery logic (Redo phase)
-
起動時リカバリ呼び出し ([db.go] 変更)
-
目的:
NewDatabaseでリカバリ処理を呼び出します。 -
作業:
NewDatabase内でrecoverDatabase(dm, wal)を呼び出す。 -
テスト:
recovery_test.goを再実行。 -
コミット:
feat: Call recovery process on database startup
-
目的:
-
https://pkg.go.dev/encoding/gob
- Go 標準ライブラリに含まれている バイナリ形式のエンコーディング(シリアライズ)ライブラリ です。Goのデータ構造を、他の Go プログラムと通信するために効率的なバイナリ形式でエンコード・デコードするために使います。
- これをつかって B+tree の node をエンコーディングして .db 形式のファイルに保存している
書き込みに関する質問
今回作っているデータ書き込みに関する質問です。
node を格納する際は、対象のページに相当するファイルの場所に都度書き込んでいるのでしょうか
はい、その通りです。B+Tree の各ノードは「ページ」という単位で管理されており、それぞれのページはディスク上のファイル内の特定の場所に対応しています。
具体的には以下のようになっています。
-
ページIDとファイル: 各ノード(ページ)には一意の
PageIDが割り当てられています。 -
ディスクマネージャー (
DiskManager):disk.go内のDiskManagerが、このPageIDを使ってディスク上のファイル (db_fileで指定されたファイル) の特定のオフセット(場所)への読み書きを管理します。 - 書き込みタイミング: ノードの内容が変更されたとき(例: キーの挿入、削除、ノードの分割、マージなど)に、その変更をディスクに永続化する必要があります。
-
WriteNode関数:DiskManagerのWriteNode関数が、変更されたノードのデータ(シリアライズされた形式)を受け取り、対応するPageIDのファイル上の位置に書き込みます。
つまり、ノードに変更があると、その都度 WriteNode が呼び出され、対応するページのデータがファイル上で上書きされる、という仕組みです。
btree だと削除の場合のそこだけをさくじょするのではなく、他のページをけしたり、統合したりなどの操作もあると思いますが、それらも別個に書き込みしてますよね?
はい、おっしゃる通りです。B+Tree の削除操作では、単にキーを削除するだけでなく、以下のような操作によって複数のノード(ページ)が変更される可能性があり、変更されたすべてのノードについてディスクへの書き込みが行われます。
-
キーの削除:
- まず、削除対象のキーが存在するリーフノードが変更され、書き込まれます。
-
アンダーフローと再配布(Borrowing / キー借用):
- キー削除後にノードがアンダーフロー(キー数が最小要件を下回る)した場合、隣の兄弟ノードからキーを借ります。
- この場合、キーを削除したノード、キーを提供した兄弟ノード、そしてそれらの親ノード(区切りキーが変わるため)の 3つのノードが変更され、それぞれディスクに書き込まれます。
-
アンダーフローとマージ(Merging / 統合):
- キーの借用ができない場合、アンダーフローしたノードは隣の兄弟ノードとマージされます。
- この場合、キーを削除したノード、マージ先の兄弟ノード、そしてそれらの親ノード(区切りキーと子ポインタが削除されるため)の 3つのノードが変更され、それぞれディスクに書き込まれます。マージによって空になったノードは、再利用可能なページとして管理されます(通常はフリーリストなど)。
-
親ノードへの伝播:
- 親ノードで区切りキーと子ポインタが削除された結果、親ノード自体もアンダーフローする可能性があります。その場合、親ノードでさらに再配布やマージが発生し、変更がルート方向に伝播していきます。変更が発生したすべての祖先ノードが書き込み対象となります。
現在の実装 (btree_delete.go 内の deleteRecursive, borrowFromSibling, mergeChildren 関数など) では、これらの操作で変更が発生した各ノード (node, sibling, parent) に対して、diskManager.WriteNode() を呼び出して、変更内容を個別にファイルに永続化しています。
なんかファイルを通じたディスクの書き込みのイメージが湧いてないのですが
page が 100byte 単位だったとして、node 1 1~100 / node 2 101~200 ... という感じの時に node3が消えたりすると、node4 以降は全て書き込み直しになる?
いいえ、node4 以降を全て書き込み直す必要はありません。そこがファイルベースのページ管理のポイントです。
イメージとしては、データベースファイルは固定サイズの「ページ」が並んだ棚のようなものです。
-
ページと棚の場所:
- 各ページ(ノード)には一意の
PageIDがあります。 -
PageIDは、ファイル内の固定された場所(オフセット) を指します。 - 例えば、ページサイズが 100 バイトなら、
-
PageID 0は ファイルの 0 バイト目から 99 バイト目 -
PageID 1は ファイルの 100 バイト目から 199 バイト目 -
PageID 2は ファイルの 200 バイト目から 299 バイト目 -
PageID 3は ファイルの 300 バイト目から 399 バイト目 -
PageID 4は ファイルの 400 バイト目から 499 バイト目
... というように、場所が決まっています。
-
- 各ページ(ノード)には一意の
-
ノード(ページ)の削除(マージによる空き):
-
node3(PageID=3 のノード) が削除(例えば、隣のノードとマージされて不要になった)されたとします。 - このとき、ファイル内の 300 バイト目から 399 バイト目の領域は「空き」になります。
- しかし、
node4(PageID=4) の場所(400 バイト目から)や、それ以降のノードの場所は変わりません。ファイル全体を詰めるようなことはしません。
-
-
書き込み:
-
node1に変更があれば、0〜99 バイト目を上書きします。 -
node2に変更があれば、100〜199 バイト目を上書きします。 - もし
node3が削除され、その結果node2とnode4の親ノードであるnodeP(例えば PageID=10) が変更されたら、nodePに対応するファイル上の場所(1000〜1099 バイト目)を上書きします。 -
node4自体が変更されない限り、400〜499 バイト目を書き込む必要はありません。
-
-
空きページの管理:
- 空いたページ(上記の例では PageID=3 の場所)は、通常「フリーリスト」のような仕組みで管理されます。
- 次に新しいノードが必要になったとき、この空き領域 (PageID=3) が再利用される可能性があります。ファイル末尾に新しいページを追加する前に、まず空きを探します。
結論:
ノードが削除されても、他のノードのディスク上の物理的な位置は変わりません。変更があったノード(ページ)だけが、その固定された場所に対応するファイル領域に書き込まれます。そのため、後続のページ全体を書き込み直すといった非効率なことは起こりません。
ファイル内のどのバイト位置にどのノード(ページ)が書き込まれているかは、主に以下の2つの要素によって暗黙的かつ直接的に決定され、管理されています。
-
ページID (
PageID):- 各ノードには一意の
PageID(通常は 0 から始まる整数) が割り当てられます。これがノードの識別子です。
- 各ノードには一意の
-
固定ページサイズ (
pageSize):- データベースファイルは、固定サイズの「ページ」の連続として扱われます。このサイズは、データベース作成時(または
DiskManager初期化時)に決定されます (例: 4096 バイト)。
- データベースファイルは、固定サイズの「ページ」の連続として扱われます。このサイズは、データベース作成時(または
これらの情報があれば、特定の PageID のノードがファイル内のどの位置にあるかは、単純な計算で求められます。
計算式:
オフセット = PageID * pageSize
例:
-
pageSizeが 4096 バイトの場合:-
PageID 0のノード:0 * 4096 = 0バイト目から -
PageID 1のノード:1 * 4096 = 4096バイト目から -
PageID 2のノード:2 * 4096 = 8192バイト目から -
PageID nのノード:n * 4096バイト目から
-
管理の主体:
この計算と、計算されたオフセットに対する実際のファイルの読み書きを担当しているのが、disk.go に実装されている DiskManager です。
-
ReadNode(pageID PageID): 内部でoffset = pageID * dm.pageSizeを計算し、ファイルからそのオフセット位置のデータをpageSize分だけ読み込みます。 -
WriteNode(node Node): ノードのPageIDを使ってoffset = node.GetPageID() * dm.pageSizeを計算し、ノードのデータをシリアライズして、そのオフセット位置に書き込みます。 -
allocateNewPage(): 新しいページが必要になった場合、現在のファイルの末尾を示す位置(これが次の利用可能なPageIDに対応するオフセットになる)を計算し、そのPageIDを返します。ファイルサイズもpageSize分だけ拡張されます(あるいは書き込み時に自動的に拡張されます)。
結論:
特別な対応表のようなデータ構造があるわけではなく、「PageID と固定 pageSize を使えば、どのノードがファイルのどこにあるかは計算によって一意に決まる」というルールに基づいて管理されています。DiskManager がこのルールに従ってファイルアクセスを行っています。
うーん、しかし親ノードがなくなってしまった場合はフリーになるという話がありました。そうなるとそのフリーに全然関係ないページがはいってくることにはならないのでしょうか
おっしゃる通り、フリーになったページ(例: PageID 3 の場所)は、次に新しいページが必要になったときに再利用されます。そして、その再利用時に、以前そこにあったノードとは全く関係のない新しいノードが書き込まれる可能性があります。
それで問題ない理由:
B+Tree(や多くのデータベースのページ管理)の仕組みでは、ページ間の関連性は、ページ内に格納されている**ポインタ(他のページの PageID)**によって定義されています。
具体的には:
-
ノードの自己完結性: 各ノード(ページ)は、それ自体がどのような種類のノード(内部ノードかリーフノードか)であり、どのキーを持っているか、そして(内部ノードなら)どの子ノード(の
PageID)を指しているか、または(リーフノードなら)どの兄弟ノード(のPageID)を指しているか、という情報を持っています。 -
ポインタによるリンク: 親ノードは子ノードの
PageIDを保持し、子ノードは親ノードのPageIDを(実装によっては)保持します。リーフノードは隣のリーフノードのPageIDを保持します。ツリー構造全体は、これらのPageIDによるリンクで成り立っています。 -
マージとポインタ更新:
node3がマージされてフリーになった際、node3を指していた親ノードのポインタは既に削除されているか、マージ先のノードを指すように更新されています。また、node3の兄弟ポインタも適切に更新されています。つまり、マージが完了した時点で、他のどのノードも「もはや存在しないnode3」を指してはいません。 -
フリーページの再利用: その後、全く新しいノード
nodeNewが必要になり、フリーになっていたPageID 3の場所が割り当てられたとします。-
nodeNewのデータ(新しいキー、新しいポインタ、新しいノードタイプ情報など)がPageID 3の場所に書き込まれます。 -
nodeNewを子として持つことになる親ノードには、nodeNewのPageID(つまり 3) が新しいポインタとして記録されます。
-
-
混線の回避:
nodeNewがたまたま以前node3があった物理的な場所を使ったとしても、nodeNewの内容と、nodeNewを指す新しいポインタによって、B+Tree の論理構造は正しく維持されます。以前のnode3の情報や関連性が混ざることはありません。ディスク上の「住所」が再利用されただけ、と考えることができます。
結論:
フリーになったページに全く関係ない新しいノードが書き込まれても問題ありません。なぜなら、B+Tree の構造は物理的な連続性ではなく、各ノード内に記録された他のノードへの論理的なポインタ (PageID) によって維持されているためです。フリーになったページの場所は、単なる再利用可能な空きスペースとして扱われます。
ページサイズを超えるデータの話
次の質問です標準的なページサイズ以上のデータを格納する場合、どうするのですか?(バイナリなど
良い質問ですね。標準的なページサイズ(例えば 4KB や 8KB)を超えるような大きなデータ、特に画像や動画のようなバイナリデータ (BLOB: Binary Large Object) や非常に長いテキスト (CLOB: Character Large Object) を格納する必要がある場合、データベースシステムは通常、特別な方法でこれらを扱います。
一般的なアプローチは以下の通りです。
-
オーバーフローページ (Overflow Pages) / LOB ストレージ:
- 基本方針: B+Tree のノード(特にリーフノード)には、大きなデータそのものではなく、そのデータの実体へのポインタ(または識別子)だけを格納します。
- データの格納場所: 実際の大きなデータは、B+Tree のページとは別に確保された専用の「オーバーフローページ」または「LOB (Large Object) セグメント」と呼ばれる領域に格納されます。
-
ポインタ: B+Tree のリーフノード内の該当レコードには、キーや他の比較的小さなカラムの値と一緒に、このオーバーフローページ(または LOB データブロックの最初のページ)の
PageIDや LOB 識別子が格納されます。 - 複数ページへの分割: データが1つのオーバーフローページにも収まらないほど大きい場合は、複数のオーバーフローページに分割して格納されます。各オーバーフローページは、次のオーバーフローページへのポインタを持つ形(連結リストや B-Tree のような構造)で管理されることが多いです。
-
メリット:
- B+Tree の効率維持: B+Tree のノードサイズを比較的小さく保つことができます。これにより、木の高さが低く抑えられ、キー検索などの B+Tree 操作の効率が維持されます。
- アクセス効率: 大きなデータを必要としないクエリ(例: キーだけをスキャンする場合や、小さなカラムだけを取得する場合)では、オーバーフローページを読む必要がないため、ディスク I/O を節約できます。
-
デメリット:
- 追加 I/O: 大きなデータにアクセスする必要がある場合は、B+Tree のページに加えて、オーバーフローページを読むための追加のディスク I/O が発生します。
今回の day34_btree_db プロジェクトにおける状況:
現在のシンプルな実装では、このようなオーバーフローページの仕組みは実装されていません。
-
db.goのInsertRow関数は、与えられたRowデータ(map[string]any)をgobでエンコードし、それをペイロードとしてbtree.Insertを呼び出します。 -
btree.goのnode.AddKeyは、キーとこのエンコードされたペイロード(value)をノード内に格納しようとします。 -
disk.goのDiskManager.WriteNodeは、シリアライズされたノードデータをディスクに書き込みます。
この一連の流れの中で、エンコードされた Row データ(ペイロード)が非常に大きく、シリアライズされたノード全体のサイズが pageSize を超えてしまう場合、現在の実装ではおそらくエラーになるか、予期しない動作を引き起こす可能性があります(具体的には DiskManager.WriteNode で書き込みサイズが pageSize を超えるケースなど)。
結論:
標準的なデータベースシステムでは、ページサイズを超えるデータはオーバーフローページなどの仕組みを使って B+Tree の外で管理しますが、今回の day34_btree_db ではその機能はなく、すべてのデータ(キーと値)が1つのページ内に収まることが前提となっています。大きなバイナリデータなどを扱いたい場合は、オーバーフローページ管理の機能を追加で実装する必要があります。
はい、その理解で概ね正しいです! より正確に言うと、多くの RDBMS では以下のようにデータを管理しています。
- インデックス (B+Tree): テーブルの主キーやインデックスが付けられたカラムの値は、効率的な検索のために B+Tree 構造で管理されます。
-
テーブルデータ(ヒープやクラスタ化インデックス):
-
行データ本体: テーブルの実際の行データ(すべてのカラムの値を含む)は、B+Tree とは別の領域に格納されることが多いです。
- ヒープ構成: 行データが特定の順序なしに格納される方式。B+Tree インデックス(非クラスタ化インデックス)には、キーの値と、実際の行データへのポインタ(行IDや物理的なアドレス)が格納されます。
- クラスタ化インデックス構成: テーブルデータ自体が主キー(または指定されたキー)の順序に従って B+Tree のリーフページに直接格納される方式。この場合、リーフページにすべてのカラムデータが含まれます。非クラスタ化インデックスは、クラスタ化キーの値をポインタとして持ちます。
-
行データ本体: テーブルの実際の行データ(すべてのカラムの値を含む)は、B+Tree とは別の領域に格納されることが多いです。
-
大きなオブジェクト (LOB) データ:
- ご指摘の通り、画像、動画、長いテキストなどの BLOB/CLOB データはサイズが大きいため、B+Tree のページや通常の行データ領域に直接格納すると効率が悪くなります。
- そのため、これらの LOB データは専用のLOB ストレージ領域(オーバーフローページや専用セグメント)に格納され、B+Tree のインデックスやテーブルの行データ領域には、その LOB データへのポインタ(LOB ロケータや識別子)だけが格納されます。
まとめ:
- 検索効率のため: インデックス(キーや検索用カラム)は B+Tree で管理されます。
-
データの実体:
- 比較的小さなカラムデータは、テーブルデータ領域(ヒープ or クラスタ化インデックスのリーフ)に格納されます。
- 非常に大きな LOB データは、専用の LOB ストレージに格納され、テーブルやインデックスにはその場所を示すポインタが格納されます。
したがって、「B+Tree がすべてのデータを直接管理している」わけではなく、「効率的な検索に必要なキーやポインタを管理し、データの実体(特に大きなもの)は別の場所に配置して、必要に応じてポインタ経由でアクセスする」というのが、多くの RDBMS における実態に近いと言えます。
はい、その理解で正しいです! セカンダリインデックスを作成すると、そのインデックス対象のカラムの値をキーとする新しい B+Tree が別途作成されます。
具体的には、その新しい B+Tree には以下の情報が格納されます。
-
キー (Key): セカンダリインデックスの対象となったカラムの値(例:
emailアドレス、作成日など)。 -
値 (Value): そのキーの値を持つ実際の行データへのポインタ。このポインタが具体的に何かは、テーブルの構成によります。
- テーブルがヒープ構成(特定の順序なし)の場合: ポインタは通常、行の物理的な位置を示す「行ID (RowID)」や内部的な識別子になります。
- テーブルがクラスタ化インデックス構成(主キー順)の場合: ポインタは通常、その行の「主キー (Primary Key)」の値になります。セカンダリインデックスで検索した後、得られた主キーを使って、さらに主キーの B+Tree (テーブルデータ本体) を検索して完全な行データを取得します。
重要な点:
- セカンダリインデックスは、主キーのインデックス(もしあれば)やテーブルデータ本体とは独立したデータ構造(別の B+Tree)として存在します。
- 元のテーブルデータに行が追加・更新・削除されると、主キーのインデックスだけでなく、関連するすべてのセカンダリインデックスも更新する必要があります。これが、インデックスが多いと書き込み性能が低下する理由の一つです。
したがって、「セカンダリインデックスを付与すると、そのカラムの情報(とその行へのポインタ)を持つ新しい B+Tree が追加される」というのが正確な理解になります。
はい、まさしくその通りです!
- テーブルデータ(主キーインデックス or クラスタ化インデックス): テーブルの本体データ、または主キーによって整理されたデータ(クラスタ化インデックスの場合)を格納・管理するための B+Tree が一つ存在します。(ヒープ構成の場合は B+Tree ではなく行データの集合ですが、主キーインデックス用の B+Tree はあります)。
- セカンダリインデックス: 各セカンダリインデックスごとに、そのインデックス対象カラムの値をキーとし、行データへのポインタ(主キー or 行ID)を値とする独立した B+Tree がそれぞれ作成されます。
例えば、users テーブルに id (主キー) と email (セカンダリインデックス) がある場合:
-
idをキーとする B+Tree (これがテーブルデータ本体の場合も) -
emailをキーとする B+Tree
という、最低でも2つの B+Tree が存在することになります。username にもインデックスを追加すれば、3つ目の B+Tree が作られます。
このように、インデックスごとに別々の B+Tree を持つことで、それぞれのカラムでの効率的な検索が可能になるわけです。
承知しました。WALとトランザクションの実装について、どこまで進んでいるか確認します。
まず、現在のプロジェクトのファイル構成を確認します。
Ran tool
day34_bptree_rdbms ディレクトリが見つからないようです。もしかしてディレクトリ名が異なる、あるいはまだ作成されていない可能性があります。
現在のワークスペースのルートディレクトリにあるディレクトリを確認します。
Ran tool
ありがとうございます。day34_btree_db というディレクトリが見つかりました。こちらで作業を進めます。
まず、day34_btree_db ディレクトリ内のファイル構成を確認します。
Ran tool
ファイル構成を確認しました。WAL関連のファイル (wal_log.go, wal_file.go, wal_manager.go, transaction.go) と、それらのテストファイルが存在しますね。
次に、各ステップの実装状況を詳しく見ていきます。
フェーズ 1: WAL 基盤 (ステップ 1〜3)
-
wal_log.go,wal_file.go,wal_manager.goが存在することから、フェーズ1の基本的な実装は完了していると考えられます。
フェーズ 2: トランザクション状態とロギングの統合 (ステップ 4〜6)
- ステップ4:
db.goとtransaction.goを確認します。
Read file: day34_btree_db/transaction.go
transaction.go を確認しました。BeginTransaction, CommitTransaction, RollbackTransaction, IsInTransaction, GetCurrentTxID が実装されており、BEGIN/COMMIT ログの記録も行われています。ステップ4は完了しているようです。
Read file: day34_btree_db/db.go
db.go を確認しました。
-
Database構造体にwal,currentTxID,inTransaction,txMuが追加されています。 -
NewDatabaseでWalManagerの初期化が行われています。 -
Closeでwal.Close()が呼び出されています。 -
ステップ10のリカバリ呼び出しはまだ
// TODO:コメントになっています。 -
ステップ5: ページ書き込み箇所への引数渡し。これは多くのファイルに影響するため、代表的な
disk_node_io.goとdisk_metadata.goを確認します。
Read file: day34_btree_db/disk_node_io.go
disk_node_io.go の WriteNode のシグネチャが WriteNode(node Node) のままです。wal と txID を受け取るように変更されていません。
したがって、ステップ5(引数渡し)とステップ6(WAL記録実装)は未完了です。
Read file: day34_btree_db/disk_metadata.go
disk_metadata.go の writeMetadataInternal も同様に、wal と txID を受け取るように変更されていません。
こちらもステップ5(引数渡し)とステップ6(WAL記録実装)は未完了です。
フェーズ 3: SQL コマンドとリカバリ (Redo) (ステップ 7〜10)
- ステップ7:
executor.goを確認します。
Read file: day34_btree_db/executor.go
executor.go を確認しました。
-
ExecuteSQLのswitch文にはBEGIN,COMMIT,ROLLBACKの case がありません。 -
executeInsertやexecuteDelete(ファイル末尾付近にあるはず) にトランザクションチェック (if !db.IsInTransaction()) が見当たりません。
ステップ7 (SQLコマンド実装) は未完了です。
- ステップ8:
disk_manager.goを確認します。
Read file: day34_btree_db/disk_manager.go
disk_manager.go を確認しました。リカバリ用の writePageRecovery 関数が見当たりません。ステップ8は未完了です。
- ステップ9:
recovery.goを確認します。そもそもこのファイルが存在するかどうか。
Ran tool
recovery.go ファイルは存在しません。ステップ9 (リカバリロジック実装) は未完了です。
- ステップ10:
db.goのNewDatabase内でのリカバリ呼び出しは、ステップ4の確認で// TODO:になっていることを確認済みです。ステップ10も未完了です。
現在の進捗状況まとめ:
-
フェーズ 1 (ステップ 1-3): 完了
- WALのログレコード定義、ファイルI/O、マネージャーの基本機能は実装済み。
-
フェーズ 2 (ステップ 4-6): 途中
- ステップ 4 (トランザクション状態管理): 完了。
Database構造体とtransaction.goは実装済み。 - ステップ 5 (ページ書き込み関数への引数渡し): 未完了。
WriteNodeやwriteMetadataInternalなどのシグネチャが変更されていない。 - ステップ 6 (WALへの変更ログ記録): 未完了。ステップ5が未完了のため、実装されていない。
- ステップ 4 (トランザクション状態管理): 完了。
-
フェーズ 3 (ステップ 7-10): 未着手
- ステップ 7 (SQLコマンド実装): 未完了。
executor.goが未対応。 - ステップ 8 (リカバリ用ページ書き込み関数): 未完了。
disk_manager.goに未実装。 - ステップ 9 (リカバリロジック実装): 未完了。
recovery.goが存在しない。 - ステップ 10 (起動時リカバリ呼び出し): 未完了。
db.goのNewDatabaseで呼び出されていない。
- ステップ 7 (SQLコマンド実装): 未完了。
次のアクション:
まずは ステップ5: ページ書き込み箇所への TxID/WAL 引数渡し から再開する必要があります。影響範囲が広いため、慎重に進めましょう。
具体的には、disk_node_io.go の WriteNode, disk_metadata.go の writeMetadataInternal (と writeMetadata) のシグネチャを変更し、それらの呼び出し元(B+Tree の操作関数など)にも wal *WalManager, txID uint64 を引数として追加していく作業になります。
この作業から開始しますか?
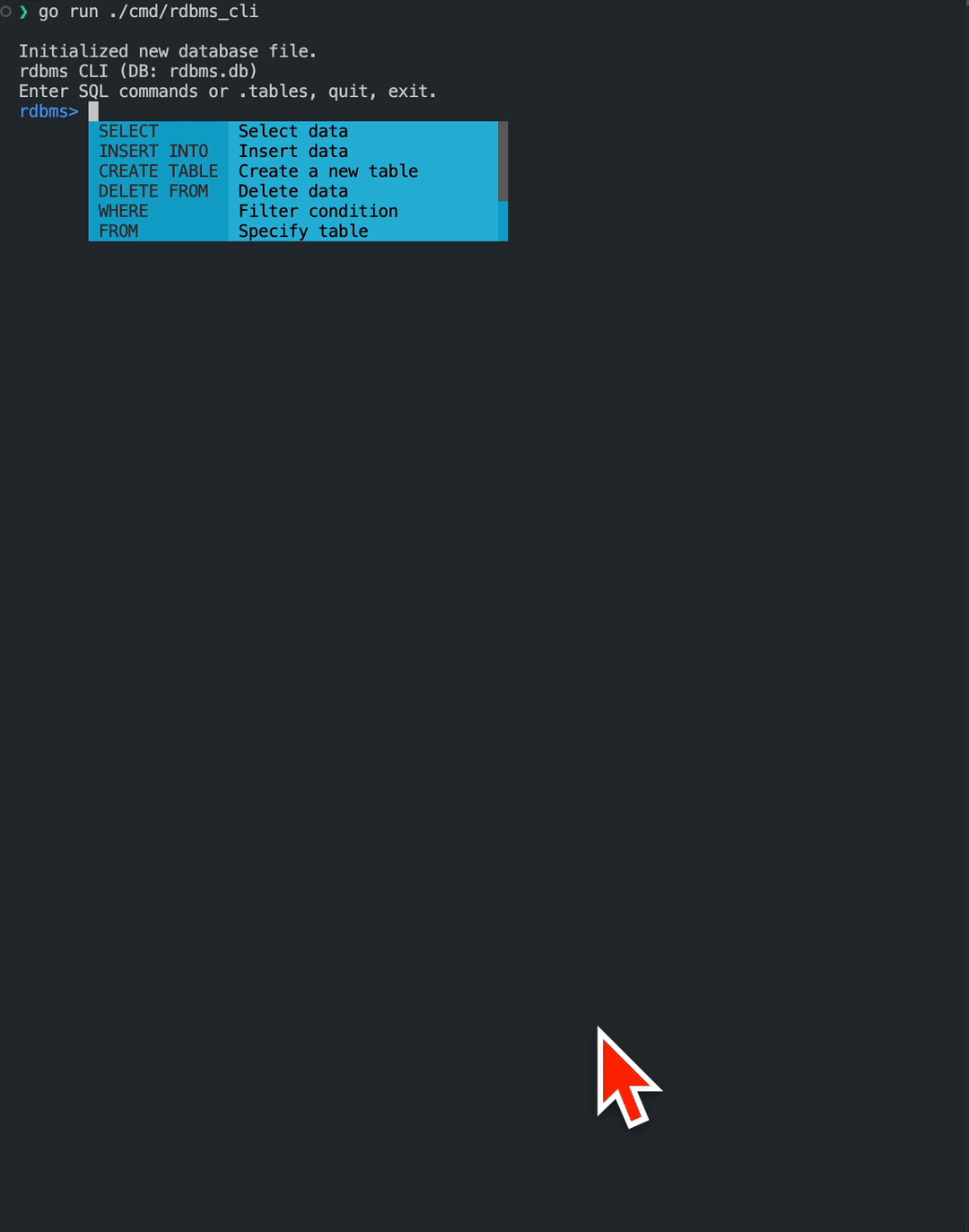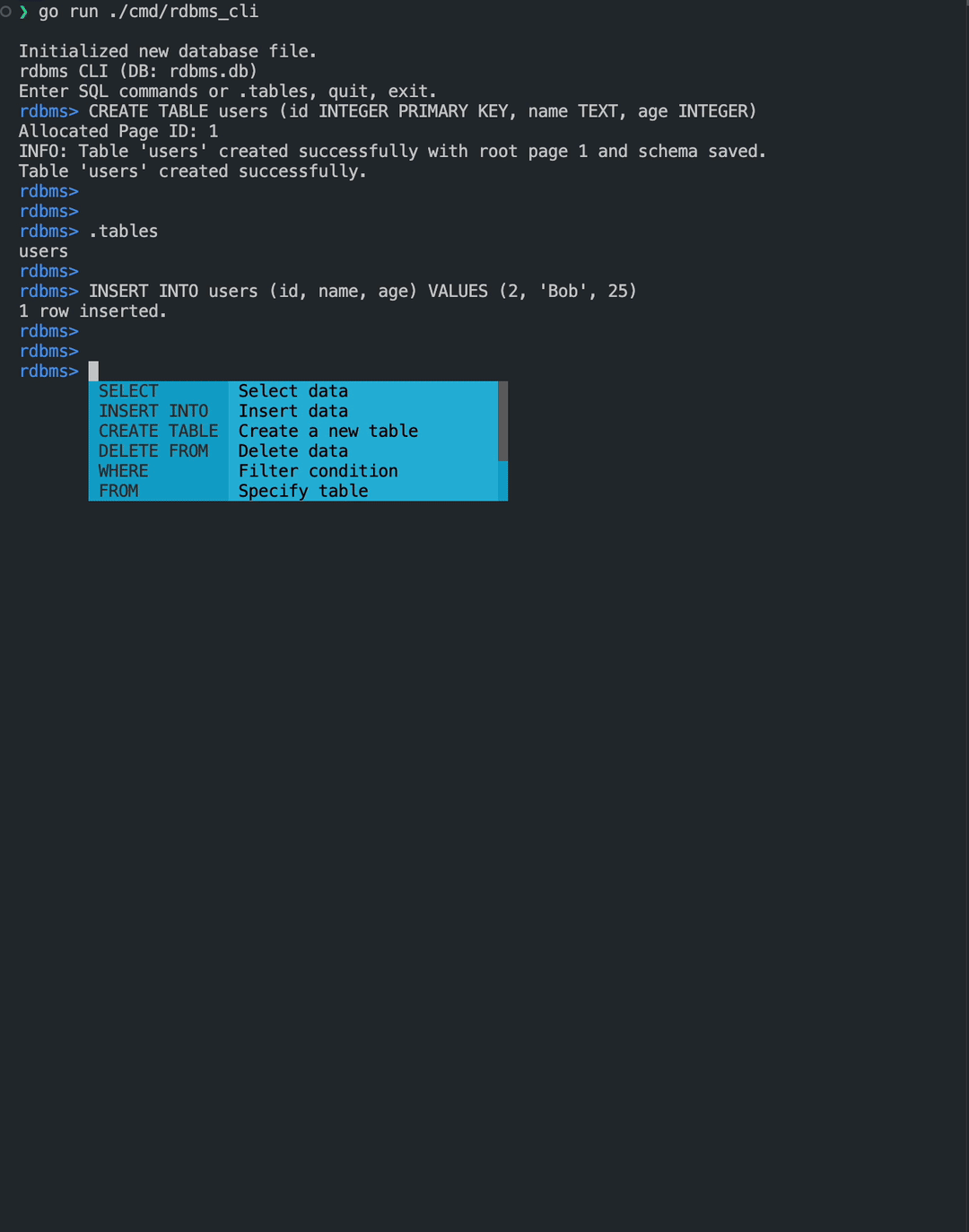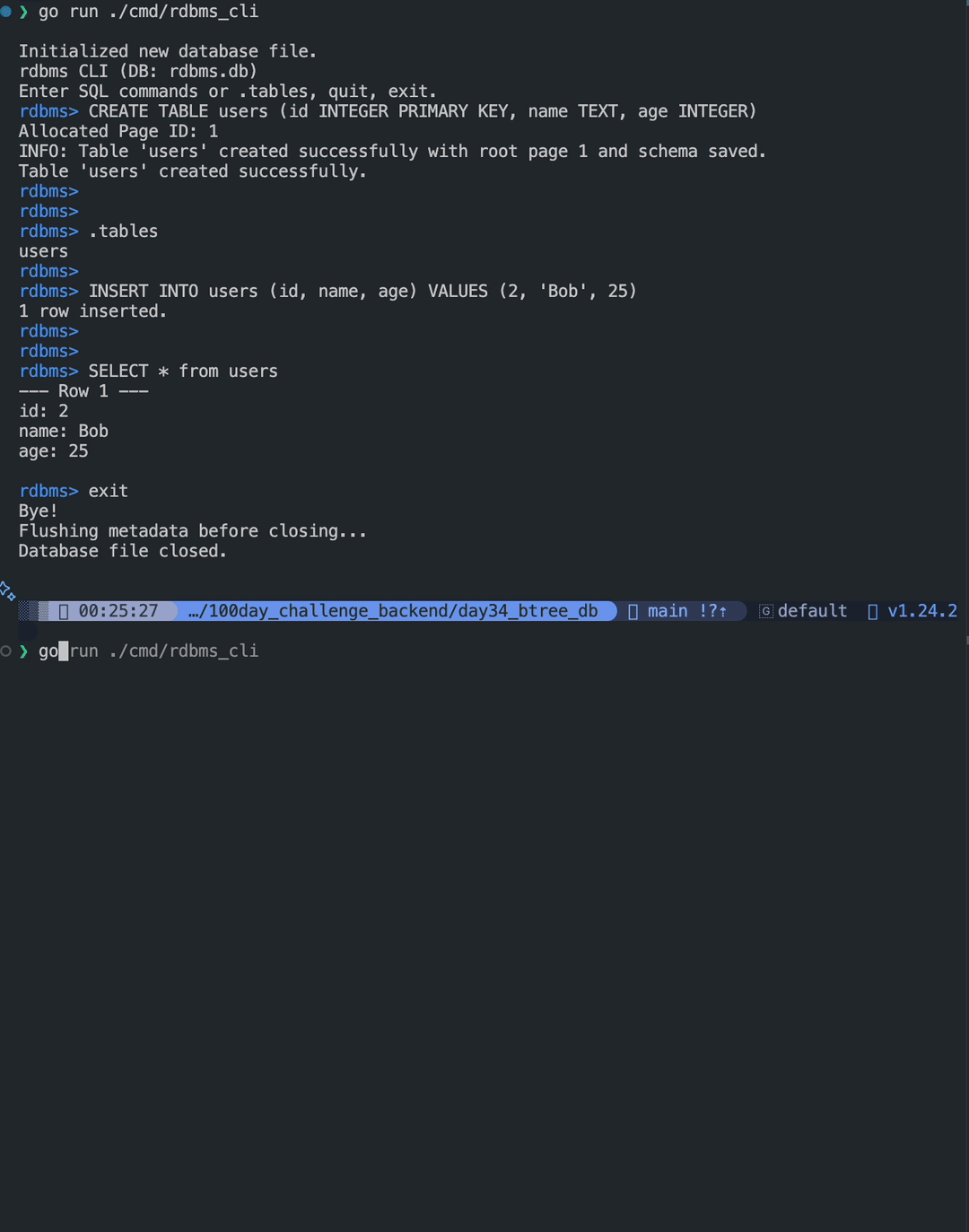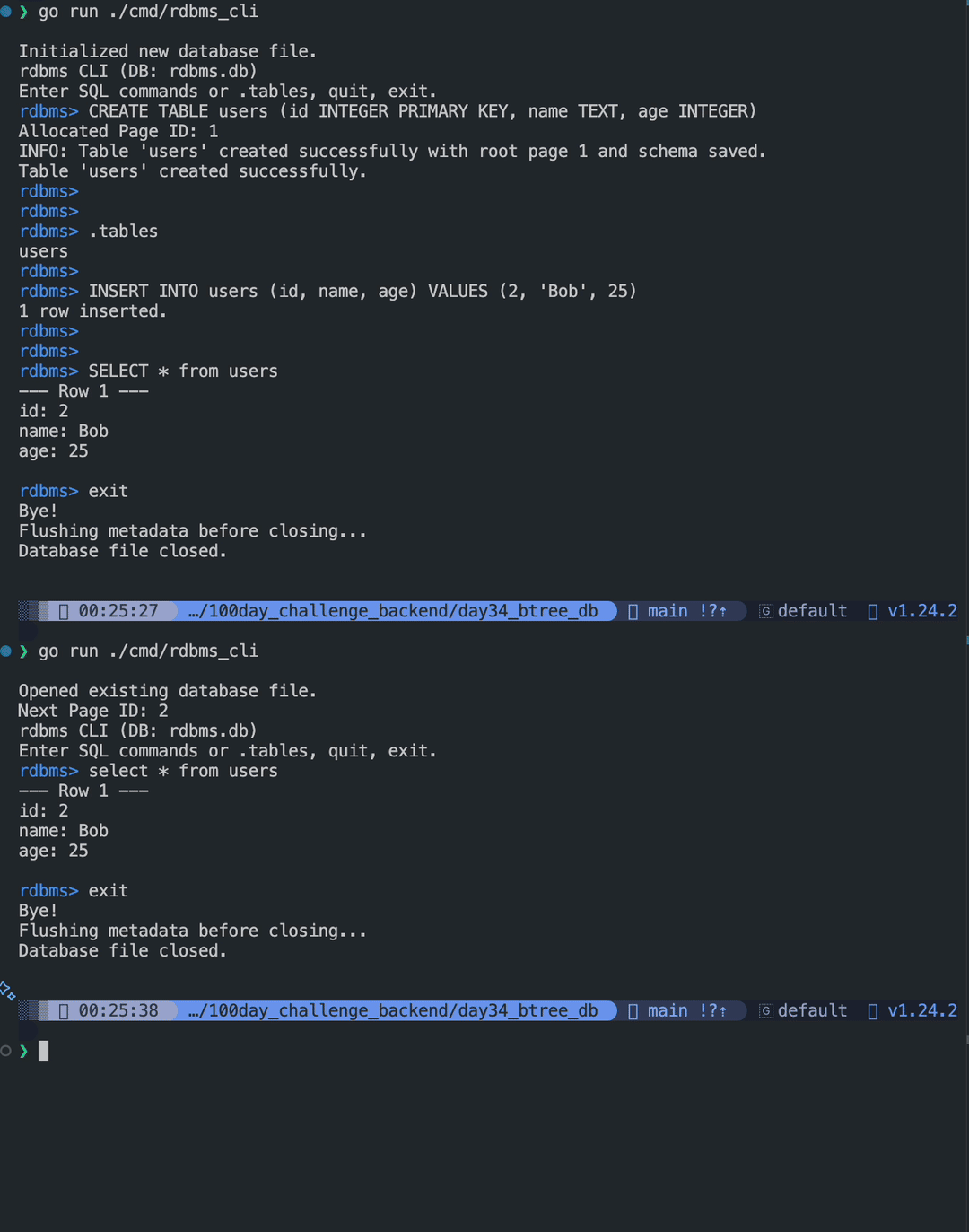
ここまでにしよう。。。トランザクションの導入はまったくうまくいかない
自分がトランザクションの実装についての知識が0なのが問題
学び
- RDBMS を作るのはめちゃくちゃ大変
- B+Tree はテーブルごとに作られ、index つくるとさらに作られる
- B+Tree の Node には具体的なデータは保管されず、別のデータとして保存されるこれによりバイナリデータが保存される
- 検索に利用されるキーは B+Tree Node に保存され、それを使って検索する
- B+Tree では作成、削除ごとにページ内にいれる Node を調整する
- B+Tree の実体の実装もめちゃくちゃ大変なのに、これをファイルに保存するのもしんどい
- ファイルに保存する時は Node をエンコードして保存していた
- トランザクションの実装はまじでできなかった(LLMを使用する実力と、知識不足)