[AWS] ECSでタスクが勝手に死ぬ→ヘルスチェックのポート指定が原因だった
仕事で ECS (Elastic Container Service) を触る機会があり、まずは学習がてら以下の記事を参考に WebSocket サーバーを立ててみました。
構成は ALB と Fargate からなるシンプルなものです。

手順に従って構築を進め、無事動作したかに思われたのですが、なぜかタスクが勝手に死に、生き返っては死、生き返っては死を10回ほど繰り返してサービスごと死ぬ現象が起きました。
同時実行タスク数を1にしていたので、タスクが死んだときに生き返るのは分かるのですが、以下の原因が分かりませんでした:
- なぜタスクが死ぬのか
- なぜ最終的にサービスごと死ぬのか
上記について調査してみました。
なぜタスクが死ぬのか
あるあるなようで、以下公式の記事を見つけました:
基本的にこれを一つ一つ調べれば原因は分かりそうです。
自分は幸いにしてすぐに原因が判明し、Failed Elastic Load Balancing (ELB) health checks に該当していました。
ELB と書かれていますが、今回使用した ALB ももちろん該当します[1]。
ALB では、登録されたターゲット(今回の場合は Fargate で登録されているタスク)に対して定期的にヘルスチェックを行なっています:
ヘルスチェックとはその名の通り、ターゲットがちゃんと稼働しているかを確認する機能なのですが、以下の記述がポイントでした:
If the health checks exceed UnhealthyThresholdCount consecutive failures, the load balancer takes the target out of service.
すなわち、ヘルスチェックに失敗すると、ロードバランサーはターゲットを停止させてしまいます(外部から停止させられているので、ECS のログを見ても気づくことができずでした…)。
ここでもう一つの疑問が生まれます。なぜヘルスチェックに失敗していたのでしょうか?
実は今回のチュートリアルでは、WS 用のポート(8080)とヘルスチェック用のポート(8000)を分けています。
↑のリンクにも説明がありますが、ALB のヘルスチェックでは WS プロトコルを受け付けていないため、ヘルスチェック用に HTTP プロトコルを受け付けるポートを別で開けていました。
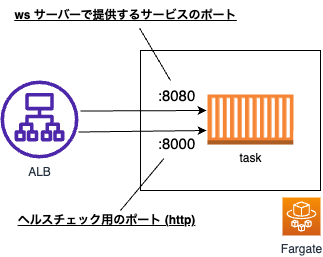
ターゲットグループはデフォルトではメインのサービスを提供するポートをそのままヘルスチェックでも使うのですが、今回の場合はそれだと ws プロトコル用のポートに向けてヘルスチェックしてしまうことになるので失敗→結局タスクが死ぬ、という話でした。
明示的に別ポートを指定する設定ですが、コンソールでは "override" というところでできました:

コンソールで構築するときの注意点
ECS のサービスを新規作成する際、併せて ALB とターゲットグループを作成するオプションがあるのですが、これだと小回りが効かないのかポートの設定項目が無く、デフォルトのポートが自動で指定されてしまいます(自分はここで本来はポートの指定が出来るということになかなか気が付けずハマってしまいました…)。
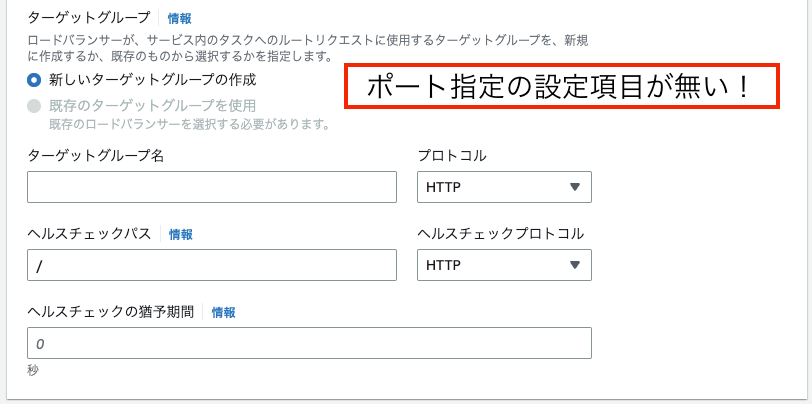
なので、きちんと EC2 のコンソールから自分で前もって作っておいてそれを指定するようにしましょう。
なぜ最終的にサービスごと死ぬのか
こちらは今のところ確たる原因を追えていません。
生き死にを無限に繰り返すようにも思われるのですが、何度やってもサービスごと死んでいました。
心当たりのある方はコメントで教えてください!
Discussion