TypeScriptで業務アプリケーションを試作してみたので、作っているときに考えたことについて書こうと思います。
作ったものは、花束問題というデータモデリングの問題をもとにした在庫管理アプリケーションです。ソースコードはこちらにあります。
なぜTypeScriptで業務アプリケーションを作ってみたかというと、Domain Modeling Made Functionalという本を読んだことがきっかけです。Domain Modeling Made Functional(以降DMMF)は、現実に基づくモデルによって堅牢なアプリケーションを作る方法について書かれた本です。
この本ではF#を使っているので、TypeScriptで実践するにはどうすればいいのかが気になりました。また、DMMFではデータベースとのやりとりがモックで実装されていたり、1つのワークフロー(商品の注文)しか扱っていません。そのため、より実践的なケースで試してみようと思いました。
花束問題について
花束問題は、花屋さんでの在庫管理をテーマにしたデータモデリングの問題です。
花束問題は、大まかには次のような設定です。詳細は花束問題の問題ページを参照してください。
- フラワーショップ「フレール・メモワール」は、Webショップ事業を立ち上げた。当初はWebからの注文を手作業で管理できていたが、受注が増えてきたためシステム化する必要が出てきた。
- 花束の組み合わせは事前に商品として決められている。顧客は商品を注文する。
- 花は特定の仕入れ先から購入され、花ごとに品質維持可能日数が決められている。品質維持可能日数を超えた花は、廃棄する必要がある。
- 花ごとに発注リードタイム(入荷されるまでにかかる日数)が決まっている。花を発注する際、発注リードタイムを超えていれば、どんな花も発注可能である。
使用したライブラリやフレームワーク
@trpc/serverがお気に入りです。バリデーションやミドルウェアなどのAPIを作る上で必要になる機能が、TypeScriptフレンドリーな方法で組み込まれていて使いやすいです。
データベースのアクセスはPrismaを使っています。書き込みはほとんどのケースに対応できそうですが、読み取りはSQLを書くことがしばしばあります(JOINや集計がやりづらい)。
実装する前に考えること
まずは問題を正しく理解する
DMMFの導入の部分で印象に残っているのは、ソフトウェア開発者の仕事はコードを書くことではなく、問題を解決することであるということです。
そして、問題を解決するためには、問題を正しく理解する必要があります。問題を正しく理解するためには、例えば次のことが重要です。
- 問題に詳しい人(ドメインエキスパート)と対話する
- 実際の現場で何が行われているかを観察する
もし花束問題が現実の問題だとすると、次のようなことをするのが重要なのかなと思いました。
- 実際に花屋さんに行ってお店の人と話をしてみる
- 花屋さんがどのように仕入れをしているのかを見てみる
- 花屋さんがどのように在庫を管理しているのかを見てみる
システムの全体像を図に書き起こす
DMMFではイベントストーミングというワークショップが紹介されています。イベントストーミングは、業務の全体像や手順を把握したり、プロジェクトに関わる人たちの間で共通理解を作るのに有効です。
イベントストーミングの成果物は、システムの全体像を把握するために役立ちます。そのため、今回は一人でやってみました(miroのテンプレートを使って雰囲気でやったので、今度はちゃんとやってみたい)。
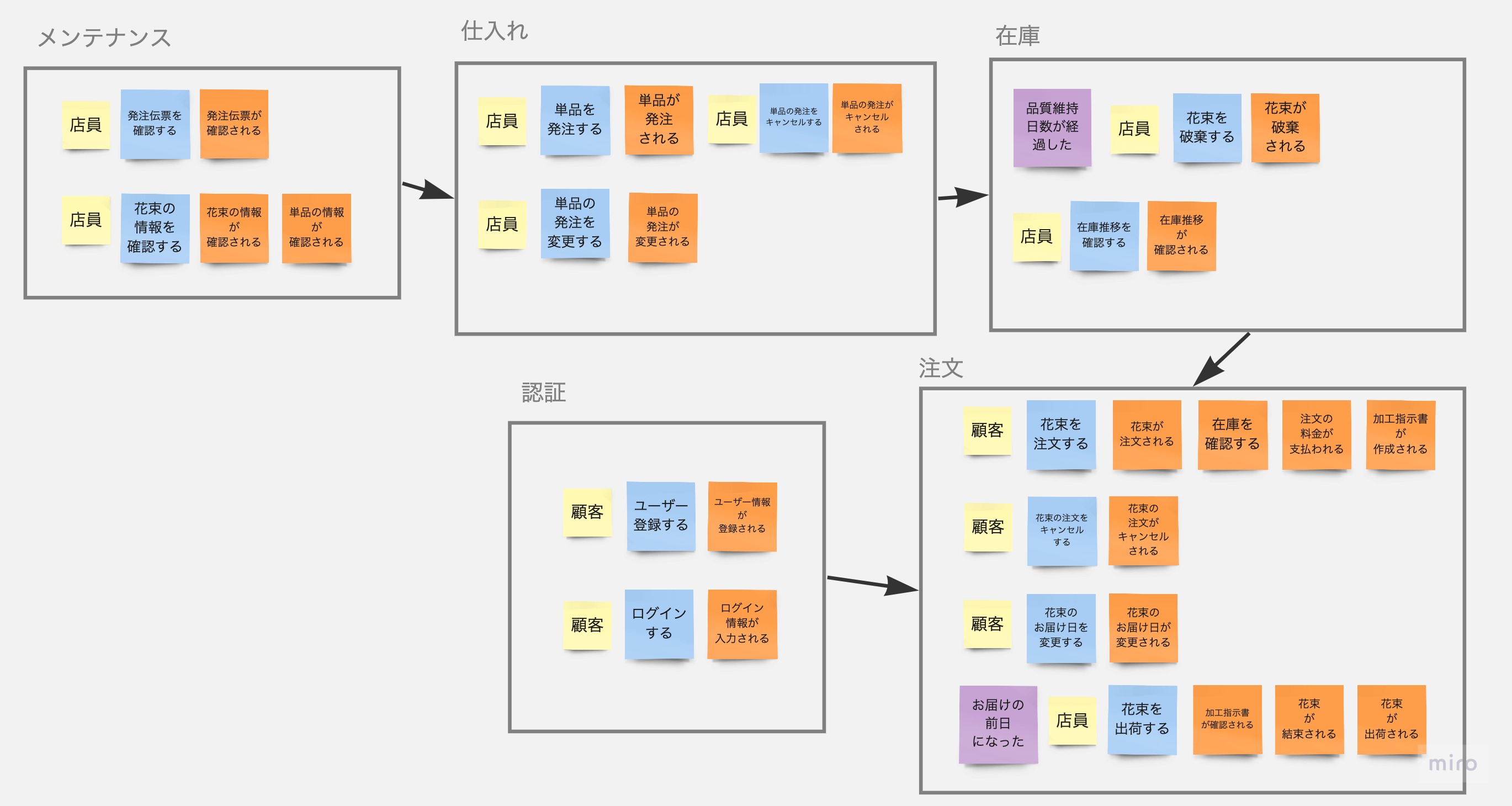
その結果、このシステムは5つのコンテキストに分けるとよさそうだということが分かりました。
- メンテナンス: 花束や花などのデータを管理する
- 仕入れ: 花の仕入れを行う
- 在庫: 現在の在庫や在庫推移を確認したり、花の破棄を行う
- 認証: ユーザーが、ユーザー登録やログインをする
- 注文: ユーザーが、花束の注文を行う
業務の手順を自然言語で記述する
DMMFでは、ワークフローごとに関連する人にインタビューを行い、ワークフローの内容を把握しています。そして、その結果を自然言語でまとめています。具体的には、次のようなフォーマットです。
このドキュメントは、業務の内容を把握したり、データ(アプリケーション側とデータベースの両方)を設計するときにも役に立ちます。
また、自然言語で記述することで、技術者以外の人と協力しながら作り上げることができます。上記はコードブロックで書いていますが、普通の文章で書いてもいいかもしれません。
今回は、ワークフローの内容をGitHubのDiscussionにまとめてみました。GitHubのDiscussionに限らず、複数人で書くことを促進してくれるプラットフォームを使うと良さそうです。
仕入れのモデリング · tekihei2317/frere-memoir · Discussion #5
データベースの設計
データベースはアプリケーションの心臓
データベースはアプリケーションの中心的な存在だと考えています。なぜかというと、データの保存の仕方が適切でないと、アプリケーション側にしわ寄せがくるからです。
データベースの設計で重要なポイント
テーブルを設計する際は、主に次の2点を考えています。
- データベースには事実を保存する
- 不正なデータを保存できないようにする
まず重要なのは、データベースには事実を保存することです。例えば、更新を避けたり、計算結果を保存しないようにします。
データを更新すると、過去の事実が消えてしまいます。そのため、後から情報が必要になるかどうかを考えてから更新する必要があります。
また、イミュータブルデータモデルという考え方があります。イミュータブルデータモデルは、データを日時属性をもつかどうかでリソースとイベントに分けるという方法です。
- イミュータブルデータモデル - kawasima
- WEB+DB PRESS Vol.130|技術評論社(イミュータブルデータモデルの特集があります)
データの変更はシステムを複雑にします。イミュータブルデータモデルは、データを変更する代わりにイベントを登録することで、システムの複雑さを軽減します。
不正なデータを保存できないようにするためには、ユニーク制約や外部キー制約を使ったり、テーブルを正規化してNULLを避けます。
データベースの具体的な設計例
それでは、実際にデータベースを設計してみます。設計するのは、仕入れ(発注と入荷)に関する部分です。
データベースの設計をするときは、業務の手順とざっくりとした画面があると役に立ちます。これらは、作るシステムをそれぞれ別の視点から切り取ったものです。業務の手順があればそこからテーブルにするものを抽出できます。また、画面があればテーブルのカラムが不足していないか確認できます。
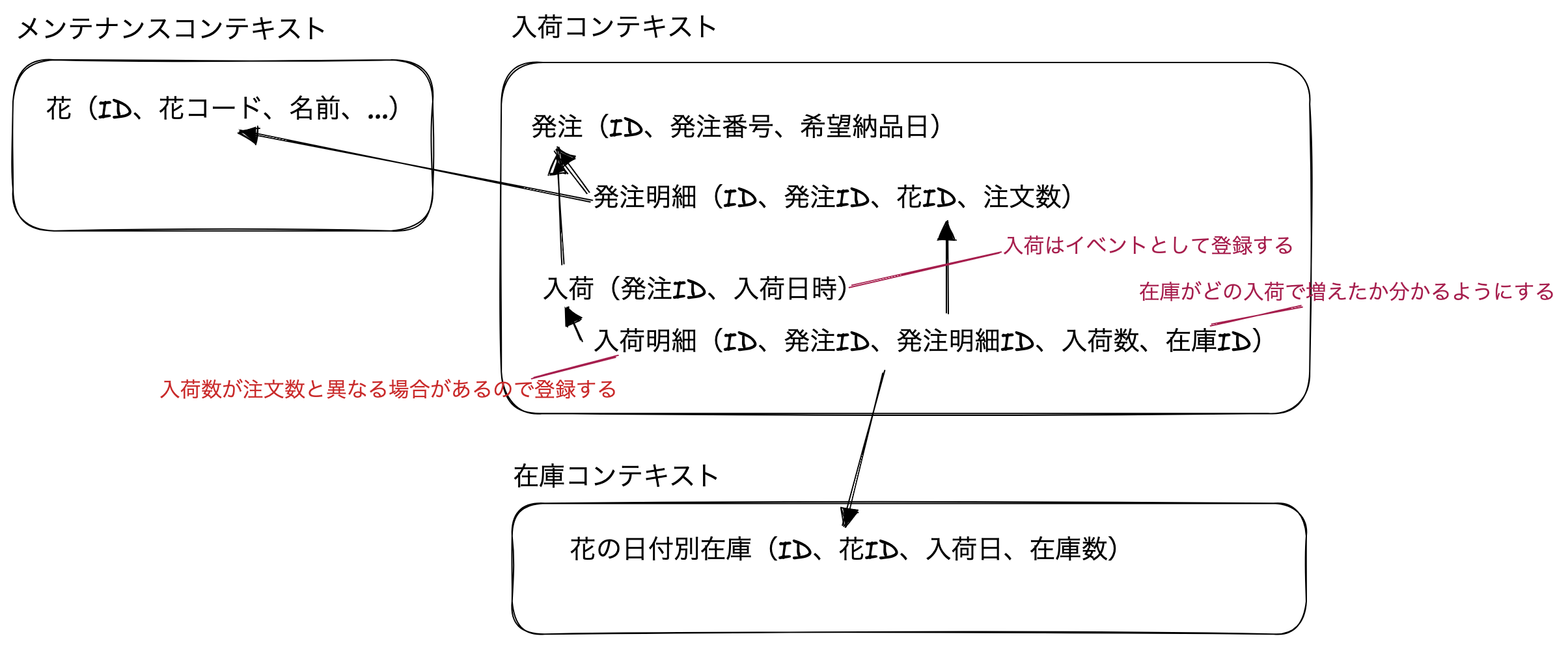
まず、発注は次のように複数の花を一度に発注します。そのため、発注テーブルと発注明細テーブルが必要です。
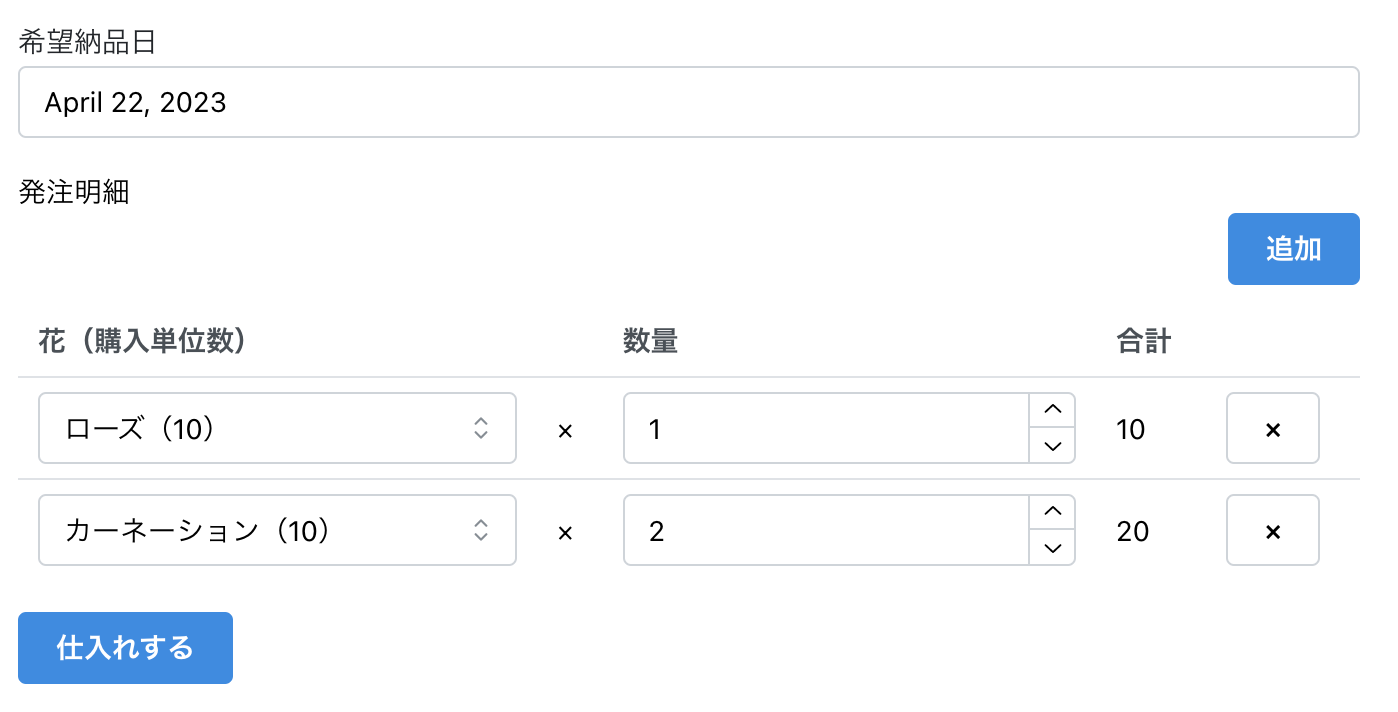
次に入荷です。入荷は、注文した数量と違う数が届く可能性があります。そのため、実際に届いた数量を登録できるように、入荷明細テーブルを作ります。
また、入荷を行う際は在庫が変化します。そのため、入荷明細と在庫を関連づけることにします。
以上のことを考えて、次のようにテーブルを作成しました。
テーブルの依存関係とコンテキストの依存関係について
上の設計には改善するところが1つあります。それは、入荷明細が在庫への外部キーを持っている部分です。
なぜ改善するべきかというと、業務の時系列と逆になっているからです。つまり、入荷を登録してから在庫を登録(または更新)するのではなく、在庫を登録してから入荷を登録する必要があります。
在庫を登録してから入荷明細を登録する必要がある
async function persistArrivalInformation(arrivalInfo: PurchaseArrival): Promise<void> {
// 在庫を作成する
const inventories = await Promise.all(
arrivalInfo.arrivalDetails.map(async (detail) => {
const inventory = await prisma.flowerInventory.upsert({
where: {
flowerId_arrivalDate: {
flowerId: detail.orderDetail.flowerId,
arrivalDate: fixDateForPrisma(arrivalInfo.arrivedAt),
},
},
create: {
flowerId: detail.orderDetail.flowerId,
arrivalDate: fixDateForPrisma(arrivalInfo.arrivedAt),
currentQuantity: detail.arrivedCount,
},
update: {
currentQuantity: { increment: detail.arrivedCount },
},
});
return inventory;
})
);
// 入荷情報を登録する
const inventoryMap = new Map(inventories.map((inventory) => [inventory.flowerId, inventory]));
await prisma.flowerOrderArrival.create({
data: {
flowerOrderId: arrivalInfo.purchaseId,
arrivedAt: arrivalInfo.arrivedAt,
orderDetailArrivals: {
createMany: {
data: arrivalInfo.arrivalDetails.map((detail) => ({
flowerOrderDetailId: detail.orderDetail.id,
arrivedQuantity: detail.arrivedCount,
flowerInventoryId: inventoryMap.get(detail.orderDetail.flowerId)!.id,
})),
},
},
},
});
}
また、コンテキストの依存関係に反していることも問題だといえそうです。そのような箇所があると、コンテキストをまたいだ更新を非同期で行えなくなります。
このような場合は、交差テーブルを用意して依存の方向を逆にすると良さそうです。具体的な実装は、リファクタリング後に追記します。
実装について
実装がシンプルにまとまる見込みがある場合は、素直に書き下す
例えば更新系の場合は、バリデーション+データベースの更新+αくらいであれば、プロシージャ[1]に処理を書き下して問題ないと思います。
具体的には次のような感じです。
/**
* 花を更新する
*/
export const updateFlower = adminProcedure.input(UpdateFlowerInput).mutation(async ({ ctx, input }) => {
const updatedFlower = await ctx.prisma.flower.update({
where: { id: input.id },
data: input,
});
return updatedFlower;
});
参照系の場合は、特に戻り値の型は指定せずにtRPCに推論させている箇所が多いです。なぜかというと、参照系APIと更新系APIで必要なデータが違うことが多かったり、画面に必要なデータには変更が入りやすいからです。[2]
/**
* 注文を取得する
*/
export const getOrder = adminProcedure.input(OrderIdInput).query(async ({ ctx, input }) => {
const order = await ctx.prisma.bouquetOrder.findUnique({
where: { id: input.orderId },
select: {
id: true,
bouquet: { select: { id: true, name: true } },
customer: { select: { name: true } },
deliveryDate: true,
senderName: true,
deliveryAddress1: true,
deliveryAddress2: true,
deliveryMessage: true,
shipment: true,
},
});
if (order === null) throw notFoundError;
return {
...order,
status: getOrderStatus(order),
};
});
書き下すと大きくなる場合は、データの型を定義して関数に分割する
更新系は特に、プロシージャに書き下すと処理が肥大化して見通しが悪くなりがちです。この対策として、データの型を定義してプロシージャを関数に分割します。
例えば、お客さんが花束を注文する機能の実装を考えてみます。これは次のようにモデリングしていました。
workflow 花束を注文する =
input: 花束の注文フォーム
output: 花束の注文
注文フォームの内容が正しいかを確認する
在庫を確認する(注文して間に合うかを確認する)
花束の金額の請求を行う
まずは、データの型や関数の型を定義します。
export type Customer = {
id: number;
email: string;
name: string;
};
export type ValidatedOrder = {
customerId: number;
senderName: string;
bouquetId: number;
deliveryDate: Date;
deliveryAddress1: string;
deliveryAddress2?: string | undefined;
deliveryMessage?: string | undefined;
totalAmount: number;
orderDetails: ValidatedOrderDetail[];
};
export type PlacedOrder = {
id: number;
customerId: number;
senderName: string;
bouquetId: number;
deliveryDate: Date;
deliveryAddress1: string;
deliveryAddress2: string | null;
deliveryMessage: string | null;
totalAmount: number;
};
// zodから導出した型
import { PlaceOrderForm } from "./api-schema";
/**
* 注文フォームをバリデーションする
*/
function validateOrderForm(orderForm: PlaceOrderForm, customer: Customer): ValidatedOrder {
}
/**
* 在庫の有無を確認する
*/
async function checkStock(order: ValidatedOrder): Promise<boolean> {
}
/**
* 注文をデータベースに保存する
*/
async function persistOrder(order: ValidatedOrder): Promise<PlacedOrder> {
}
/**
* 請求を行う
*/
async function processPayment(order: PlacedOrder): Promise<void> {}
そして、プロシージャからこれらの関数を使用します。
export const placeOrder = customerProcedure.input(PlaceOrderForm).mutation(async ({ input, ctx }) => {
const validatedOrder = await validateOrderForm(input, ctx.user);
if (!(await checkStock(validatedOrder))) {
throw new TRPCError({
code: "BAD_REQUEST",
message: "在庫が不足しているため、指定したお届け日にお届けできません。",
});
}
const placedOrder = await persistOrder(validatedOrder);
await processPayment(placedOrder);
return placedOrder;
});
プロシージャの中を見ればどのような処理をしているのかが一目で分かります。また、関数に分かれているので修正もしやすいです。
実装が手探りで、最初からデータの型を定義しにくい場合もあると思います。その場合は、後から関数に分けるといいと思います。
複雑になってきた場合は3つのレイヤーに分ける
ここまでの説明では、プロシージャに関する処理はほとんど1ファイルに書いてきました。しかし、ファイルの行数が多くなってくると、どこに何が書かれているのかが分かりづらくなってきます。[3]
その場合は、例えば次の3つのグループに分けると綺麗になると思います。
- procedureのように、なんでも書いてよい場所
- データベースに関する処理を書く場所
- HTTPやDBに依存しない、純粋なロジックを書く場所
今回は、この3つに分けたのは在庫推移の取得機能です。必要な情報をいろいろなテーブルから取得したり、その情報から計算する処理があったため、分割することで分かりやすくなりました。
2はpersistenceディレクトリ、3はcoreディレクトリに置くことにしました。
これから試すこと
まずは、プロシージャのテストを書きたいです。仕事のプロジェクトでは、Quramyさんのjest-prismaとprisma-fabbricaを使ってデータベースのテストを書いています。3月に発売されたJestではじめるテスト入門も読んでみて、参考にしたいと考えています。
次に、ESLintで依存関係のチェックをできるようにしたいです。チェックしたい依存関係は、コンテキスト間の依存関係と、コンテキスト内の依存関係です。
コンテキスト間の依存関係をチェックする場合は、PrismaClientを直接使うのではなく、コンテキストごとにモデルを配置するといいかもしれないと思いました(例えば、注文のコンテキストでexport orderModel = prisma.orderとする)。
Result型の導入も検討したいです。現状では、プロシージャと同じファイルに書いている関数ではTRPCErrorをスローしています。Result型を使うと、失敗する可能性があることを関数のインターフェイスで表現できます。そのため、いずれTRPCErrorをスローするとしてもメリットがありそうです。
あと、コアの部分の型定義がPrismaの型定義とほとんど同じになったので、制約をうまく表現できていないところがあるのかなと思いました。DMMFを参考にしたものの、データベース駆動の開発になった感じがあります。
DMMFや、TypeScript による GraphQL バックエンド開発 - Speaker Deckを読み返してみようと思います。
振り返り
このシステムが現実の誰かの役に立つのかというと、答えはNoだと思います。一番の原因は、実際に問題を抱えているユーザーを観察して作っていないことだと思います。言い換えると、自分の先入観や仮定に基づいて作っていたということです。
そのため、実際にアプリケーションを開発する際は、問題を抱えている人にインタビューをしたり、自分が困っていることを解決するようなものを作ることが重要だと感じました。
また、一度に全ての機能を作らないことが重要だとも感じました。なぜかというと、作る→使う→修正するというサイクルを何度も繰り返した方が、不要な機能や使いづらい機能を作るのを防げるためです。
DMMFには、リソースが足りない場合はビジネスで重要なところ、つまりお金になるところから作ろうと書かれています。今回のシステムは、次のような事情がある想定でした。
当初は受注も少なく手作業で管理出来ていたが、受注が増えるにつれシステム化の必要性が出てきた。「新鮮な花を大切な記念日に」を売り文句にしていることもあって、廃棄される在庫が多く、受注の増加にともなって利益が伸びていないため。
そのため、手作業ですると大変な部分や、廃棄を少なくするための機能を優先して作ればよかったのかなと思いました。
まとめ
TypeScriptで業務アプリケーションを試作してみて、考えたことや実装して気づいたことをまとめてみました。
Domain Modeling Made Functionalからは、問題を正しく理解すること・システムの全体像を把握してコンテキストに分けること・自然言語で業務の手順を整理することを学びました。
実装面では、データに正確な型をつけることや、ワークフローを入出力が明確な関数の集まりで構成することが重要だと感じました。
システムを作る上では、データベースの設計が非常に重要です。データベースの設計で重要なことは、事実を保存することと、不正なデータが登録されないようにすることです。データベースの設計の際は、イミュータブルデータモデルの考え方が参考になります。

Discussion
有益な記事ありがとうございます!!