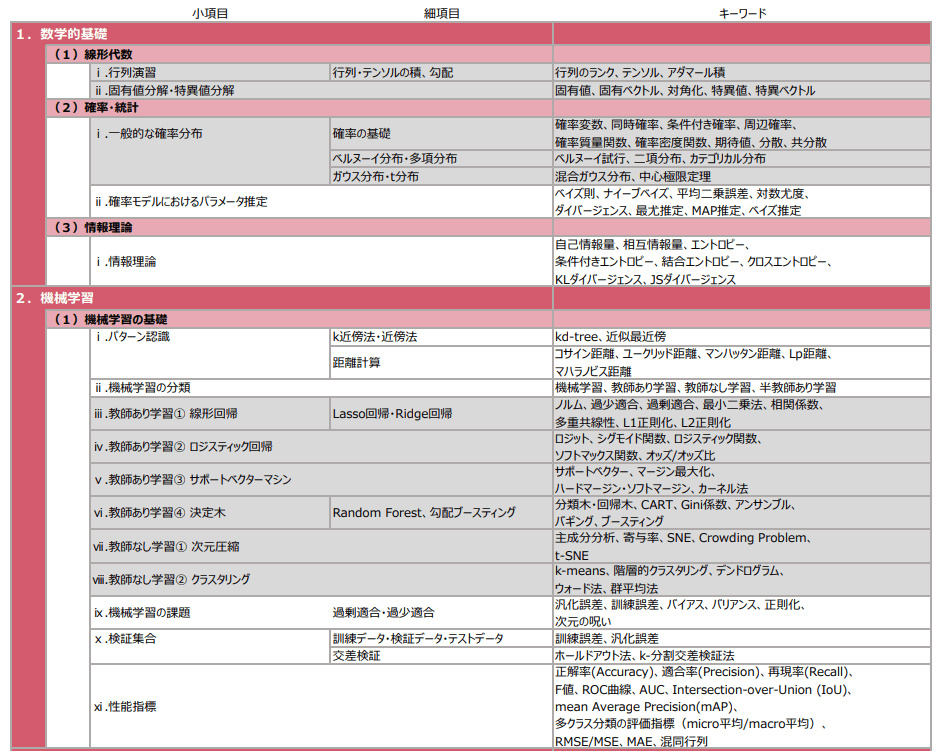
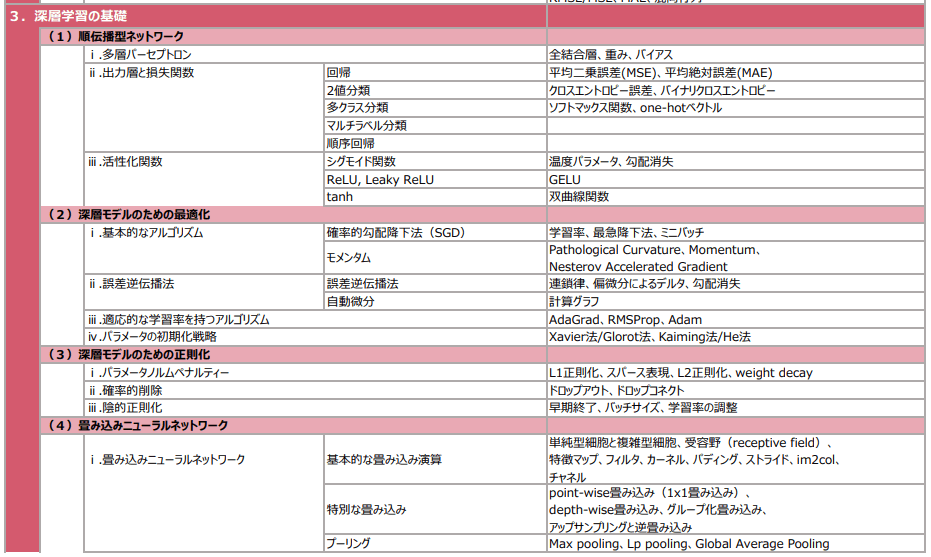
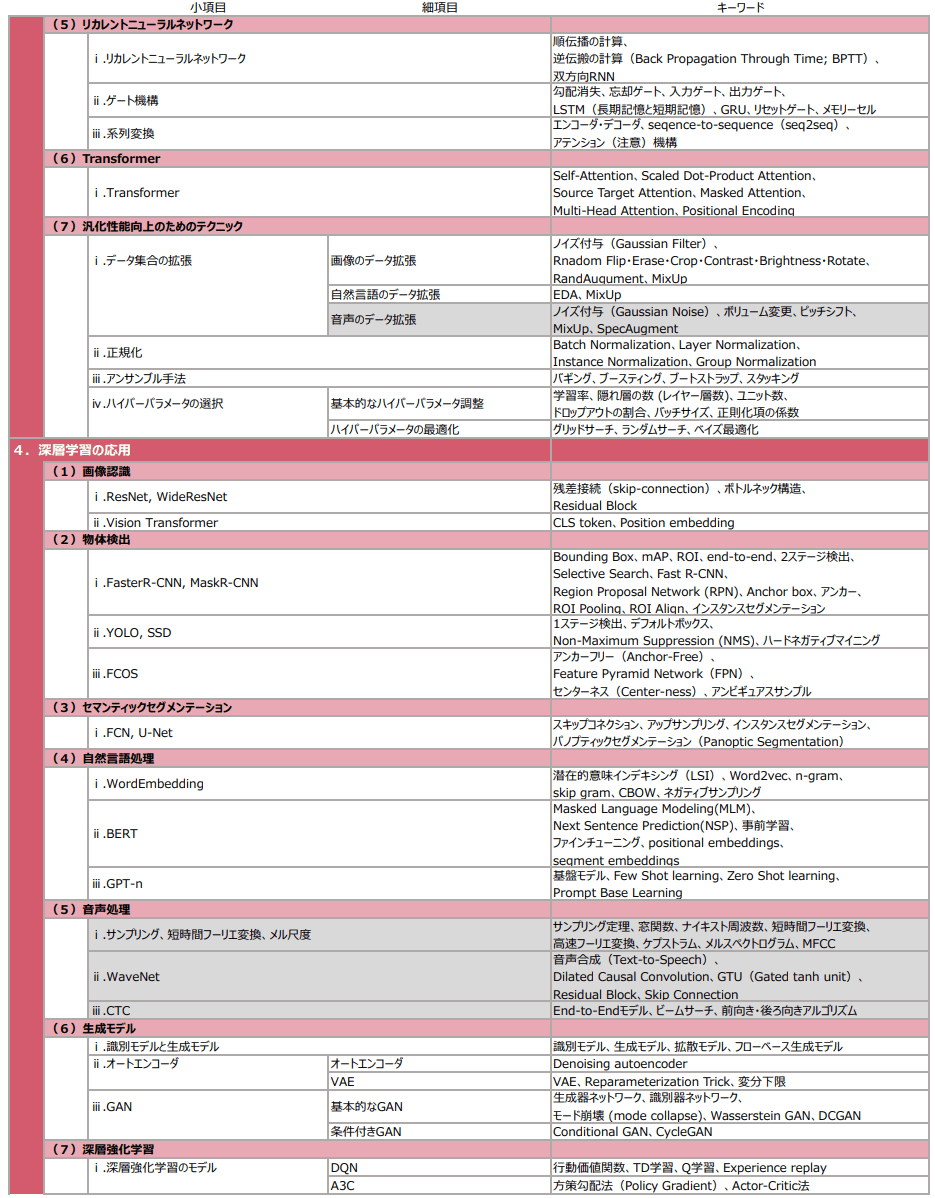
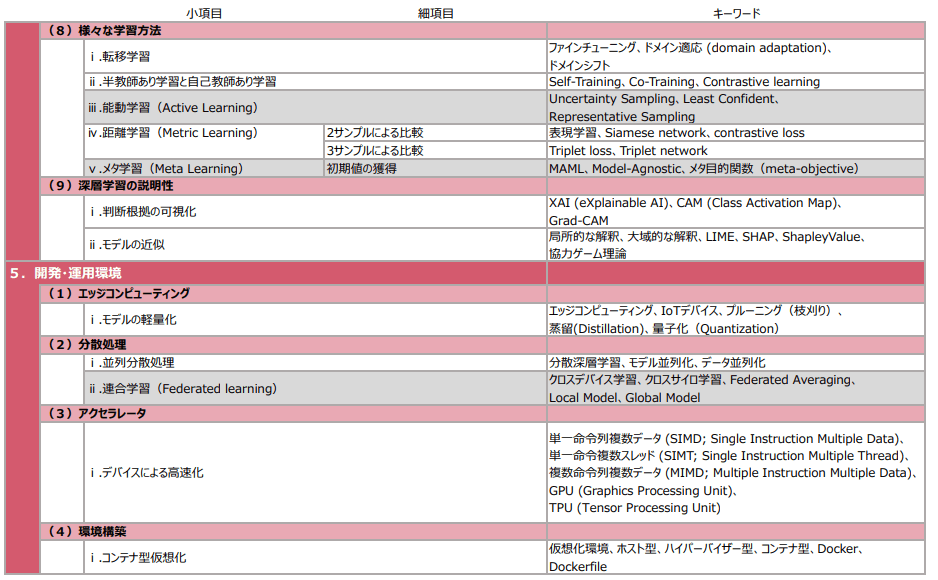
E資格対策 18-19章
第18章:開発・運用環境
回答した問題:
- ア:A,イ:B,ウ:A,エ:B,オ:B,カ:A,キ:C
- A
- B
- ア:C,イ:C,ウ:D,エ:B
間違えた問題:
- キ:C→D
- A→D
- B→C
蒸留(distillation)
蒸留とは大きなモデルが獲得した知識を小さなモデルに転移させる方法であり,一般に軽量化の手法に位置づけられる。

量子化(quantization)
量子化は、深層学習モデルのパラメータやアクティベーションを、元の32ビット浮動小数点表現から、8ビットや16ビットなどの低精度な数値表現に変換する手法です。これにより、モデルのメモリ使用量と計算コストが大幅に削減され、推論速度が向上します。精度の低下を最小限に抑えつつ、リソース制約のあるデバイス(モバイルやエッジデバイスなど)でも高効率な実行が可能になるのが量子化の主なメリットです。

剪定(pruning)
Pruning(プルーニング)は、深層学習モデルから不要なパラメータ(重みやニューロン)を削除してモデルを軽量化する手法です。これにより、モデルのサイズが縮小し、計算コストやメモリ使用量が削減され、推論速度が向上します。通常、プルーニングはモデルの精度をほぼ維持しながら、効率を高める目的で行われます。
- チャンネル剪定(channel pruning)では,ラッソに基づいて代表的なチャンネルを選択し,冗長なチャンネルを刈り取ったうえで,最小二乗法で残ったチャンネルを再構成する。
- ニューラルネットワークには「部分ネットワーク構造」と「初期値」の組み合わせに当たりが存在し,それを引き当てると効率的に学習が可能という仮説がある。これを宝くじ仮説(lottery ticket hypothesis)という。この仮説は,「剪定によって得られる疎なネットワークはなぜ剪定を使わずに最初から学習できないのか?」という動機により生み出された。
- 剪定は学習と同時もしくは学習後に行われるため,学習前に剪定すべきノードやエッジなどを知ることはできない。
19章:総仕上げ問題
※以下出題範囲に則り問題を解く
- ボトルネック構造:https://qiita.com/koshian2/items/031b6a335d0d217e4c4c
要するに畳み込みの前に1×1のconv挟んでチャンネル数を減らしておきましょうねということだと理解
回答した問題と解説
- ア:D,イ:B,ウ:C
- ア:D,イ:B,ウ:C
- ア:D,イ:C,ウ:B,エ:A
- ア:C,イ:A,ウ:A,エ:C
- ア:A,イ:D,ウ:A,エ:B,オ:C,
- ア:B,イ:A,ウ:A
- Ⅰ:D,Ⅱ:B,Ⅲ:D,Ⅳ:B,
- Ⅰ:A,Ⅱ:A,Ⅲ:C,Ⅳ:A
- Ⅰ:G,Ⅱ:A,Ⅲ:D,Ⅳ:A,Ⅴ:B,Ⅵ:C,Ⅶ:B
- Ⅰ:C,Ⅱ:C,Ⅲ:D,Ⅳ:A,Ⅴ:B,
- Ⅰ:B,Ⅱ:B
- Ⅰ.C,Ⅱ:A,Ⅲ:D,Ⅳ:C
→
→colとimgのxとyの配列の順番は同一,heightがy,widthがxに対応している。
→im2colではチャンネルごとに別々の列に畳み込み領域が格納される。そのため,reshapeする際は,((Nout_hout_w),-1)に変換する - Ⅰ:D,Ⅱ:C,Ⅲ:G
→DenseNet: スキップ接続をブロックの入出力のバイパスとしてのみならずブロック内のあらゆる箇所に伸ばすような構造を採用している
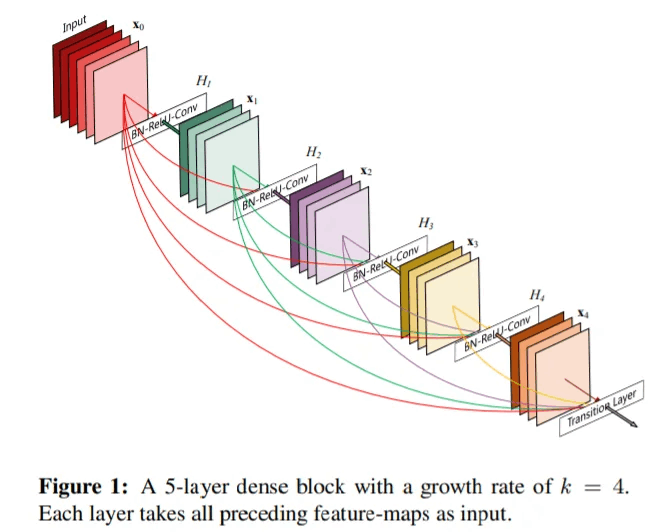
- Ⅰ:B,Ⅱ:A,Ⅲ:B
→SSD,YOLOに代表されるシングルショット系の手法では,グリッドごとに所定の数の物体を検出する。モデルの構造がシンプルなこと,軽量に動作すること,背景の特徴を暗に学習できることなどから,現在の物体検出モデルの主流となっている。 - D
→FCNの特徴:- 最初期のセグメンテーションモデル

- 最初期のセグメンテーションモデル
- Ⅰ:B,Ⅱ:B,Ⅲ:C
グループ畳み込み
通常の畳み込み層では、入力チャネル全体に対してフィルタが適用されます。例えば、入力が64チャネルあり、出力が128チャネルの場合、128個のフィルタそれぞれが全ての64チャネルに対して畳み込みを行います。この場合の計算コストは非常に大きくなります。
一方、グループ畳み込みでは、入力チャネルを複数のグループに分割し、各グループに対して個別に畳み込みを行います。例えば、64チャネルの入力を4つのグループに分割すると、それぞれのグループは16チャネルを持つことになります。そして、各グループに対して個別にフィルタが適用され、その結果が最終的な出力に統合されます。
グループ畳み込みの仕組み
-
入力チャネルの分割:
- 例えば、入力が64チャネルあり、グループ数を4とする場合、入力チャネルを16チャネルずつ4つのグループに分割します。
-
各グループへの畳み込み:
- 各グループに対して独立したフィルタを適用します。例えば、出力チャネルが128チャネルになる場合、各グループに32個のフィルタを適用します(128チャネル ÷ 4グループ)。
-
出力の統合:
- 各グループから得られた出力を統合して、最終的な出力を形成します。この場合、各グループの出力が32チャネルであるため、最終的な出力は128チャネルになります。
グループ畳み込みの利点
-
計算コストの削減: グループごとに計算を行うため、計算コストが大幅に削減されます。これにより、より深いモデルやより大きな入力サイズを効率的に処理できます。
-
メモリ使用量の削減: フィルタ数が減少するため、モデルのメモリ使用量も削減されます。
-
表現力の向上: 入力をグループに分けることで、各グループが異なる特徴を学習することができます。これにより、モデルの表現力が向上することがあります。
グループ畳み込みの実装例
以下は、PyTorchでグループ畳み込みを実装する際のコード例です。
import torch
import torch.nn as nn
# 入力チャネルが64、出力チャネルが128、グループ数が4のグループ畳み込み
group_conv = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1, groups=4)
# ダミー入力(バッチサイズ1、64チャネル、32x32ピクセル)
input_data = torch.randn(1, 64, 32, 32)
# グループ畳み込みの適用
output_data = group_conv(input_data)
print(output_data.shape) # 出力: torch.Size([1, 128, 32, 32])
このコードでは、64チャネルの入力を4つのグループに分け、それぞれに対して畳み込みを行い、最終的に128チャネルの出力を得ることができます。
22. Ⅰ:B,Ⅱ:D,Ⅲ:C,Ⅳ:D,Ⅴ:D
→GRUは"リセットゲート"と"更新ゲート"で構成される。LSTMは"入力ゲート","出力ゲート","忘却ゲート"

→pythonにおいて,アダマール積は*のような形式で表す(例:r * h_prev)。
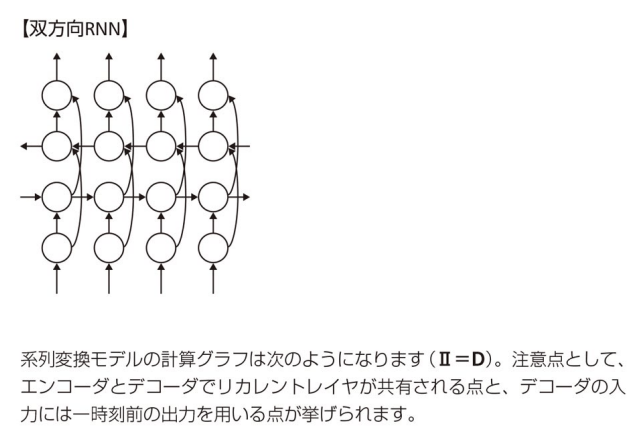
23. Ⅰ:C,Ⅱ:D
→
24. Ⅰ:D,Ⅱ:B
25. Ⅰ:D
→
26. Ⅰ:A,
27. Ⅰ:D,Ⅱ:A,Ⅲ:C
→JSダイバージェンス:https://www.hello-statisticians.com/explain-terms-cat/js_divergence1.html
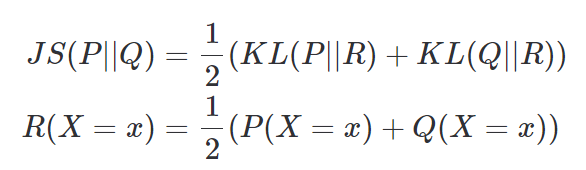
28. Ⅰ:B,Ⅱ:B,
→AlphaStar
29. Ⅰ:B,Ⅱ:B,Ⅲ:B
→Sarsaは行動価値関数を更新する際,行動価値の小さい探索結果も考慮されやすいという利点がある。その反面計算は不安定にないやすい欠点もある。
→Sarsaは方策オン型の手法で,行動を決定する方策と行動価値関数の更新に利用される方策は同一
→Sarsaでは,経験していない「状態と行動の組み合わせ」に対する行動価値関数は更新されない。
→Q学習はSarsaよりも行動価値関数の収束が早い傾向にある。
→Q学習は方策オフ型の手法。行動を決定する方策と行動価値関数の更新に利用される方策が異なる。
→Q学習は,行動価値関数を更新する際,行動価値の小さい探索結果は反映されにくい傾向がある。
→Q学習は,Sarsaとは異なり,行動価値関数Qの更新が行動の決定方法に依存しない。
30. C
→
31. Ⅰ:B