Capnproto公式要約 - Encoding



概要
Cap'n Protoが通信する際の最も基本的な単位の概念(Struct/Listなど)とそのメモリ上のレイアウトを定義する
Cap'n Protoがやり取りするメッセージのバイナリのフォーマットを説明する
(元のドキュメントは公式ドキュメント 参照)
データ構造
64-bit words
- Capn'Protoでは
Wordは8byte - 全ての
Object(Struct/List/Capabilityなど)はWord境界にパディングで揃えられる(C++の構造体のパディングと一緒)
<a id="anchor1"></a>
アンカー
Serialize
Capn ProtoのRPCはバイトストリームでRPCを行う。
ストリームに流れるデータのフォーマットは以下の通り。
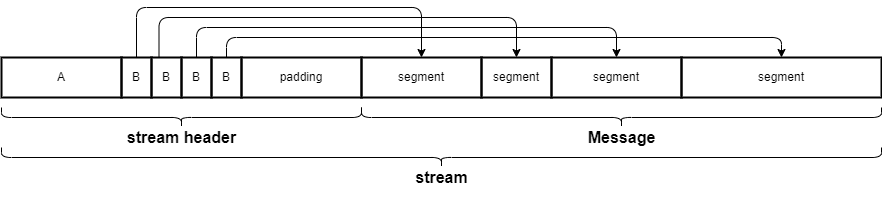
- A(32bit): segmentの数 - 1
- B(32bit): i番目のBはi番目のsegmentのサイズ(ワード長)
- padding(0または32bit): 次のワード境界までのpadding
- segment:
Messageがここに入っている
Message
- 通信の単位は
Message -
Messageは(意味的な構造としては)Objectのツリー構造である。- ルート
Objectは常にStructである
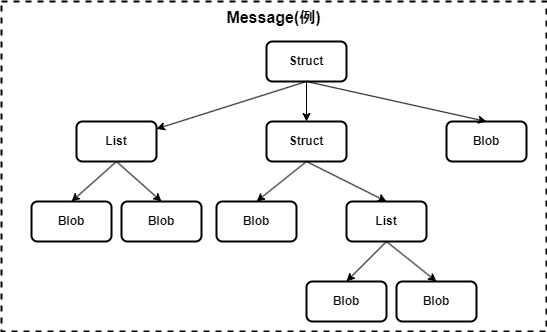
- ルート
-
Messageは(メモリ上の物理的構造としては)1つまたは複数のSegmentに分割される- 少なくとも読みだす際は連続したメモリ領域に配置する必要がある
-
Messasgeの最初のSegmentの最初のWordは常にMessageのルートObjectへのpointer
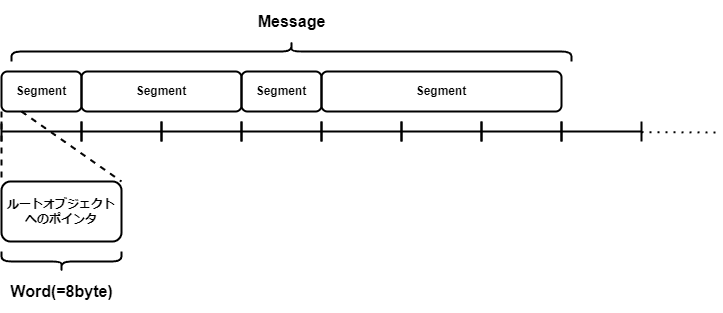
Object
-
Objectは組み込み型とpointerで構成される -
Objectはpointerで参照される任意の値であり、pointerは常にObjectの先頭を指す -
Objectとpointerは1:1であり、1:NやN:1にはならない(=木構造になる)
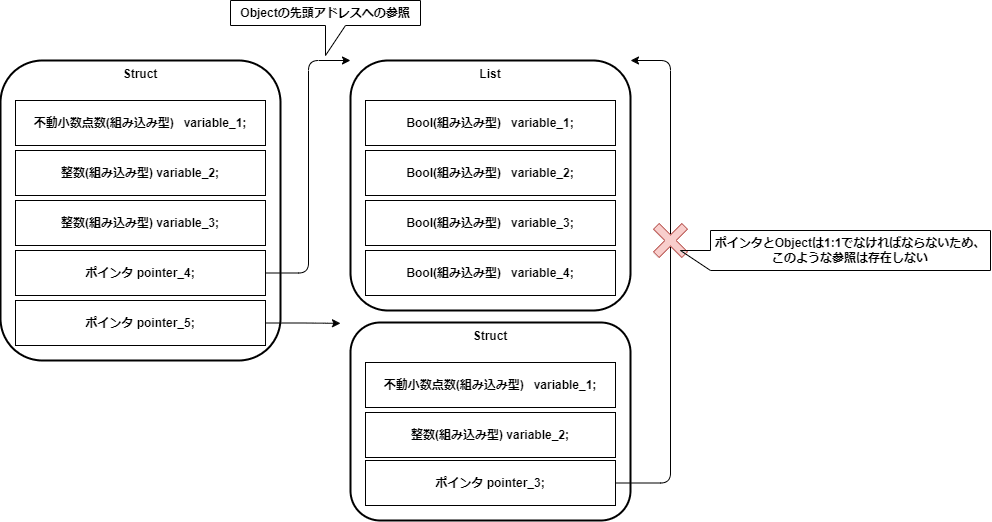
-
Objectには以下の4種類の構造が存在し、それぞれ構造が異なるStructListFar-pointer landing padBlob
値のEncoding
組み込み型
- 型毎に以下のルールでエンコードされる
-
Void: 情報がないため、エンコードされない -
Bool: 1ビット(1=true, 0=false)にエンコードされる -
Integer: 符号は2の補数で表現する -
Float: IEEE-754のフォーマットでエンコードされる
-
Enum
- Uint16としてエンコードされる
Blobs
-
Data: List(Uint8)と同等 -
Text: ほぼDataと同等だが、UTF-8である必要がある
ObjectのEncoding
Structs
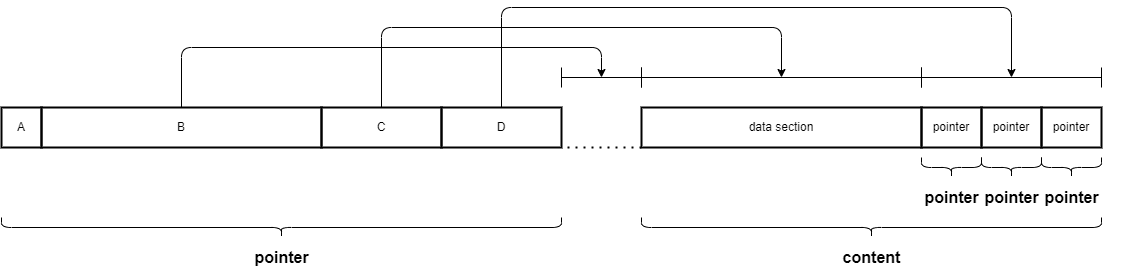
-
Structの構造は以下のとおり- この
Strcutのpointer- A( 2bits):
Messageの種別を表現するbit.Structの場合は00になる - B(30bits): この
pointerの終端からdataセクションまでのoffset - C(16bits): dataセクションのサイズ(Word長換算)
- D(16bits): pointerセクションのサイズ(Word長換算)
- A( 2bits):
- この
Strcutのcontent- data section:
組み込み型等の集合 - pointer section: この
Structが所有する別のObjectへのpointerの集合
- data section:
- この
Lists(Struct以外)
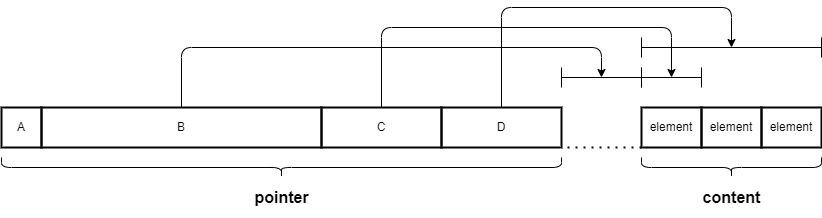
-
Listの要素がStruct以外のListの構造は以下のとおり。- この
Listのpointer- A( 2bits):
Messageの種別を表現するbit.Listの場合は01になる - B(30bits): この
pointerの終端からListの最初の要素までのoffset - C( 3bits):
Listの要素一つあたりのサイズ- 0 = 0 (e.g. List(Void))
- 1 = 1 bit
- 2 = 1 byte
- 3 = 2 bytes
- 4 = 4 bytes
- 5 = 8 bytes (non-pointer)
- 6 = 8 bytes (pointer)
- D(29bits):
Listの要素の数
- A( 2bits):
- この
Listのcontent: 要素のデータが入っている
- この
Lists(Struct)
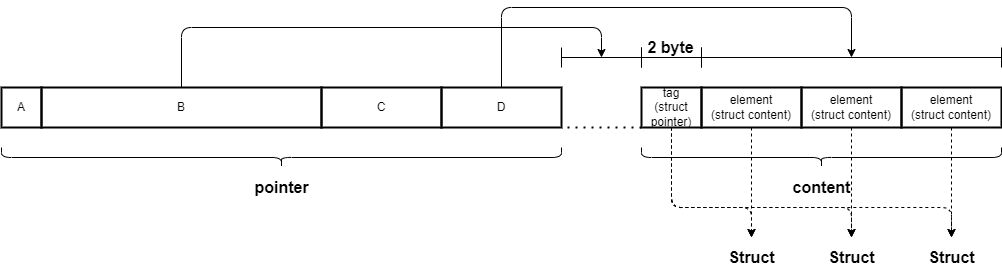
-
Listの要素がStructのListの構造は以下のとおり。- この
Listのpointer- A( 2bits):
Objectの種別を表現するbit.Listの場合は01になる - B(30bits): この
pointerの終端からListの最初の要素までのoffset - C( 3bits):
Listの要素がStructの場合、7になる- 7 = composite (see below)
- D(29bits):
Tagを除くListの要素全体の長さ(Word長換算)
- A( 2bits):
- この
Listのcontent: 要素のデータが入っている-
tag:Listの要素のStructのpointerが入っている。ただし、B(30bit)はListの要素数になっている -
element:Listの要素のStructのcontentが入っている
-
- この
Capabilities

-
Capabilityの構造は以下のとおり- A( 2bits):
Objectの種別を表現するbit.Capabilityの場合は03になる - B(30bits):
Capabilityの場合0になっている - C(32bits):
Capabilityのインデックス番号
- A( 2bits):
SegmentをまたぐPointers
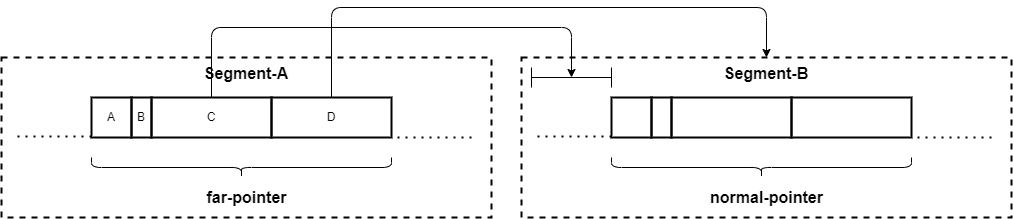
- 通常の
far-pointer- A( 2bits):
Objectの種別を表現するbit.far-pointerの場合は02になる - B( 1bits): 通常の
far-pointerの場合、ここは0 - C(29bits): 参照先の
segmentの先頭からのoffset - D(32bits): 参照先の
segmentのID
- A( 2bits):
SegmentをまたぐPointers(二重)
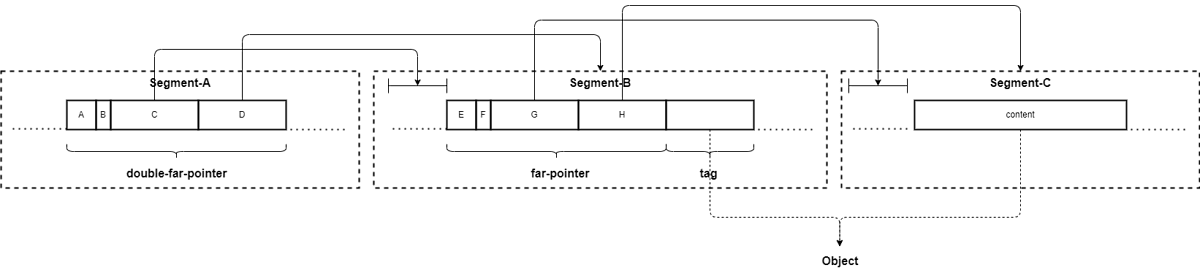
- 二重の
far-pointer- A( 2bits):
Objectの種別を表現するbit.far-pointerの場合は02になる - B( 1bits): 二重の
far-pointerの場合、ここは1 - C(29bits): 参照先の
segmentの先頭からのoffset - D(32bits): 参照先の
segmentのID - E( 2bits):
Messageの種別を表現するbit.far-pointerの場合は02になる - F( 1bits): ここは通常の
far-pointerであるため、0になる - G(29bits): 参照先の
segmentの先頭からのoffset - H(32bits): 参照先の
segmentのID - tag: 通常の
pointerと同じだが、offsetは0になっている
- A( 2bits):
- ただし、二重の
far-pointerが使われる状況はまれである
Packing
わりと公式ドキュメントがわかりやすいので省略
実践
ここでは、上述の理解から実際に通信のバイナリデータをダンプして中身を読みだしてみる
詳細は割愛しますが、linuxであれば最終的にwriteInternalでソケットのfdにデータをwriteしているため、ここに以下のようにログを仕込みます
$ git diff c++/src/kj/async-io-unix.c++
diff --git a/c++/src/kj/async-io-unix.c++ b/c++/src/kj/async-io-unix.c++
index 62ce2132..0524971e 100644
--- a/c++/src/kj/async-io-unix.c++
+++ b/c++/src/kj/async-io-unix.c++
@@ -57,6 +57,7 @@
#include <limits.h>
#include <sys/ioctl.h>
#include <kj/filesystem.h>
+#include <iostream>
#if __linux__
#include <sys/sendfile.h>
@@ -768,6 +769,21 @@ private:
iovTotal += iov[i].iov_len;
}
+ std::cout << "~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~" << std::endl;
+ std::cout << iovTotal << std::endl;
+ int kaigyou = 0;
+ for (uint i = 0; i < iov.size(); i++) {
+ for (uint j = 0; j < iov[i].iov_len; ++j){
+ printf("%02X", ((unsigned char*)iov[i].iov_base)[j]);
+ ++kaigyou;
+ if (kaigyou == 8){
+ kaigyou = 0;
+ printf("\n");
+ }
+ }
+ }
+ std::cout << "\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~" << std::endl;
+
if (iovTotal == 0) {
KJ_REQUIRE(fds.size() == 0, "can't write FDs without bytes");
return kj::READY_NOW;
例えば以下のようなメッセージを送ることがあるかもしれません
00000000
05000000
00000000
01000100
08000000
00000000
00000000
01000100
00000000
00000000
00000000
00000000
まずは、Serializeのセクションに記載した通り、先頭の4バイトが セグメントの数-1 です
00000000 # セグメントの数-1。
05000000
00000000
01000100
08000000
00000000
00000000
01000100
00000000
00000000
00000000
00000000
明らかに0なので、セグメントの数は1つだと分かります
次に、Serializeのセクションに記載した通り、次の4バイトがこのセグメントのワード長です
00000000 # セグメントの数は1つ
05000000 # セグメントのサイズ (ワード長)
00000000
01000100
08000000
00000000
00000000
01000100
00000000
00000000
00000000
00000000
リトルエンディアンですので、0x00000005=5がセグメントのワード長です
ワードは8byteですので、このセグメントは40byteであることが分かります
分かりやすく、以下のようにまとめます
#####################################
# Streamのヘッダの情報
00000000 # セグメントの数は1つ
05000000 # セグメントのサイズは40byte
#####################################
00000000
01000100
08000000
00000000
00000000
01000100
00000000
00000000
00000000
00000000
Messageに書いたとおり、最初のセグメントの最初のワード(8byte)はポインタです
最初のpointerはStructのポインタなので、Structsを見ると読み方が分かります
#####################################
# Streamのヘッダの情報
00000000 # セグメントの数は1つ
05000000 # セグメントのサイズは40byte
#####################################
# Pointer
00000000 # 整数値としては0
0100 # dataセクションのサイズは1ワード長
0100 # pointerセクションのサイズは1ワード長
#####################################
08000000
00000000
00000000
01000100
00000000
00000000
00000000
00000000
この最初の4byteのうち、lsbで先頭の2bitがMessageの種別、lsbで3bit目以降がoffsetになる
最初の4byteをリトルエンディアンで解釈した値をXとすると、X&3やX>>2で算出する
(今回はどちらも明らかに0)
#####################################
# Streamのヘッダの情報
00000000 # セグメントの数は1つ
05000000 # セグメントのサイズは40byte
#####################################
# StructのPointer
00000000 # 種別は00(=struct), offsetも0
0100 # dataセクションのサイズは1ワード長
0100 # pointerセクションのサイズは1ワード長
#####################################
08000000
00000000
00000000
01000100
00000000
00000000
00000000
00000000
offsetが0だったので、次はこのStructのdataセクションとpointerセクションが並んでいます
それぞれ1ワード(8byte)なので以下のようになっています
#####################################
# Streamのヘッダの情報
00000000 # セグメントの数は1つ
05000000 # セグメントのサイズは40byte
#####################################
# StructのPointer
00000000 # 種別は00(=struct), offsetも0
0100 # dataセクションのサイズは1ワード長
0100 # pointerセクションのサイズは1ワード長
#####################################
# Structのdataセクション
08000000
00000000
#####################################
# Structのpointerセクション
00000000
01000100
#####################################
00000000
00000000
00000000
00000000
00000000
dataセクションにどのようなデータが入っているかは、rpc-schemaやuser-schemaで定義されることなのでここでは割愛します
(対応するschemaから生成されるReaderのコードを読むと、解釈の方法が分かりやすいです)
pointerセクションは読み方がわかるはずなので、読んでみましょう
#####################################
# Streamのヘッダの情報
00000000 # セグメントの数は1つ
05000000 # セグメントのサイズは40byte
#####################################
# StructのPointer
00000000 # 種別は00(=struct), offsetも0
0100 # dataセクションのサイズは1ワード長
0100 # pointerセクションのサイズは1ワード長
#####################################
# Structのdataセクション(割愛)
08000000
00000000
#####################################
# Structのpointerセクション
00000000
01000100
#####################################
00000000
00000000
00000000
00000000
00000000
Discussion