Triton - Ensemble Modelsのオーバーヘッドの調査
Triton Inference Server の性能に関する調査を個人的に行っており,その結果をまとめていきます.読者としては,Triton のチュートリアルレベルの経験がある人を想定しています.Triton 初心者の方は,まずは こちら (Triton Inference Server とは?- Qiita) をご覧ください.
TL;DR
- Triton Inference Server の Ensemble Models におけるオーバーヘッドを検証をした.
- Ensemble を使って複数モデルを直列結合した場合,Monolithic な実装よりも実行時間が長くなった.また実行時間の遅延は,バッチサイズにも比例.
- Triton においてモデルの出力に対してコピー命令が実行されている模様.Ensemble でモデルを接続する場合,各モデルの出力に対してコピーが走るので,モデルの出力サイズに比例した遅延が発生する模様.
- Segmentation など主流力テンソルが大きくなる場合には注意が必要.
"Ensemble Models"に対する懸念点
Ensemble Models を使うことで簡単にパイプライン処理を構築できるが,モデル間のデータのやり取りなどに余分な処理が発生する.データのやり取りを Triton 側がやってくれることはメリットであるが,その部分は自由に触ることができない.
Latency が重要なサービスにおいては,このオーバヘッドが命取りになる可能性があるため,どの様なオーバヘッドが発生し,どのくらいの時間を消費するのか把握しておくことが必要である.
今回はこの点について調査を行った.
Triton Inference Server の "Ensemble Models" とは?
Ensemble Models は,Triton 上でホストされている複数のモデルを接続し,パイプライン処理を実装できる機能.クライアントからは 1 つのモデルとして見えるが,内部的には複数のモデルを組み合わせることで,全体として複雑な処理を行うことができる.個人的には,各モデルを独立に定義できることで,各モデルのメンテナンス性を向上させることができるのが,大きなメリットだと思う.特に,モデルは Tensor RT で実行できるが,前処理・後処理は Tensor RT 化できない(or 困難) なケースでは,前処理・推論・後処理をそれぞれ別のモデルとして定義することで,モデルの実行環境を柔軟に切り替えることが可能である.
Triton のスケジューラの一種として実装されており[1],中で動かすモデルは全て個別に定義する必要がある.
評価手法
-
conv2d1 層のみで構成されるダミーモデルを用意 - 同じモデルを,2 つの方法で直列結合したパイプラインを作成
- (Ensemble) Ensemble Models を使用して直列結合
- (Monolithic) Python Backend の
model.pyのハードコーディングで直列結合
- 2 つの結合方法で構成したモデルの実行時間の差分を確認
- (advanced) NVIDIA Nsight System を使って,各処理の所要時間を計測
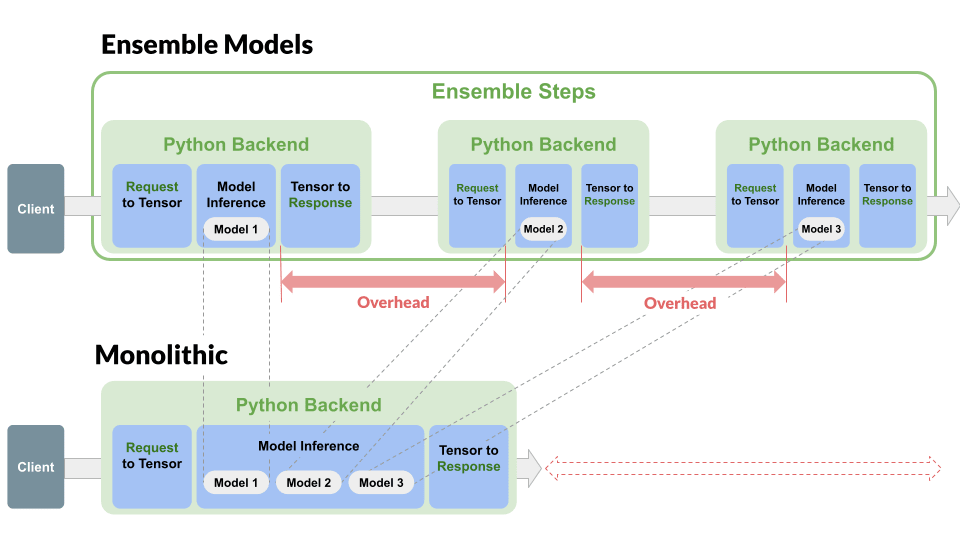
Pipeline Architecture. 3 つのモデルを直列する例.2 つの実行結果の差分を取ることによって,赤い部分のサイズを調査する.
(Ensemble) の実装例
config.pbtxt の ensemble_scheduling で同じモデルを複数回呼び出す.
ensemble_scheduling {
step [
{
model_name: "dummy_model"
model_version: -1
input_map {
key: "image_input"
value: "image_input"
}
output_map {
key: "image_output"
value: "image_output_m1"
}
},
{
model_name: "dummy_model"
model_version: -1
input_map {
key: "image_input"
value: "image_output_m1"
}
output_map {
key: "image_output"
value: "image_output"
}
}
]
}
(Monolithic) の実装例
Python Backend を使用して実装. model.pyのexecute() で以下の様に複数回モデルを呼び出す.
class TritonPythonModel:
def execute(self, requests):
...
# Inference (1st)
image_input = preproc_outputs[DUMMY_IMAGE_INPUT_TENSOR_NAME]
model_outputs = self.model(image_input)
# Inference (2nd)
image_input = model_outputs[DUMMY_IMAGE_OUTPUT_TENSOR_NAME]
model_outputs = self.model(image_input)
...
評価条件
- リクエストの Batch Size:
[1, 2, 4, 8] - Ensemble のステップ数:
[1, 2, 3, 4] - 入力: Full HD 画像
torch.Tensor(size=[batch_size, 3, 1080, 1920]) - Model: Conv2d 1 層 (入出力は同じサイズのテンソル)
なお,今回は Latency を見たいので,モデル側の Dynamic Batching は無効にした.
また,検証上は不要であるが,入出力は Cuda Shared Memory を使用し,Client と Triton 間でデータのコピー処理を無くした.
評価環境
- GCP
- マシンタイプ: g2-standard-4
- GPU: NVIDIA L4 x 1 (メモリ: 16GB)
- Triton
- Docker:
nvcr.io/nvidia/tritonserver:24.01-py3 - Backend: Python Backend
- Docker:
Code (GitHub)は後日公開予定.
結果
まずは,パイプライン全体の実行時間の図を示す.
「全体の実行時間 (Total Execution Time)」は,Client 側で計測したリクエスト送信から,結果を受信するまでの時間.結果は共有メモリにあるため,テンソルを読み出す処理は含まない.横軸の「Ensemble Steps」は,モデルの繰り返し回数 (i.e., conv2d の実行回数) である.
Bはバッチサイズ.
バッチサイズ 16 では,1 段増えると実行時間がおよそ 10ms 増加し,4 段のパイプラインになるとおよそ 40~50ms かかる.Ensemble Step 数が増えると,同じ処理の回数が増えるので,実行時間は線形に増加する.しかし,Monolothic に対して Enseble の実行時間の増え方は大きくみえる.
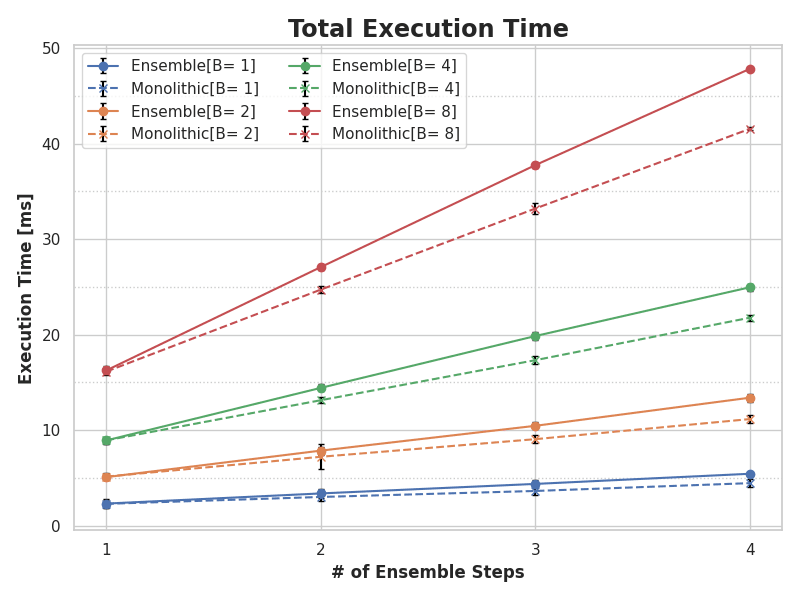
次に,Ensemble によって増加している Overhead 部分を調べるために,Ensemble の結果から Monolothic の結果を引いたもの (Ensemble の Overhead)を示す.どのバッチサイズもおおよそパイプラインの段数に対して線形にオバーヘッドが増加する.モデル以外では,メモリコピーなどバッチ数に関係する処理は行なっていないが,バッチ数が増えるとオーバーヘッドが増加している点が非常に気になる.Batch Size=8 の場合では,1 段増えるごとに 1.5ms のオバーヘッドが発生する.大きなバッチ数で運用する場合は,無視できなくなるのではないだろうか?

考察
grpcclient.InferenceServerClient.get_inference_statistics() を使うことで, Triton 内部の統計情報を取得することができる.Batch Size 2 と 8 の統計を比較すると,execute() が呼ばれる前の Triton 側の前処理 (compute_input) は大きく変わらないが,Triton 側の後処理 (compute_output) は 2 倍程度の時間がかかっている.出力のテンソルに何らかの処理が行われていると見られる.
| Pipeline | Batch Size |
compute_input [ms] |
compute_output [ms] |
|---|---|---|---|
| Ensemble (1 step) | 2 | 0.978 | 1.129 |
| Ensemble (1 step) | 8 | 1.178 | 2.030 |
より詳細に挙動を分析するために,プロファイラ (NVIDIA Nsight Systems)を使用して,Ensemble と Monolithic の挙動を比較する.下の二つの図は,4 段の Ensemble と Monolithic のリクエスト 1 つ分の推論結果である.また,nvtx を使用して,model.excute() 内の処理にタグをつけた (triton_execute, prepare_inputs, inference, prepare_outputs).
Triton は各モデルの後 (triton_executeラベルの外側) に,モデルの出力をそのまま使用せず,どこか別の領域にコピーしている模様である.Monolithic の結果では,conv2d 実行後に 1 回しかMemcpyが呼ばれないが,Ensemble の場合は各ステップ後にMemcpyが走っている.Memcpyの実行時間やコピーしているデータ量が一致することから,同じサイズのテンソルをコピーしていると考えられる.出力のテンソルが小さい場合は大きな問題にならないが,セグメンテーション結果などサイズが大き苦なる場合は,バッチサイズを大きくするとこの時間は無視できなくなってくる.逆に出力のテンソルサイズが小さい場合は,大きな影響を与えないのではないだろうか?

Ensemble (4 段, Batch Size 8)
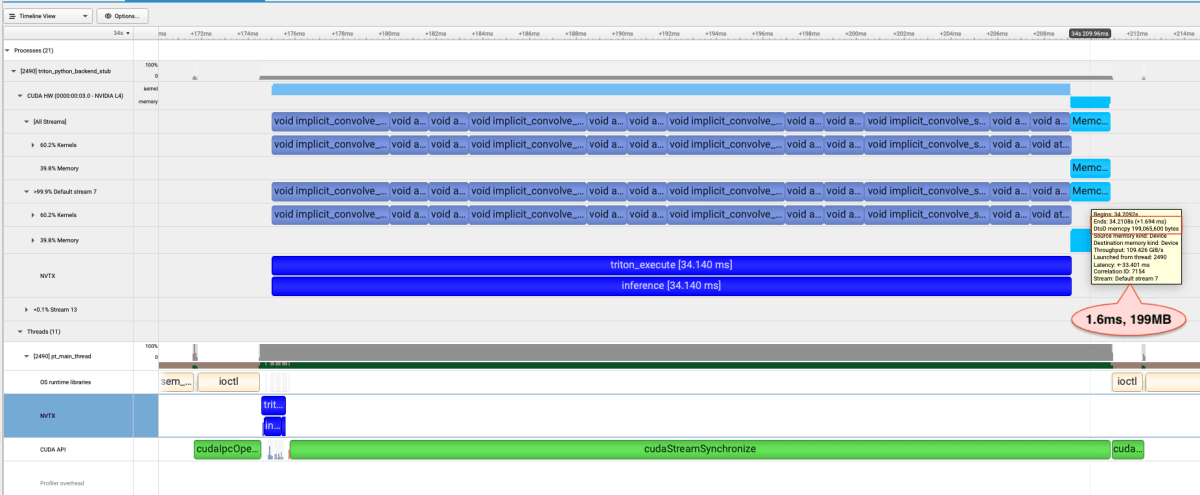
Monolithic (4 段, Batch Size 8)
一方で,dlpack から入力のテンソルを取り出す処理や,出力のテンソルを dlpack に変換する処理はとても早く (Batch Size= 8 で 50μs 程度),全体の速度提供への影響は無視しても良いと思われる.prepare_inputs[2] と prepare_outputs[3] は小さすぎて,添付の図ではほとんど確認できない.
理由は不明だが,Triton Python Backend の入力には FORCE_CPU_ONLY_INPUT_TENSORS というオプションがデフォルトで True になっている[4].出力においても似た何かが走っているのではないだろうか?この挙動が Python Backend 特有なものなのか,ONNX など他のバックエンドでも同様なのか調べておきたい.
まとめ
- Python Backend を使用した ensemble では,各モデルの後に出力テンソルのコピーが行われる.Monolithic なモデルに比べると,この部分が主な追加の処理時間となる.
- 出力テンソルが大きい場合,この出力テンソルのコピーに関する時間に配慮が必要である.
- dlpack[2:1][3:1][5] を用いたテンソルの受け渡し部分は,非常に小さい.特段の配慮はいらないと思われる.
Future Work
今回の実験を通して,追加で湧いてきた疑問を,自分用のメモとしてまとめておく.
- ONNX/TRT バックエンド使用時の Ensemble のオーバーヘッド
- 今回は前処理・後処理を Python で行うことを想定したため,Python Backend のみを対象にした.Request オブジェクトからのデータの取り出しはユーザ側の Python 実装になる.ONNX/TRT のバックエンドを使用した場合,このオーバーヘッドを減らせるのか検証したい.
- Ensemble Models におけるモデルの並列実行
- 上記の観察から, 出力のメモリコピーにより latency が増加することを確認した.モデルを並列実行した際に,コピー部分は他の処理とオーバーラップできて,全体では無視できるのか確認したい.
-
triton-inference-server/common/protobuf/model_config.proto において,
ensemble_schedulingはscheduling_choiceの選択肢の一つとしてある.他の選択肢は,dynamic_batching・sequence_batching. ↩︎ -
GitHub - Python Backend - Interoperability and GPU Support ↩︎
Discussion