はじめに
きっかけは、地理空間情報課ラボのアイデア募集「Q5 建物へのIDの付番」への取り組みの中で、以下の点に気づいたことでした。
-
Quadkeyは他の空間インデックス(GeohashやGoogleのOpen Location Code (Plus Codes))に比べて、同じレベルの範囲を表す際、桁数が長くなる
(以下の例では、Geohashが9桁、Open Location Codeが11(+1)桁のところ、Quadkeyは23桁となる) - 空間IDのタイルハッシュ形式(Z曲線)で高度(Floor)値がない場合は、Quadkeyの各桁を+1したものと同じになる
(以下の例では、Quadkeyのコード値が13300211231200101110210のところ、空間ID (TileHash)のコード値は24411322342311212221321となる)
東京駅付近の緯度・経度 35.675,139.762 の各ジオコード値(リンク)
| Geohash | Quadkey |
|---|---|
 |
 |
| Open Location Code | 空間ID (TileHash) |
|---|---|
 |
 |
桁数の短さだけではGeohashが最も短くなるものの、空間IDについては経産省の「3次元空間情報基盤アーキテクチャ設計 報告書」の p.36-40 にXYZタイル(4分割)とGeohash(32分割)との違いがかなり詳細に記載されていて、3次元空間でのボクセル表現にあたっては、各ズームレベルで8x4、4x8の順に長方形で32分割するGeohashよりも、QuadkeyなどのXYZ形式の方が優れているように思えたので、Quadkeyや空間IDのタイルハッシュ形式でコード値を短く圧縮する方法について考えてみました。
圧縮方式の検討
圧縮にあたっての要件
圧縮にあたっての要件としては以下のようなものを考えました。
- 圧縮後、元のコード値の復元が可能なこと (=可逆圧縮であること)
- 圧縮状態でも、元のコード値が備えている、前方一致検索性能を保持すること
- 圧縮状態でのソート時に、元のコード値と同じ順序となること
4進数から16進数への変換
Quadkeyは各桁が0-3の4進数(2ビット)、空間IDのタイルハッシュ形式(Z曲線)も高度(Floor)値が0の場合は各桁が1-4となり、各桁を-1すれば4進数となるので、圧縮方式としては4進数の各桁を先頭から2桁(=2x2ビット)ずつ取り出して16進数(4ビット)に変換する方法を考えました。
(圧縮効率面からは、他にBase32(5ビット)、Base64(6ビット)なども可能かもしれませんが、可変桁の場合の複雑さが増すと思われたため、16進数(4ビット)を選択しました。)
先ほどのズームレベル23では少し長くなるので、以下の例ではズームレベル16にまで落としています。
Quadkeyのズームレベル16の場合の変換
| 桁数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4進数 | 1 | 3 | 3 | 0 | 0 | 2 | 1 | 1 | 2 | 3 | 1 | 2 | 0 | 0 | 1 | 0 |
| 2進数 (2ビット) | 01 | 11 | 11 | 00 | 00 | 10 | 01 | 01 | 10 | 11 | 01 | 10 | 00 | 00 | 01 | 00 |
| 桁数 | 1 - 2 | 3 - 4 | 5 - 6 | 7 - 8 | 9 -10 | 11-12 | 13-14 | 15-16 |
|---|---|---|---|---|---|---|---|---|
| 2進数 (4ビット) | 0111 | 1100 | 0010 | 0101 | 1011 | 0110 | 0000 | 0100 |
| 16進数 | 7 | c | 2 | 5 | b | 6 | 0 | 4 |
ズームレベルが16で偶数の場合は、2桁ずつ取り出して変換することができるので、16進数にピッタリ変換することができますが、ズームレベル16から一つ落としたズームレベル15の場合はどうでしょう?
Quadkeyのズームレベル15の場合の変換
| 桁数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4進数 | 1 | 3 | 3 | 0 | 0 | 2 | 1 | 1 | 2 | 3 | 1 | 2 | 0 | 0 | 1 |
| 2進数 (2ビット) | 01 | 11 | 11 | 00 | 00 | 10 | 01 | 01 | 10 | 11 | 01 | 10 | 00 | 00 | 01 |
| 桁数 | 1 - 2 | 3 - 4 | 5 - 6 | 7 - 8 | 9 -10 | 11-12 | 13-14 | 15- |
|---|---|---|---|---|---|---|---|---|
| 2進数 (4ビット) | 0111 | 1100 | 0010 | 0101 | 1011 | 0110 | 0000 | 01 |
| 16進数 | 7 | c | 2 | 5 | b | 6 | 0 | ? |
上のように最後の桁が半分(01)となってしまい、16進数に無理に変換しようと 00 を追加して 0100 とし、16進数に変換して 4 となっても、他の16進数文字と区別がつかなくなってしまいます。
4進数が奇数桁の場合の対応
解決策として、最初は 00 を追加して16進数文字に変換した後、末尾に何らかの文字(u, m や < など)を追加して、それらの記号が末尾にある場合は、4進数での桁を1つ(2進数では2ビット分)戻すような方法を考えてました。(u は upper、m は middle の頭文字で、< は左側に1桁戻すイメージから来ています。)
Base64で用いられるフィラー(=)とは意味合いが異なりますので、レデューサー(Reducer)のような命名を考えていました。
上の例では、00 を追加して 0100 で16進数で 4 となり、レデューサーに u を利用の場合は末尾が 4u となります。
既存事例の調査
上記の辺りで少し行き詰まり、これまでで同じような課題に取り組んだ事例がないか、おもむろにChatGPTのDeepResearchで調べてみたところ、以下の記事・論文を見つけました。
1つ目のGIS StackExchangeの Peter Krauss さんの回答では、S2 Geometryのキーの一部がbase4(4進数)で表現されていること、また、16進数への圧縮にあたって、奇数桁の場合には、半桁(half digit)の部分にbase16(16進数)を拡張した J, K, L, M を当てる方法が紹介されていました。
Suggestion for base16 encoding
About convert "Face/Face_pos" to hexadecimal, is possible for example convert the base4
10002200to hexa40a0, but base4 with more one digit will result in entirely different (or invalid) hexadecimal; for example100022003results in102801... The "more one digit" ocurrs when you compare for example level 18 keys with level 19 keys.To avoid this problem, an extra digit must be added by a extend base16 algorithm.
function base4_to_base16(str) { const tr = {"0":"00","1":"01","2":"10","3":"11"} let strBin='' for(let i of str.split('')) strBin += tr[i] return BigInt('0b'+strBin).toString(16) } function base4_to_base16h(str) { const tr = {"0":"J","1":"K","2":"L","3":"M"} let len = str.length if (len % 2 == 0) return base4_to_base16(str); let h = base4_to_base16( str.slice(0,-1) ) // cut last return h+tr[ str.slice(-1) ] } var key = S2.latLngToKey(i.lat, i.lon, level); [face,face_pos] = key.split('/'); keyHex = face + base4_to_base16h(face_pos)
2つ目の同じ Peter Krauss さんの論文では、4進数=>16進数への変換だけでなく、より汎用的に、2進数や8進数からの変換にも対応した Base16h が定義されていて、4進数からの変換の場合の拡張文字としては H, M, R, V を利用しているようでした。
論文内ではGitHubリポジトリも紹介されていて、JavaScript(ESM形式)のAPIとPostgreSQLのストアド(PL/pgSQL)関数の実装もあるようでした。
圧縮状態でのソート順の問題
既存事例・実装があるので、それをそのまま利用するnpmパッケージを作成しても良いようにも思いましたが、要件の3つ目で上げていた「圧縮状態でのソート時に、元のコード値と同じ順序となること」を満たすかを確認したところ、拡張文字がASCII・Unicodeコード上で16進数に利用される文字コード([0-9a-f])よりも大きくなることにより、ソート順が元のコード値と異なってしまうことがわかりました。
JavaScriptでの例:
// 元の4進数コード値
const quadKeys = [
'13300211231200', // ズームレベル14
'133002112312001', // ズームレベル15
'1330021123120010', // ズームレベル16
];
console.log(quadKeys.sort());
// => ['13300211231200', '133002112312001', '1330021123120010']
// 圧縮後の16進数コード値
const hexKeys = [
'7cb5260', // ズームレベル14
'7cb5260K', // ズームレベル15
'7cb52604', // ズームレベル16
];
console.log(hexKeys.sort());
// => ['7cb5260', '7cb52604', '7cb5260K'] <= ズームレベル14,16,15の順になってしまう
PostgreSQLでの例:
SELECT quadkey FROM (
VALUES
('13300211231200'), -- ズームレベル14
('133002112312001'), -- ズームレベル15
('1330021123120010') -- ズームレベル16
) AS t(quadkey)
ORDER BY quadkey;
-- =>
-- quadkey
-- ------------------
-- 13300211231200
-- 133002112312001
-- 1330021123120010
-- (3 rows)
SELECT hexkey FROM (
VALUES
('7cb5260'), -- ズームレベル14
('7cb5260K'), -- ズームレベル15
('7cb52604') -- ズームレベル16
) AS t(hexkey)
ORDER BY hexkey;
-- =>
-- hexkey
-- ----------
-- 7cb5260
-- 7cb52604
-- 7cb5260K <= ズームレベル14,16,15の順になってしまう
-- (3 rows)
なお、上記のソート順の問題は、拡張文字利用時だけでなく、レデューサー文字利用時にも発生します。
JavaScriptでの例:
// 圧縮後の16進数コード値
const hexKeys = [
'7cb5260', // ズームレベル14
'7cb52604u', // ズームレベル15
'7cb52604', // ズームレベル16
];
console.log(hexKeys.sort());
// => ['7cb5260', '7cb52604', '7cb52604u'] <= ズームレベル14,16,15の順になってしまう
PostgreSQLでの例:
SELECT hexkey FROM (
VALUES
('7cb5260'), -- ズームレベル14
('7cb52604u'), -- ズームレベル15
('7cb52604') -- ズームレベル16
) AS t(hexkey)
ORDER BY hexkey;
-- =>
-- hexkey
-- -----------
-- 7cb5260
-- 7cb52604
-- 7cb52604u <= ズームレベル14,16,15の順になってしまう
-- (3 rows)
インジケータ記号(#)を利用したソート順の問題の解消
圧縮後もソート順を保持するには、次の桁が16進数文字最小の 0 から始まった場合も、その前に並ぶように、ASCII・Unicodeコード上で 0 より前の文字を利用する必要がありそうです。
ASCIIコードの印字可能範囲、もしくはUnicodeコードの U+0020 - U+007F 範囲は、下表のようになります。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 20 | SP | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 30 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 40 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 50 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 60 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 70 | p | q | r | s | t | u | v | w | x | y | z | { | \ | } | ~ | DEL |
ASCII・Unicodeコード上で0より前の文字は限られていて、 !, " , #, $, %, &, ', (, ), *, +, ,, -, ., / の15文字(記号)です。
ケースとしてはあまりないかもしれませんが、ファイル名やフォルダ名としても利用することを想定した場合、Windowsファイルシステムの予約文字 <, >, :, ", /, \, |, ?, * に含まれる文字は外した方が良さそうです。
また、正規表現で利用される文字 (, ), *, +, ., ?, {, }, [, ], ^, $, | に含まれる文字も外したほうが良さそうです。
各文字(記号)の利用可能性についてまとめたところ、以下の表のようになりました。
| ASCII・Unicodeコード | 文字(記号) | 利用可能性 | 備考 |
|---|---|---|---|
| 0x21 | ! |
o | |
| 0x22 | " |
x | Windowsファイルシステム予約文字 |
| 0x23 | # |
o | |
| 0x24 | $ |
x | 正規表現 (行の末尾) |
| 0x25 | % |
o | |
| 0x26 | & |
o | |
| 0x27 | ' |
o | |
| 0x28 | ( |
x | 正規表現 (グループ化) |
| 0x29 | ) |
x | 正規表現 (グループ化) |
| 0x2A | * |
x | Windowsファイルシステム予約文字 正規表現 (直前の要素の0回以上の繰り返し) |
| 0x2B | + |
△ | 正規表現 (直前の要素の1回以上の繰り返し) 後述の空間IDの高度(Floor)成分の符号として利用 |
| 0x2C | , |
o | |
| 0x2D | - |
△ | 後述の空間IDの高度(Floor)成分の符号として利用 |
| 0x2E | . |
x | 正規表現 (任意の1文字) |
| 0x2F | / |
x | Windowsファイルシステム予約文字 |
利用可能な文字として !, #, %, &, ', , の6文字が残りましたが、これらから4文字を先の拡張文字 J, K, L, M の代わりに当てるのは難しいように思えましたので、意味合い的にURLのページ内(アンカー)リンク指定やMarkdownの見出しにも利用される # を半桁のインジケータとして利用し、直後には 0, 1, 2, 3 の4進数文字をそのまま当てることにしました。
(他に、桁と桁の中間の意味合いから、10進数で小数部との区切りに利用される . の利用も検討しましたが、少数部が 0.0 から 0.f まで上がった後に 1.0 となってしまう(=小数部が実質16分割となる)ことから見送りました。)
Quadkeyの場合、並びはZ階数曲線となることから、ズームレベル偶数時は16分割([0-9a-f])となるところ、ズームレベル奇数時は4分割で # の後にZ曲線順の4進数文字(0, 1, 2, 3)を当てはめれば良いので、直感的にも分かりやすいように思えました。

ソート順の問題も、以下の通り、解消していることを確認できました。
JavaScriptでの例:
// 圧縮後の16進数コード値
const hexKeys = [
'7cb5260', // ズームレベル14
'7cb5260#1', // ズームレベル15
'7cb52604', // ズームレベル16
];
console.log(hexKeys.sort());
// => ['7cb5260', '7cb5260#1', '7cb52604'] <= ズームレベル順が維持される
PostgreSQLでの例:
SELECT hexkey FROM (
VALUES
('7cb5260'), -- ズームレベル14
('7cb5260#1'), -- ズームレベル15
('7cb52604') -- ズームレベル16
) AS t(hexkey)
ORDER BY hexkey;
-- =>
-- hexkey
-- -----------
-- 7cb5260
-- 7cb5260#1 <= ズームレベル順が維持される
-- 7cb52604
-- (3 rows)
空間IDのタイルハッシュ形式(Z曲線)で高度(Floor)値がある場合の対応
次に、空間IDのタイルハッシュ形式(Z曲線)で高度(Floor)値がある場合の対応を考えます。
東京駅付近の緯度・経度 35.675,139.762、高度 10000 m、ズームレベル16の空間IDは以下のようになります。
- ZFXY形式:
16/19/58210/25808 - タイルハッシュ形式(Z曲線):
2441132234271165
タイルハッシュ形式(Z曲線)では、以下の公式SDKのREADME.mdに記載の通り、 北西下、北東下、南西下、南東下、上などの8方向 となっていて、下段の後に上段が続く形となっています。
以下のサイトにある、Z曲線の3次元の場合の画像イメージがとても分かりやすいです。

画像引用元: https://note.g2-studios.net/n/nfbc1d878fc78
上段にある 4, 5, 6, 7 は、8進数(3ビット)の最上位ビットとなるため、以下の手順で各桁をYX成分とF(高度)成分に分け、それぞれを16進数に変換した後、F(高度)成分を +/- の符号に続けて末尾に追加する形としました。
| 手順 | 内容 | データ |
|---|---|---|
| 1 | 元データ | 2441132234271165 |
| 2 | 各桁を-1して8進数に変換 | 1330021123160054 |
| 3 | 8進数を2進数に変換(桁数が元データ桁数 の3倍に満たない場合は先頭を0埋め) |
001 011 011 000 000 010 001 001 010 011 001 110 000 000 101 100 |
| 4 | 各桁内の3ビットをYX成分(2-3ビット目)とF(高度)成分(1ビット目)に分割 | YX成分: 01 11 11 00 00 10 01 01 10 11 01 10 00 00 01 00F成分: 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 1
|
| 5 | YX成分は4進数から16進数に変換、 F成分は2進数から16進数に変換 |
YX成分: 0111 1100 0010 0101 1011 0110 0000 0100 => 7cb52604F成分: 0000000000010011 => 13
|
| 6 | YX成分末尾にF成分を+/-の符号に続けて追加 |
7cb52604+13 |
F成分の 13 は、ZFXY形式の 16/19/58210/25808 の2節目のF値 19 の16進数表現に相当するため、正しく変換できていることが分かります。
16進数部分先頭へのxの追加
上記で圧縮時に追加で利用する記号 #, +, - が決まりましたが、最後に圧縮前後のコード値の区別を容易にするため、圧縮後の16進数部分の先頭に16進数の略字として良く用いられる x (Hexadecimalのx)を追加することにしました。
npmパッケージの作成と公開
圧縮方式についての方針が決まったので、以下のZenn記事や地理情報関連のGitHubリポジトリを参考に、pnpmとViteのライブラリモードでnpmパッケージの作成を行いました。
参考にしたZenn記事
pnpm create vite@latest からのViteライブラリモードのテンプレート選択手順や、 tsconfig.json の修正、buildスクリプトの修正など、基礎的なViteライブラリモードでのパッケージ作成手順は以下のZenn記事を参考にしました。
参考にした地理情報関連のGitHubリポジトリ
npmパッケージのAPI設計やライブラリ・デモ用のVite設定(vite*.config.ts)、Vitestでのテストコード作成は、以下のGitHubリポジトリを参考にしました。
作成したGitHubリポジトリとnpmパッケージ
一からのnpmパッケージ作成は初めてのトライアルでしたが、上記のZenn記事やGitHubリポジトリを参考にしつつ、ChatGPTやGitHub Copilotの助けも借りて、何とかリリースまでたどり着くことができました。
作成したGitHubリポジトリとnpmパッケージ、デモイメージ・URLは以下となりますので、興味のある方は是非御覧ください。
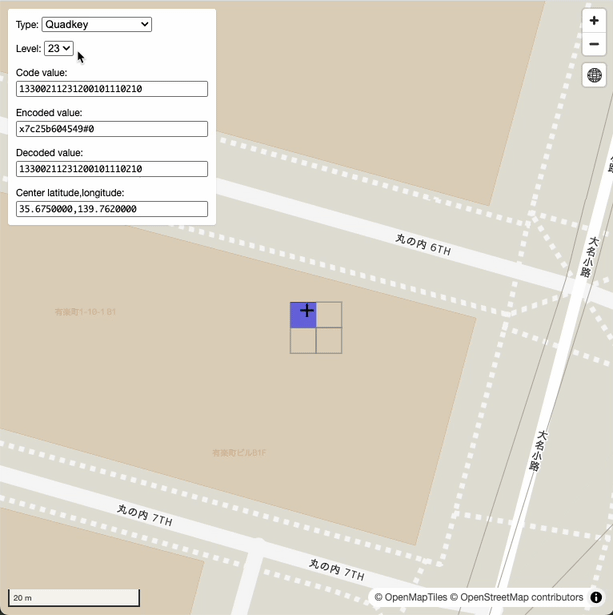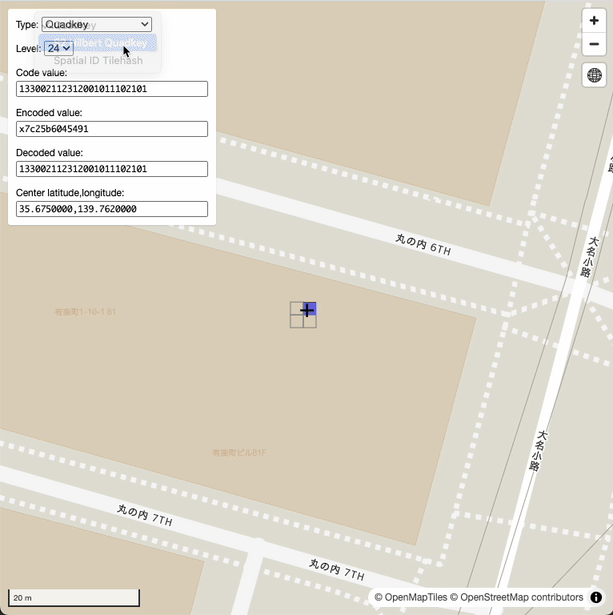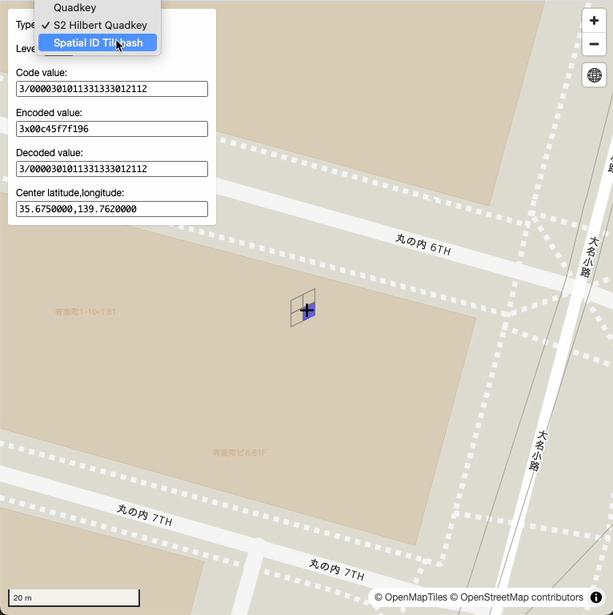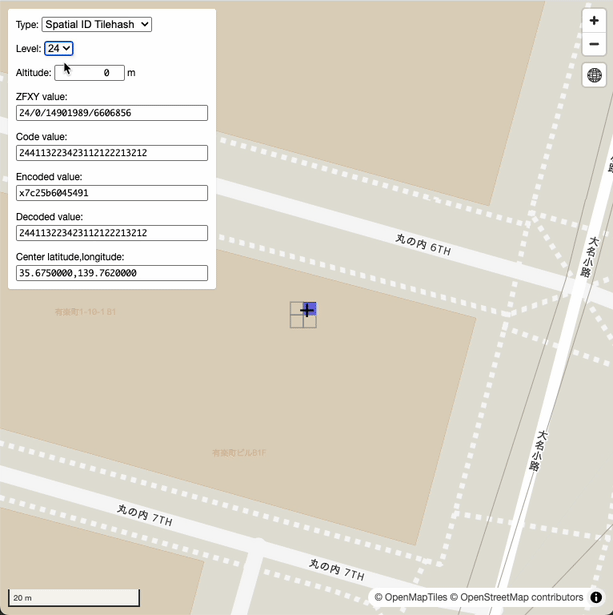
デモURL: https://sanak.github.io/quad-hexer/
おわりに
以上、ざっととなりますが、空間インデックス(Quadkey・S2・空間ID)の4進数表現部分を16進数に可逆圧縮するnpmパッケージの作成についてまとめました。
GitHubリポジトリのコードの方は、正規表現でのフォーマットチェックと、文字列ベースの愚直な変換処理となっていて、ビット演算の導入などでパフォーマンス改善やGo・Rustなどの他言語への移植性も高まるかもしれませんが、この辺りは今後の課題としたいと思います。

Discussion