金融マーケットデータの最適化:Snowflake上での生成AI向けTickデータによる時系列分析のイノベーション(翻訳)
この記事はSnowflakeでの僕の同僚のChris Napoliの以下の記事の翻訳です。
皆さん、こんにちは!先に断っておきます、これはSnowflakeで「0から生成AIへ」というテーマで、金融でのトレーディングのデータ、分析、レポートの高度化などを私たちがここに至るまでの物語も少し見ながら書いた記事でちょっと長いです。
右に目次があるので必要に応じて特定のトピックにスキップしてください。サマリーまで行っていただければこちらのトピックをカバーしているウェビナーにサインアップやYouTubeの動画も見れます。
はじめに
今年の8月、私は自分の人生の半分を金融サービス業界のデータと分析に費やしてきたことを思い出させる誕生日を迎え、2000年代初頭の大学卒業後の若き日のことを懐かしく思い出しました。それは2008年の金融危機が影を落とす前の、若々しい希望と野心に満ちた日々でした。ヤンキースのほぼ毎年のワールドシリーズ優勝とブロードウェイでのティッカーテープパレードを懐かしく思い出します。窓から流れるティッカーテープの光景は、祝賀と成功の象徴でした。現在のヤンキースの状態をしばしば考える一方で、この記事で考えているのは別のテーマで「あのパレードのティッカーテープはどうなったのだろう?」です。
ティッカーテープは、その後20年で世界が物理的データからデジタルデータへと移行するにつれて、徐々にTickデータへと進化しました。取引所データのデジタル化は分析をよりアクセスしやすくし、その使用を金融のフロント、ミドル、バックオフィス全体に広げました。これらの進歩は金融のトレーディングで今年8月やこの9月に私たちが目撃したような市場のボラティリティが高まる期間中に、テクニカルパターンを分析して利益を生み出す機会を創出しました。そしてまたレガシーシステムでリスク分析をしている金融機関の損失リスクも表面化されました。ティッカーテープは私たちの日常のプロセスに深く根付いています。
この記事のタイトル「金融マーケットデータの最適化」は、金融サービスでSnowflakeを長年使用しているユーザーには不思議に思えるかもしれません。Snowflakeは既にクロス・クラウドのコラボレーション(別のクラウドサービス同士を接続可能にする機能)やSonwflakeマーケットプレースにより複雑なデータパイプラインの必要性を排除しましたよね?もちろんその通りですが、Snowflakeはこの分野でさらに革新を続けており、データ転送の領域だけに焦点を当てることは2021年にソフトウェア史上最大のIPOとなった後も広範な開発と進歩を続けるSnowflakeを大幅に過小評価することになるのです。
SnowflakeのAIデータクラウドプラットフォームの進歩を探求する前に、Tickデータの本質、その使用法、そして過去20年間にこのデータを分析する上で浮上した課題を理解することが重要です。
ここを理解すれば、組織がビジネスのユースケースをSnowflakeのフィナンシャル・データクラウドに移行することによりどのようにこの課題を対処できるかということに興味が持てるはずです。
Tickデータとは?
Tickデータとは、特定の市場でのすべての個々の取引やトランザクションに関する詳細な情報を提供する金融マーケットデータを指します。これには以下が含まれます:
- タイムスタンプ:取引が実行された正確な時間
- 価格:取引が実行された価格
- ボリューム:取引に関与した株式または契約の数量
- 取引識別子:取引のユニークな識別子
グローバル金融のダイナミックな世界では、膨大な取引データを処理・分析することが競争力を維持するために不可欠です。複数の資産クラスにわたって1日200万件以上の取引を実行する大手資産運用会社は、投資の決断やポートフォリオを最適化するために高度なデータ分析に依存しています。これらの取引は株式、債券、デリバティブ、その他の資産にまたがり、重要なデータで彼らが対処しなければならないさらに広範な市場のデータの一部です。
Tickデータは、数十年にわたって蓄積された膨大な金融情報の宝庫です。市場活動の最も細かな視点を提供し、各取引をその都度キャプチャします。Tickデータは、高頻度取引、市場分析、アルゴリズム取引の日常業務に不可欠ですが、この記事では秒単位以上のストリーミング時間枠でのデータ分析について議論します。Tickのヒストリカルデータの最大のリポジトリは、6ペタバイト以上のデータを保存しており、40年以上の市場の履歴を表し、500以上の世界中の取引所と取引プラットフォームをカバーしています。平均的な日では、少なくとも7つの主要な資産クラスにわたって驚異的な600億件の取引が実行されます。この膨大な日々の取引とヒストリカルのTickデータは、金融サービス企業がバックテストやトレーディングの戦略など市場分析や複雑な計算を実行するために重要です。
ヒストリカルのTickデータの膨大な規模と深さは、市場の専門家にとって大きな機会を提供します。このデータを効果的に活用することで、貴重なインサイトを引き出し、投資のパフォーマンスを向上させ、今日の金融市場の複雑さの中で重要な優位性を持つことが可能です。
Tickデータは、Sybase、SQL Server、Oracle、Pinecone、Kdbなどのデータベースに保存できるデータセットで、Tickデータフィードを通じて提供されるデータの例は以下のとおり:
取引データ
市場のすべての取引をキャプチャし、トランザクションに関する詳細な情報を提供
気配値データ
気配値データには、最良の買い(ビッド)と売り(アスク)の価格とサイズに関する情報が含まれ、市場の現在の買いと売りの関心を反映
個別注文
各注文に関する詳細な情報で、価格、サイズ、注文タイプ(指値、成行など)を含む
時間と販売データ
各取引の時間、価格、ボリュームを含む、取引の時系列記録(ナノ秒単位まで)
レベル I データ(トップオブブック・データ)
最良の買い・売り価格、サイズ、最新の取引情報を提供します。
レベル II データ(市場の深さ)
オーダーブックのデータとも呼ばれるレベル IIデータには、最良価格を超えるさまざまな買い・売り価格に関する情報が含まれます。市場の供給と需要のより包括的なビューを提供します。
レベル III データ(注文フロー)
利用可能な最も詳細な情報を含み、個々の市場参加者の行動へのインサイトを提供
金融でTickデータがよく使用されているのは?
トレーディングのライフサイクルとオペレーションに関わり、Tickデータは金融業界でセルサイド側(銀行、証券)、アセットマネージメント&アセットオーナー(バイサイド側)、および規制当局によって使用されています。セルサイドとバイサイドでは市場 / Tickデータは3つの主要なオフィスセグメント全体で使用されています:
フロントオフィス(収益を生み出すセグメント)
Tickデータはフロントオフィスでさまざまな方法で使用されています。本記事の範囲外ではありますが、日々のアルゴリズム取引や高頻度取引のプロセスでよく使用されます。本記事の範囲内としては、マーケットメイカーとしての機能を支援しトレーダーがビッド・アスクスプレッドを動的に調整することを可能にします。また、定量分析や取引戦略のバックテストにも不可欠であり、ライブの市場状況での戦略のパフォーマンスを評価します。
定量的リサーチ
Tickデータは、定量的リサーチプロセス全体で使用されます。例えば:戦略のバックテスト、アルゴリズム取引と高頻度取引の開発、市場のマイクロストラクチャー分析、流動性とボラティリティの分析、イベント分析
デスクの損益(P&L)モニタリング
トランザクションコスト分析とその出力は、フロントオフィスが監視するP&Lの計算の中で重要な一部です。すべてのデータソースを同じシステムに持つことで、より正確でタイムリーな分析と執行のためのシグナルを作成し、リアルタイムに近いP&Lを可能にします。
ミドルオフィス(リスク、ポジション&トランザクション管理)
同じTickデータは、ミドルオフィスでのリスク管理とコンプライアンスモニタリングにも使用されます。自社の取引と注文データとともに、リスクの閾値や規制要件の遵守を確保するためにトレーディングをリアルタイムで確認します。Tickデータはまた、取引の照合や確認を含むポストトレード分析をサポートし、不一致や潜在的な問題の検知を可能にします。さらに、リスク評価やパフォーマンス評価のためのレポートを生成し、トレーディングが企業の全体的なリスク管理フレームワークと一致することを保証します。
トランザクションコスト分析&最良執行
トランザクションコスト分析(TCA)には取引を執行するコストの評価が必要です。これは、手数料、コミッション、取引比較(Volume Weighted Aevrage Price[VWAP]、Time Weighted Average Price[TWAP])、執行のタイミングなどの明示的なコストや、市場への影響やスリッページなどの暗黙的なコストを含みます。
リスク管理
Tickデータは、市場、カウンターパーティ、流動性リスクの監視などリスク管理フレームワーク全体で資産やその関係者のモニタリングなどさまざまなアプリケーションを持っています。堅牢なリスク管理プログラムは、ヘッジ戦略を作成することで潜在的な損失を軽減し、ブック全体の未知のエクスポージャーを表面化し、逆の価格変動や市場でのカウンターパーティまたは流動性リスクへの潜在的なエクスポージャーのシグナルを提供します。
バックオフィス(エンタープライズおよびオペレーションでのセグメント)
Tickデータは、多極的に接続された金融機関内での規制報告やコンプライアンスにおいて重要な役割を果たします。フロントおよびミドルオフィスで使用されるTickや取引データでの分析を可能にし、財務、コンプライアンス、オペレーションなどのバックオフィス機能全体で一貫性を保ちます。
取引コンプライアンス&規制報告
Tickデータは、MARなどの規制の下での市場悪用を監視・防止するために、取引コンプライアンスで重要な役割を果たします。リアルタイムの監視、異常検出、取引活動のフォレンジック調査を可能にする詳細なタイムスタンプ付き記録を提供し、不審な行動を特定・調査するのに役立ちます。さらに、Tickデータは、MiFID IIなどの規制報告をサポートし、検出された活動と企業のコンプライアンス作業の記録を可能にします。
顧客報告
顧客報告は、金融業務における透明性と信頼のために重要であり、取引活動、投資パフォーマンス、コストに関する詳細な更新を含みます。Tickデータは、正確な取引確認、包括的なポートフォリオパフォーマンスレポート、コストの透明性を提供し、個々の顧客のニーズに合わせたカスタマイズされたレポートを作成することを可能にします。
Tickデータの分析における課題とは
過去20年間の技術的な制限により、Tickデータを企業全体で使用する際に多くの技術的な課題が生じました。これらの課題は、フロント、ミドル、バックオフィス全体で運用上の問題を引き起こし、フロントオフィスでのアルファ / 利益の創出の機会の損失、市場リスクや規制上の問題による評判リスクなど、ミドルおよびバックオフィス全体でリスクを増大させました。
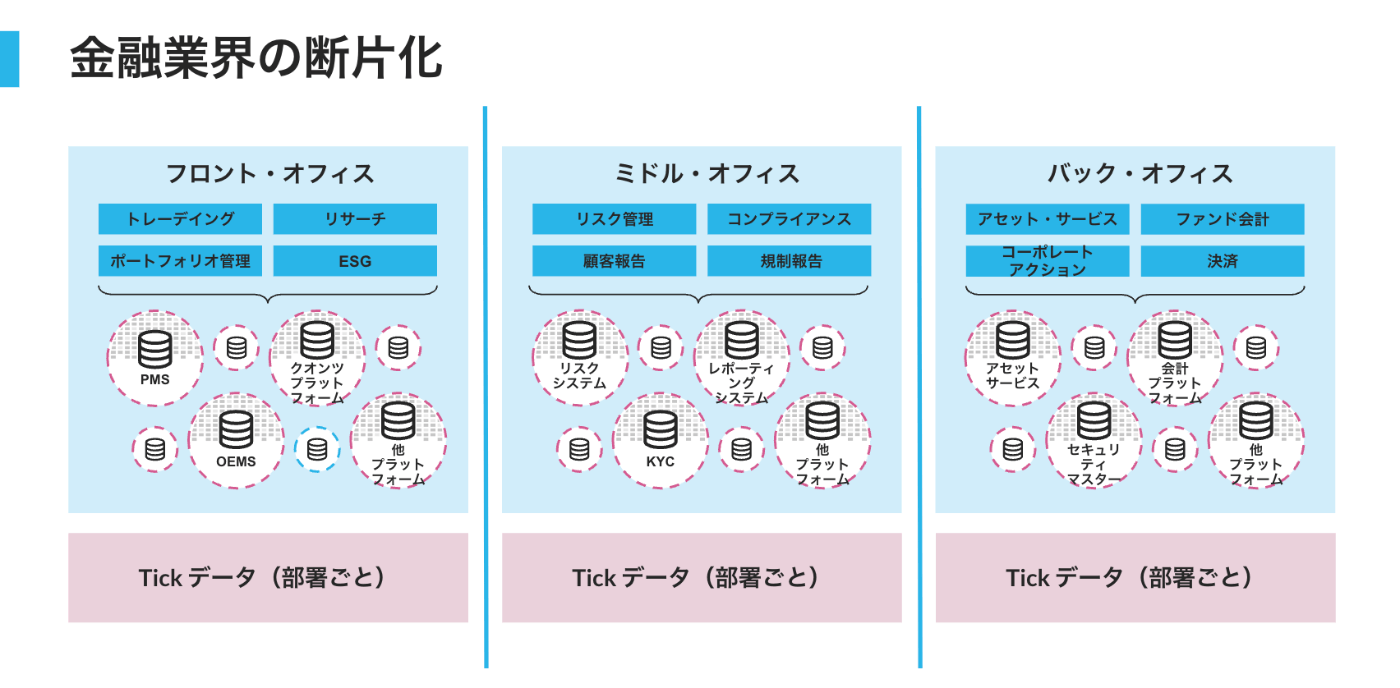
データのパイプライン問題:Tickデータは合成や結合が非常に難しく、正確な市場活動をキャプチャするためには多数のデータプロバイダーが必要な場合があります。これらのETL(抽出、変換、ロード)パイプラインの管理とメンテナンスは、データ分析の有形および無形のコストを増加させます。
ストレージとコンピュートの制限問題:ヒストリカルなTickデータは非常に大きく(数ペタバイトのデータ)、特定のデータベースの種類や固有のフォーマットを持つ場合があり、時間とともにデータ量が増加します。追加の市場分析やより多くのデータセットが必要になると、ストレージとコンピュートの制限が意思決定に必要な時間に影響を与えます。
タイムスタンプの分析の難しさの問題:Tickデータ分析で最もイライラする部分の一つは、ミリ秒単位で特定の時間範囲にわたってデータを分析する必要があることです。エンドユーザーの要件に応じて、しばしば異なるシステム、データベース、オブジェクト指向/手続き/計算言語を必要とします。
フロント、ミドル、バックオフィス間でのデータのサイロの問題:必要となるTickデータは、システムごと、デスクごと、地域ごとに異なり、ビジネスプロセスごとに使用されます。内部と外部の両方で異なるデータサイロが発生し、重複したコストやステークホルダーへの報告の不正確さをもたらします。
計算要件のサイロ化による計算リソースのクラスター化問題:フロント、ミドル、バックオフィス全体のユースケースには、トレーダー、ポートフォリオマネージャー、ビジネスアナリスト、データサイエンティスト、財務など、さまざまなビジネスユーザーペルソナがあります。各々が異なるデータ頻度と閲覧要件を持ち、コンピュート時間はリアルタイムに近いものからバッチ分析まで。アクセスや表示もノートブック、スプレッドシート、ダッシュボード、データアプリケーションなど様々なものがあります。
このプロセスをクラウド型AIデータプラットフォームへの移行を可能にする最近の技術革新
クラウドコンピューティングの進歩により、ほぼ無制限のCPUパワーがもたらされ、ストレージ所有のコストが削減されました。ETLからELT(抽出、ロード、変換)への移行は、データの流動性と意思決定までの時間を改善するのに役立ちました。しかし、クラウドコンピューティングだけではすべての課題を解決せず、短期的な視野のアーキテクチャやハイパースケーラーの相互運用性の新たなサイロ化などの追加の課題を生み出しました。
ストレージとコンピュートの分離、およびコンピュート間の分離:Snowflakeのクラウド型データプラットフォームは、2014年にストレージとコンピュートを分離することで最初の革新を生み出しました。これにより、計算エンジンをデータ自体から分離し、同時処理を可能にし、オンプレミスのバッチ処理のボトルネックを解消し、最終的にはフロント、ミドル、バックオフィス全体で1つのデータソースをマルチクラウドのインフラで金融機関が活用できるようになりました。

2022年より、Snowparkへの革新により、Snowflakeのアーキテクチャのマネージドサービスのインテリジェンスレイヤーはコンピュート同士も分離し、データを組織内で移動することなく、異なる言語を並行して実行するためのクラスターを自動的にスピンアップおよびダウンさせます。
より簡単なコラボレーション:過去2年間で、Factset、ICE、BMLLなどのTickデータプロバイダーが、Snowflake マーケットプレイスとSnowflake Native Applicationsにデータアプリとマーケットプレイスリスティングを追加しています。さらに多くのサードパーティプロバイダーが参入予定です。これにより、データ共有の多数の利点(圧縮されたストレージ、データレプリケーション)を活用して、オンプレミスのデータセットとワークロードをクラウドに移行することができます。Snowflakeのユーザー定義関数(UDF)やSQLおよびPythonのストアドプロシージャを共有したり、新しい分析コプロセッサであるRelational.aiとのグラフ分析をが可能になるなど、すべてのステークホルダー間のより簡単なコラボレーションを可能にする強化されたエコシステムが、マルチクラウド環境での次の革新を進めます。
生成AI:ベクトル化は生成AIの重要な要素であり、モデルが機能し、出力を改善するのに役立ちます。SnowflakeはAIデータクラウドの開発を推し進め、Snowflake内のデータのベクトル化関連の開発により、時系列データをデータ処理に使用される個別の特殊なベクトルデータベースなしでより簡単に集約できるようになりました。SnowflakeにはVECTOR関数があり、Snowparkを介してベクトルベースのPython UDFやライブラリパッケージを活用できます。これにより、組織はビジネスユースケースに必要な言語でTickデータをエンジニアリングおよび分析できます。
Cortexは、Snowflake内でLLMのデプロイ、管理、ファインチューニングを容易にするSnowflakeのマネージドサービスです。ファインチューニングのコストとタイムラインを削減し、NVIDIAとの拡大パートナーシップにより可能になった必要なGPUへの直接アクセスを提供します。最新のCortex Analyst機能のリリースにより、ドメイン固有の時系列対応のLLMやコパイロットの存在する世界が間もなく到来するでしょう。
(集計)時系列機能:SnowflakeはSQLにネイティブな一連の機能に大きく投資し、時系列データをナノ秒単位で簡単に集計および分析できる機能であるASOF Join、Time_Slice関数が2024年6月にSnowflakeでリリースされました。これは、特定の時間範囲にわたってデータを分析する必要があるという、Tickデータ管理の主要な課題の一つを軽減します。エンドユーザーの要件に応じて、これはしばしば異なるシステム、データベース、オブジェクト指向/手続き/計算言語を必要とします。しかし、SnowflakeはAIデータクラウドで時間範囲の結合とマイクロセグメント化をネイティブに簡素化しました。さらに、SnowflakeはネイティブのML機能に大きく投資し、ヒストリカルデータからの予測を簡素化しています。
(集計)Snowpark — Anaconda用のPythonパッケージ:
SnowflakeのSnowpark for Pythonのリリースにより、既存のPythonコードをSnowflakeに移行しヒストリカルのTickデータの分析に活用ができます。さらにSnowflakeのSnowparkに最適化されたウェアハウスの開発により、メモリ処理速度が向上し非常に計算力を必要とする業務やオーケストレーションを可能にします。またSnowflakeのKxとのパートナーシップを通じてPyKXパッケージをインストールすることもできます。これによりオンプレミスのqコードをクラウドに移行し、Snowflake上のTickデータを活用してユーザーフレンドリーなPythonファーストのインターフェース通じqプログラミング言語の速度で金融でのモデル開発が可能です。
ダイナミックテーブル機能:この新しい製品機能により、テーブルのポスティングやアクセスなしで分析結果をより迅速に取得でき、リアルタイム処理速度が重要なワークロードのクエリパフォーマンスが向上します。
Streamlit:SnowflakeのStreamlitの買収により、数行のPythonコードで内部アプリケーションを開発する時間を短縮し、データアプリの迅速な開発が可能になりました。
なぜ今行動すべきか?
金融市場と規制環境はとても変化のスピードが早く、クラウドでこのプロセスを再構築することで、運用上および市場のアルファを生成し、リスクとコストを軽減する多数の理由があります:
セキュリティ&ガバナンス — 意思決定までの時間:新しい戦略、デスク、資産クラスを立ち上げるための意思決定の迅速化は、直接的にAUM(運用資産残高)とアルファに影響しますが、可能な限り最も安全でガバナンスが効く環境で行う必要があります。Snowflakeのフィナンシャル・データクラウドの暗号化された環境内に計算のコードを移動することで、速度と精度の両方が暗号化された圧縮ストレージ内のデータで実現できます。
マクロ経済環境 — 資本コスト:オンプレミスのソフトウェアとハードウェアの所有そしてメンテナンスコストを削減することは、経費の資本コストが増加する今の世界において高く優先されます。これらは埋没費用ではなく、資本を解放し、それに応じて再利用する機会を提供します。
マクロ経済要因 — 市場のボラティリティ:最近の8月と9月の市場のボラティリティは、銀行・証券や資産運用会社にとって収益成長とパフォーマンスの主要な推進力をトレーディングデスクに提供しましたが、リスク管理フレームワークを近代化する必要があるという早期警告信号でもあります。
市場と技術の規制:データ、インフラストラクチャ、報告に関する膨大な数の市場と技術の規制(FRTB、GDPR、CCPA、CAT、DORAなど)は、テクノロジー組織にレガシーワークロードを再構築する必要性を要求し、将来施行される可能性のある規制に対して将来性を確保する機会を提供します。
競争環境 / ディスラプション:金融におけるトレーディングはゼロサムゲームであり、一方が勝てば他方が負けますが、時間がゲームの定義に貢献します。クラウドコンピューティング時代以降に生まれた新しい市場参加者は、これらの技術的進歩の一部をすでに活用して、ニッチなビジネスを開拓し、既存のプレーヤーから市場シェアを奪っています。金融機関は、既存の収益を保護しながら、新しい収益源を多様化するために、すべてのビジネス機能全体でデジタルトランスフォーメーションを行う必要があります。
セルサイドとバイサイド側の両方の組織が現在、Snowflakeと協力して、ビジネスユースケースのためにTickデータのプロセスの近代化に貢献しています。是非この機会にあなたもこの変革の機会にご参加をご検討ください。
可能性を実現する力(Art of the Possible)
私たちの言葉を鵜呑みにする必要はありません。マーケットプレイスからTickデータを取得し、Snowflake Notebooksを活用してスリッページ計算をSQLやPythonで実行することや、エンドユーザーがStreamlitのシンプルなデータアプリケーションで分析期間の設定を自分で変えられるようになること、はイメージがわくでしょうか?ウェビナーにサインアップして、これがどのように可能かを説明します。また、待ちきれない方のためにこのYouTubeビデオも用意しています。
まとめ
もう一度ヤンキースの優勝の喜びを味わうにはしばらく時間がかかるかもしれませんが(どうか近いうちに)、それが起こったときにブロードウェイのオフィスからティッカーテープが投げられることはおそらくないでしょう。20年前と同様に、確かなことはテクノロジーが進化し続けることです。私たちには、生産性を向上させ、時代の先を行くために、新しいテクノロジーを私たちのプライベートやビジネスに取り入れる機会があります。
Snowflakeでは、市場を分析し、顧客の声に耳を傾け、トレンドを観察し、未来のためのプラットフォームを設計しています。セルサイドとバイサイドの組織が現在、企業全体でTickデータのプロセスを近代化するために私たちと協力しています。私たちはこの新しい変革の取り組みをモジュール型に設計しているので、マーケットデータの引き込みからエンドユーザー向けのアプリケーションの開発まであなたがこの変革の「旅」のどの段階でも、どの課題を経験していても私たちはサポートできます。
是非ご一緒に金融業界で変革を起こしていきましょう。
Discussion