TL;DR
- AWS の ECSコンテナのログをBigQueryに転送する
- タスク定義に FireLens のサイドカーコンテナを設定
- Workload Identity 連携を使用して、GCPの認証情報をイメージ内に含めないように工夫
はじめに
初めまして。株式会社ジーニーの GENIEE CHAT開発チームのマネージャーを担当しています。
GENIEE CHATでは各サービスのログをBigQueryに保存しており、調査や分析を行う用途として使用しております。
今回は、n番煎じですが ECSのコンテナログを BigQuery に転送する方法に関して調査と検証を行ったので、対応内容と注意点を記載したいと思います。
FireLensとは?
ECSのタスクで出力されたコンテナログのルーティングを行うためのAWS公式ツールです。
サイドカーコンテナとしてタスク定義に含めることで、タスクから出力されたログを fluent-bit や fluentd を介して、必要な場所にコンテナログを送信することができます。
Firelens の発表 – コンテナログの新たな管理方法 | Amazon Web Services ブログ
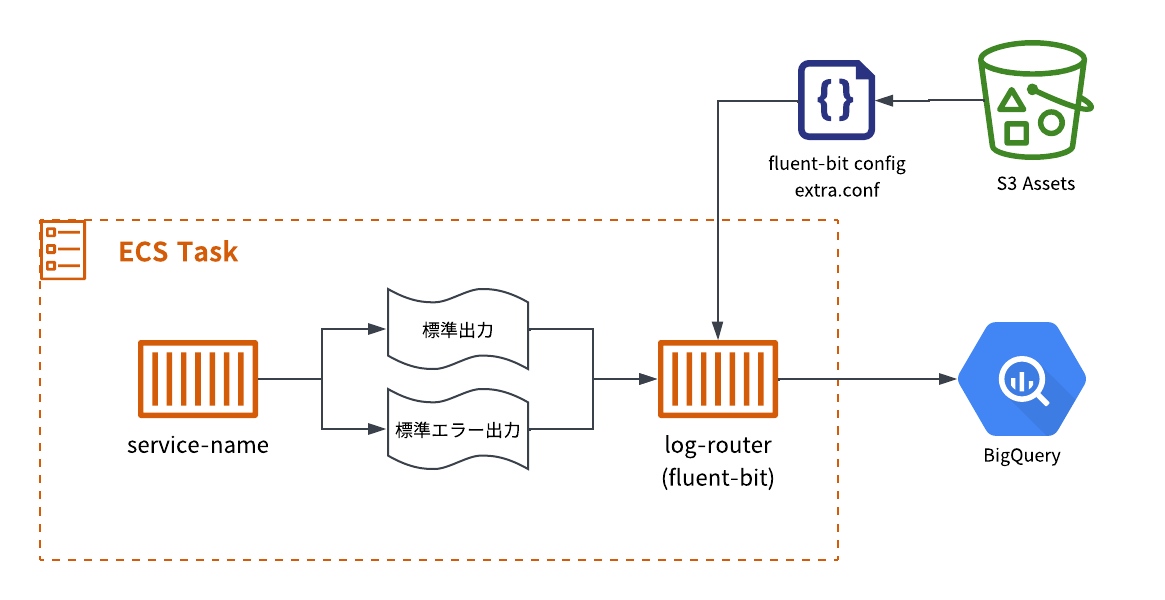
全体像
全体像は以下のようになっています。
ECSのタスク定義は対象のサービス+ログのルーティングを行うサイドカーコンテナで構成されており、
サービスで出力されたコンテナログ(標準出力・標準エラー出力)はサイドカーコンテナに送られます。
サイドカーコンテナとしては AWS公式の Fluent Bit イメージを使用しており、 Fluent Bit の設定ファイルをS3から読み込むように設定します。
設定ファイルにはBigQueryの指定したテーブルに送信するように設定します。
実装
実装には AWS CDK + TypeScript を使用して、インフラの設定をコード上で管理できるようにします。
AWS CDK 上の設定
実際のコードを説明用に関数化しています。
FireLens の設定に関連する設定を部分的に説明します。
import * as s3assets from 'aws-cdk-lib/aws-s3-assets';
import * as ecs from 'aws-cdk-lib/aws-ecs';
import * as ecr from 'aws-cdk-lib/aws-ecr';
import * as iam from 'aws-cdk-lib/aws-iam';
import * as logs from 'aws-cdk-lib/aws-logs';
import * as path from "path";
import { Construct } from 'constructs';
interface ECSContainerProps {
cpu: number;
memoryLimitMiB: number;
environment: { [key: string]: string; };
containerPort: number;
hostPort: number;
}
export const CreateECSTask = (
scope: Construct,
environment: string,
taskName: string,
serviceName: string,
taskExecutionRole: iam.Role,
ecrRepository: ecr.Repository,
taskRole: iam.Role,
containerProps: ECSContainerProps,
): ecs.Ec2TaskDefinition => {
const task = new ecs.Ec2TaskDefinition(scope, `${taskName}-task`, {
networkMode: ecs.NetworkMode.AWS_VPC,
taskRole: taskRole,
executionRole: taskExecutionRole,
});
task.defaultContainer = task.addContainer(`${taskName}-default-container`, {
containerName: serviceName,
image: ecs.ContainerImage.fromEcrRepository(ecrRepository, "latest"),
cpu: containerProps.cpu,
memoryLimitMiB: containerProps.memoryLimitMiB,
environment: containerProps.environment,
logging: ecs.LogDrivers.firelens({
options: {},
}),
portMappings: [{
containerPort: containerProps.containerPort,
hostPort: containerProps.hostPort,
}],
});
// FireLens の設定ファイルを S3 にアップロードする
const asset = new s3assets.Asset(scope, `${taskName}-firelens-config`, {
path: path.join(__dirname, serviceName, environment, "extra.conf"),
});
task.addFirelensLogRouter(`firelens-log-router`, {
firelensConfig: {
type: ecs.FirelensLogRouterType.FLUENTBIT,
},
environment: {
aws_fluent_bit_init_s3_1: `arn:aws:s3:::${asset.s3BucketName}/${asset.s3ObjectKey}`,
},
image: ecs.ContainerImage.fromRegistry(
"public.ecr.aws/aws-observability/aws-for-fluent-bit:init-2.32.2.20240425"
),
logging: ecs.LogDrivers.awsLogs({
streamPrefix: "log-router",
logRetention: logs.RetentionDays.ONE_WEEK,
}),
cpu: 128,
memoryLimitMiB: 128,
});
// 設定ファイルの取得に関するロールを追加
taskRole.addToPolicy(
new iam.PolicyStatement({
actions: [
"s3:GetObject",
"s3:GetBucketLocation",
],
resources: [
`arn:aws:s3:::${asset.s3BucketName}`,
`arn:aws:s3:::${asset.s3BucketName}/*`,
],
effect: iam.Effect.ALLOW,
})
);
return task;
};
デフォルトコンテナの設定
task.defaultContainer = task.addContainer(`${taskName}-default-container`, {
containerName: serviceName,
image: ecs.ContainerImage.fromEcrRepository(ecrRepository, "latest"),
cpu: containerProps.cpu,
memoryLimitMiB: containerProps.memoryLimitMiB,
environment: containerProps.environment,
logging: ecs.LogDrivers.firelens({
options: {},
}),
portMappings: [{
containerPort: containerProps.containerPort,
hostPort: containerProps.hostPort,
}],
});
ECSタスクに対して、デフォルトコンテナとして対象サービスを明示的に設定しています。
サイドカーコンテナを使用する場合など、1つのタスク定義に複数のコンテナを含める場合、どれがデフォルトのコンテナになるのか明示的な指定が必要になります。
(何も指定しないと、最初に定義したコンテナがデフォルトコンテナになりますが、明示的に指定する方が好ましいと考えています。)
Fluent Bit の設定ファイルをS3に配置
考慮ポイントは「複数のマイクロサービスでFluent Bitの設定ファイルをどのように管理するか」という点です。
Fluent Bitの設定ファイルをカスタマイズするには以下の二つの方法があります。
- ファイルから設定を読み込む
- S3のオブジェクトから設定を読み込む
1の場合だと、設定ファイルをイメージ内に含めるパターンが考えられます。
ただし、複数サービスを運用しており、設定ファイルを個別に設定する必要がある場合、サービス毎にカスタムイメージを作成する必要になります。
2の場合、設定ファイルをS3に配置する必要がありますが、カスタムイメージの作成は不要になり、イメージの管理コストが浮きます。
そのため、今回は 2. S3のオブジェクトから設定を読み込む を採用しました。
設定ファイルの配置は、aws-cdk-lib/aws-s3-assets を利用すると簡単に設定できます。
// FireLens の設定ファイルを S3 にアップロードする
const asset = new s3assets.Asset(scope, `${taskName}-firelens-config`, {
path: path.join(__dirname, serviceName, environment, "extra.conf"),
});
フォルダ構成は以下のようになっており、複数サービスのログ周りの設定を共通化しています。
(以下の例では ecsTask.ts 内に CreateECSTask 関数が定義されているイメージ)
ecsTask.ts から設定ファイルの相対パスは サービス名/リリース先の環境/extra.conf で統一しており、フォルダ構成にもルールを設けています。
├── service-name-aaa
│ ├── production
│ │ └── extra.conf
│ └── staging
│ └── extra.conf
├── service-name-bbb
│ ├── production
│ │ └── extra.conf
│ └── staging
│ └── extra.conf
└── ecsTask.ts
FireLens コンテナの設定
対象サービスのタスク定義に、FireLens のサイドカーコンテナの設定を追加します。
コンテナイメージは公式のものを使用しており、環境変数で aws_fluent_bit_init_s3_1 を指定しています。
環境変数を通じて、ファイルまたはS3のオブジェクトから Fluent Bit の設定を読み込むことができるようになっており、aws_fluent_bit_init_file_[数字] または aws_fluent_bit_init_s3_[数字] のような形で読み込む順番、ソースを指定できます。
設定ファイルの読み込みなど初期化プロセスに関しては README や ソースコードを読むと理解が深まります。
logging は Fluent Bit のログの出力先に関する設定になります。
この設定の場合、CloudWatch Logs に Fluent Bit のログが出力されるようになっています。
CPUやメモリのリソースはサービスのログの出力量を考慮して、控えめに設定しています。
task.addFirelensLogRouter(`firelens-log-router`, {
firelensConfig: {
type: ecs.FirelensLogRouterType.FLUENTBIT,
},
environment: {
aws_fluent_bit_init_s3_1: `arn:aws:s3:::${asset.s3BucketName}/${asset.s3ObjectKey}`,
},
image: ecs.ContainerImage.fromRegistry(
"public.ecr.aws/aws-observability/aws-for-fluent-bit:init-2.32.2.20240425"
),
logging: ecs.LogDrivers.awsLogs({
streamPrefix: "log-router",
logRetention: logs.RetentionDays.ONE_WEEK,
}),
cpu: 128,
memoryLimitMiB: 128,
});
S3から設定を読み込むため必要なポリシーをタスクロール(タスク実行ロールではない)に設定しています。
// 設定ファイルの取得に関するロールを追加
taskRole.addToPolicy(
new iam.PolicyStatement({
actions: [
"s3:GetObject",
"s3:GetBucketLocation",
],
resources: [
`arn:aws:s3:::${asset.s3BucketName}`,
`arn:aws:s3:::${asset.s3BucketName}/*`,
],
effect: iam.Effect.ALLOW,
})
);
FireLens の設定
FireLens のログルーターとして、fluentd か fluent-bit を選べますが、推奨の fluent-bit を採用しました。
コンテナの標準出力、標準エラー出力がデフォルトで転送されるため、 INPUT の設定は省略しており、FILTER と OUTPUT のみ設定しています。
FILTER
Lua のフィルターを利用して、ログの出力フィールドにタイムスタンプとサービス名を出力する設定を追加しています。
設定は以下のような形になりました。
[FILTER]
Name Lua
Match *
call append_fields
code function append_fields(tag, timestamp, record) new_record = record new_record["ts"] = os.date('%Y-%m-%d %H:%M:%S', timestamp) new_record["service"] = "service-name" return 1, timestamp, new_record end
ワンライナーで設定内に記載していますが、共通化できる設定や複雑な設定は Script と Call を利用して、外部の Lua ファイルの関数を呼び出す方式にした方が良さそうです。
OUTPUT
この項目では、BigQueryにログを転送する設定を記載しております。
Google Cloud BigQuery | Fluent Bit: Official Manual
把握している限りで、Fluent Bit から BigQuery にアクセスを行う方法として二つあります。
- サービスアカウントキーを発行して、JSONファイルを指定する
- Workload Identity 連携を使用してアクセス権を取得
1 の場合、ビルドイメージ内またはボリュームのマウント経由でサービスアカウントキーの設定ファイルを取得する必要があると考えました。
認証情報をディスク上、イメージに含めるのはセキュリティ上の懸念があり、今回は 2 を選びました。
設定は以下のような形になりました。
[OUTPUT]
name bigquery
match *
project_id project-name
dataset_id dataset-name
table_id ecs_service_logs
ignore_unknown_values true
# Workload Identiy Provider の設定
enable_identity_federation on
aws_region ap-northeast-1
project_number 123456789012
pool_id aws-access-pool
provider_id aws-role-name
google_service_account aws-firelens-service-name@project-name.iam.gserviceaccount.com
設定を書く上でハマりそうになった注意点が二つあります。
- ドキュメントが一部誤りがある
- Workload Identity 連携の必須設定項目がドキュメント上で不明
たまたま興味本位で設定の読み込みとデータをどのように送信しているか、リトライは実装されているかなど確認していたため、自分の場合はソースコードから確認を進めていました。
そのため、自分は無事回避できました。
1.ドキュメントが一部誤りがある
ドキュメントには、enable_workload_identity_federation と書いてあるが、実際の設定キー名は enable_identity_federation になっている。
2.Workload Identity 連携の必須設定項目がドキュメント上で不明
BigQuery のプラグインの使用時に、Workload Identity 連携を行う場合以下の設定項目が必要です。
aws_regionproject_numberpool_idprovider_idgoogle_service_account
ソースコードから必要な設定項目を確認していたため、つまづくことはなかったのですが以下に該当箇所を載せておきます。
if (ctx->has_identity_federation) {
if (!ctx->aws_region) {
flb_plg_error(ctx->ins, "`aws_region` is required when `enable_identity_federation` is true");
return NULL;
}
if (!ctx->project_number) {
flb_plg_error(ctx->ins, "`project_number` is required when `enable_identity_federation` is true");
return NULL;
}
if (!ctx->pool_id) {
flb_plg_error(ctx->ins, "`pool_id` is required when `enable_identity_federation` is true");
return NULL;
}
if (!ctx->provider_id) {
flb_plg_error(ctx->ins, "`provider_id` is required when `enable_identity_federation` is true");
return NULL;
}
if (!ctx->google_service_account) {
flb_plg_error(ctx->ins, "`google_service_account` is required when `enable_identity_federation` is true");
return NULL;
}
}
最終系
最終系の設定ファイルはこんな感じです。
SERVICEはAWS公式の詳解 FireLensを参考に設定していますが、サービスに応じて調整余地はあると思います。
[SERVICE]
Flush 1
Grace 30
[FILTER]
Name Lua
Match *
call append_fields
code function append_fields(tag, timestamp, record) new_record = record new_record["ts"] = os.date('%Y-%m-%d %H:%M:%S', timestamp) new_record["service"] = "service-name" return 1, timestamp, new_record end
[OUTPUT]
name bigquery
match *
project_id project-name
dataset_id dataset-name
table_id ecs_service_logs
ignore_unknown_values true
# Workload Identiy Provider の設定
enable_identity_federation on
aws_region ap-northeast-1
project_number 123456789012
pool_id aws-access-pool
provider_id aws-role-name
google_service_account aws-firelens-service-name@project-name.iam.gserviceaccount.com
Workload Identity 連携 の設定
GCP側で Workload Identity 連携を行うために必要な設定は以下のとおりです。
- サービスアカウントの作成
- Workload Identity プール/プロバイダの作成
- サービスアカウントの権限借用を使用してアクセス権を付与
詳細は割愛しますが、ポイントを紹介します。
サービスアカウントの作成
サービスアカウントの作成と権限の付与を行います。
複数サービスで権限を共通化するために、 ロールを作成して、サービスアカウントに付与するようにしています。

ロールには以下の権限を付与しています。
- bigquery.datasets.get
- bigquery.tables.get
- bigquery.tables.updateData

Workload Identity プール/プロバイダの作成
AWSプロバイダ用の Workload Identity プールを作成しました。
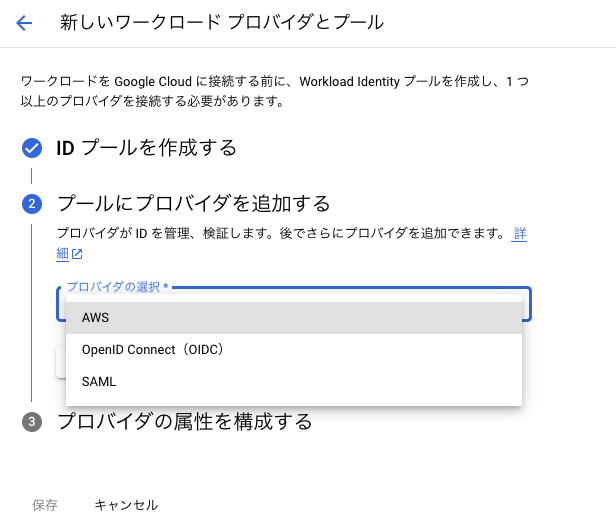
詳細はAWS または Azure との Workload Identity 連携を構成する | IAM Documentation | Google Cloud を参考にして設定しています。
サービスアカウントの権限借用を使用してアクセス権を付与
作成した Workload Identity プール の詳細画面から「アクセスを許可」を選択して、指定したAWSのロールに対して許可を追加します。

具体的には aws_role に arn:aws:sts::アカウントID:assumed-role/ロール名 を設定します。
最後に
ドキュメントに誤りがあったり、設定ミスがあった場合に実際にタスクをデプロイするまでわからないことが多いなどいくつかハマると辛い点がありますが、他の人の参考になれば幸いです。
実際のサービスでは Firehose を利用しているサービスがある、標準出力・標準エラー出力以外のログをどうするかなど課題もあるため、今後も検証を続けていきたいです。
参考リンク
AWS公式
AWS CDK
- CDKで複数コンテナのECSタスクを作成する際はDefaultコンテナの指定を忘れずやろう|スクショはつらいよ
- ECS FargateでFireLens(AWS for Fluent Bit)の設定ファイルをS3から参照してみた | DevelopersIO
FireLens
- Fargate でも使える!FireLens の init プロセスを活用して設定ファイルを S3 から読み込む - kakakakakku blog
- aws-for-fluent-bit/use_cases/init-process-for-fluent-bit/README.md at mainline · aws/aws-for-fluent-bit · GitHub
- aws-for-fluent-bit/init/fluent_bit_init_process.go at mainline · aws/aws-for-fluent-bit · GitHub
Fluent Bit
Workload Identity 連携

Discussion