GENIEE RECOMMENDでインフラとバックエンドを担当している新卒2年目の櫻井です。
本記事では、GENIEE RECOMMENDにおける機械学習パイプラインの導入とVertexi AI Pipelinesについて紹介します。
特に、Kubeflow Pipelinesを用いた柔軟なパイプラインの実装について説明します。
GENIEE RECOMMENDと推薦システム
GENIEE RECOMMENDは、売上順やPV順など画一的なロジックのみならず、ユーザ一人ひとりの行動をAIが学習・分析し、独自のロジックによりユーザの好みにパーソナライズされた商品提案サービスです。
推薦システムには大きく分けて以下の2つの推薦方式があります。
- リアルタイム推薦: ユーザーのリアルタイムな行動に基づいてリクエスト時に商品を推薦する
- バッチ推薦: 定期的にユーザーに対して商品を推薦する
どちらの方式も、最新の行動データや商品データを使用するために定期的な推薦モデルの再学習や推薦結果の更新が必要になります。
機械学習パイプラインの導入
背景
機械学習パイプラインを導入する前は以下のような課題がありました。
- 各データ処理ステップに適したマシンリソースの割り当てが難しい
- データ処理ステップの並列化に伴うメモリ使用量や処理制御の複雑さ
- 各データ処理ステップで生成される生成物の容量確認が難しい
- 前処理後の行動データや商品データや推薦モデルなど
- 問題の特定に時間がかかる
これらの課題を解決するために、Google CloudのVertex AI Pipelinesという機械学習パイプラインの導入を進めました。
導入によるメリット
機械学習パイプラインの導入により、以下の点が改善されました。
- 各データ処理ステップに適したマシンリソースを割り当てることが可能に
- 行動データはデータサイズが大きいためRAMを16GBから32GBに増加
- 推薦アルゴリズムごとの適切なRAM,vCPUの割り当て
- DAG(有向非巡回グラフ)による依存関係の記述で各ステップが自動的に並列化される
- パイプラインがDAGで構成されることで依存関係のないステップが並列で実行され実行時間の短縮に繋がる
- 各ステップで生成される中間生成物の容量をGUIから確認可能
- Vertex AI Pipelinesはパイプラインの実行状況がGUIで可視化される
- GUIで各ステップで作成された生成物がGCSに保存され、内容を確認できる
- 中間生成物を取得して調査することで、問題の特定までの時間が短縮
- 前処理後のテーブルデータなどはGCSに保存されるため、個別にダウンロードしローカルで内容を調査することができる
次は、これらを実現することができたVertex AI Pipelinesについて紹介していきます。
Vertex AI Pipelines とは
Vertex AI Pipelinesは、Google Cloudが提供する機械学習向けのワークフローツールです。
パイプラインを実行するとこのように実行の様子が可視化されます。
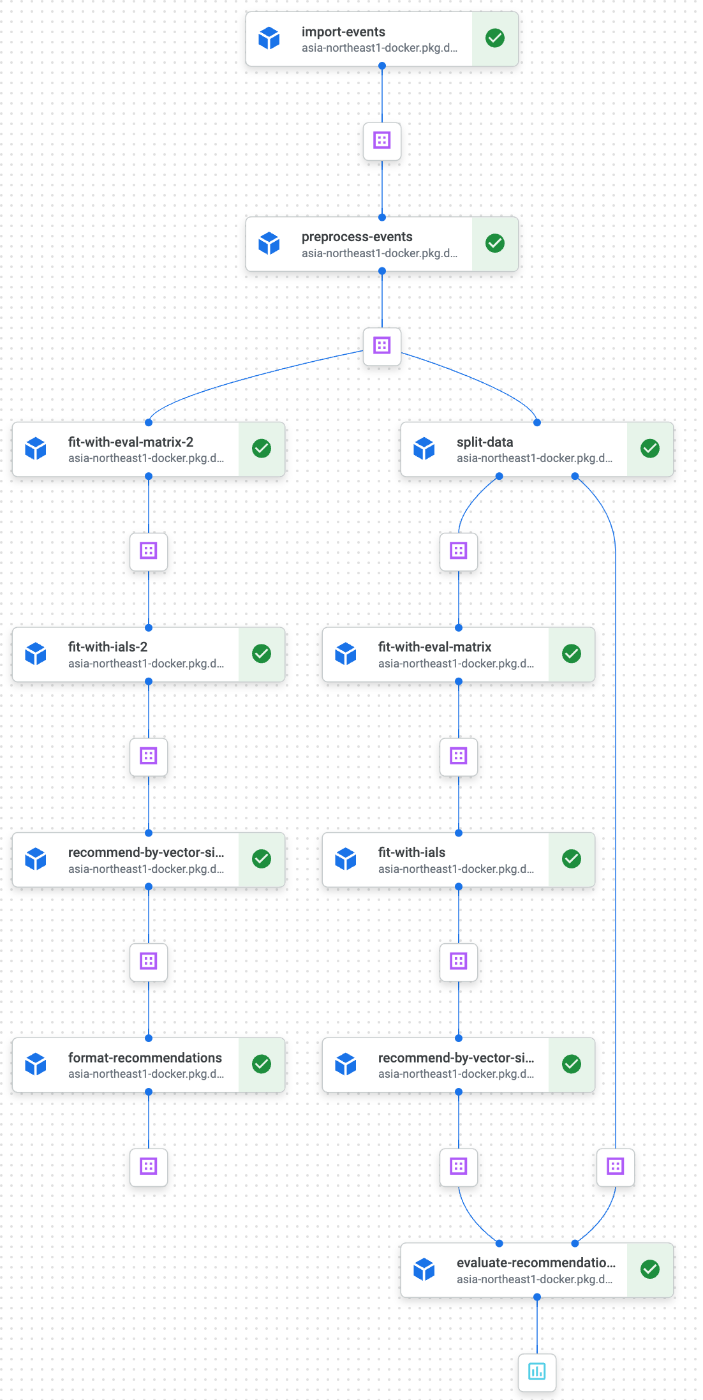
パイプラインの可視化
Vertex AI Pipelinesには以下の特徴があります。
- サーバレスコンテナ実行環境(Vertex AI Training Job): OSやインフラの管理が不要で、パラメータ設定のみでステップごとにスペックを変更可能
- Dockerコンテナでの実行: ワークフロー内の各ステップがDockerコンテナで実行され、ローカルでの開発や動作確認が容易
同様のワークフローを実行管理できるサービスとしては AWS Step Functions + AWS Batch、Apache Airflow、MLFlowなどがあります。
Vertex AI PipelinesがサポートするMLフレームワークは以下の2つがあります。
- Kubeflow Pipelines
- TensorFlow Extended
GENIEE RECOMMENDでは、Kubeflow Pipelinesを採用しています。Kubeflow Pipelinesは、シンプルなPythonで実装するコンポーネントや任意のDockerコンテナを実行できる柔軟なコンポーネントがあります。また、必要に応じてVertex AI PipelinesからKubernetesに移行することも可能かと思われます。
Kubeflow Pipelines の構成要素
パイプラインの実装時に使用するPythonライブラリのKubeflow Pipelinesについて詳細を説明していきます。
Kubeflow Pipelinesは、以下の主要な構成要素から成り立っています。
- パイプライン: ワークフローの一連の処理のまとまり
- コンポーネント: 前処理やモデルトレーニング、結果のフィルターなど、ワークフロー内の1ステップを実行
- アーティファクト: コンポーネントによって出力されるデータやモデル、メトリクスなど
パイプラインの記述例
以下はKubeflow Pipelinesを使用したパイプラインの記述例です。
importerという外部のアーティファクトをインポートするコンポーネントを使用してデータを読み込み、polarsでデータ処理をしています。
from kfp import dsl
from kfp.dsl import Input, Output, Dataset
# データを処理するコンポーネント
@dsl.component(
packages_to_install=["polars"],
base_image="python:3.10"
)
def process_data(input_data: Input[Dataset], output_data: Output[Dataset]):
# ここに処理内容を記述
pass
# パイプライン定義
@dsl.pipeline(
name="Data Processing Pipeline with Polars",
description="A pipeline that processes data using Polars in Python 3.10 environment."
)
def data_pipeline(data_url: str):
# importerを使用してデータを取得
data_importer = dsl.importer(
artifact_uri=data_url,
artifact_class=Dataset,
reimport=False # キャッシュを使用する設定
)
# データ処理ステップ
data_processing_step = process_data(
input_data=data_importer.output # importerの生成物をprocess_dataの入力に渡す
)
# パイプラインをコンパイルしてYAMLファイルに保存
if __name__ == '__main__':
import kfp.compiler as compiler
compiler.Compiler().compile(data_pipeline, 'data_pipeline_with_polars.yaml')
コンポーネントの定義
Kubeflow Pipelinesでは、以下の2種類のコンポーネントを定義できます。
Lightweight Python Components
Pythonコードを直接コンポーネントとして実行でき、軽量なプロジェクトに適しています。
Pythonのバージョンや依存するパッケージを記述することで使用できます。
Container Components
任意のDockerイメージを使用可能で、Python以外の言語も使用することができます。コマンドラインツールをコンポーネントごとに実装することで実行することができます。
こちらのコンポーネントを主に使用し、clickで動作するPythonコマンドラインツールを実装させることが多いです。
以下にContainer Componentsの実装例を示します。
@dsl.container_component
def process_data(input_data: Input[Dataset], output_data: Output[Dataset]):
return dsl.ContainerSpec(
image="asia-northeast1-docker.pkg.dev/<project_id>/<repository_name>/process_data:latest",
command=[
"poetry",
"run",
"python3",
"process_data.py",
],
args=[
"--input_dataset_path",
input_data.path,
"--output_dataset_path",
output_data.path,
],
)
clickで実装されたprocess_data.pyに引数を渡しています。
コマンドラインツール側はinput_dataset_pathに存在するローカルファイルをロードし、加工した後output_dataset_pathにデータを保存するという流れになります。
パイプライン実行までの流れ
最後に、コンパイルしたパイプラインをVertex AIのPython SDK(google-cloud-aiplatform)を用いてVertex AI Pipelinesで実行する流れを以下のコードに示します。
実行はシンプルで、コンパイルしたYAMLファイルとそれに渡すパラメータを指定することでジョブを定義できます。
ジョブはpipeline_job.run()でその場で実行することができます。さらに、pipeline_job.create_schedule()を使用することでVertex AI Pipelinesのスケジュール実行機能を用いてcronで定期実行することもできます。
import google.cloud.aiplatform as vertexai
# プロジェクトIDとリージョンの設定
PROJECT_ID = "<YOUR_PROJECT_ID>"
REGION = "asia-northeast1"
PIPELINE_ROOT = f"gs://<YOUR_BUCKET_NAME>/pipeline_root" # パイプラインの結果を保存するGCSバケットのパス
# Vertex AIの初期化
vertexai.init(project=PROJECT_ID, location=REGION)
# パイプラインジョブの実行
pipeline_job = vertexai.PipelineJob(
display_name="data_pipeline_with_polars",
template_path="data_pipeline_with_polars.yaml",
parameter_values={
"data_url": "gs://<DATA_PATH>" # パイプラインに渡すデータのURLを指定
}
)
# パイプラインジョブの開始
pipeline_job.run()
Vertex AI Pipelines の料金体系
Vertex AI Pipelines自体の料金は、パイプラインの実行回数で課金されます。
- Vertex AI Pipelinesの実行料金: $0.03/実行
また、Vertex AI Pipelinesは複数サービスが組み合わさって実行されているため、以下のような付随するサービスで料金がかかります。
-
Vertex AI Training Job:
-
e2-standard-4(4vCPU, 16GB)で$0.197717/時間 - (GCE: $0.171928/hour +15%程度)
-
- Google Cloud Storage: アーティファクトの保存料金
- Artifact Registry: Dockerイメージの保存料金
パイプライン実行時のみ従量課金がメインになるため稼働していない時のコストを抑えることができます。
ただし、アーティファクトの保存期間の管理を怠ると、ストレージ料金が膨らむ可能性があるため注意が必要です。
Vertex AI Pipelines まとめ
Vertex AI Pipelines導入後、数ヶ月使用した感想としては以下のようになります。
良い点
- Pythonのみでパイプラインの定義から実行まで完結
- コンポーネントのローカル開発の開発者体験が高い
- Container Componentsの柔軟性が高い
- Vertex AI周辺サービスを活用しやすい
- インフラ管理不要かつ使用料金が高くない
課題点
- Container Componentsの起動に時間がかかる場合がある(1~3分)
- イメージサイズを削減する工夫が必要になってくる
- 複数パイプラインの連携やスケジューリング機能が不足しており、他サービスを追加で使用する場合がある
他のコンテナサービスと同様に起動時間のオーバヘッドがあるため、それらを許容または改善する必要があります。また、コンポーネントの分割や制御の流れなどはエンジニアが1から設計し、モジュールやコンポーネントの再利用性を高めていくことで生産性を高めていくことができると考えています。
今後の展望
今後は、以下の点を実現することでさらに生産性を向上させたいと考えています。
- ローカル環境でのパイプラインに対する統合テストの導入
- モノレポ管理における設定コストの削減: モノレポ管理ツール(Pantsなど)の導入
本記事では、GENIEE RECOMMENDにおける機械学習パイプラインの導入について紹介しました。Vertex AI PipelinesやKubeflow Pipelinesを活用することで、効率的なワークフローの自動化が実現でき、安定性と速度を両立したレコメンドの提供を実現しています。今後はよりVertex AI周辺サービスを活用し、レコメンドの質の向上を目指していきます。

Discussion