こんにちは。
Gen-AX AIエンジニアの箕輪です。
今回は弊社プロダクト「X-Boost(クロスブースト)」のPoCにおいて取り組んだ、RAGの検索結果に対する主観評価にLLM as a Judgeを利用した際の検証結果について紹介します。
本記事のサマリー
- RAGの検索結果に対して人間が行った主観評価をLLM as a Judgeで模倣させた
- LLM as a Judgeは全データに対しては「Moderate(中等度の一致)」となった
- 評価者間で評価が一致しているデータに絞ると「Substantial(かなりの一致)」となった
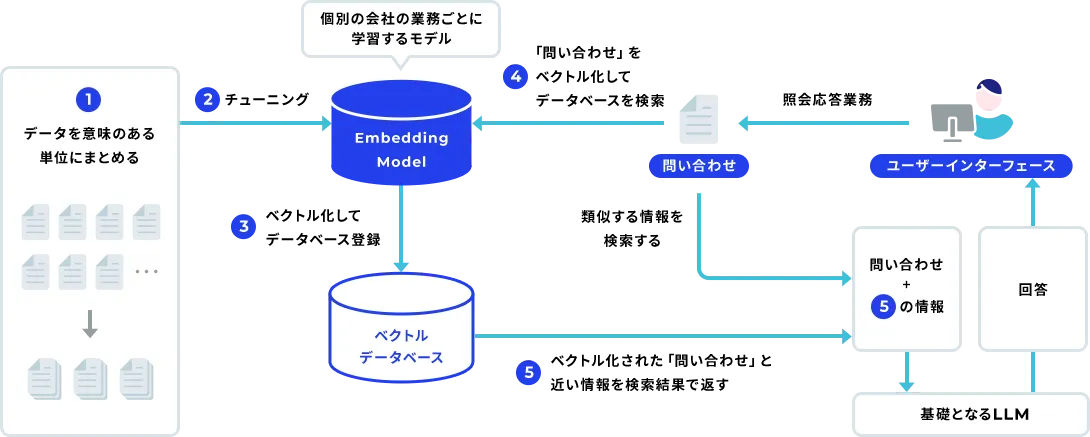
X-Boostとは?
「X-Boost」は、Gen-AXが提供している問い合わせ応答業務をサポートする生成AI SaaSプラットフォームです。
X-BoostはいわゆるRAGに基づいたシステムで、チャットによる問い合わせ業務を効率化するソリューションです。問い合わせ文から過去の類似した問い合わせの履歴を検索し、それをもとに回答文を生成するという点では一般的なRAGと同じですが、X-Boostには以下のような特徴があります。
- 回答生成時に利用する情報を、ユーザが検索結果から明示的に選択
- Embeddingモデルを個社の業務ドメインに合わせてFine-Tuning
LLM as a Judgeとは?
「LLM as a Judge」とは、LLMを用いて何らかの評価を行う手法です。NeurIPS 2023において、Zhengらによって提唱されました。
チャットボットの応答など、特に主観評価が重要なタスクにおいて人手評価の代替として提唱され、現在ではチャットボットの応答評価の他に契約書のレビューや検索結果に対する関連性評価などにも利用されます。
Zhengらの研究では、GPT-4の評価結果がクラウドソーシングを用いた人手評価に対して80%以上の一致率を示しています。Zhengらの研究の他にも例えば、Pinterestでの検索の関連性評価や、Microsoft Bingでの関連性研究などが存在します。これらの研究でも、人間の評価者に匹敵する精度を達成しています。
LLM as a Judgeで人間と同等の評価精度が確認された事例がある一方で、ドメイン知識の不足やバイアスなどの影響でその精度は大きく変動します。例えば「A survey on LLM-as-a-Judge」では、タスク非依存のバイアスとして以下を含むいくつかのバイアスが挙げられています。
- Self-Enhancement Bias(自己強化バイアス)
- LLM評価者が自分自身で生成した応答を好む傾向。評価対象物の生成と評価を同一モデルで行うなど。
- Position Bias(位置バイアス)
- プロンプト内の特定の位置にある応答をLLM評価者が好む傾向。最初の位置を好む、2番目の位置を好むなど。
- Length Bias(長さバイアス)
- 特定の長さの応答を好む傾向。特に冗長な応答を好むなど。
このようなバイアスの軽減や評価性能改善のために、Few-shot Promptingの採用や評価ステップ・基準の分解、説明付き評価などいくつかの手法が検討されていますが、一定の改善は報告されている一方で依然として様々な課題が指摘されています。
LLM as a Judgeはこのようにいくつかの課題が存在するものの、人間の評価を一定模倣することができる点や現実的に人手での主観評価に一定の無視できないコストがかかる点を考慮すれば有用な選択肢であることには変わりありません。
今回は、X-BoostのPoCにおける検索結果をLLM as a Judgeで模倣することが可能か検証を行いました。
検証内容
X-BoostのPoCではRAGの検索結果に対して、正解データを用意して機械的に行う自動評価と、人手による主観評価の2段階で評価を行っています。
正解データを用いた自動評価では、事前にテストデータとして「検索クエリ」と「正解問い合わせ」のペアを作成し、正解問い合わせが検索結果として取得できるかを機械的に評価します。X-Boostの仕様としてユーザに表示する検索結果は上位6件までなので、上位6件に正解問い合わせが含まれる場合はそのテストケースを正解、含まれなければ不正解として各テストケースを評価します。機械的な自動評価は簡単に実行できる一方で、ペアとなっている正解問い合わせと類似している問い合わせでも不正解になってしまうという課題があります。
人手による主観評価では「検索クエリ」に対して「正解問い合わせ」のペアを作成せず、PoCを実施している企業の担当者様が目視で上位6件の検索結果を確認し、それぞれ正解と見なせるかどうかを判断します。お客様の事業ドメインに精通した方が人手で評価することで、プロダクトを実際に利用した際の精度をより正確に測ることができます。評価という観点では機械的な自動評価よりも実態に即した結果を得られる一方で、お客様に工数を割いていただく必要があるため実施できる回数やタイミングは限られてしまいます。
そこで今回は、PoCを行ったあるお客様(以下A社)での主観評価結果をLLM as a Judgeで模倣できるか検証しました。
なお、X-Boostでは検索結果のうち上位6件のデータをUI上でユーザが選択する形式です。そのためテスト検索クエリ1つにつき、上位6件の検索結果が実際の主観評価・LLM as a Judgeのテストデータとして存在することになります。また、実際のPoCでは個社ごとに検索対象となるデータ件数や評価を行う人数、テストデータ件数などは全て異なります。
実験設定
テストデータ件数および評価者数は以下のとおりです。
| 評価者数 | テストデータ数 |
|---|---|
| 2名 | 600件(100クエリ×6検索結果) |
また、LLMはAzure OpenAI Service上でGPT-4o-miniを利用しました。
プロンプト
LLM as a Judgeに用いるプロンプトは独自に作成したプロンプトで行いました。今回は比較的簡易的に行った検証のため、プロンプトの精査はあまり行っていません。
システムプロンプト
あなたは問い合わせ履歴データの評価専門家です。
与えられたテストクエリ(query)に対して、検索結果(content)が適切かどうかを2つの観点から評価してください。
評価観点:
1. query_match: queryの検索結果として、contentが適切かどうか
- queryの内容に対して、contentが関連性があり、有用な情報を含んでいるか
- ユーザーの質問や問題に対して、適切な回答や解決策を提供しているか
2. content_similarity: correct_content(正解とされる内容)とcontentが同一の問い合わせとみなせるかどうか
- 同じ問題や質問について扱っているか
- 内容の本質が同じかどうか(表現の違いは考慮しない)
評価基準:
- 内容の本質を重視し、表現の細かい違いは無視する
- 部分的な一致でも、核心部分が同じなら類似とみなす
- 正常ケースと異常ケースの区別に注意する
必ずJSON形式で以下のように出力してください:
{"query_match": true/false, "content_similarity": true/false}
ユーザプロンプト
以下の情報を評価してください:
【テストクエリ】
{query}
【検索結果の内容】
{content}
【正解とされる内容】
{correct_content}
上記の情報を基に、2つの観点で評価してください:
1. query_match: テストクエリに対して検索結果の内容が適切か
2. content_similarity: 正解とされる内容と検索結果の内容が同一の問い合わせとみなせるか
プロンプトの評価指標について
このプロンプトでは query_match と content_similarity の2つの指標を用意しました。
query_matchは比較的シンプルな指標で、テスト用の検索クエリに対して検索結果である contentが適切かどうかを true/false の2値で判断します。
content_similarityはよりシンプルに、1:1テストにおける正解である correct_content と検索結果の content が同一の内容に関する問い合わせと見なせるかを true/false で判断します。
content_similarity を導入した意図ですが、例えば「〇〇してほしい」という問い合わせがあったときに質問者のステータスに応じてその可否が変化するなど、同一の問い合わせクエリでも応答結果が異なるケースが考えられるためです。こういった複数の分岐が考えられる際に、どのパターンでも正解と見なすのか標準的なパターンのみを正解と見なすのかは、お客様が実際にどのようなユースケースを想定しているかによって異なる可能性があります。
(今回の検証でこの意図通りに動作しているかはさておき)このような理由から2つの指標を用意しました。また、今回は簡易的な検証のため1度のリクエストで2指標の結果を同時に得ていますが、より厳密に検証を行うのであればバイアスを考慮するためにそれぞれ独立したリクエストとして結果を生成させるほうが望ましいです。
検証結果
LLM as a Judgeの結果評価を見ていく前に、A社については評価者が2名存在するので人間評価者間でどの程度評価が一致しているかの確認する必要があります。
評価者間の一致評価
評価者間(以下評価者a、b)の一致について、評価結果は以下の通りになりました。
| a\b | TRUE | FALSE |
|---|---|---|
| TRUE | 260 | 37 |
| FALSE | 98 | 205 |
このように評価が一致していた件数(TRUE×TRUE, FALSE×FALSE)は 465件(77.5%) 、評価が分かれた件数は 135件(22.5%) でした。また、一致率に関する指標は下記のとおりです。
| Accuracy | F1-Score | MCC | Cohen's k |
|---|---|---|---|
| 0.775 | 0.794 | 0.563 | 0.551 |
この評価者間での指標がA社におけるLLM as a Judgeの実質的な上限値となります。
LLM as a Judgeの結果
結果については、全データに対する分析結果と、評価者a,bの結果が一致したデータに絞った分析結果を紹介します。
全データ
| Evaluator | LLM Method | Accuracy | F1-Score | MCC | Cohen's κ | Precision | Recall |
|---|---|---|---|---|---|---|---|
| 評価者a | query_match | 0.755 | 0.746 | 0.510 | 0.510 | 0.766 | 0.727 |
| 評価者a | content_similarity | 0.677 | 0.680 | 0.354 | 0.353 | 0.667 | 0.694 |
| 評価者b | query_match | 0.723 | 0.741 | 0.468 | 0.453 | 0.840 | 0.662 |
| 評価者b | content_similarity | 0.645 | 0.681 | 0.290 | 0.286 | 0.735 | 0.634 |
一致データ
| LLM Method | Accuracy | F1-Score | MCC | Cohen's κ | Precision | Recall |
|---|---|---|---|---|---|---|
| query_match | 0.809 | 0.820 | 0.621 | 0.621 | 0.867 | 0.777 |
| content_similarity | 0.708 | 0.729 | 0.413 | 0.413 | 0.756 | 0.704 |
検証結果まとめ
今回の検証では、全データにおいては 評価者a と query_match が Accuracy 0.755, MCC 0.510, Cohen's k 0.510 と比較的良好な結果となりました。純粋な数値としては「Moderate(中等度の一致)」ですが、人間の評価者間の結果(実質的な上限)が Accuracy 0.775, MCC 0.563, Cohen's k 0.551 であることを考えると十分高い結果と言ってよいと思います。また、 評価者b に対する結果は 評価者a より全体的にやや低い結果となっていますが、 query_match が Precision 0.840 を記録するなど、一定程度の精度は出ています。
評価者a, b 間で評価結果が一致しているデータに絞って分析するとAccuracy 0.809, MCC 0.621, Cohen's k 0.621 と、「(Substantial)かなりの一致」を示しています。Accuracy 0.809 なので人手評価の完全な代替はまだ難しいですが、人手評価を行えないタイミングでの参考値としての利用であれば業務でも実用できる水準と言えるかと思います。
またLLM as a Judgeの評価指標に着目すると、全データ・一致データのいずれのケースでも query_match のほうが content_similarity よりも高い精度で人間の評価を模倣できていました。これだけ聞くと content_similarity は全く意味のない指標に思えますが、 content_similarity のみが正解している件数も一定存在します。
content_similarity それ自体が最適かは別として、先行研究でも言われている通り LLM as a Judge を用いる際には複数の評価指標を組み合わせて用いることでより網羅的に高い精度で結果を模倣することができると言えそうです。
おわりに
LLM as a Judgeは主観評価が必要な内容を自動評価しするうえで非常に重要な手法であり、今後も様々な活用事例が出てくることが予想されます。LLMの生成結果をアプリケーション上で利用するだけでなく、LLM as a Judgeや学習データの生成に利用するなどMLOps/LLMOpsにおける活用も引き続き注目です。今回はプロンプトのパターンなどの検証は簡易的にしか実施していませんが、何らかの参考になれば幸いです。
Gen-AXでは一緒に働くエンジニアを大募集中です!
少しでもご興味のある方はカジュアル面談も受け付けておりますので、是非お気軽にご連絡ください。

Discussion