dbtで家計簿アプリ作ってみた




こんにちは!ゲンシュンです。
めちゃめちゃ今更ですが、この記事はdatatech-jp Casual Talks #6で発表した「dbtで家計簿アプリを作ってみた」の実際のコードとかの話を中心に記載しています。本記事では以下3つを主に取り上げて解説します〜。
①Workload Identity連携でgithubからterraformとdbtを実行する
②dbt-osmosis、dbt_exposures、dbt_mlを使ってみた
③dbtで作ったデータをLookerStudioに繋げてみた
このイベントで伝えたかったメッセージは「データエンジニアも自作アプリで技術検証とかできるよー」です。スライドはこちらです。
①Workload Identity連携でgithubからterraformとdbtを実行する
ゴールはgithub actions経由で、terraformとdbtを実行する環境作りです。大体公式ドキュメントに従ってやりました!
リポジトリのActions設定
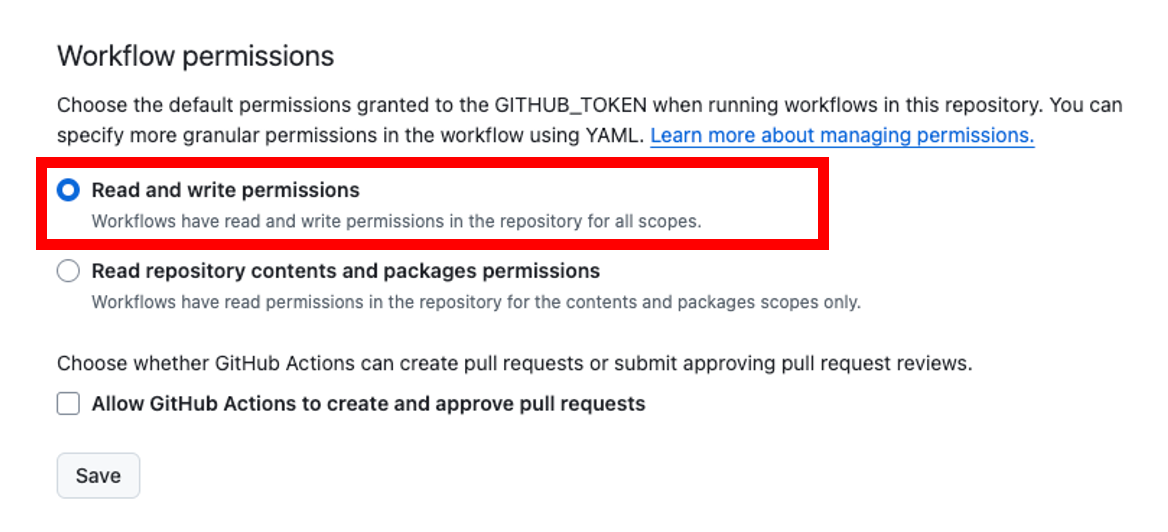
リポジトリのSettingでActionsの項目から、Workflow permissionsを「Read and write permissions」を選択。terraform経由でリモートstateを更新するから必要なんですかね〜
サービスアカウントとterraform用GCSを用意
今回は github-actions@{PROJECT_NAME}.iam.gserviceaccount.com を作成しました。terraformとdbtで必要な権限が違うので、実際はgithub-actions-terraformとgithub-actions-dbtの2種類用意したんですが、今回の記事は便宜上このサービスアカウントだけで解説進めます。
また、terraformのremote state用のGCSバケットをコンソールから作成しておきます。
Workload Identityのプール/プロバイダ作成
今回は以下の設定をコンソールからポチポチで作ります。
- プールID:今回は「github-actions」で作成
- プロバイダ:OpenID Connect(OIDC)
- プロバイダ名プロバイダID:今回は「github」で作成
- 発行元(URL):
https://token.actions.githubusercontent.com - オーディエンス:デフォルトのオーディエンスを選択
- 属性マッピング
- google.subject:
assertion.sub - attribute.repository:
assertion.repository
- google.subject:
- 属性条件
- 条件CEL:
assertion.repository.startsWith('リポジトリ所有者名/') - ※
assertion.repository_owner == "リポジトリ所有者名"やassertion.repository == "リポジトリ所有者名/リポジトリ名"でもOK。目的はリポジトリの制約をつけたいだけなので!
- 条件CEL:
Workload Identityとサービスアカウントの接続
アクセス許可で「サービスアカウントの権限借用を使用してアクセス権を付与する」を選び、続きは以下を画面ポチポチで。
- サービスアカウント:さっき作ったサービスアカウントを指定
- プリンシパル
- 属性名:
subject - 属性値:
リポジトリ所有者/リポジトリ名
- 属性名:
本来はこれで十分なはずですが何故かずっと Permission 'iam.serviceAccounts.getAccessToken' denied on resource が出てしまい、以下の権限を追加で付与したらうまくいきました。 principal:// と principalSet:// の権限差分が原因だったかも?
gcloud iam service-accounts add-iam-policy-binding \
github-actions@{PROJECT_NAME}.iam.gserviceaccount.com \
--project="{PROJECT_NAME}" \
--role="roles/iam.serviceAccountTokenCreator" \
--member="principalSet://iam.googleapis.com/projects/{PROJECT_NAME}/locations/global/workloadIdentityPools/{プールID}/attribute.repository/{リポジトリ所有者}/{リポジトリ名}"
Github Actionsのワークフロー作成
画面からの手動実行もしくはterraform関連の変更commit時のみ実行されるようにしたい!サービスアカウントやWorkloadIdentityプロバイダーIDを直に書くのはセキュリティ的に微妙なのでgithubリポジトリのSecretに格納しておきます。
- GCP_SERVICE_ACCOUNT:
github-actions@{PROJECT_NAME}.iam.gserviceaccount.com - GCP_OIDC_PROVIDER:
projects/{プPROJECT_NUMBER}>/locations/global/workloadIdentityPools/{プールID}/providers/{プロバイダID}
以下terraform apply実行用のyml実装。
name: deploy-terraform.yml
on:
# 手動実行
workflow_dispatch:
# 特定のファイルに関するcommit
push:
branches:
- main
paths:
- "terraform/environments/xxxxxxx/**"
- "terraform/modules/**"
env:
TF_VERSION: 1.9.7
DEPLOY_PROJECT_NAME: xxxxxxx
jobs:
terraform_apply:
runs-on: ubuntu-latest
permissions:
id-token: write
contents: read
pull-requests: write
steps:
- name: main checkout
uses: actions/checkout@v4
- name: authenticate to gcp
uses: google-github-actions/auth@v2
with:
project_id: ${{ env.DEPLOY_PROJECT_NAME }}
service_account: ${{ secrets.GCP_SERVICE_ACCOUNT }}
workload_identity_provider: ${{ secrets.GCP_OIDC_PROVIDER }}
- name: set up terraform
uses: hashicorp/setup-terraform@v3
with:
terraform_version: ${{ env.TF_VERSION }}
- name: terraform init
run: terraform init
working-directory: ${{ github.workspace }}/terraform/environments/${{ env.DEPLOY_PROJECT_NAME }}
- name: terraform apply
run: terraform apply -auto-approve -no-color 2>&1
working-directory: ${{ github.workspace }}/terraform/environments/${{ env.DEPLOY_PROJECT_NAME }}
次はdbt用のymlファイルです。あ、ちなみにdbt core使用です。CloudBuildやCloudrunJobsにタスクを投げる方が良さそうですが、今回はスピード重視で若干雑でもOK!
name: deploy-dbt.yml
on:
# 手動実行
workflow_dispatch:
# 特定のファイルに関するcommit
push:
branches:
- main
paths:
- "dbt/**"
env:
PYTHON_VERSION: 3.12.6
jobs:
deploy:
permissions:
id-token: write
contents: read
runs-on: ubuntu-latest
steps:
- name: main checkout
uses: actions/checkout@v4
- name: authenticate to gcp
uses: google-github-actions/auth@v2
with:
service_account: ${{ secrets.GCP_SERVICE_ACCOUNT }}
workload_identity_provider: ${{ secrets.GCP_OIDC_PROVIDER }}
- name: set up python
uses: actions/setup-python@v4
with:
python-version: ${{ env.PYTHON_VERSION }}
- name: install dependency
run: |
pip install dbt-core dbt-bigquery
- name: dbt run
working-directory: ./dbt
run: |
dbt deps
dbt seed
dbt run
dbt test
これでterraform applyやdbt runの実行が自動化できたぜ〜。

terraform周りの実装
今回使ったterraform用リポジトリが、全個人アプリ/全技術検証の全インフラリソースを管理している都合上、モジュール構成は雑に小さい粒度で切ってます。モジュールの切り方は人/組織それぞれ違うので何も参考にならないと思いますが、ディレクトリ構成とコードの一部だけ。
※諸々の都合上、今回のアプリ名cold_waveなので、このあたりの名前はいい感じに無視してください〜
.
├── environments
│ └── xxxxxxxx
│ ├── backend.tf
│ ├── cold_wave.tf ← 今回追加したリソース
│ └── main.tf
└── modules
├── artifact-registry
│ ├── locals.tf
│ ├── main.tf
│ └── variable.tf
├── bigquery
│ ├── locals.tf
│ ├── main.tf
│ └── variable.tf
├── cloud-nat
│ ├── locals.tf
│ ├── main.tf
│ └── variables.tf
├── iam
│ ├── main.tf
│ └── variable.tf
├── network
│ ├── locals.tf
│ ├── main.tf
│ ├── output.tf
│ └── variables.tf
├── service-account
│ ├── main.tf
│ ├── output.tf
│ └── variable.tf
└── storage
├── locals.tf
├── main.tf
└── variables.tf
terraformのコード、一部だけ雰囲気こんな感じです。
# cold_wave.tf
module "cold_wave_service_account" {
source = "../../modules/service-account"
project_id = "xxxxxxx"
account_id = "cold-wave-service-account"
display_name = "cold_wave用 Service Account"
description = "cold_waveアプリ用。dbt実行やLookerStudio接続用"
}
module "cold_wave_iam" {
source = "../../modules/iam"
project_id = "xxxxxxx"
member = module.cold_wave_service_account.service_account_member
roles = [
"roles/bigquery.jobUser",
"roles/bigquery.dataEditor",
"roles/iam.serviceAccountTokenCreator"
]
}
# iam.tf
resource "google_project_iam_member" "sa_role" {
for_each = toset(var.roles)
project = var.project_id
member = var.member
role = each.value
}
# variable.tf
variable "project_id" {
type = string
}
variable "member" {
type = string
description = "The member string for the IAM binding"
}
variable "roles" {
type = list(string)
}
②dbt-osmosis、dbt_exposures、dbt_mlを使ってみた
久しぶりにdbtでモデリングしたい!ということで、家計簿csvデータを取り込みディメンショナルモデリングでそれっぽい実装をしてみた。また、せっかくの機会なので気になっているライブラリとか使ってみたい!ということで、色々触ってみた。
dbtの全体設計
まず各ディレクトリごとの責務はざっくり以下。
- seed層:データソース。家計簿データは手動でエクスポートすることにして、csvをここに配置
- staging層:日付の変換や、税や利息などの面倒いデータを除去
- intermediate層:口座間のお金のやり取り(振替)や、各カテゴリの整理。例えば口座A(個人)から口座B(家計)に食費を出す際、全体のお金は±0なのに口座単体で見ると出費が発生しているようにみえちゃうのでそれを均すためにここの層で頑張ることにした
- mart層:dimensionとfactテーブルを作る
- ml層:ML関連のモデル
ディレクトリ構成こんな感じ。
※ローカルで開発するときは poetry shell 環境で実行してたので、poetry周りのファイルあります。
.
├── models
│ ├── intermediate
│ │ ├── int_xxx.sql
│ │ └── schema.yml
│ ├── mart
│ │ ├── dim_xxxx.sql
│ │ ├── fct_xxxx.sql
│ │ └── schema.yml
│ ├── ml
│ │ ├── predict.sql
│ │ ├── train.sql
│ │ └── schema.yml
│ └── staging
│ ├── stg_xxx.yml
│ └── schema.yml
├── seeds
│ ├── xxxxx.csv
│ └── schema.yml
├── dbt_project.yml
├── package-lock.yml
├── packages.yml
├── poetry.lock
├── profiles.yml
├── pyproject.toml
└── requirements.txt
dbt_projectはこんな感じ。 dbt-osmosis とかについては後述
# Configuring models
models:
cold_wave:
+dbt-osmosis: "schema.yml"
# +dbt-osmosis: "{model}.yml" ← モデル名.ymlにしたかったらこれ
staging:
materialized: view
intermediate:
materialized: view
mart:
# mart層だけ実体化
materialized: table
ml:
# ML層は特定の条件のみ実行するのでタグ付け
+tags: ml
seeds:
cold_wave:
+dbt-osmosis: "schema.yml"
# User configuration
flags:
use_colors: false
データの抽出も自動化したかったんですけどねぇ〜API周りがめちゃめちゃややこしかったので断念!
dbt-osmosisを使ってみた
dbt周りでカラムdescriptionのバケツリレー作業が地味に面倒だった記憶があったのですが、上流モデルの定義をちゃんと行えれば、参照先の下流モデルのdescriptionを補完してくれるとのこと。便利そう!やってみよう。
dbt_project.ymlに +dbt-osmosis 追記するだけで良さそう。
models:
cold_wave:
+dbt-osmosis: "schema.yml"
# +dbt-osmosis: "{model}.yml" ← モデル名.ymlにしたかったらこれ
初回実行が dbt-osmosis yaml documentで2回目以降は dbt-osmosis yaml refactor ですかねぇ。

例えば dim_account の account_number や account_name は stg_account の account_number と account_name を参照しているんですが、実行するとdescriptionが勝手に補完してくれる!これは便利〜入れ得っすね!

dbt_exposuresを使ってみた
これは課題感というより、気になったので使ってみた感じです。
dbt docsだけでは、各テーブルが最終的にBIツールのどのダッシュボードに使われているのか把握できないので、それも把握できるようになるぞって感じですかね
exposures:
- name: g_report
label: report
type: dashboard
url: https://lookerstudio.google.com/reporting/xxxxxx
description: 家計簿の全ダッシュボード一覧
depends_on:
- ref('fct_billing_genshun')
- ref('dim_category')
- ref('predict')
owner:
name: genshun
上記実装し dbt docs generate の後にdbt docsを覗いてみる。確かにBIツールのダッシュボードまでの依存関係が明らかに!

Looker使ってた時は「どのテーブルがどのダッシュボードが使われているのかわからない」という課題感はあまり感じられなかったんですが、LookerStudioなどコード管理できないBIツールを使ってたり、複数のBIツールを利用しているときには効力発揮するかも?
今回の自作アプリでは1ダッシュボードしかないので、dbt-osmosisほどの恩恵を感じず!
dbt_mlを使ってみた
初めてのBQMLです!ぶっちゃけMLのモデルとか全然わからないですが「毎月」「カテゴリ」ごとに「支出金額」を予測できれば何でも良かったので ARIMA_PLUS というのを使って以下実装してみた。
このあたりの設定って、configに書くかschema.ymlに書くか、どっちが良いんですかね〜?
# train.sql
{{
config({
"materialized": 'model',
"tags": ["ml"],
"ml_config": {
'model_type': 'ARIMA_PLUS',
'time_series_timestamp_col': 'month',
'time_series_data_col' : 'total_spent_money',
'time_series_id_col': 'category'
}
})
}}
select
month,
category,
total_spent_money
from {{ ref('fct_billing_xxxxx') }}
# predict.sql
{{
config(
materialized="table",
tags=["ml"]
)
}}
select
category,
forecast_value as predicted_spent_money
from
ML.FORECAST(MODEL {{ ref('train') }},
STRUCT(1 AS horizon))
人生初のBQMLの結果、それっぽい予想が出た・・!

③dbtで作ったデータをLookerStudioに繋げてみた
BigQuery→LookerStudioのコンボが無料で出来るので使ってみた。
認証情報をサービスアカウントにする準備
LookerStudioのデータソースって、デフォルトで作成者のアカウントを使って認証するので、サービスアカウントを使うようにします。基本公式ドキュメントに全て従いましたが、LookerStudioサービスエージェントに、サービスアカウントへのアクセス許可する部分はterraformで実装しました。雑にこんな雰囲気。
resource "google_service_account_iam_binding" "sa_iam_bind" {
service_account_id = 作成したサービスアカウントのID
role = "roles/iam.serviceAccountTokenCreator"
# LookerStudioのサービスエージェント
members = toset([
"serviceAccount:service-org-xxxxxxx@gcp-sa-datastudio.iam.gserviceaccount.com"
])
}
データソース/レポートの作成
コード管理できないBIツール側で諸々ゴニョゴニョさせたくないので、BQにあるテーブルをデータソースとして定義しレポートはそれを参照するだけの形にして、BIツールの責務は描画に集中!
今回は dim_category と fct_billing_xxx をjoinしてgroup byしたレポートテーブルと、BQMLによるpredict結果のテーブルだけを参照するデータソースを作成しました。
データの認証情報は先程ごにょごにょしたサービスアカウントを指定するようにした。

完成しました!
登壇資料のスクショ祭りになりますが、雰囲気だけ。金額はいい感じにぼかしてます
まずは各月各カテゴリごとの金額推移。その他多すぎてよくわからん。

「その他」の定義を、家計簿アプリのサジェストに従って分解してみた結果、細かすぎてよくわからん。

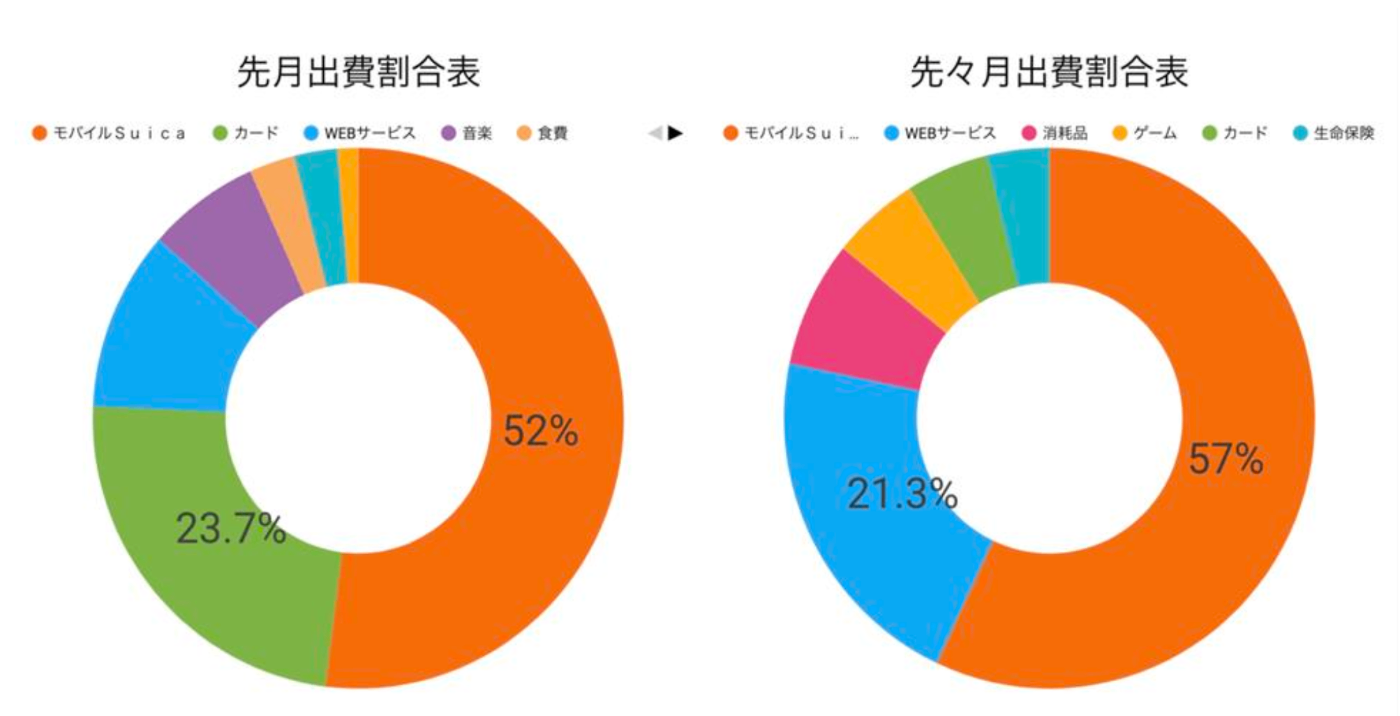
実行日前月と前々月の、カテゴリごとの出費割合比較です。ほぼモバイルSuicaやんけ!
ヒートマップっぽい表を作りたかったので、それっぽいものを。
ん???これ、家族旅行で俺がホテルを建て替えたままになってることね?!?!?

BQMLの予想テーブル。2万以上超えるものを自動で赤字にするやーつも入れてみた!ほぼモバイr(ry

これは家計全体の推移。一部データ欠損時期がありますね。俺が家計簿アプリへの連携をめちゃめちゃサボってた期間だ。。

なんか減ってるな〜とこのグラフを追ってみたところ、どうやらケータイ変更に伴う携帯電話料金の変化を発見!これは気づき。本来はこんなの見なくてもわかるはずですけど・・

学び
- WEBアプリをサクッと作るノリと同じように、身近なデータを使えばデータモデリングとか技術検証個人で全然できるじゃん〜という発見
- やっぱりdbtは楽しい
- 実は、家計簿アプリへデータをちゃんと整備してくれた妻がMVPでは笑?やっぱデータソースの重要性だよな〜〜〜
- ぶっっちゃけお題ミス。家計簿アプリ見れば全部済m(ry
以上ですありがとうございました〜。
Discussion