Dive deep on Amazon S3
S3の全体像

フロントエンド:負荷分散をするところ
インデックス:どのようなデータをどこに配置しているか、大きなデータベース
ストレージ層:データを保管しているところ
フロントエンドの理解
ピークトラフィック:1PB/秒
裏ではオートスケールしているが、利用者側(リクエストを行う側)でも緩和策を実施してもらっている
-
マルチパートアップロード(並列PUT)
スループットの向上だけではなく、分割したうちの1つが失敗した場合はそれだけをリトライすれば良くなる -
レンジの利用(並列GET)
マルチパートアップロードしていたコンテンツは並列GETすることで、スループットが向上する -
複数のIPへの負荷分散
S3のドメインにアクセスするとき、裏ではS3のフリート(サーバーの集合)にアクセスが分散される
3つの緩和策については利用者自ら実装することも可能だが、最新のAWS CLIとAWS SDKが利用するRuntime環境に既に組み込まれているため透過的に利用していることになる。
インデックスの理解
350兆のオブジェクト、秒間1億件以上のリクエスト

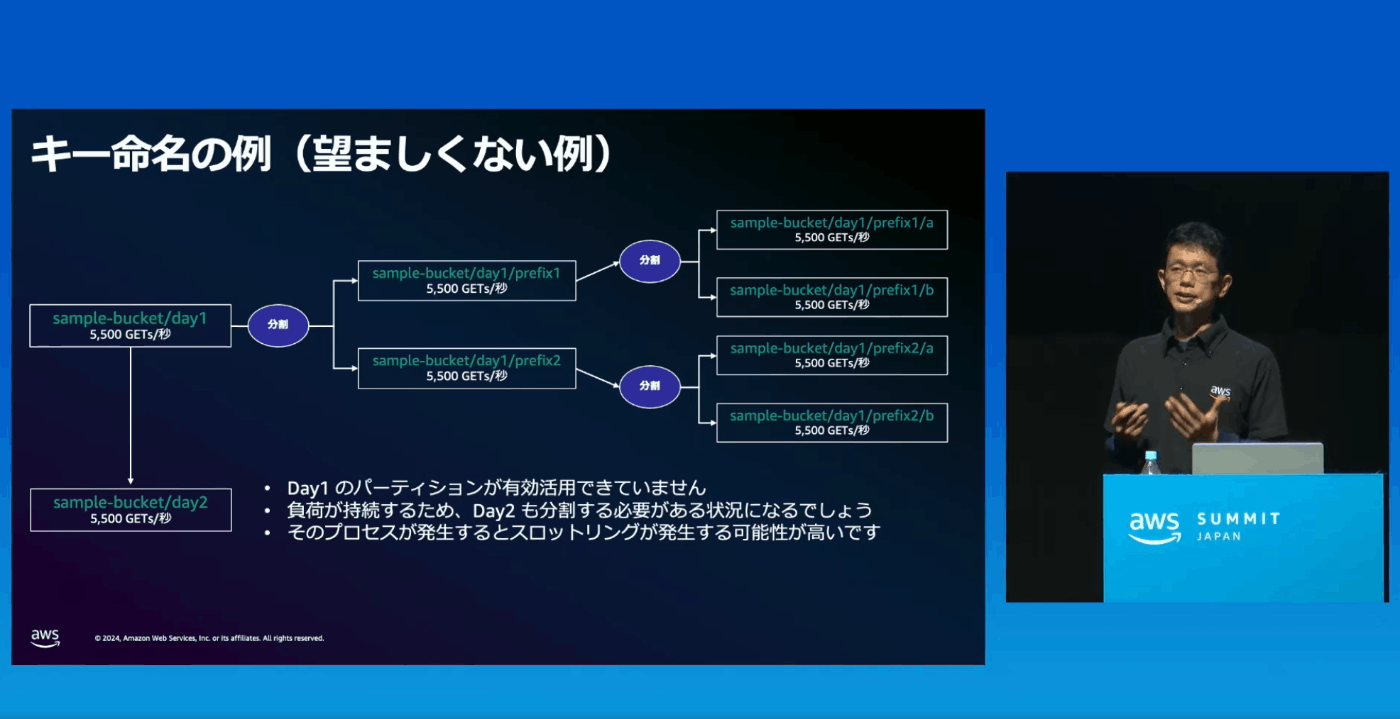
例えば、アルファベットの特定範囲を考えてみる
英語ではN-Sで始まる単語が多いため、格納されるオブジェクトのKeyもその区間が多くなり、利用頻度が多くなる。
これを分散するためにS3の裏側ではオートスケーリングするようになっている。
S3が提供する性能上限はプレフィックスあたりで設定されている。
なぜならS3はプレーンなKey-Valueストアだから(フォルダと読んでいるものは便宜上そのように表現しているだけで、実際には階層という概念はない)。
この性能上限を超えると503がレスポンスとして返ってくる

フラットなKey-Valueストアであることによる性能上限の性質と、オートススケーリングの性質を加味して、ユーザー側で行うことができる緩和策が2つある。
- キー名のカーディナリティを左に寄せる
- キー名に日付をいれるならばなるべく右側に寄せる
ストレージ層の理解
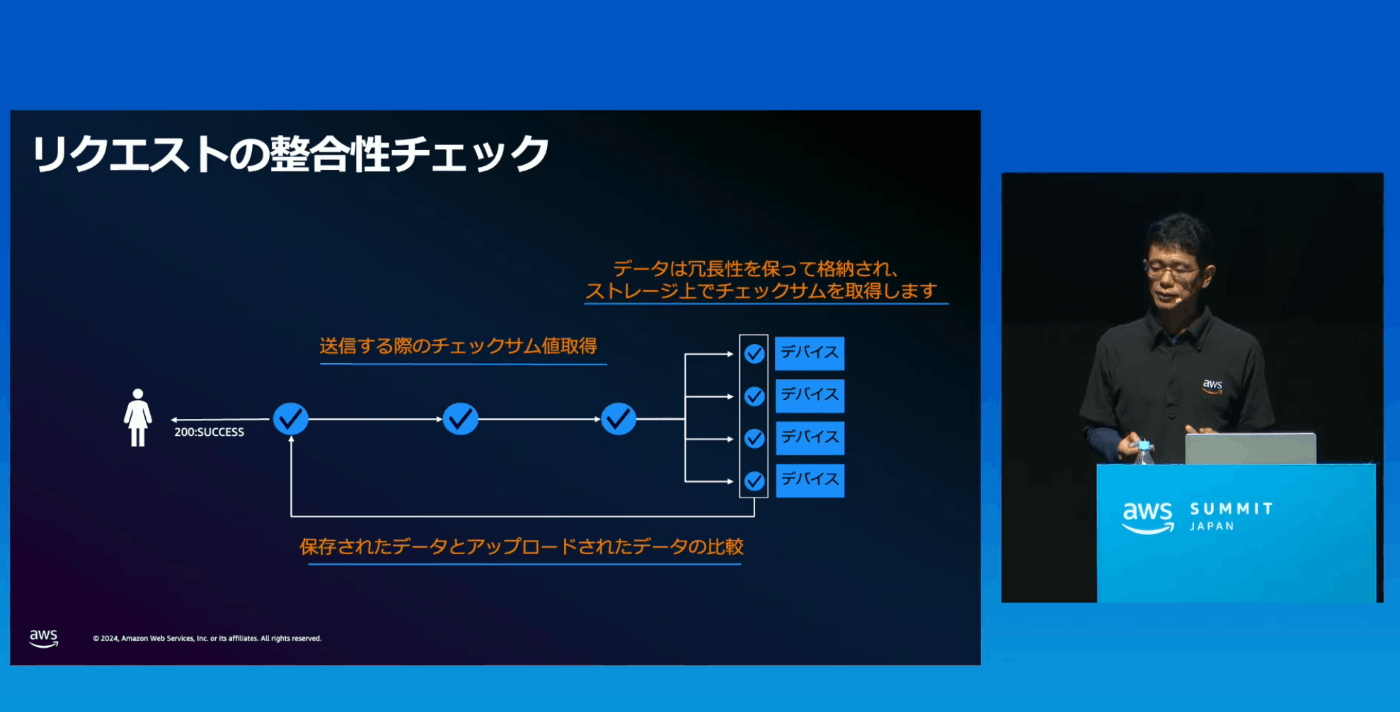
何百万ものハードドライブ、エキサバイトのデータ、99.999999999%のデータ耐久性
チェックサムの確認は1度だけではない、複数AZでの冗長化をしている
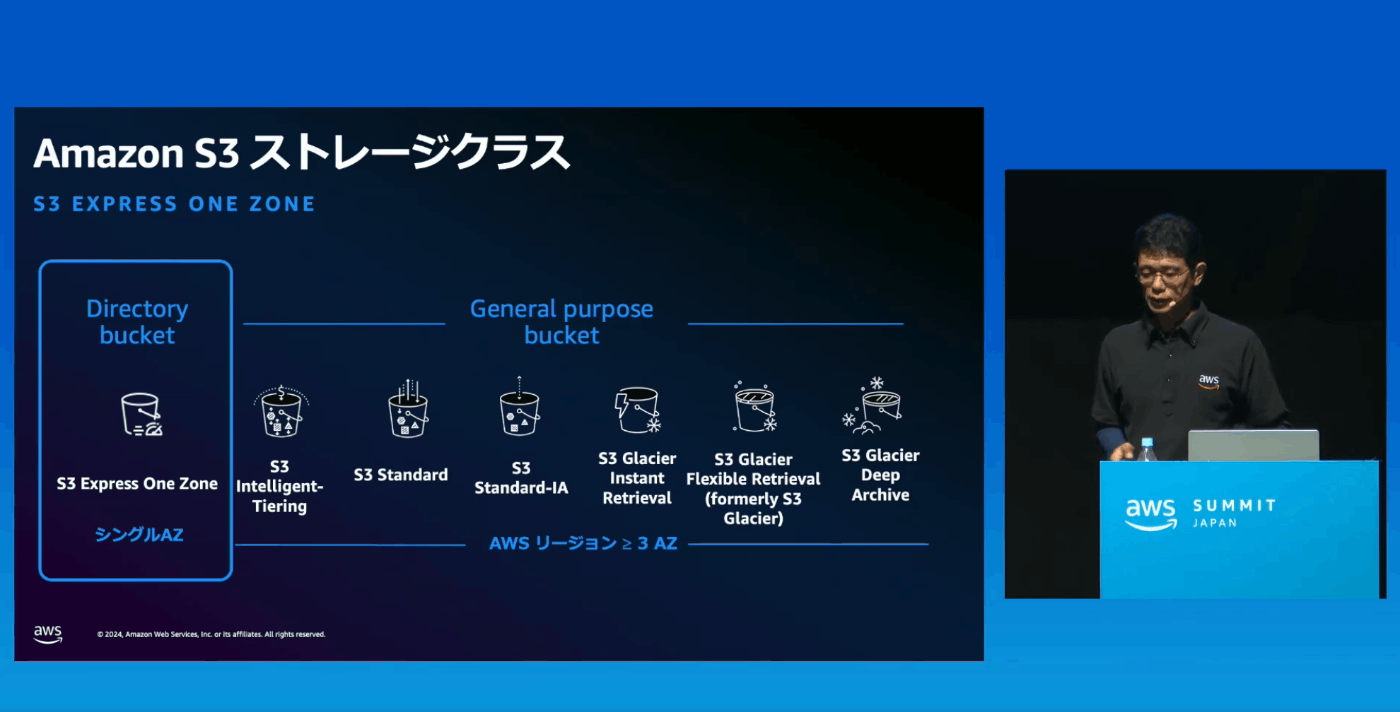
新しいストレージクラス
これまでに提供していたもの:General purpose bucket
新しくre: inventで発表したもの:Directory bucket
Directory bucket
ストレージクラス名:Amazon S3 Express One Zone
シングルAZで構成→データ損失の可能性

なぜこのようなバケットがあるのか?
→レイテンシを低減したいアプリケーション向け
S3は冷蔵庫、開け閉めに時間がかかる
まな板(メモリ)で動作するのとは異なる、が、まな板で動作するような速さにも挑戦したい
アーキテクチャへの影響

通常のバケット:アクセスのたびに認証・認可の処理が発生する
Express One Zone:セッションベースでの管理のため、最初にセッションを確立したあとは接続詞っぱなし
セッションの概念もSDKを利用していれば透過的に利用できる

具体的な利用用途:機械学習におけるトレーニング
特にI/O性能が重視される

I/Oの部分(Storageの部分)はComputeリソースが遊んでしまっている状態
Express One ZoneでStorageのI/O処理にかかっていた時間を短縮することで、Computeリソースが遊んでいる時間を短くできる(高速化、コンピュートリソースの削減)
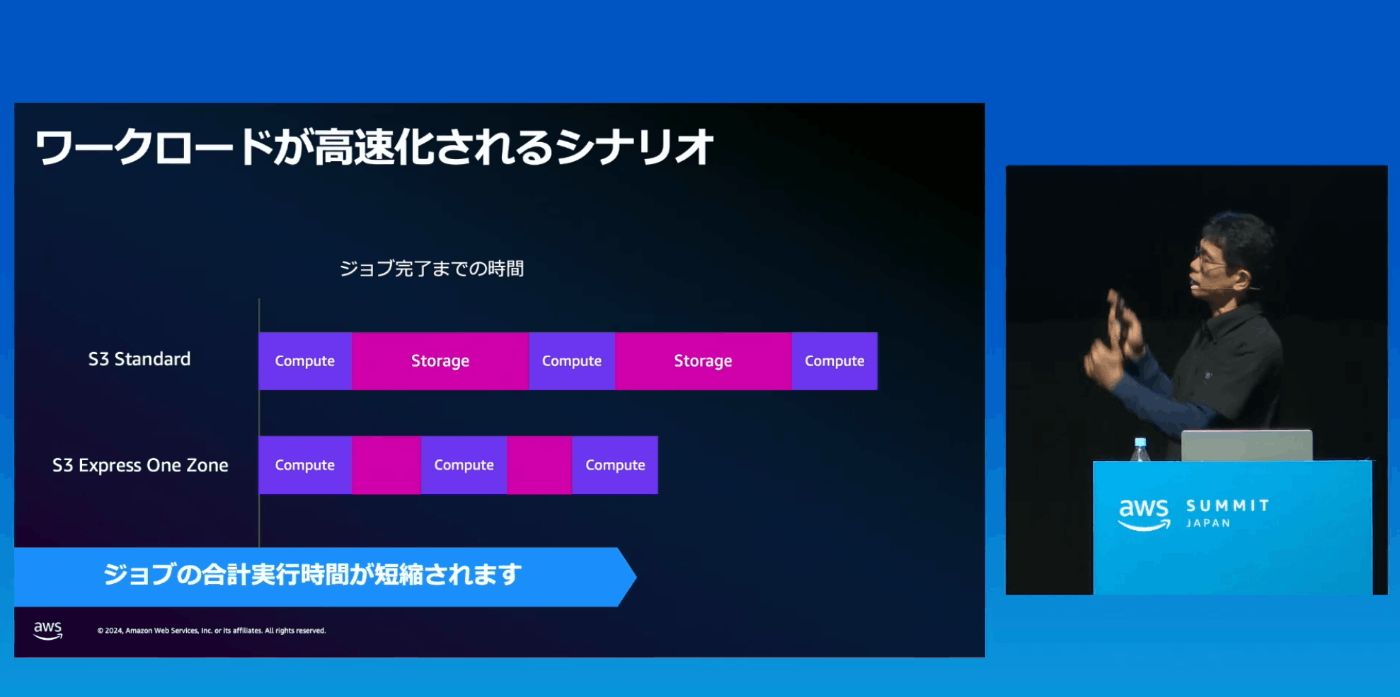
機械学習のワークロードの例
・通常のバケットからExpress One Zoneへのデータコピーはimportという処理で行う(バッチ処理)
・青色の矢印部分が最適化される
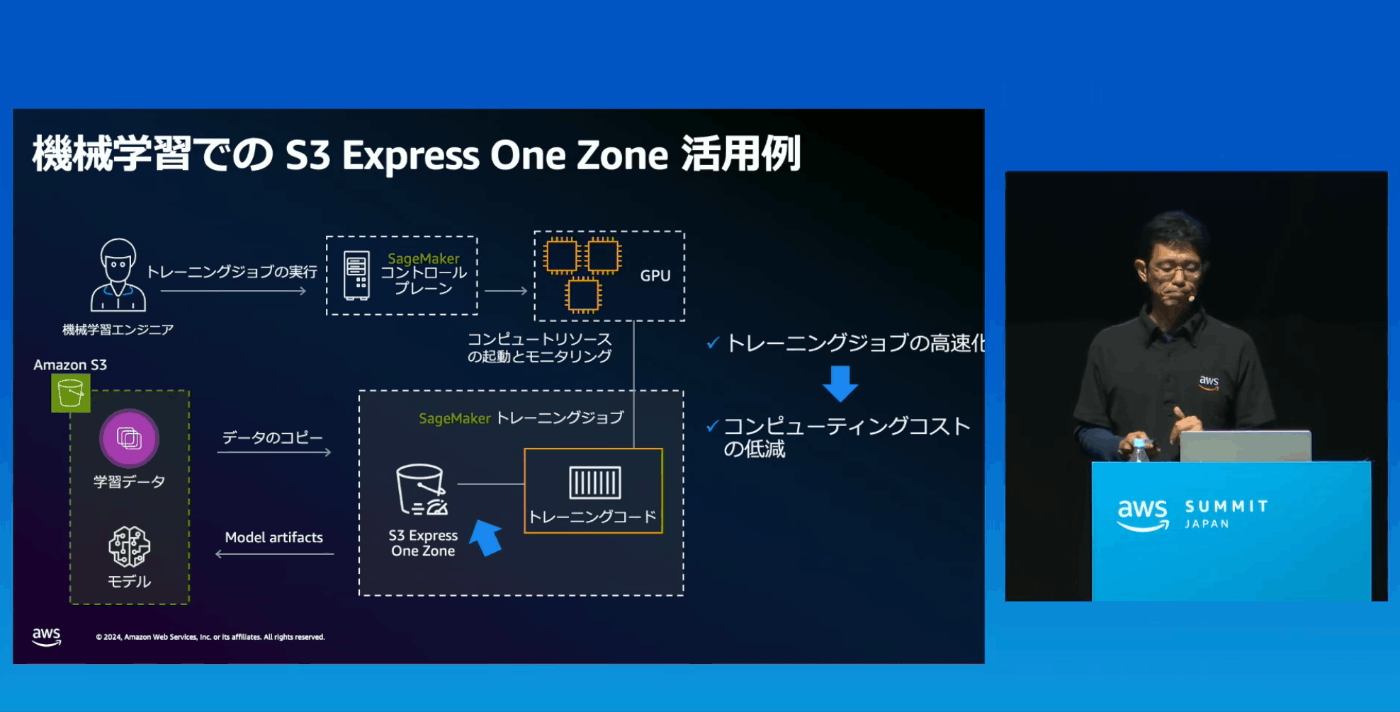
通常のバケットとExpress One Zoneで比較した場合
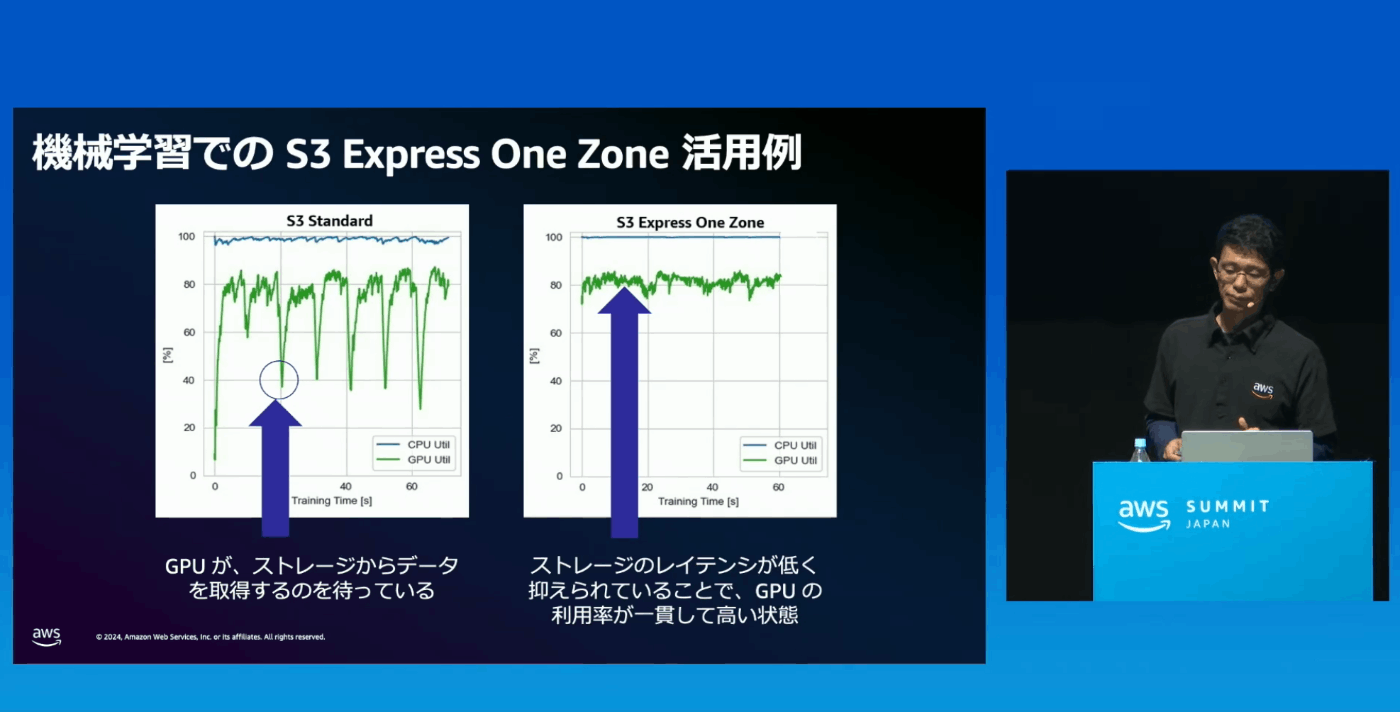
Express One Zoneを利用するうえでの注意点
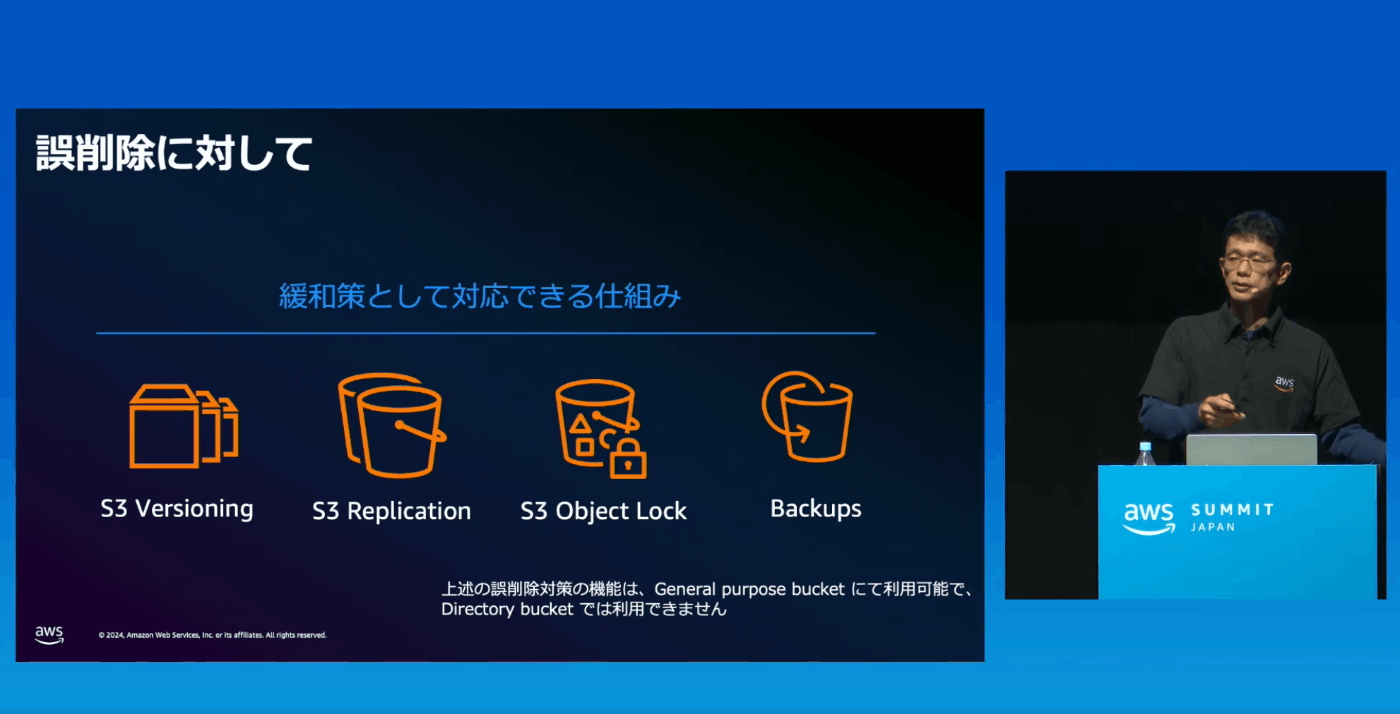
データご削除の仕組みは利用できない
大切な、削除されたら困るデータは通常のS3バケットへ
機械学習などで利用する一時的に拘束アクセスしたいデータはExpress One Zoneへ
→機械学習で利用するときのみExpress One Zoneへデータをコピーする、など