ソフトウェア設計の羅針盤:変化を味方につける「4つの普遍的分類」と「コードの成長戦略」
ソフトウェア開発の現場では、「また要件変更か…」「この機能、どこを直せばいいんだっけ?」といった声が日常的に聞かれます。ビジネスは常に変化し、新しい技術が次々と登場する中で、一度作ったシステムはまるで生き物のように「成長」し、複雑さを増していきます。
この「成長」というダイナミックな世界で、どうすればコードの健全さを保ち、開発スピードを落とさず、将来にわたって保守し続けられるのでしょうか?
その答えは、「良いコード」とは何か、という問いから始まります。そして、それを実現するための「普遍的なコードの分類」と、決して焦らず「段階的にコードを育てていく戦略」に隠されています。
「良いコード」って、どんなコード?
「良いコード」の定義は人それぞれかもしれませんが、ここでは特に「成長し続けるソフトウェア」という視点で、開発者にとって本当に助けになる3つのポイントに絞って考えてみましょう。
- 変更しやすい(Changeable): 「ここを直したい」と思ったときに、サッと、しかも正確に修正できるコードです。何より大切なのは、その変更が他の思わぬ場所に悪影響を及ぼさないよう、影響範囲を小さく、局所化できること。これができていれば、安心してコードをいじれるし、開発スピードもグッと上がります。
- 分かりやすい(Understandable): 「このコード、何やってるんだ…?」と頭を抱えることなく、新しい開発メンバーでもサッと意図を理解できるコードです。これは、コードがそれぞれの「関心事」に応じて明確に役割分担されていることで、大きく向上します。ごちゃごちゃしたコードよりも、整理整頓されたコードの方が、誰にとっても読みやすいですよね。
- テストしやすい(Testable): コードの品質をしっかり確かめるためのテストを、効率よく、漏れなく実行できるコードです。これを可能にする鍵は、コードがデータベースや外部サービスなどの外部依存を簡単に「置き換え可能」 になっていること。テスト用のダミー(モックやスタブ)に差し替えられれば、実際のサービスを動かす必要なく、高速で安定したテストが回せるようになります。
つい目の前の機能実装に追われがちですが、これらの「良いコード」の特性を意識することが、複雑なシステムを長く運用していく上で、開発チームを本当に助けてくれます。では、どうすればそんな良いコードが書けるんでしょう?
そこで役立つのが、今回ご紹介する「4つの普遍的なコードの分類」と、それを段階的に適用する戦略です。
ソフトウェアの「4つの普遍的分類」:コードを整理し、変化を味方につける
ソフトウェアのコードベースは、その役割や変更されやすさによって、大きく4つの「分類」に分けて考えることができます。これらは、上下関係を示す厳密な「層」というよりも、コードの「関心事」や「責任範囲」に応じた仕分け、と捉えるとしっくりくるでしょう。これらの分類は、システムが成長するにつれて、徐々に明確になっていきます。
1. Core (コア):ビジネスの真髄、変わらない価値の集約地
システムの心臓部。ここには、あなたのビジネスにとって最も大切な「純粋なビジネスルール」や「ドメインの概念」、そして「具体的なユースケース」(ユーザーがシステムでやりたいこと)が詰まっています。あなたの会社の本当の価値は、この分類に集約されている、と言っても過言ではありません。
このCore分類は、必ずしも単一の厳密な層を指すわけではありません。クリーンアーキテクチャなどでいう「ドメイン層」や「ユースケース層」といった複数の内部レイヤーを含む、ビジネスの本質に関わる関心事の集合体と捉えてください。システムの規模や複雑さが増すにつれて、Core分類の内部もまた、変更頻度や責任に応じて細分化されていきます。
Coreは、ユーザーインターフェースやデータベース、外部サービスといった、変化の激しい「外部」から隔離され、ビジネスの本質に集中します。
Coreの知識範囲における重要な注意点:
Coreは「純粋なビジネスルール」に焦点を当てるべきですが、そのルールを実装するために汎用的なUtilityライブラリの「使い方」に関する最小限の知識を含むことは許容されます。例えば、日付の計算に汎用的な日付ライブラリのメソッドを呼び出す場合などです。これは、Utilitiesが安定しており、変更が少ないという性質を持つためです。このような安定した汎用機能に対してまで、Coreが独自の抽象インターフェースを定義し、それを実装するアダプターを設けることは、かえってコードの複雑さを不必要に増し、オーバーエンジニアリングにつながる可能性があるため、実用上は避けられることが多いです。
2. Drivers (ドライバー):システムを動かす多様な入口
ユーザーや他の外部システムからの「入力」(Webリクエスト、コマンドラインからの命令、イベント通知など)を受け付け、それをCoreが理解できる形に変換し、Core分類のユースケースを呼び出す「システムの玄関口」となるコード群です。これはヘキサゴナルアーキテクチャのプライマリアダプターや、レイヤードアーキテクチャのプレゼンテーション層に相当します。
Drivers分類で使われるライブラリの例:
UIフレームワーク、CLIパーサー、そしてDI (依存性注入) ライブラリなど、Driverの構築と、Coreとの接続を管理するためのライブラリのみこの分類で使われます。
3. Integrations (インテグレーション):外部との安全な橋渡し
Core分類が「利用したい」と考える外部システム(データベース、外部Webサービス、ファイルシステムなど)との具体的な連携を担うコード群です。システムが外部へ「データを出力」したり「外部の情報を利用」したりする際の、あらゆる技術的詳細がここにカプセル化されます。これはヘキサゴナルアーキテクチャのセカンダリアダプターや、レイヤードアーキテクチャのインフラストラクチャ層に相当します。
Core分類は、このIntegrations分類が実装する抽象的なInterface(例えば、ユーザー情報を保存するリポジトリの約束事)にのみ依存します。
この分類には、外部システムと通信するための外部依存を持つライブラリ(例: データベースクライアント、決済APIクライアント、クラウドストレージSDKなど)が含まれます。Integrationsは、Coreのドメインモデルとこれらの外部ライブラリのインターフェース、そして外部システムのデータ形式との間で、必要なデータ変換(マッピング)を行う「橋渡し」の役割も果たします。
4. Utilities (ユーティリティ):汎用的な共通機能のハブ
特定のビジネスロジックや外部連携とは直接関係ないけれど、アプリケーション全体で繰り返し使われる、汎用的な補助機能を提供するコード群です。日付の計算、データ形式の変換、共通の入力チェック、時刻の管理などが含まれます。
この分類のコードは、外部依存がなく、非常に安定しているべきです。ここに汎用機能を集中させることで、コードの重複を防ぎます。
注意点:
「共通的に使われているからといって、何でもUtilitiesに放り込めばいい」というわけではありません。この分類は、特定のドメイン(ビジネス領域)に紐づかない、純粋な汎用処理であるべきです。もし、ドメイン固有の知識やビジネスルールがUtilitiesに紛れ込んでしまうと、それはもはや真のユーティリティではありません。例えば、「会員登録日の月末を計算する」といった処理は、一見汎用的に見えても「会員」というドメイン情報を含んでいます。このような処理をUtilitiesに入れてしまうと、ドメインの変更がUtilitiesにも波及し、結果的に変更容易性を損なってしまうことになります。Utilitiesは、「誰が使っても同じ結果になり、かつドメイン知識を一切含まない」 ようなコードを厳選して配置しましょう。
フェーズで考えるコードの成長戦略:焦らず、段階的に育てていくアプローチ
「よし、今日から全部のコードを4分類に完璧に分けよう!」—そう意気込む気持ちは分かりますが、ちょっと待ってください。最初から完璧なアーキテクチャを目指すのは、不必要に複雑になり、まだ見ぬ未来の要件のためにオーバーエンジニアリングになってしまったりすることがよくあります。
例えば、まだMVP(Minimum Viable Product)を作る段階なのに、何ヶ月もかけて複雑なアーキテクチャを構築してしまったら、市場のニーズが変わったときに全てが無駄になってしまうかもしれません。これこそが、機能を作る前に設計しすぎてしまう「オーバーエンジニアリング」の罠です。
もっと現実的で効果的なのは、プロジェクトの成長に合わせて、これらの分類を段階的に明確化し、コードを洗練させていくアプローチです。まるで、生まれたばかりのシステムを、必要に応じて少しずつ成長させていくように。これは、アジャイルな開発プロセスにも非常にしっくりきます。
フェーズ1:シンプルに始める「まずは動かす!」
状態: システムが最もシンプルに、特定の機能を迅速に実現することに注力する段階です。例えば、main関数のみだったり、単一のファイルの中に、ユーザーからの入力処理、簡単なビジネスロジック、データベースへの直接的な操作などがギュッと詰まっている状態です。
このフェーズへの移行きっかけ:
- 「とにかく早く動くものを作って、アイデアを試したい!」
- プロトタイプ開発やMVP(Minimum Viable Product)を市場に迅速に投入し、ユーザーの反応を見たい。
- プロジェクトが始まったばかりで、まだ要件が固まっていない。
良いコードへの収束: この段階では、将来の大きな変更や複雑な構造を考慮しすぎず、**まずは「動くものを作る」**ことに焦点を当てます。シンプルなほど、初期の変更は速く行えます。
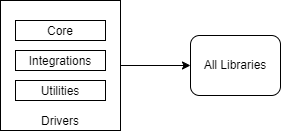
フェーズ2:Coreの分離「そろそろ整理しようか」
状態: ビジネスロジックの複雑性が増してきたら、システムの心臓部であるCore分類を明確に分離します。DriversはCoreに依存するようになり、ユーザーインターフェースとビジネスロジックの「関心事」が分かれ始めます。
このフェーズへの移行きっかけ:
- 「
main関数が肥大化しすぎて、どこに何が書いてあるか分かりづらくなってきた…」 - 「同じビジネスロジックを、Web画面からも、バッチ処理からも使いたいんだけど、コードが重複しちゃうな。」
- 「ビジネスロジックのテストを書きたいのに、UIの準備が大変でテストがしにくい。」
良いコードへの収束:
- 変更しやすい: UI(Drivers)の変更がCoreへ不必要に波及するのを防ぎます。これにより、ビジネスロジックへの影響を心配することなく、UIの変更や追加が容易になります。
- 分かりやすい: ビジネスロジックとUIの関心事が明確に分離されるため、それぞれのコードが何を担当しているのか理解しやすくなります。
- テストしやすい: Core分類のテストはDriversに依存せずに行えるようになり、そのテスト容易性が向上します。また、同じCoreロジックをWeb APIやコマンドラインといった異なるDriversから安心して再利用できるようになります。
これは、レイヤードアーキテクチャの基本的な考え方に近い分離の始まりです。

フェーズ3:Integrationsの分離「外部との境界線を引く」
状態: データベースや外部サービスとの連携が本格化したら、Integrations分類を導入し、Coreが外部の技術に直接依存するのをやめます。Coreは抽象的なInterface(約束事)を定義し、IntegrationsがそのInterfaceを「実装」する形に進化させます。
このフェーズへの移行きっかけ:
- 「Coreのビジネスロジックの中に、データベースアクセスや外部API呼び出しのコードが混ざっていて、読みにくいし、テストも大変…」
- 「もしかしたら、将来データベースの種類を変えるかもしれないし、外部サービスも増えるかも。」
- 「外部サービスの仕様が変わるたびに、Coreロジックまで直さなきゃいけないのが辛い!」
良いコードへの収束:
- 変更しやすい: データベースの変更や外部APIの仕様変更があっても、Integrations分類のコードだけを修正すればよくなり、変更による影響は Integrations 分類内に完全に局所化されます。これにより、Integrations分類自身の変更容易性を最大限に高めます。
- 分かりやすい: 外部システム連携の技術的詳細がIntegrationsに集約されるため、Coreのビジネスロジックがより純粋になり、読みやすくなります。
- テストしやすい: Coreが外部の技術詳細から独立するため、Core分類からIntegrations分類のモックを簡単に差し替えることで、Core分類のテスト容易性が飛躍的に向上します。外部依存を置き換えて高速かつ安定したテスト実行を可能にします。
これは、依存性逆転の原則 (DIP) の適用であり、ヘキサゴナルアーキテクチャやクリーンアーキテクチャの核となる考え方です。

フェーズ4:Utilitiesの独立「共通部品をまとめる」
状態: アプリケーション全体で汎用的に利用される補助機能が多くなってきたら、Utilities分類を独立させます。他の全ての分類から依存される、共通の便利な機能群となります。
このフェーズへの移行きっかけ:
- 「あっちこっちで同じ日付変換のコードを書いてるな…」
- 「共通のバリデーションロジックがいろんなところに散らばって、修正が大変だ。」
- 「汎用的な処理を直したら、予期せぬ場所でバグが出た…」
良いコードへの収束:
- 変更しやすい: 汎用的な機能が独立しているため、その変更が他の分類に与える影響が明確になり、管理しやすくなります。
- 分かりやすい: 共通部品がUtilityとして集約されることで、コードの重複が減り、全体が整理整頓され、理解しやすく、保守しやすいコードベースが実現します。
- テストしやすい: 外部依存がなく、非常に安定したコードのみを抽出するため、一度作成すれば頻繁な変更が不要となり、結果として全体の変更容易性に貢献し、単体テストも非常に容易になります。
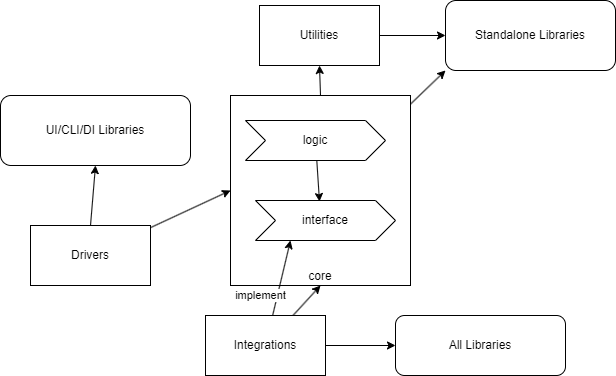
フェーズ5:Core内部の深層化「変化に合わせた最適化」
状態: Core分類のビジネスロジックがさらに複雑化し、その内部でも変更頻度に差が出てきたら、Core内部をビジネスの変更頻度に応じたグラデーションの層に細分化し、それぞれをInterfaceで疎結合にします。 これらの層は、Volatile logic(変更頻度が多いロジック)、Medium volatility logic(中くらいの変更頻度のロジック)、Stable logic(変更頻度が少ない安定したロジック)といったように変更頻度で区別されます。
このフェーズへの移行きっかけ:
- 「Coreの中の特定のロジックが頻繁に修正されるせいで、安定しているはずのCoreの他の部分まで影響が出てしまう…」
- 「ビジネスロジックが複雑すぎて、どこが本質で、どこが頻繁に変わるルールなのか、区別がつきにくくなってきた。」
- 「このビジネスロジックの変更頻度が、他の部分と明らかに違うな。」
良いコードへの収束:
- 変更しやすい: これは究極的な変更容易性の追求です。ビジネス要件の変更が最も頻繁に発生する部分だけを分離し、その影響範囲を Core 分類内の最小単位に局所化します。このグラデーションの層の数は、システムの複雑度やビジネスの変化の頻度によって柔軟に調整すべきです。
- 分かりやすい: Core内部の役割と変更頻度が明確になるため、コードベースのどの部分がビジネスの核であり、どこが変動しやすいのか、より詳細に理解できるようになります。
- テストしやすい: 各層が疎結合になることで、単体テストの範囲がさらに細かくなり、テスト容易性がさらに高まります。これにより、デバッグや機能追加のサイクルが短縮されます。
これにより、ビジネスのスピードに完璧に追従できる、極めてアジャイルなシステムが実現します。

まとめ:未来を見据えた設計のために
「良いコード」をいきなり完璧に目指すのではなく、プロジェクトの成長に合わせて、少しずつ「コードの分類」を明確にし、洗練させていく。この「4つの普遍的な分類」と、それを段階的に適用する「コードの成長戦略」は、あなたのシステムが変化を味方につけ、持続的に成長し続けるための、強力な羅針盤となるはずです。
これは、特定のアーキテクチャパターン(レイヤード、ヘキサゴナル、クリーンなど)をただ適用するだけでなく、それらの根底にある「関心の分離」「依存性逆転」「変更時の影響範囲の局所化」といった設計原則を、あなたのプロジェクトのフェーズとニーズに合わせて、賢く柔軟に適用するアプローチに他なりません。
今日からあなたのプロジェクトで、これらの分類と成長戦略を意識してみてください。完璧な一歩でなくても構いません。まずは、「このコードの役割は何だろう?」「変更するなら、どこに影響しそう?」と自問することから始めてみましょう。
これらの指針が、あなたのソフトウェア開発に役立つことを願っています。
Discussion