実プロダクトにおけるプロンプトチューニングはとても疲弊する仕事です。
出力が求める品質に満たない時にプロンプトを変更していく訳ですが、それによって他の品質が満たせなくなるリグレッションが起きたり、また、ある課題が100%の確率で起きるということはほぼなく、何回も繰り返し実行してその課題が起きないか確認する必要があったりします。
この疲弊しがちなタスクを効率化するために実験管理の環境を整えるのも大事なのですが、それにアドオンとして可能な限りLLMさんに自動でチューニングしていただけないかな〜と思い、手始めに先行研究を色々調べてみたのでそのリサーチ内容をまとめてみます。
NeuroPrompts
少し前にこちらの記事で話題になった方法です。
ざっくりまとめると「text-to-imageのプロンプトチューニングに特化した fine-tuning をしたモデルを作った」という内容です。
2章を読むに以下の方法で実現しています。
- GPT-2 に対して text-to-image のプロンプトデータセットで fine-tuning を行う
- 使ったデータセット: https://github.com/poloclub/diffusiondb
- 「エキスパートでない人が作ったプロンプトが、その人が求めるようなアウトプットになる」ための強化学習を行う
- NeuroLogic というアルゴリズムで decoding 時の出力に制約を持たせる
- キュレーションしてあったプロンプトのに使われるキーワードのセットがあり、その中から出力に使われるキーワードが選ばれるようにしている
おそらく考え方などはtext-to-textでも参考にできる部分があると思いますが、単語を並べるプロンプティングは t2i 固有で decoding 時に制約を入れるとかは使わなそう?
いつかはこういうプロンプトチューニングモデルを作ってみたさもありますが、短期的に仕事で使えるレベルのものはおそらくできないのですぐに応用はできないかなという所感でした。
Automatic Prompt Engineer
APE とも略して呼ばれるみたいです。
日本語でも詳しい解説記事があったので引用しますと
入力と出力のペアと,プロンプトのテンプレートを入力として与えることで,入力が与えられた時に正確に出力が得られるようにプロンプトテンプレートを最適化する
手法です。
- input の例と、そのインプットの時に期待するアウトプットの例のペアのリストを作る
- 求めるアウトプットが出る確率が高いプロンプトを生成してくれる
「求めるアウトプットが出る確率が高いプロンプトを生成」の部分に関してなのですが、モンテカルロ法のシミュレーションとしてLLMを活用し、LLMに前回のイテレーションでスコアが高かったプロンプトのバリエーションをたくさん作ってもらって、それを元に再度スコアを出させてその中からスコアが高いものからバリエーション生成...を繰り返しているそうです。
▼ バリエーション生成のプロンプト

これは結構筋が良さそうなアプローチに感じており、後述するのですが基本的にLLMによる自動プロンプティング研究は何らかの一般的な評価メトリクスを扱っており、プロダクト開発で扱うようなプロンプト毎に細かいプロダクト要求がある場合に、まず初手として「評価観点を作っていく」プロセスが必要になります。
ただ、事前に評価観点を洗い出すのは難しく、なぜなら、プロダクト要求のようなものはもちろん言語化すべきですが、それ以外の何回もやっていく中で「変に出力フォーマットが崩れる」とか「会話の返信文だけを求めてるのに全部の会話シミュレーションしてくる」とか事前に予期しようもない課題が山ほど出てくるからです。
このため、このプロセスは探索的にならざるを得ず、もぐら叩きのようになっていくのが疲弊する大きな要因なのかなと感じています。
ですが、APEでは期待するアウトプットの例を列挙すると、それに向かって最適化してくれるので、その「課題の洗い出し -> 対処」の手間が省かれるのではないかと期待ができます。
こちらに関しては複雑なプロンプト事例で試したらレポートなど別途書こうかなと思います(多分)
OPRO
Optimization by PROmpting の略です。
ORPOは昨年秋頃にLLMをアルゴリズムの最適化に使う手法として話題になりましたが、この論文中ではその ORPO の適用事例としてプロンプトチューニングがされています。
具体的にはメタプロンプトと名付けられた LLM にプロンプトを生成させるためのプロンプトがあり、これに達成したいタスクの説明と前回のイテレーションでのアウトプットとスコアのペアをインプットします。
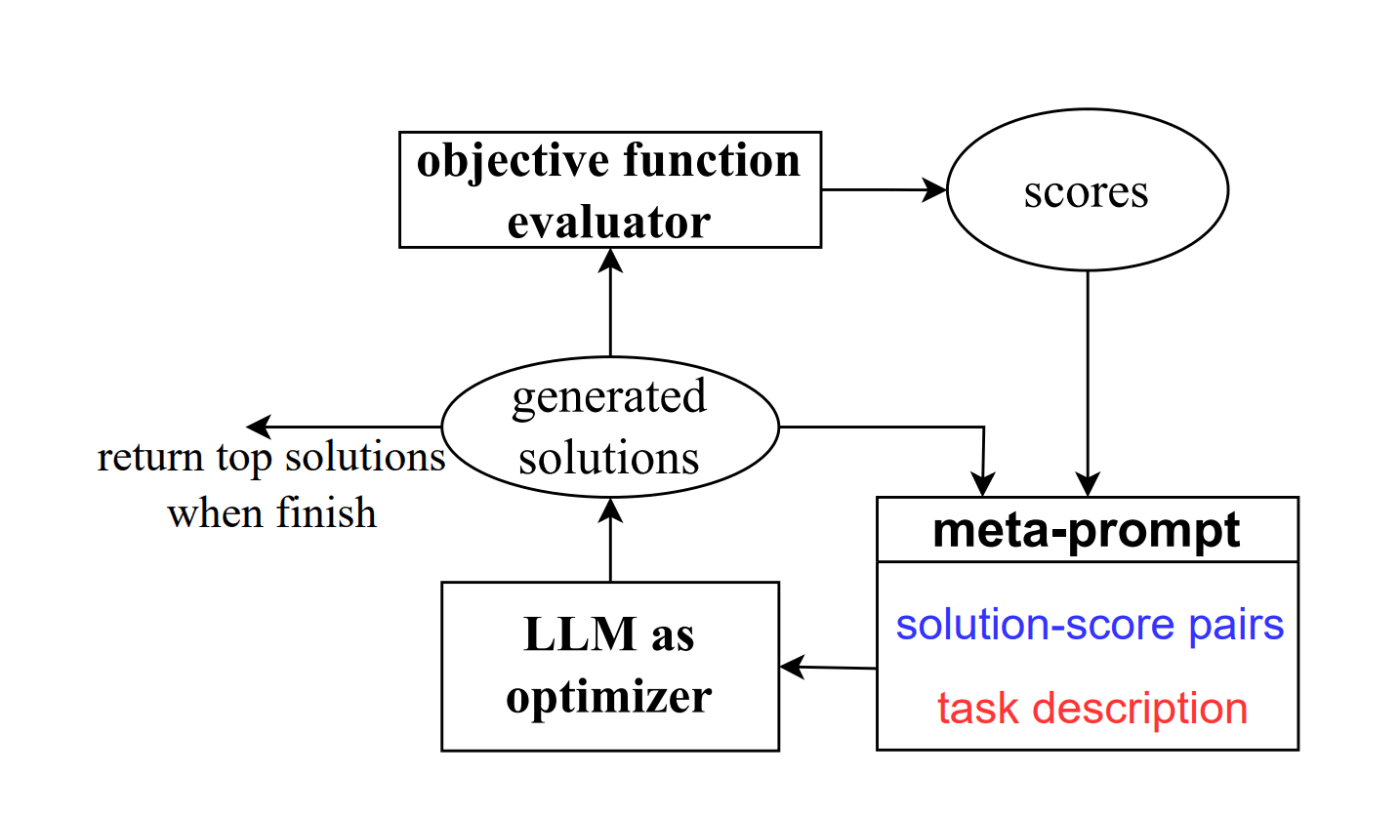
具体的なプロンプト例も Appendix に書いてあったので引用すると以下の通りです。
- Orange の部分が
meta-instruction、つまりはメタプロンプトのテンプレートのようなもの - 青の部分が今までの生成結果とスコア
- 紫の部分が最適化したい対象のタスクとアウトプットのフォーマットの説明

概念としては割とシンプルだなという所感です。
また、この論文内での参考事例には GSM8K というベンチマークデータセットが使われていて、実際のプロダクト開発においてはこの部分をどう用意するか?が依然として課題として表出してくるのかなと感じています。
EvoPrompt
名前から察せられる通り進化的アルゴリズムをプロンプトチューニングにも適した内容です。
下図のようにプロンプトの交配や突然変異をLLMにシミュレートさせて評価を実行し、スコアの高いものを次の世代で同じように変異させることを一定回数繰り返して精度を高めていきます。

初期のプロンプトに縛られず広い可能性を探索できていいなと思いつつ、こちらも ORPO の時に抱いた評価メトリクスをどう育てるか?の観点は気になってくるのかなと感じました。
ProTeGi
Prompt Optimization with Textual Gradientsの略です。
プロンプトの問題点を自然言語で記述した「勾配」を生成し、その勾配とは "逆方向" の空間からプロンプト候補を探索することによって効率的により良いプロンプトを求められるようにする手法です。
論文中では下記のプロンプトで新しい候補を生成しています。
I'm trying to write a zero-shot classifier.
My current prompt is:
"{prompt}"
But it gets the following examples wrong:
{error_str}
Based on these examples the problem with this prompt is that {gradient}
Based on the above information, I wrote {steps_per_gradient} different improved prompts.
Each prompt is wrapped with <START> and <END>.
また、勾配の生成も人間ではなく LLM がやっていて、wrong と判定するのは人間がやっています。
I'm trying to write a zero-shot classifier prompt.
My current prompt is:
"{prompt}"
But this prompt gets the following examples wrong:
{error_string}
give {num_feedbacks} reasons why the prompt could have gotten these examples wrong.
Wrap each reason with <START> and <END>
論文中の例は分類タスクで正解が一意に定まるため、他の会話などより定型でないタスクへの応用は課題がありそうな予感がしますが、自動改善のフレームとしてはアリなのかなと思いました。
DSPy Optimizers
多分最近一番人気がありそうな手法で、APEと似ているのですが、プロンプトに対してたくさんのInput/Output Example集と自動評価関数を作り、評価が最も高くなるようなFew showの組み合わせを探してくれます。(Few shotいじる以外もやってるのかな)
以下が Optimizer を使う時のサンプルコードです。(teleprompt というのは昔の名前ですが、ライブラリの方の変更が追いついてないのかもしれない)
from dspy.teleprompt import BootstrapFewShotWithRandomSearch
# Set up the optimizer: we want to "bootstrap" (i.e., self-generate) 8-shot examples of your program's steps.
# The optimizer will repeat this 10 times (plus some initial attempts) before selecting its best attempt on the devset.
config = dict(max_bootstrapped_demos=3, max_labeled_demos=3, num_candidate_programs=10, num_threads=4)
teleprompter = BootstrapFewShotWithRandomSearch(metric=YOUR_METRIC_HERE, **config)
optimized_program = teleprompter.compile(YOUR_PROGRAM_HERE, trainset=YOUR_TRAINSET_HERE)
ライブラリの作者はこれを"PyTorchにインスパイアを受けている"と言っており、私は最初は「どのあたりがPyTorchインスパイア?」と思っていたのですが、さながらニューラルネットワークの backpropagation のように評価(=損失関数)を元にプロンプトの内容を変えていくことからそう呼んでいるのではないかと考えています。(多分合ってる)
こちらでハードルになりそうだなぁと思うのは、これはもう全ての手法に対して思ってますが、自動で評価を算出するロジックを作るところです。
意外とそこの精度はテキトーでも品質上がるのかもしれないですが、Humans-in-the-loop で評価の部分は人間がポチポチするだけみたいなことができたらチューニングに頭を使わなくなっていいかもしれないなぁ、などと妄想しています。
マニュアルフィードバックループ
人間は改善点だけを伝えてLLMに最適化させるループを回す手法です。("マニュアルフィードバックループ"は勝手に私がそう呼んでいる)
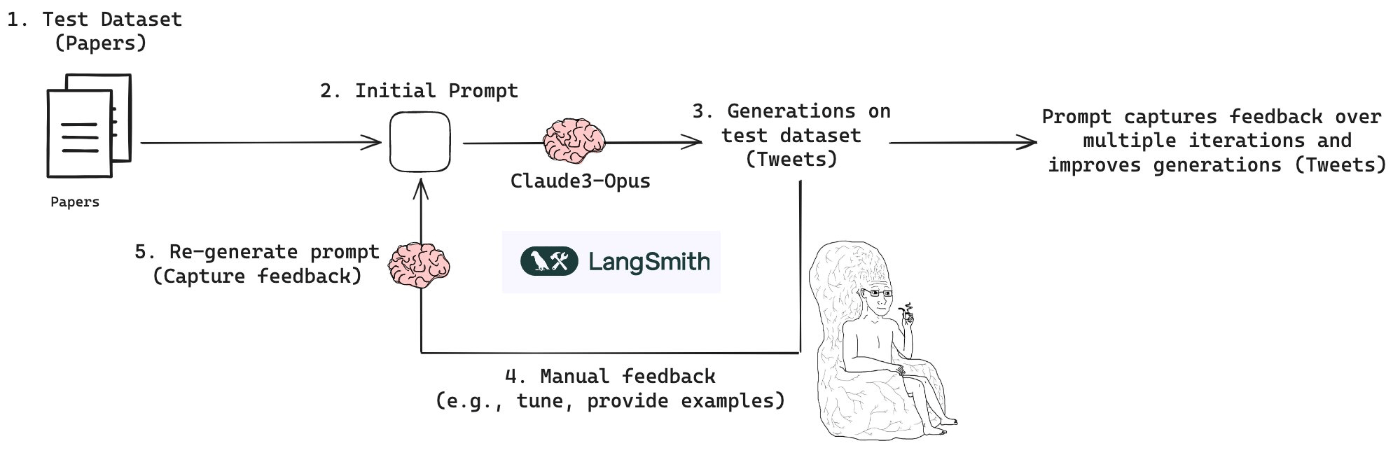
ただ、こちら私も以前軽く試してみたことがあるのですが、プロダクトの中で手に入れようのないデータを勝手に作ったプロンプトを作成して利用できない、など課題もポロポロ見えてきたので、そんなシュッと動く感じではないかなと思いました。
まとめ
以上プロンプトチューニングを自動化する手法をまとめてみました。
大きくは2パターンに分かれるのかなと思い
- インプットと期待するアウトプットの例をたくさん用意して、そこからいい感じに生成する
- NeuroPrompt のようにプロンプトチューニングができるモデルに fine-tuning
- APE
- 評価メトリクスを用意しループを回して最適化させていく
- ORPO
- EvoPrompt
- ProTeGi
- マニュアルフィードバックループ
今後は APE を試しつつ、実験管理環境を整えて評価メトリクスを育てていきながら上記のような最適化アルゴリズムも適用する、みたいなプロセスを作っていくのにトライしてみようかなと考えています。
他にもご存知の最適化手法があったらぜひ教えてください、切実に求めてます。
それではお読みいただきありがとうございました!👋

Web3スタートアップ「Gaudiy(ガウディ)」所属エンジニアの個人発信をまとめたPublicationです。公式Tech Blog:techblog.gaudiy.com/
Discussion