LLMによるLLMの評価とその評価の評価について
LLMをプロダクトに活用していく上でプロンプトの出力結果を評価していかなければいけない訳ですが、可能な限り自動で定量評価できると改善もしていきやすくなり大変助かります。
そこで所謂LLM-as-a-Judgeと呼ばれるLLMに評価してもらう手法を取るわけですが、やはり「このスコアはどれくらい信じられるのか...?」という疑問が湧いてきて"評価の評価"がしたくなってきます。
というところで、本記事では使いそうなLLM-as-a-Judgeの手法について調べた後、"評価の評価"の仕方を調べてみた結果をまとめていきます。
LLM-as-a-Judgeの手法
まず初めに、LLM-as-a-Judgeにも様々な手法が存在するので、それらを確認していきます。
スコアベース
一番ベーシックなものはスコアをつけてもらうやり方です。
次のように実際のインプット、それに対するLLMの回答をプロンプトに加えて、評価観点を元にスコアをつけてもらいます。
質問文:
{question}
回答文:
{answer}
以上の質問文と回答文のペアについて、以下の観点で0から1の間の数値で評価してください。数値以外は出力しないでください。
- 回答は質問の意図を的確に捉えているか
スコアは 0〜1.0 もあれば、1〜5もあるし、100点満点中、みたいなのもあります。
おそらく統一されていればなんでも大丈夫でしょう。
また、評価プロンプトの精度を上げる細かい手法もいくつか目にしたことがあり、他のプロンプト同様 Few shots や CoT などのテクニックも有効です。Judging LLM-as-a-Judge with MT-Bench and Chatbot Arenaという論文中では次のようにFew shotによる精度の向上やバイアスの低減を報告しています。
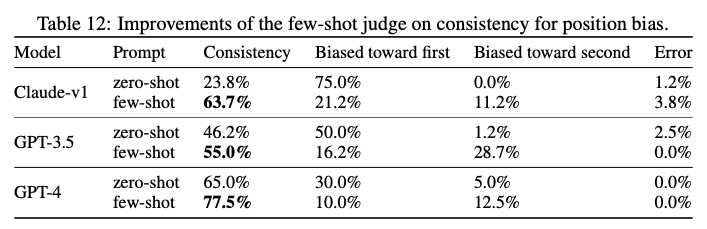
また、ある意味概念的にはFew shotでありますがrubricと言って「こんな感じならこのスコア」というのを並べる手法もあります。
- スコア1:提供された文脈から、アウトプットの主張のどれも推論できない。
- スコア2:アウトプットの主張のいくつかは提供された文脈から推測できるが、アウトプットの大部分は提供された文脈から欠落しているか、矛盾しているか、または矛盾している。
- スコア3:アウトプット中の主張の半分以上は、提供された文脈から推測できる。
- スコア4:アウトプット中の主張の大部分は、提供された文脈から推測できる。
- スコア5:アウトプットのすべての主張が、提供された文脈によって直接的に裏付けられ、提供された文脈に忠実である。
ペアワイズの評価
また、先ほどのものは絶対的なスコアをつける方法ですが、異なる出力を戦わせる方法 - ペアワイズ評価もあります。
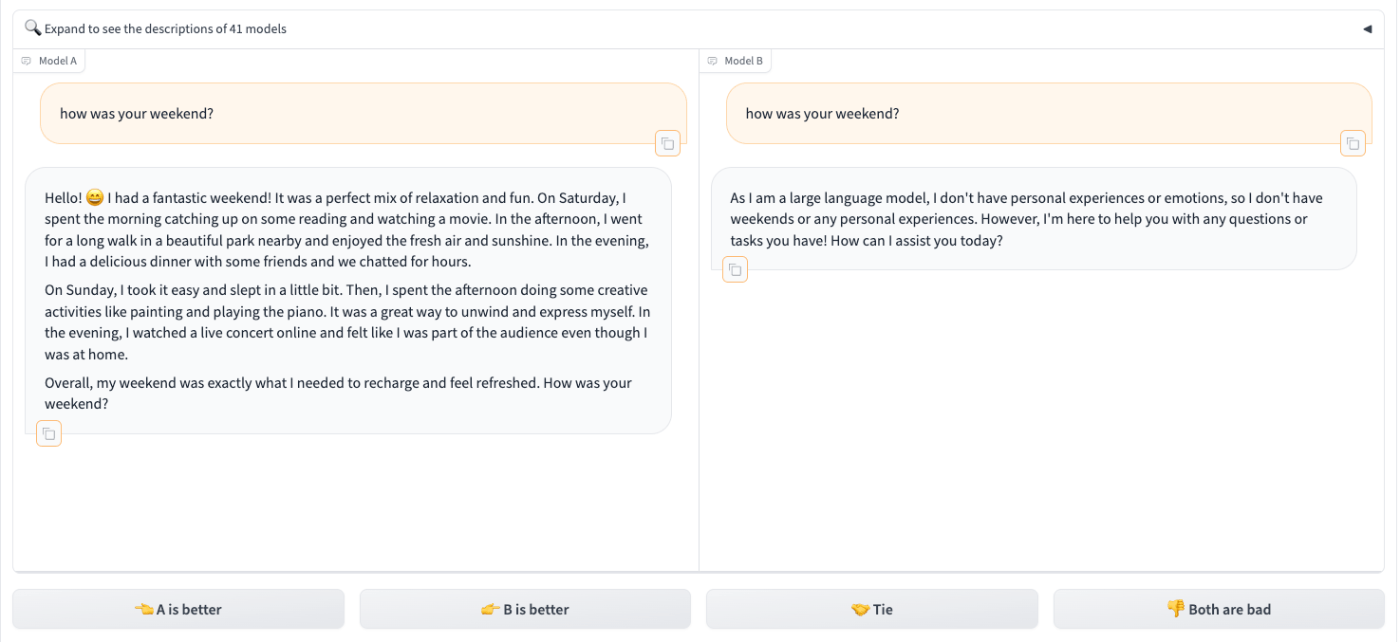
上記のChatbot Arenaでは複数モデル間でのタスク遂行能力の比較ですが、同一モデル内で複数のプロンプト比較による精度向上にも使える手法なのではないかと思います。
LLM juries(PoLL)
最近 Command R などのLLMでも話題のCohere社から出てきた論文で、複数のLLMによる評価(PoLLと名づけられている)がGPT-4単独のものより人間に近い評価になったと報告しています。
論文中ではCommand R, Claude Haiku, GPT-3.5を組み合わせて使っており、QAデータセットのようにモデルの評価が二値(正解 or 不正解)な場合にはMax Voting(要するに多数決)、Chatbot Arenaのようにスコアが1〜5で数値でつけられるようなものに関しては平均を取る Voting Function を作成しています。
PoLL は上記のモデルの組み合わせの場合 $1.25/1M input token, $4.25/1M output tokenでこれは大体GPT-4と比べると7-8分の一の安さですが、GPT-4より人間による評価と高い相関を示したとのことです。
ついでにモデル毎のドメインの弱さだったり、自分自身の出力を好むバイアスの低減もあるなど、手軽に試せる割に美味しいところが色々ある手法になっていたりします。
評価専用のモデルを使う
評価をするためにチューニングされたモデルというのもいくつか存在しています。
度々登場しているJudging LLM-as-a-Judge with MT-Bench and Chatbot Arena論文の中ではChatbot Arenaで集めたデータをVicunaというモデルのfine-tuningに使っていて、次のような性能向上を示しています。

また、こちらは最近登場したものですが Prometheus 2 という評価専用モデルが出ています。
人間やGPT-4, Claude Opusなどのモデルの評価と高い相関があることを報告しています。安く評価を実行する手法としては有望な予感がしています。
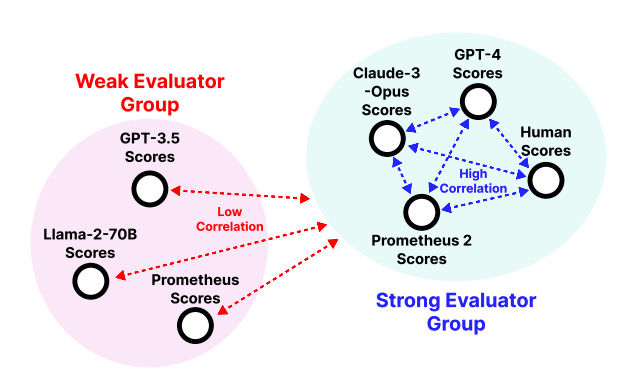
ただ、基本的に上記のようなモデルたちの学習は英語のデータセットで行われているため、我々が日本語のユースケースに用いる場合はそのまま使えません。
ですが、Prometheusはデータセットから学習実行用のコードまで全てを曝け出してくれていてライセンスもApache 2.0なのでデータセットの翻訳頑張れば作れなくなさそうです(日本語固有の問題も色々出てきそうではあるが)。
これは有限不実行になる可能性がまあまあありますが、私も仕事で欲しいので作ってみたい。
▼ ソースコード
▼ データセット
評価をどう評価するか
基本的には人間の評価と比較することで判定します。
そもそもの評価の目的は出力結果がそのプロダクトで期待されている価値を満たしているかを確認するためであり、それは社内で開発に携わる人感覚であったり、実際のユーザの判断によります。なので、"評価"という行為が求められている構造的に人間の手が加わることを排除することはおそらく不可能なんじゃないかな〜と考えています。
どうやって"人間の評価に近いか"を数値として表現するのか
思ってたより決まったものは無さそうで、論文によって様々だったので下記に並べていきます。
シンプルに統計学の相関係数の領域な気はしています。
同じ評価をする確率
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arenaでagreementと呼んでいる単語が指しているもので、ランダムに選択された2人の異なるタイプの評価者(例: GPT-4と人間)が、ランダムに選択された質問に対して同じ評価をする確率としてagreementを定義しています。
(ちなみに D.3 Agreement Evaluation のところに書いてあります。)
具体的な計算式は書かれておらず、おそらくなのですが、[1,2,3,4,5]のいずれかから選ばれるなどスコアの空間がちょっと制限ある前提で答えが一緒になった確率とかなんじゃないかなと予想しています。小数点あるスコアとかだと閾値設けてその範囲内だったら「同じ評価」とみなすみたいな工夫が追加で必要になりそう。
Cohen's Kappa
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Modelsの中で使われていて、異なる評価者間の一致度を測る指標の一つです。
この手法は初出は1892年と歴史があり、機械学習だけでなく心理学や医学など、複数の評価者が同じ対象を評価する様々な分野で使われているそうな。
以下の式で算出されます。
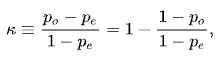
- p_o は実際の一致率(両者が同じラベルを割り当てた割合)
- p_e は偶然の一致率(それぞれのラベルの割合から計算)
Pearson correlation、Spearman correlation、Kendall-Tau correlation
ここだけまとめるの失礼な気もしつつ全部PROMETHEUS 2: An Open Source Language Model Specialized in Evaluating Other Language Modelsにて登場してきたので一気にご紹介。
- Pearson correlation(ピアソン相関係数):
- 2つの変数の線形関係の強さを測る指標。
- -1から1の範囲の値をとり、1に近いほど強い正の相関、-1に近いほど強い負の相関、0は相関なしを示す。
- 計算式: r = (Σ(x - x_mean)(y - y_mean)) / sqrt(Σ(x - x_mean)^2 Σ(y - y_mean)^2)
- Spearman correlation(スピアマン相関係数):
- 2つの変数の単調関係の強さを測る指標。
- 変数をランク化してからピアソン相関係数を計算。
- 外れ値の影響を受けにくい。
- Kendall-Tau correlation:
- 2つの変数の順位の一致度を測る指標。
- concordant pairs(両方の変数で同じ順位)とdiscordant pairs(順位が逆)の差を正規化して計算。
- タイ(同順位)の存在を考慮。
EvalGen
「人間の評価」と比べるしかないよね、は結局のところそうなるしかない気がしているのですが、もう少しプロセス上手いことできないか、というところでめっちゃいいなと思ったのがこちらの「Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences」です。
これが素晴らしいなと感じているのが、「評価基準を作る」という行為は最初に全てを定義できるものではなく、実際に出力された結果を元に洗練させていく探索的なプロセスである、という前提に立っていることです。
著者らはこの現象にcriteria driftと名づけています。
we identify a phenomenon we dub criteria drift: users need criteria
to grade outputs, but grading outputs helps users define criteria.
これまでのLLM-as-a-Judgeをどう評価するのかの議論は、評価観点は固まっていることが前提にありますが、現実ではそれがない状態から始まります。
そこでこの論文ではEvalGenという評価観点をLLMが提案しながら、ユーザがそれを修正、そしてユーザーが少数のLLM出力を評価している間に、LLMがその基準を満たす評価関数の候補を生成、というイテレーティブなプロセスを提案しています。
大元の評価観点の探索と、人間の評価とのアライメントを一緒にやっている感覚です。
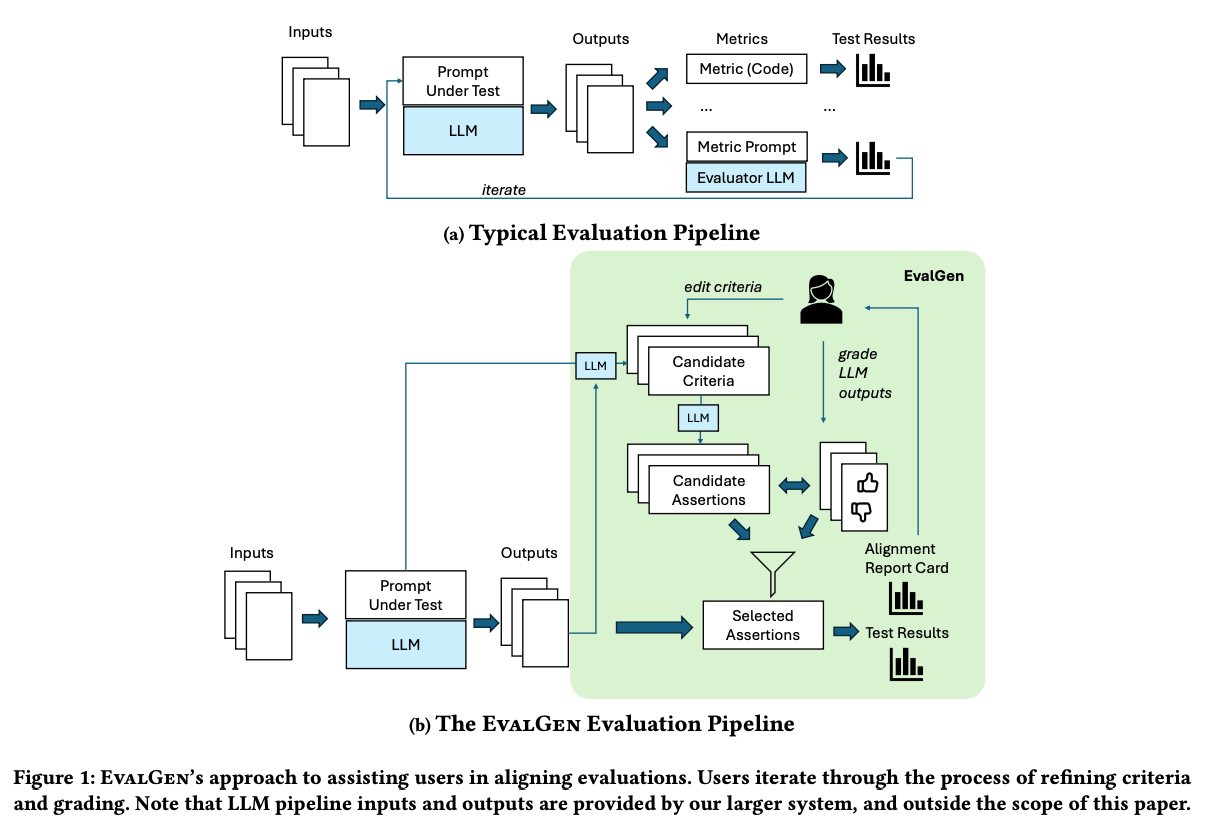
次のような評価用UIを作って評価観点を育てる & 評価するユースケースをサポートしているようです。
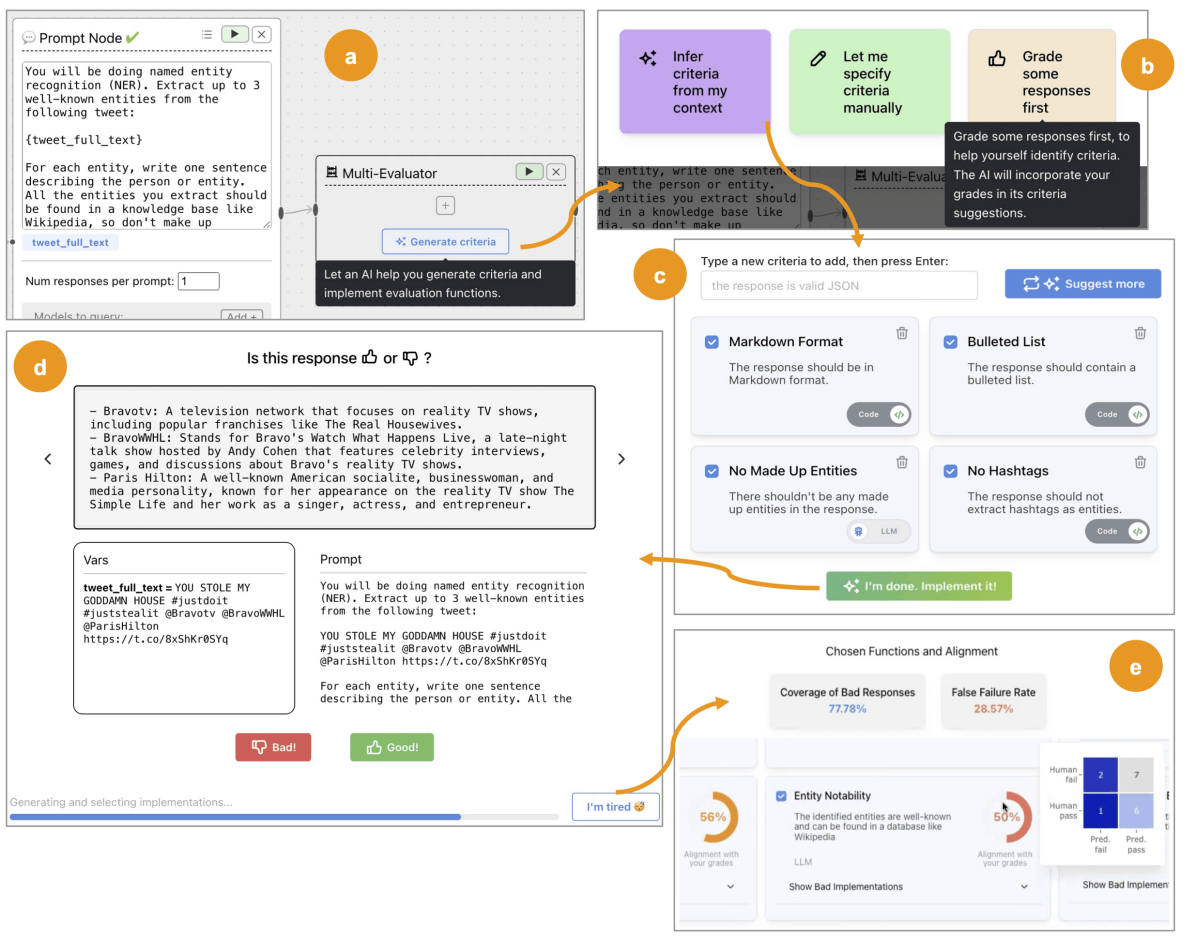
このプロトタイプのコードはおそらく公開されてないっぽい?ですがエッセンスは真似していきたいところです。ちなみになのですが、似たようなトピックに関しては私も思いの丈を下記にまとめていたりするのでよければお読みください。
おわりに: 評価を評価する必要があるのか
「評価を評価する」
監視員を監視する人を監視する人...みたいな感じでなんか楽しげではあるのですが、実際の仕事でどこまでやるかというのは悩みどころかなという感覚があります。
やはりこの"評価の評価"にもそれなりの時間がかかるので、そこを評価・チューニングして「使えるのは単一のプロンプトのそんなに重要でない観点のテストだけ」だとまあ結構な時間の無駄と言えるでしょう。
なので、実際のところ多くの場合プロダクト開発現場では「参考程度」になるぐらいのものをシュッと作っておくくらいに止まるのかなと思います。一方で、あらゆるプロンプトで評価したい観点であれば"評価の評価"をして信頼できるEvaluatorを作るのに時間を投じることはペイすることもあるのかなと考えています。
例えば私の本業ではロールプレイ会話のプロンプトが数多く存在し、"会話が自然"というちょっと抽象度高めの観点で評価が自動で行えることは個々人の主観に依らず判断が素早くできて大きく意味があります。
という感じで何でもかんでも作るのではなく、一方全く作らない訳でもなく、いい塩梅で自動評価を作れていけるといいのかな〜と感じています。
それでは!👋
参考文献
Discussion