この記事は#GauDev Advent Calendar 2025の2日目です。
音声対話アプリケーションを開発する際、ユーザー体験を大きく左右する主要な課題の一つが、ターンテイキングの制御(発話の交代)です。本記事では、この技術における一般的な課題を概説した上で、LiveKitを用いて開発中のアプリケーションで発生した具体的なUX課題と、その解決のために行ったVADとTurn Detectionのパラメータ調整事例を紹介します。
ターンテイキングにおける技術的な課題
普段、人間同士の会話では、無意識のうちに以下のような複雑な判断を行っています。
- 相手が話し終わったかどうか
- 相手が考えている途中の沈黙なのか、発話が完了したのか
- 相手の発言に割り込むタイミングはいつか
など。これらの判断は言葉そのものだけでなく、イントネーション、間の長さ、会話の文脈など多くの要素を総合的に考慮して行われています。
発話終了検出の難しさ
音声対話システムにおける発話終了(End of Turn, EOT)の正確な検出は、AIエージェントが人間らしい対話を実現するための最大の課題です。
VADとEOU/EOTの違い
ここで混同されやすいのが、VADが検出するEOU(End of Utterance:音声が途切れた瞬間)と、ユーザーが実際に話し終えたEOT(End of Turn:発話が完了した瞬間)との違いです。
VADの役割(EOUの検出)
VAD(Voice Activity Detection)とは、音響信号から音声区間を非音声区間から物理的に識別する技術であり、一般に広く利用されるSilero VADのようなモデルは、入力された音声フレームに対して「人間の発話」の有無を高速かつ高精度に確率推定します。
VADの限界(EOTの誤判定)
しかし、VADが検出するEOUと、実際のEOTは異なります:
ユーザー: "週末はアニメを見たり、あとは..." [0.5秒沈黙] "読書をしたりします。"
↑ EOU ↑ EOT
VAD: "0.5秒無音だから発話終了" → 誤判定
VADは音響的な無音しか判断できず、会話の文脈や言語的な意図を理解できません。
LiveKitのTurn Detectionモデル
こちらのブログでも書かれているように、上記のような問題からLiveKit独自のTurn Detectionモデルを開発しており、このモデルは与えられた会話コンテキストから文法的な構造や、話された内容を分析し、「本当にターンが終わったか(EOT)」の確率を計算します。
# VADによるEOU検出後
probability = await turn_detector.predict_end_of_turn(chat_ctx)
if probability < unlikely_threshold:
# まだ話が続いている可能性が高い → 長く待つ(割り込み防止)
endpointing_delay = 3.0秒
else:
# 話し終わった可能性が高い → 通常の待機時間で応答
endpointing_delay = 1.2秒 # 発話完了
それでも完璧ではない
1. 人の話し方の多様性
人間の話し方には、話すテンポが速い、ゆっくり考える、言い直しが多いなど、大きな個人差があり、モデルが一律で最適な発話区間を検出することを難しくしています。
2. サービスの特性による最適値の違い
サービスの目的や性質によって、検出の「最適値」が異なります。例えば、カスタマーサポートやインタビュー、あるいはオンライン会議では対話の様式が異なるため、単一のモデルで全てのシーンに完璧に対応することはできません。
3. リアルタイム性とのトレードオフ
-
待機時間を長く設定すると、話者の区切りを正確に判断できるようになり、誤判定は減少しますが、その分処理が完了するまでの応答遅延は増加する。
-
反対に、待機時間を短く設定すると、応答速度が向上し、リアルタイム性が高まるが、発話の終了判定が不十分になり、誤判定が増加する傾向がある。
よって、これらを考慮したパラメータの調整が必要です。本記事では、実際の問題を改善した事例を紹介します。
実際に発生したUX課題
現在、LiveKitを用いて音声対話型のエージェントアプリケーションを開発しています。ChatGPTの 1 対 1 の音声モードのようなものをイメージしてもらうと分かりやすいと思います。開発の過程で、以下のような問題が頻繁に発生しました。
今回、LiveKitについての詳細説明は省きますが、LiveKitとはWebRTCをベースにリアルタイムの音声・映像メディアを取得・エンコード・処理・送受信まで扱えるOSSの通信基盤です。こちらのドキュメントを参照してください。
1. ユーザーメッセージの不自然な分割
- ユーザーは1つの発言をしているつもりなのに、UIには複数のメッセージとして表示される
- 1つの文章が不自然に分割されて、視覚的なノイズになっている

2. エージェントの不自然な割り込み
- ユーザーが話している途中や思考中に、「発話終了」として判断され、割り込まれる
- 人間同士の会話では起こらない不自然なタイミングでの応答
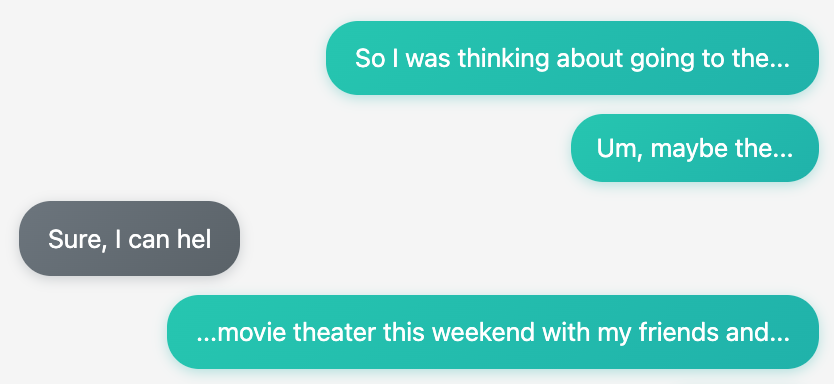
解決方法
結論から言うと、「VADでの音声切り出し」と「Turn Detectionでの応答判断」、この2つのタイミングを調整することで解決しました。判定まで時間を少し増やしたため若干の応答の遅さは許容することになりましたが、結果として対話の自然さなどのUXは大きく向上しました。
from livekit.agents import AgentSession
from livekit.plugins import silero
from livekit.plugins.turn_detector.multilingual import MultilingualModel
vad = silero.VAD.load(
min_silence_duration=1.2, # 0.55秒 → 1.2秒に延長
min_speech_duration=0.05,
activation_threshold=0.5,
)
session = AgentSession(
turn_detection=MultilingualModel(),
vad=vad,
min_endpointing_delay=1.2, # 0.5秒 → 1.2秒に延長
max_endpointing_delay=5.0, # 3.0秒 → 5.0秒に延長
# ...
)
LiveKit Agentsの音声処理フロー
では、実際にどのような流れで音声が処理されているのか、これらのパラメータがどのように作用するのか解説します。
1. VAD(Voice Activity Detection)
最初のステップは音声アクティビティ検出です。Silero VADは32ms毎にONNXモデルで音声の有無を判定します。
処理フロー
- 音声フレームの受信
- ユーザーから送られてくる音声を、32ms ごとに 1 フレームとして処理する。
- 音声か無音かの判定
- 各フレームについて音声確率を計算。
- 音声確率が
activation_threshold(例:50%)以上 → 音声と判定 - 音声確率が
activation_threshold未満 → 無音と判定
- 音声と判定されたフレームの処理
- フレームをバッファに追加。
- 音声状態が
min_speech_duration(例:0.05秒)以上 続いたら
→START_OF_SPEECHイベントを発火。
- 無音が続いた場合の処理
- 無音状態が
min_silence_duration(例:1.2秒)以上 続いたら
→END_OF_SPEECHイベントを発火。
- 無音状態が
- 音声データの送信
- バッファに保持していた 1つの発話(完全な音声区間) とイベントをまとめて送信。
if (pub_speaking and silence_threshold_duration >= self._opts.min_silence_duration):
pub_speaking = False
pub_silence_duration = silence_threshold_duration
self._event_ch.send_nowait(
agents.vad.VADEvent(
type=agents.vad.VADEventType.END_OF_SPEECH,
samples_index=pub_current_sample,
timestamp=pub_timestamp,
silence_duration=pub_silence_duration,
speech_duration=pub_speech_duration,
frames=[_copy_speech_buffer()],
speaking=False,
)
)
発話終了するために必要な無音時間を調整することで、息継ぎや言葉を選ぶ際の短い沈黙で、VADが誤って END_OF_SPEECH を発火することを防止しました。それによりユーザーのひとつのまとまりであるメッセージが不要に分割されてしまう課題を修正しました。
VADの無音判定を1.2秒に伸ばしたことで、最速でも1.2秒の応答ラグが発生しますが、意図しないタイミングで文が切断されるストレスと比較して、こちらの設定の方がユーザー体験が良いと判断しました。
2. STT(Speech-to-Text)
VADから受け取った音声フレームをテキストに変換します。
処理フロー
- 音声区間の受信
-
END_OF_SPEECHイベントとともに、バッファリングされた音声フレームを受け取る
-
- STT
- 受け取った音声をまとめてテキスト変換
- 結果の出力
- 確定したテキスト
FINAL_TRANSCRIPTを出力
- 確定したテキスト
3. Turn Detection
STTからFINAL_TRANSCRIPTイベント受け取った後、直近の会話履歴を元にEOTの推論が実行されます。
処理フロー:
-
FINAL_TRANSCRIPTの受信- STTから確定したテキストを受け取る
- EOT推論の実行
- 直近の会話コンテキスト、STTの文字起こし結果を元に、ユーザーの発話が続くかどうかを推定。
- 待機時間(delay)の決定
- 発話終了の確率が低い
→max_endpointing_delay(例:5.0秒)だけ待機。 - 発話終了の確率が高い
→min_endpointing_delay(例:1.2秒)だけ待機。
- 発話終了の確率が低い
- ユーザーの割り込みを監視
- 待機完了 → ターン終了
- ユーザーの発話が終了したと判断し、ターン終了を確定する。
-
on_end_of_turnを実行し、LLMレイヤーへ処理を移す。
end_of_turn_probability = await turn_detector.predict_end_of_turn(chat_ctx)
unlikely_threshold = await turn_detector.unlikely_threshold(self._last_language)
if end_of_turn_probability < unlikely_threshold:
endpointing_delay = self._max_endpointing_delay
else:
endpointing_delay = self._min_endpointing_delay
Turn Detectionモデルがターンの終了と判定した場合の待機時間を延長することによっても、不自然なメッセージの分割や、エージェントによる割り込み処理が発生しづらくなりました。また、「まだ続きがありそう」と判断した場合の待機時間も延長することで同様の課題を解決しました。
4. LLM推論と応答生成
ターン終了が確定すると、LLM推論が開始されます。(LLM推論以降の詳細は省きます)
まとめ
音声対話型アプリケーションにおいて、ターンテイキングは最も重要かつ難易度の高い課題です。細かいパラメータの調整が大事です。
- min_silence_duration(VAD): 物理的な無音の検出
- min_endpointing_delay(Turn Detection): 発話終了の基本待機時間
- max_endpointing_delay(Turn Detection): 文脈を考慮した最大待機時間
今回のケースでは、これら3つのパラメータを調整することで:
- ユーザーメッセージの分割問題を解決
- 思考中の長い間にも対応可能
- より自然な会話体験を実現
- 応答速度も実用的な範囲を維持
ただし、値を大きくしすぎると応答が遅く感じられる可能性があるため、トレードオフを考慮する必要があります。
#GauDev Advent Calendar 2025、明日の担当はMochidukiさんです
参考リンク

Web3スタートアップ「Gaudiy(ガウディ)」所属エンジニアの個人発信をまとめたPublicationです。公式Tech Blog:techblog.gaudiy.com/
Discussion