こんにちは。株式会社GaudiyでAnalytics Engineerをしている星野(@mochigenmai)です。
この記事は #GauDev Advent Calendar 2025 の1日目の記事です。
昨今、生成AIを用いたデータ抽出(Text-to-SQLやMCPでのセマンティックレイヤーの操作など)の構築にトライしている方は多いのではないでしょうか。その文脈の中で「生成AIとディメンショナル・モデリングは相性が良い」という話を耳にすると思います。
しかし、整備したデータを利用してデータ抽出をさせても、以下のような問題に当たることはありませんか?
「簡単な集計はできるけど、少し複雑になるとハルシネーションを起こしてしまう」
「プロンプトチューニングをしてみるも、他の集計でうまくいかなくなってしまう」
こうなると、原因が自分の指示(プロンプト)の拙さにあるのか、そもそもデータ構造がAIにとって理解しにくいのか分からなくなってしまいます。
この記事では、プロンプトを固定化させ、AIの出力をベースにデータ基盤をアップデートしていく方法を紹介しようと思います。
なぜ生成AIとディメンショナル・モデリングは相性が良いのか
ディメンショナル・モデリング(Dimensional Modeling)は、データを分析しやすく、理解しやすい形式で整理することを目的としている手法だからだと考えます。大きく以下の2点がAIとの相性が良い理由なのではないかと思います。
1. スキーマが「測定(Measurement)」と「文脈(Context)」で分かれている
ディメンショナル・モデリングでは、測定に関する情報は Fact。文脈に関する情報は Dimension で保持します。これによってテーブルやカラムの探索が容易になるのと同時に、集約関数に入れるべきカラム、フィルターすべきカラム、ブレイクダウンすべきカラムをルールベースで決められるようになります。
▼ Fact テーブルの構成要素
| 要素 | 説明 |
|---|---|
| サロゲートキー | データ基盤で作成する Fact/Dimension のキー |
| ナチュラルキー | プロダクトDBで利用しているキー |
| 測定項目 | 集約関数の中に入るカラム(ナチュラルキーもそのうちの要素になる) |
| 日時 | ビジネスイベントが発生した日時 |
▼ Dimension テーブルの構成要素
| 要素 | 説明 |
|---|---|
| サロゲートキー | データ基盤で作成する Fact/Dimension のキー |
| ナチュラルキー | プロダクトDBで利用しているキー |
| 文脈項目 |
GROUP BY や ORDER BY で利用したいカラム |
| その他付随する情報 | テキスト情報などレコードの詳細を理解するのに必要なカラム |
2. 会社固有の「ドメイン知識」をスキーマに埋め込める
優秀なデータアナリストは、社内のドメイン知識(暗黙知)を脳内に持っているため、複雑なデータも正しく扱えます。例えば、「このフラグが立っているときは集計対象外」といったサービス固有の仕様や、「データ転送遅延による特定時間の欠損」といったデータ基盤の癖です。これらをAIにプロンプトだけで教え込むのには限界があります。
ディメンショナル・モデリングを行うということは、これらの「地雷」を避けるためのロジックをスキーマ設計の中に押し込むことを意味します。正規化・クレンジング済みの状態にしておくことで、AIは暗黙値にぶつかることなく、シンプルなSQLを書くだけで正解に辿り着けるようになります。
とはいえ、ディメンショナル・モデリングされているデータだけでは不十分
しかし、完璧なスタースキーマがあっても、AIが期待通りのデータを抽出してくれるとは限りません。
AIに指示を出す人間のデータ抽出要件不足が問題になってきます。
例えば、「キャンペーンAの参加状況を知りたい」と依頼した時に「参加とは何か(閲覧か、応募か)」「状況とは何か(人数か、率か)」は依頼者によってイメージしているものが異なります。しかし、AIは要件を詳細に聞かずに、最初に閲覧データを見つけた場合その結果を返してきてしまい、思っていたものと違うといった事象が発生してしまいます。
そこで活用したいのが、BEAM✲(Business Event Analysis & Modeling)フレームワークです。
BEAM✲を取り入れたデータ抽出
BEAM✲とは
BEAM✲は、アジャイルなデータウェアハウス設計のためのフレームワークです。「モデルストーミング」と呼ばれるワークショップ形式で、レポート・分析要件から様々なビジネスイベント(Who does what?)を洗い出します。
この時に7W(Who, What, When, Where, How, How Many, and Why)で詳細を詰めることで汎用的に利用できるFact/Dimensionを設計可能にします。
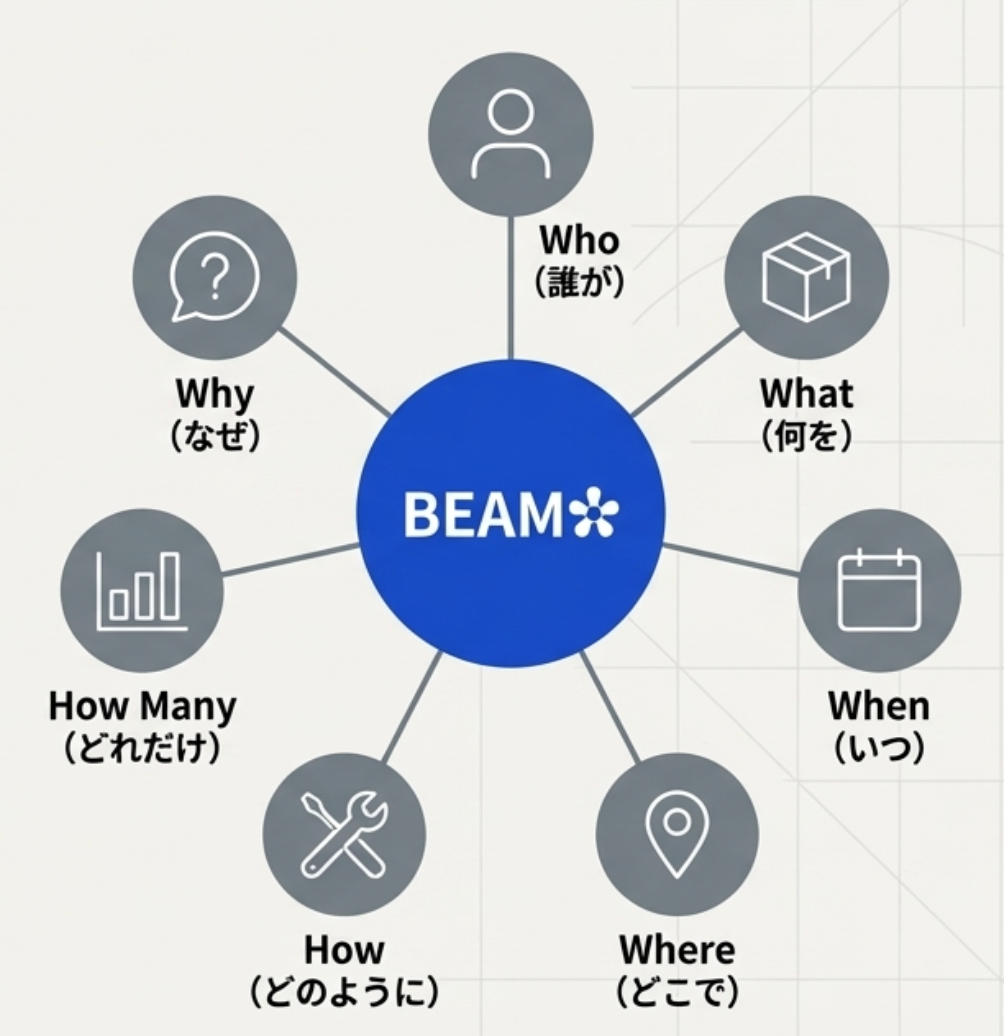 BEAM✲フレームワークにおける7Wの要素
BEAM✲フレームワークにおける7Wの要素
7Wで要件整理を行い、データを探索・抽出させる
分析要件からビジネスイベントを見つけ出し、ディメンショナル・モデリングを設計するフレームワークなのであれば、分析要件からビジネスイベントを見つけ出し、すでにディメンショナル・モデリングされたデータから要件に該当するものを探索することにも使えると考えました。
システムプロンプトのイメージ
抽出対象となるビジネスイベント(例:「顧客が製品を注文する」)に対し、以下の7つの次元と計測タイプ(7W)を順序立てて適用し、関連するすべてのデータ要素を特定してください。
1. Who (誰が)
イベントに関与する主体や関係者を特定します。
• 主体 (Subject): イベントを実行する主要な人物、組織、またはシステム(例:CUSTOMER)。
• 関係者 (Other Whos): イベントに関連する追加の関係者(例:Salesperson)。
• 抽出例: 顧客、営業担当者、サプライヤー。
2. What (何を)
イベントの対象となる要素、またはイベントに関連する詳細を特定します。これは主にコンテキスト記述子(ディメンション)と、場合によってはファクトの基礎となる要素を指します。
• 対象 (Object): イベントが関わる具体的なモノやサービス(例:PRODUCT)。
• 追加のWhat (Additional Whats): イベントに関連するその他の重要な要素。
• 抽出例: 製品名、製品バンドル。
3. When (いつ)
イベントが発生した時間的な詳細を特定します。時間の粒度(日単位、時間単位など)を判断するために、前置詞(例:「on an order date」の「on」)に注意を払ってください。
• 発生時間: イベントが発生した具体的な日付または時刻(例:注文日)。
• 期限/予定時間: イベントに関連する将来または過去の期限(例:配達予定日)。
• 抽出例: 注文日、配達予定日。
4. Where (どこで)
イベントが発生した場所、またはイベントに関わる場所の詳細を特定します。
• 発生場所: イベントが発生した物理的または論理的な場所(例:店舗の場所、販売チャネル)。
• 関連場所: 対象の配送先や関連する場所(例:配送先住所)。
• 抽出例: Store NYC (店舗)、Memphis, TN (配送先)。
5. How Many (いくつ/どのくらい)
イベントに関連する測定可能で定量的なデータ(メジャー)を特定します。これらは後にデータウェアハウスのファクトとなり、BIレポートやダッシュボードのKPIに情報を提供します。
• 数量: イベントにおける計測値(例:注文数量、売上高)。
• 単位 (Unit of Measurement): 各数量に付随する測定単位を角括弧 [] を用いて追跡します。
• 抽出例: 注文数量、価格 [€]、割引率 [%]。
6. Why (なぜ)
イベントが発生した理由、または特定の数量や場所で発生した背景となるコンテキストを特定します。
• 理由/コンテキスト: イベントを引き起こした要因や付随する状況(例:プロモーション、キャンペーン、製品発表イベント)。
• 抽出例: プロモーション名、キャンペーンコード。
7. How (どのように/メカニズム)
ビジネスイベントの背後にある実際のメカニズムや、オペレーションシステムからの識別子を特定します。
• トランザクション識別子: イベントを一意に識別するためのID(例:ERPシステムによって作成された注文ID)。これはイベントの粒度詳細 (GD) の一部となります。
• 抽出例: 注文ID (O1222)。
これにより、AIは「キャンペーンAの参加状況」という曖昧な依頼を、以下のように解釈しようとし、依頼者に齟齬がないか確認してもらってからSQLを生成するようになり、意図した結果が得られるようになるはずです。
Who: ユーザー
What: キャンペーン応募イベント
When: 先月
How Many: 応募ユーザー数(ユニークカウント)
AIに7W整理をさせてもSQLが間違っている場合、それは「必要なDimensionやFactが存在しない」あるいは「定義が曖昧である(暗黙値が残っている)」というデータ基盤側の不備を示唆していると考えるのが良いでしょう。FactテーブルやDimensionテーブルの作成・更新を行い、再度データ抽出ができるか試すことで、データ基盤のアップデートがかけられるはずです。
さいごに
生成AIでデータを抽出することは、単なる業務効率化ではなく、自分たちのデータ基盤がどれだけビジネスの実態(イベント)を正しく表現できているかを検証することでもあると考えます。
今までは「モデルストーミング」と呼ばれるワークショップを行うことでディメンショナル・モデリングの開発を進めていくことが推奨されていました。
これからはデータ活用時にAIに小規模なモデルストーミングをやらせることで、適切なデータ活用とデータ基盤改善が継続的に行えるようになるかもしれません。
#GauDev Advent Calendar 2025、2日目の担当はTsubakiくん(@tsubakiky)です。お楽しみに〜
参考資料

Web3スタートアップ「Gaudiy(ガウディ)」所属エンジニアの個人発信をまとめたPublicationです。公式Tech Blog:techblog.gaudiy.com/
Discussion