Stable Diffusionを使ってTwitter用アイコンをつくってみた
エイプリルフールのネタとして自分の長年使ってきたTwitterアイコンを変えるのを思いついたはいいものの、素材をどうするかということで流行りのStable Diffusionでつくってみました。
今回つくった画像はこんなのになりました。

ヘッダー画像も変更してみました。

もともと使っているアイコンは「ガラスボー」という名前ともに高校時代の友人がつくったもので、以来GitHubや会社のSlackアイコンとかでも使っているくらいには気に入っているものです。
ですが、たまにこのアイコンが無表情なせいで相手に怖い印象を与えるがためにコミュニケーションがうまくいかないことがあるのではないか、という仮説があったりなかったりして、何度かもっと柔らかい印象を与えるいいアイコンはないかということを考えたことがあります。
しかし、当時はStable Diffusionもなく、自分にも画力がなくとかで結局変えずじまいに終わってしまいました。
そんなわけで、かつては断念したアイデアをエイプリルフールのネタを仕上げようと思い立ったわけです。
ただ、エイプリルフールのネタとしてはややインパクトが薄かったように思います。アイコンは色彩が地味なせいでちょっと目立ちにくいし、そもそもStable Diffusion出てからだいぶ経っているので旬を逃している感も否めません。
とまあ、やや空振り感はあったのですが、せっかくですので今回は実際に使ってみた感想とか、今後のAIに思うところを書いていこうかなとか思います
Stable Diffusionのローカルへの導入
Stable Diffusionを直接導入するのはなぜかうまくいかなかったので、Stable Diffusion web UIというサードパーティーツールを使い導入しました。
これはStable Diffusionの環境をローカルでセットアップしてかつローカルにウェブサーバーを立ててブラウザ経由でイラスト生成を可能にするというものです。
Stable Diffusion単体では動かず、別途モデルを導入する必要があります。モデルは一つ数GBほどあるので、ディスク容量には気をつけてください
HuggingFaceというところで多くのモデルがホストされていて、ここからダウンロードするのが良いでしょう。
モデルごとに得意な領域が異なり、イラストの出来栄えにも大きな差が出ます。また、モデルごとにライセンスも異なるのでそのへんも注意しながら用いるといいでしょう。
アイコン生成用にはAnything V4を使いました。ヘッダー画像は他のモデルもいくつか試しつつ、生成画像に対してimg2imgするなどして、最終的にAnything V4から出力させたものにぼかしを手動で入れたものです。
こちらからanything-v4.5-pruned-fp16.ckptというファイルをmodels/Stable-diffusion以下に配置します。
その他にもTwitterとかでいわゆるAI絵師という方々がイラストに使ったモデルを紹介していたり、自分で調整したモデルを公開していたりするので、気に入ったものを使うといいと思います。
また、モデルとは別にVAEと呼ばれるものも使うことが推奨されます。これはイラストの最後の仕上げをして色とかをはっきりさせる効果があります。
実は生成したアイコンはVAEを入れ忘れたものだったのですが、すこし色がぼやけた感じになっているのがわかると思います。まあ、今回の構図的にはちょっとぼやけた感じのほうが逆にいいな、と思ったのですが、基本的にはVAEを入れるほうがいいと思います。
Anything V4のレポジトリにVAEも個別に配布されているので、anything-v4.0.vae.ptというファイルをmodels/VAE以下に配置します。
VAEを適用するにはWeb UIからSettings -> Stable Diffusion -> SD VAEから明示的にVAEを指定したあと、Apply settingsボタンを押して設定を反映させる必要があります。
モデルの中にはVAEが内蔵されているというものもあるので、READMEを読んでそのモデルに合うVAEを設定しましょう。
使い方のコツ
txt2imgでのいわゆる呪文のつくり方は他のいろいろなブログ記事などがあるので、探してみるといいと思います。
ただし、呪文の効果はモデルの内容にも大きく依存します。例えばAnythingはイラスト特化ということもあってか、比較的簡易な呪文でもイラストの質はそこまで差がなかったです。
一方で、汎用性の高いモデルになってくると"masterpiece"とか"super fine illustration"とかのキーワードを入れないと質の高いものがなかなか出てこないなという印象です。
このような質を高めるためのキーワードが逆にモデルによっては足を引っ張ることもあるので、難しいところです。
少ないキーワードでいいイラストが出るタイプのモデルだと、それはそれでイラストの雰囲気の幅が狭くなってしまうのも悩みどころです。
モデルの
追加の学習やモデルのマージなどをすることによって、モデルをカスタマイズすることも可能なので、そのようなことをするのもいいでしょう。
自分は今回はそこまでは手を出すことができませんでした。
Stable Diffusionにはimg2imgという与えられた画像と追加のキーワードから新しい画像を生成する機能もあります。
言葉での指定が難しい場合や、すでに生成された画像から派生させたものをつくりたい場合は便利です。
HimawariMix-V2というモデルを使った例を紹介します。
こちら、適当にtxt2imgで生成したイラストなのですが、表情が少し怒ったような表情でアイコンには不向きそうです。

そこでこの画像をimg2imgのinpaintという機能を使い改変してみます。生成した画像を読み込ませ、変えたいパーツ周りを適当に塗りつぶします。
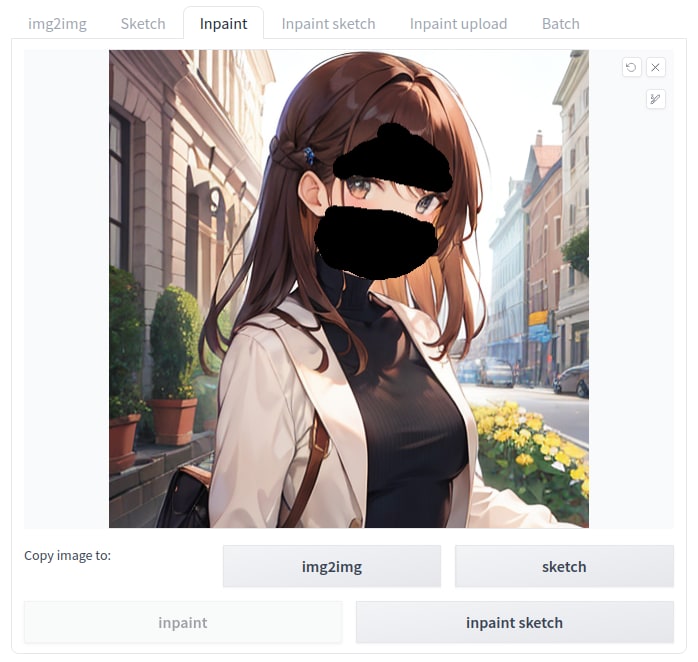
それで、テキストとしては「beautiful woman, upper body shot, smiling」などのキーワードを与えます。もともとのイメージにある変えたくない要素をきちんと入れつつ、追加したい要素のワードを入れる感じです。
そうすると以下のような画像が出てきました。

ちゃんと微笑んだ女性のイラストが生成されました。
また、ControlNetという拡張を使うとより高度なことができます。
これは画像から法線マップや人のポーズ形状を抽出して、txt2txtやimg2txtでのヒントとして使うことができます。
これにより、例えば簡易な3Dモデルの人のポーズから、そのポーズをしているイラストを生成したり、より高い精度で似たような構図のイラストの生成が可能になります。
ただし、VRAMをより多く使うことになるので、VRAMが少ない環境ではLow VRAMモードを有効化したり、生成するイラストサイズを小さくする必要があります。
自分の環境ではVRAMが6GBと大変小さかったので、よくOOMで泣かされました。
Stable Diffusionを使ってみての感想
かなり綺麗なイラストが生成されていると感じる一方、やはり手や服の構造といった細部がおかしい画像もたくさん生成されました。
このイラストは同じくAnything V4を使ったのですが、顔はすごく整って見えますが、右手と左の二の腕がぐちゃっとなって不自然に見えますね。

モデルによってはイラストの質もばらつきが多かったり、質は安定するが狙った構図がなかなか出ないことも多かったです。
こんな画像がほしいぞ、と思っていい画像に出会えるまでなんだかんだ数時間くらいはかかる印象です。
イラストレーターのお絵描き配信とかで数時間でそこそこのクオリティのものが出来上がっているのをみると、これでイラストレーターが駆逐できるというものではないように感じます。
細部がおかしいとか現状のモデルが未成熟であるからかもしれないので、今後よりより手法でそのへんの構造も正確なものへと改善される可能性はあるのかなとは思いますが、そもそもとして短いテキストから細部のイラストまでの乖離というが大きい以上、自分の意図どおりのものを出力させる困難さがめちゃくちゃ減るというのは難しいような気がします。
ControlNet的な別の手法で意図を伝える、とかを採用するとかなり改善するようには思いますが、そのためにはラフ絵とかを自分で描く力は必要になってくるでしょう。
そんなわけで、Stable Diffusionを使いこなすにはなんだかんだ最低限の画力がないと厳しいように思います。
AI開発と倫理
イラストAI全般に対して、その学習のために無断転載の画像が使われている、などとして批判されることが多く、イラストレーターがイラストAIに関してネガティブな意見を表明しているケースをよく見ます。
これはイラストAIに限らず、GitHub Coploitのようなプログラミングツールに対しても似たような批判がなされる場合があります。
自分は法律の専門家ではないので法的な見解は正確でない可能性がありますが、どうやら下のような記事を見る限り、著作物を機械学習のソースとして使うこと自体は一般には違法ではないようです。
人間だって商用のイラストレーターのイラストを見て学んだりするわけなので、機械学習に対してあえてそのような区別をつけるのも確かにおかしな話であるように思えるので、このような法律はそれなりに妥当性があるように思います。
一方で、イラストAIにかなり世の中には存在しないと思われる特殊なシチュエーションを入力として与えると自分の作品とそっくりなものが出力された、とか、ChatGPTでプログラミングさせたコードは実はとあるサイトのチュートリアルコードそのままだった、などの話を聞くこともあります。
そのような場合、事実著作物を再配布している行為にもなりえそうな気がするので、もとの著作物がいかなるライセンスだろうと学習ソースにしても(倫理的に)いい、という主張はやや疑問符がつきます。
また、上記のリンク記事にあるように無断転載サイトをソースにするという行為もかなり疑問符がつく行為には思います。
また、機械学習のためにはデータを集める必要がありますが、すでにMicrosoftがChatGPTを利用した各種サービスを展開しているように、AIを利用したサービスを展開することでさらにデータを収集していく、ということが考えられます。
現在でさえWeb広告のターゲティングのためのトラッキングなどが問題視され、利用者のプライバシーが大きな関心になっている中で、今後このようなAIサービスに対するデータ収集に関する規制というのは考えないといけないように思います。
と、こんな記事を書いていたらちょうどイタリアでGDPRによってChatGPTが規制されるという事件が起きました。思ったより展開早い
また、Mozillaは大企業がそのような高度なAIを寡占することに対抗して、Mozilla.aiという団体を設立しています。
そんな中でGPT-4以上のAI開発を半年間ポーズするべきだというオープンレターが出され、ジャイアントテックのトップ層が署名して注目を集めています。
これによると、このままAIの進歩が進んでしまえば取り返しのつかない変化を人類に与えて、そうなる前に一定のルールを敷くべきだとしています。
AI技術の可能性
倫理的に議論するべきポイントはいくつもあるのですが、技術的には非常に可能性のあるもののように感じます。
Stable Diffusionも全く画力がない自分にある程度のクオリティのイラストを生成することを可能にしてくれました。
ChatGPTの作文能力はかなりのもので、プログラミング支援にも使えそうです。
一方で、いろいろな限界も指摘されているように思います。Stable Diffusionであれば、まだ指とか服とかの構造を正しく認識する力は甘いし、ChatGPTによるプログラミングもそれっぽいコードを生成するが間違えだらけだったり、自分ができること以上のことはできないのではないか、みたいなことも言われています。
自分も少し試してみたのですが、検索機能のあるBing AIに遊戯王に関する質問を投げたところ不正確な情報が帰ってきます(このツイートはGPT-3のころのものですが)。
しかしこれらの限界は最近の進歩のスピードを見ると、数年後塗り替えられてしまうかもしれません(そういった懸念が先程のオープンレターにはあったのでしょう)。
やはり、AI技術を積極的に利用していかなければ時代に取り残されてしまうというフェーズに入りつつあるように思います。今回Stable Diffusionを使ってみようと思ったのはそういう危機感に駆られた部分もあります。
自分が気になっているのはStable Diffusionは個人の購入できるレベルのPCでも十分に動かせるのですが、GPT-4クラスの高性能AIはモデルが公開されていないこともそうですが、公表されているパラメーター数などから個人のPCで動かすのは到底無理で、莫大なコンピューティングリソースを要する点です。
現状のGPT-4レベルの能力だと、自分で追加学習させたりチューニングするようなことをしたいというユースケースは多いように思います。
今後AI技術が進歩するとして、果たしてコンピューティングリソースを節約するような方向へのイノベーションは起きるのか、それとも莫大なリソースを持つ大企業しか使うことができないのか、というのは一つのキーになったりするのかなあと思っています。
まあ、AI技術には疎いのでこのへんの研究成果とかはよく知らないんですが…
ともかく、今後も出てくるAI技術には注目し続け、どうやったら活用できるのかを積極的に試せるようにはしたいですね。
レッツ、ウルティマ・アトリビューション!
Discussion