【Python】Pytorchの物体検出アルゴリズムFaster-RCNN を用いたゲーム画面からの人物検知とその応用




この記事の続きになります!よかったらぜひ読んでみてください!
本記事が対象とする人:
- Pytorchで利用できる物体検出の学習済みモデルであるFaster-RCNN modelの使い方とその応用方法について興味のある方
- 他の人の個人開発を見るのが好きな方
- 前の記事の続きが気になる方
はじめに
背景
(前記事に記述した部分と被るため折りたたんでおきます)
現在、e-スポーツが話題となっており、競技人口や大会を視聴する人も増えています!
高校での部活動としても取り組み始められており、これからもどんどんe-スポーツに触れる人が増えていくのではないかと思います!
- e-スポーツの競技人口に関するサイト
- 全国のe-スポーツを学べる・部活動ができる高校に関するサイト
また、現在IT技術やビッグデータの利活用により、競技の戦略や選手の成長のサポートを行う仕組みが確立されつつあります(個人的には世界バレーなどで監督が手にタブレット端末を持っているのすごく印象に残っています。)
- バレーボールのデータ分析に特化したソフトウェア「Data Volley」
そこで、盛り上がりを見せているe-スポーツをデータ分析・プログラミング技術を用いて支援できる仕組みを構築することで新たな形で盛り上がりに貢献することができるのではないかと思い、今回はApex Legendsのプレイ動画を対象に動画解析アプリを作りました!
概要
アプリ全体の概要は以下のようになっています。
- Apex Legendsのプレイ動画から戦闘シーン(銃を撃っているシーン)を自動検出
-
自動抽出された動画から人物検知により、敵の位置を算出し、
エイムの傾向を可視化←本記事で解説

本記事では、Pytorchの物体検出の学習済みモデルを用いた人物検知を行い
エイムの傾向を可視化する手法について説明します。

エイムの可視化の手順について
- 1フレームずつ画像と取り出し、物体検出モデルを用いた人物検知を行い、
検出された箇所をボックスで囲む
例1:

例2:

- 検知したブロックをもとに中心(エイムをしている場所)とのズレがわかるように
グラフにプロットする

エイムの傾向をグラフにプロットすることで、プレイ動画を見返すことなく、
自分のエイムの傾向がわかりそうですよね!
自分の場合、真ん中に多くプロットされているものの、左右へのばらつきがあるので、
追いエイムができていないかもしれませんね!
置きエイムの場合、人が左右に動くことがあるので一概に言えませんが、
このようにグラフからエイムについて次の練習方法について検討することができると思います。
これからこれら2つの手順で使われている技術について解説していきます。
使用したライブラリ(必要に応じてインストールしてください):
import torch
import torchvision
from PIL import Image, ImageDraw
from torchvision import models as models
from torchvision import transforms as transforms
from matplotlib import pyplot as plt
import matplotlib.pyplot as plt
物体検出モデルを用いた人物検知
今回の人物検知では物体検出アルゴリズムであるFaster R-CNNの学習済みモデルを利用しました。このモデルは、Pytorchで簡単に利用することができます。
このモデルでは、人物以外に、車や自転車など88カテゴリーの物体を検出することができるので興味がある方は手元で動かしてみてください。
- Pytorchのドキュメント
このモデルを写真に写っている人物を検出する記事は目にしましたが、
ゲーム画面からの人物検出を行なっている記事はあまり見かけませんでした。
(調査不足だったら申し訳ございません。)
本記事ではゲーム画面を対象にモデルを利用してみた結果について共有しよう思います。
モデルの作成方法について
こちらのサイトのコードを参考にし、加工&機能を追加していくという形で実装させていただきました。
出力結果を改良・応用しているため、モデルの作成と利用方法について少し説明します。
# デバイスを指定(CPU or GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# モデルの作成
model=models.detection.fasterrcnn_resnet50_fpn(pretrained=True).to(device)
# 推論のみを行うため、model.eval()とする
model.eval()
models.detection.fasterrcnn_resnet50_fpn(pretrained=True)のpretrained=Trueとすることで学習済みモデルを作成することができます。
モデルの利用方法について
物体検知モデルの推論について
# 推論の実行
out = model([image_tensor])[0]
# 推論された結果から人である確率が0.4(score=0.4)であるという条件でボックスのフィルタリング
ID = 1
score = 0.4
boxes = out["boxes"][out["labels"] == ID & out["scores"] >= score].detach().cpu().numpy()
推論結果では、物体を囲むボックス(幅と高さ)とそのボックスのラベル(人、車)と
スコア(人である可能性0.4、車である可能性0.2)などの情報が返却されます。
出力結果について(とても多いので折り畳んでおきます)
{'boxes': tensor([[333.3714, 193.4102, 491.7807, 357.5507],
[ 46.6528, 358.4347, 260.9439, 415.1146],
[ 37.7311, 34.8063, 743.6085, 560.2494],
[748.9410, 325.0403, 786.5388, 363.6988],
[568.5364, 388.6073, 787.8217, 447.5220],
[692.5568, 2.9102, 790.5864, 404.6631],
[265.3645, 197.0009, 436.0099, 401.3181],
[691.8454, 0.0000, 790.6823, 407.7481],
[241.9697, 88.7612, 585.6792, 449.4500],
[ 23.5500, 1.7543, 435.1152, 75.3460],
[ 0.0000, 24.4495, 736.7495, 452.6496],
[ 39.5017, 346.6777, 267.9140, 595.6346],
[322.9312, 186.8627, 384.7004, 259.5823],
[320.1677, 200.6720, 729.2131, 488.2437],
[216.4995, 201.5084, 725.8540, 546.2513],
[272.9803, 82.6139, 698.3035, 279.5707],
[525.8349, 210.7228, 723.3886, 442.4457],
[380.1336, 181.8555, 442.7959, 275.3830],
[112.6479, 11.9658, 159.6510, 60.3064],
[323.3102, 187.9415, 384.4980, 258.6329],
[ 80.2718, 12.0307, 758.2069, 556.9834],
[214.0732, 74.9944, 592.0546, 568.2926],
[562.6445, 224.7893, 717.9313, 401.1909],
[ 59.1893, 1.4415, 222.2307, 72.3713],
[284.1985, 225.4269, 333.8943, 365.6503],
[ 46.4413, 43.0025, 687.3811, 434.5616],
[308.3393, 200.4571, 505.5440, 453.9946],
[ 80.1163, 18.9626, 379.1290, 168.0166],
[ 5.7102, 0.0000, 536.3854, 395.8783],
[322.7232, 188.3551, 385.3425, 260.1613],
[526.0906, 214.6258, 731.0037, 431.3772],
[178.6307, 93.8407, 231.6513, 141.0471],
[337.7607, 202.4939, 723.7096, 483.7678],
[ 4.8629, 20.8675, 733.4885, 463.5768],
[ 50.5350, 137.2455, 82.0898, 173.8543],
[505.9355, 205.7293, 731.3644, 453.2090],
[278.7262, 217.5682, 350.9685, 394.2758],
[290.0864, 208.0727, 554.1423, 410.6364],
[259.3663, 206.3684, 439.1599, 405.0284],
[693.4757, 19.8455, 789.8423, 448.5536],
[331.1252, 199.8021, 507.3270, 371.2636],
[268.7733, 222.1785, 569.9790, 496.1372],
[351.5643, 238.4649, 478.8485, 349.1431]], device='cuda:0',
grad_fn=<StackBackward0>), 'labels': tensor([ 1, 28, 8, 3, 3, 6, 72, 8, 72, 55, 7, 28, 72, 8, 3, 33, 10, 1,
55, 84, 6, 8, 14, 55, 77, 72, 1, 55, 28, 73, 3, 57, 6, 9, 57, 8,
72, 72, 73, 3, 18, 62, 27], device='cuda:0'), 'scores': tensor([0.9223, 0.8767, 0.7323, 0.6544, 0.5287, 0.4347, 0.3996, 0.3977, 0.3204,
0.2492, 0.1845, 0.1810, 0.1804, 0.1705, 0.1646, 0.1583, 0.1559, 0.1517,
0.1501, 0.1371, 0.1351, 0.1243, 0.1214, 0.1213, 0.1137, 0.1120, 0.1101,
0.1098, 0.0967, 0.0962, 0.0802, 0.0787, 0.0724, 0.0707, 0.0666, 0.0639,
0.0626, 0.0620, 0.0594, 0.0578, 0.0575, 0.0567, 0.0560],
device='cuda:0', grad_fn=<IndexBackward0>)}
出力結果を見るとわかるのですが、人物以外でも車などの何かしらの物体である可能性のある場合の情報が全て出力されるため、絞り込みを行う必要があります。
out["labels"] == 1 & out["scores"] >= 0.4という条件にすることで、
ラベルが1(人)である可能性が0.4以上であるボックスのみに絞り込むことができます。
出力された画像をもとに、出力結果のイメージを作成してみました。

またscoreについてイメージしづらいと思ったので、試しに0.1,0.8で設定した場合の
出力結果の例を用意してみました。
score=0.1(0.1の可能性で人であると判断)の場合

scoreを低く設定してしまうと人物以外のものに対しても、人物であるという判定がされ、
誤検出されてしまうことが確認できました。
score=0.8(0.8の可能性で人であると判断)の場合

逆にscoreを高く設定してしまうと検出されない場合があることを確認しました。
おそらく今回利用したモデルは、写真に写っている人物を検知するためのモデルであり、
ゲーム画面に適応することを目的としていないため、人物である可能性が低く出力されてしまう
のではないかと思います。
しかし、scoreを低くすることで、ゲーム画面に対しても人物を検出できることが確認できたことに
驚きました。(いろいろダメもとで試した結果たどり着いたモデルなので個人的に感動しました)
これらの結果から、両方ともの画像で検出することができたscoreを0.4に設定して利用することにしました。
検出する箇所の絞り込み(ひと工夫)
エイムしようとしている可能性がある場所は、画面全体ではないと思います。
また物体である可能性がある情報を全て出力してしまうことから、検出しようとする画面が広くなれば、
その分誤検出をしてしまう確率が高くなってしまいます。
そこで、エイムしようとしている箇所をある程度絞った上で、モデルで推論するようにしました。
指定した大きさの画像に中心から切り取るためのコードは以下のようになっています。
# 中心を切り取る関数
def pick_center(default_img, pick_wide, pick_high):
default_wide, default_high = pil_img.size
x_min = (default_wide - pick_wide) // 2
y_min = (default_wide - pick_high) // 2
x_max = x_min + pick_wide
y_max = y_min + pick_high
return default_img.crop((xmin,y_min,x_max,y_max))
元の画像のサイズ(1920,1080)、切り取りたい画像のサイズ(800,600)とした場合、
xmin = (1920 - 800) // 2 = 560
xmax = 560 + 800 = 1360
ymin = (1080 - 600) // 2 = 840
ymax = 840 + 600 = 1440
となり検出箇所は以下のイメージのようになります。

人物検知に関しては、以上のようになっています。
これを元に出力されたボックスをどのように利活用するのかを次に説明しようと思います。
検知したブロックをもとに中心(エイムをしている場所)とのズレがわかるようにグラフにプロット
物体検出モデルからの出力結果をもとに、グラフにプロットするためにデータを加工します。
以下の手順で加工を行います。
- ボックスの中心点を算出
- 中心に近いボックスをエイム対象とし、座標を取得
- 動画全体で人物の座標を取得し、図にプロットする
これらの手順について説明します。
ボックスの中心点を算出する
モデルの出力では、[450,650,250,500]のような形式で値が返ってきます。
そのため、どこの部分を中心とするのかを算出する必要があります。
簡単ですが以下のようなコードを書いています。
box = [450,650,250,500]
high = (box[0] + box[1]) / 2
wide = (box[2] + box[3]) / 2
例の場合、このように中心点を求めることができます。
high = (450 + 650) / 2 = 550
wide = (250 + 500) / 2 = 375

中心に近いボックスをエイム対象とし、座標を取得
ここで1つ問題です!どちらを狙っている可能性が高いでしょうか?

おそらく①であると思った方が多いんじゃないかなと思います。
しかし、2つのボックスが現れた場合,どちらを狙っている可能性が高いのかを決める必要があります。
そこで、今回は中心に近い場合を狙っていると仮定することにしました。
正直、ここの条件は甘いと思いますが、今後の課題とさせてください🙇♂️
コードは以下のようになっています。
# 変数の初期化
min_distant = 800
best_high = 0
best_wide = 0
for high, wide in zip(high_list,wide_list):
# 中心との距離を計算する
distant = ((high-300)**2+(wide-400)**2)**0.5
if min_distant > distant:
best_high = high
bset_wide = wide
min_distant = distant
中心点 = [400,300]
① = [550,375]
② = [25,500]
中心点と①の距離:
distant = ((550-400)^2+(375-300)^2)^0.5
= (28125)^0.5
≒ 167.7
中心点と②の距離:
distant = ((25-400)^2+(500-300)^2)^0.5
= (180625)^0.5
≒ 425
短い距離である①の中心点を選択するという仕組みになっています。

動画全体で人物の座標を取得し、図にプロットする
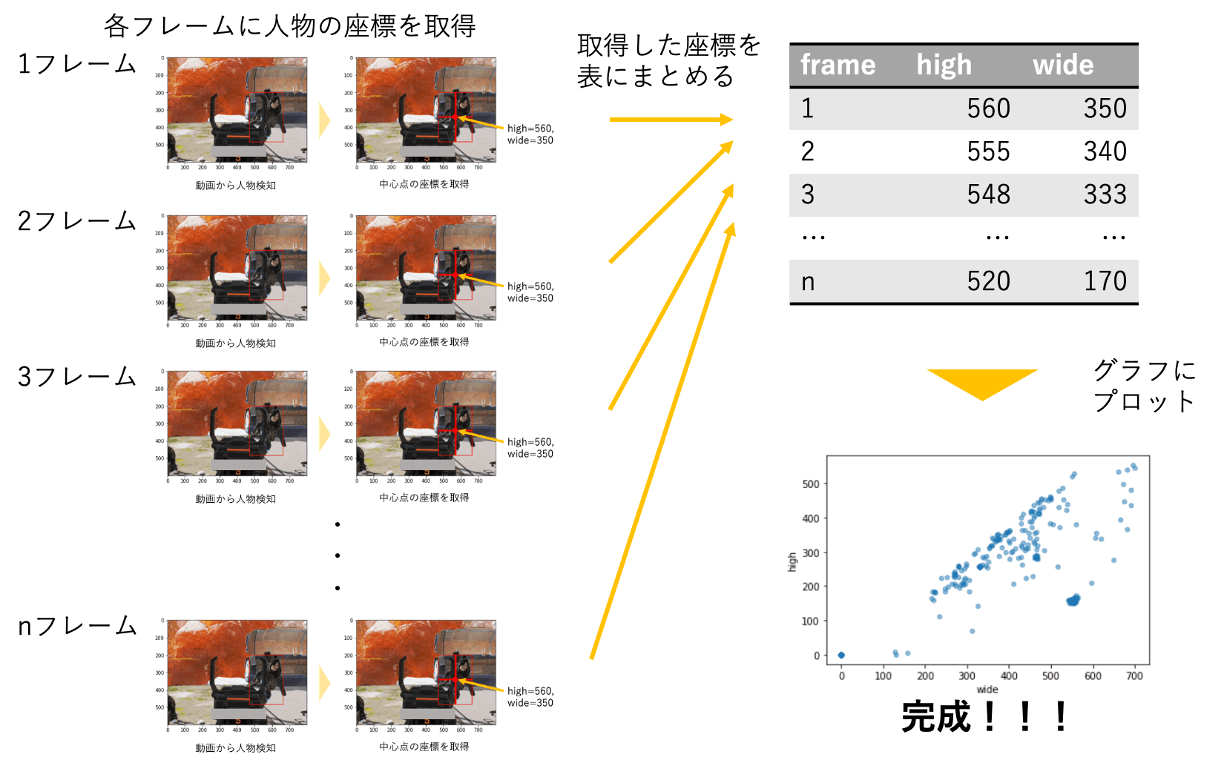
画像から中心点を算出してきたので、これらを動画に対して適応させて完成です!
座標の管理、グラフとして表示する仕組みは以下のようになっています。
動画データを読み込んで、各フレームに対して人物検知を行い、
検知されたボックスの中心点の座標を取得します。
取得されたデータを順に保存しておき、最後のフレームまで取得したのち、
図を作成し、表示するという流れになります。
動画処理に関する技術に関しては、前回の記事に詳しく記載しているので、
気になる方は、確認していただけると嬉しいです。
これまでのコードをまとめた関数(human_marker)
def human_marker(f):
# 各種変数の初期化
wide = 0
high = 0
min_distant = 800
just_high = 0
just_wide = 0
fin_list = []
a = np.zeros(4)
image = Image.fromarray(f)
# 中心部分に着目する
image = pick_center(image, 800,600)
# pytorchで使用できるようにtensor型に変換する
image_tensor = transforms.functional.to_tensor(image).to(device)
# 推論
out = model([image_tensor])[0]
# 人である確率が0.4であるという条件でボックスを取り出す
ID = 1
boxes = out["boxes"][out["labels"] == ID & out["scores"] >= 0.4].detach().cpu().numpy()
draw = ImageDraw.Draw(image, mode="RGBA")
for box in boxes:
# 四角形の中心の座標を取得する
high = (box[0] + box[1]) / 2
wide = (box[2] + box[3]) / 2
# 中心との距離を計算する
distant = ((high-300)**2+(wide-400)**2)**0.5
if min_distant > distant:
a = box
just_high = high
just_wide = wide
min_distant = distant
draw.rectangle(box, outline="blue", width=3)
# 画像をnumpyarrayに戻す
make_frame = np.array(image)
fin_list.append(make_frame)
fin_list.append(just_high)
fin_list.append(just_wide)
return fin_list
read = cv2.VideoCapture(read_name) # 動画の読み込み
read_width = int(read.get(cv2.CAP_PROP_FRAME_WIDTH))
read_height = int(read.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = read.get(cv2.CAP_PROP_FPS)# *0.5
high_list = []
wide_list = []
fourcc = cv2.VideoWriter_fourcc('m','p','4','v')
write = cv2.VideoWriter(write_name,fourcc,fps,(800,600))
while(True):
ret,frame = read.read()
# 人物情報の取得
anadata = human_marker(frame)
frame = anadata[0]
high = anadata[1]
wide = anadata[2]
# 座標取得(上下反転しているため、highはマイナスにする)
high_list.append(-high)
wide_list.append(wide)
# 描写
write.write(frame)
if not ret:
break
write.release()
read.release()
# データの保存
df = pd.DataFrame({"high":high_list,
"wide":wide_list}, index=None)
df.to_csv(point_file_name)
以上で、エイムの可視化に関する実装は終了です!
長くなってしまいました!お疲れ様でした!
おわりに
本記事のまとめ
本記事では、Pytorchの物体検出の学習済みモデルを用いた人物検知を行い、
エイムの傾向を可視化する手法について書いてきました!
学習済みモデルでもゲーム画面に対して人物検知できることがわかりました!
また、検出された結果をグラフにプロットするという形で応用してきました!
みなさんのお気に入りのゲームで人物検知を試す時や、
出力結果の応用したい時に参考にしていただければと思います!
アプリ全体でのまとめ
Apex Legendsを対象に盛り上がりを見せているe-スポーツにデータ分析・プログラミング技術を用いて、競技者を支援できる仕組みを構築することで新たな形で盛り上がりに貢献したいというモチベーションでアプリの作成してきました!
精度がいいものとは言えませんが、スタートラインに立つくらいの取り組みができたのではないかと思います!
また今回のモデルでは、あくまでApex Legendsのみサポートができるものなので、
他のゲームでもサポートできるアプリが作れたらいいのかなと思います!
長くなりましたが、ここまで記事を読んでいただき、ありがとうございます!
初めての投稿で〜みたいなこと、2部作になってしまったため言うタイミングを逃していました!
記事を書くことに慣れていないのですが、楽しんでいただけていれば嬉しいです!
これまでの取り組みは、githubにまとめているので手元で動かしてみたい方はぜひ遊んでみてください!
あとがき
e-sportsを支援するアプリの開発という形で、中高のプログラミング・データ分析の教育が発展しないかなとか少し考えていたりします!
バレーとか野球などのスポーツは、多くの中高で部活動として取り組まれていますが、
分析用に動画データを扱う場合、カメラや専用アプリケーションを購入する費用など、環境を整えることが難しいのではないかと思います!
それに比べ、e-sportsはプレイしている動画を録画するだけでデータを取得できるという点で、データを利活用することがバレーや野球に比べて簡単なのではないかなと思います!
(ゲーミングPCの準備、キャプチャツールの購入もなかなかハードルが高いと思います、、、)
今回の取り組みを通して、まだ部活動として普及していないe-sportsが、競技する人がプレイデータを作成し、分析する人がデータをもとに分析結果を競技する人にフィードバックするという新しい形で中高でコミュニケーション力とプログラミング力・データ分析力を養える部活動として普及できれば面白いのではないかなとか思いました!
参考サイト
Discussion