Kaggleで金融コンペを開催するための(僕が知っている)すべて
はじめに
先週からマケデコというMarket APIのDeveloper Communityの運営をスタートしており、その中で我々が問題設計を担当した以下のKaggleコンペにおいて どのような問題設計と実際にどうやって解いてみたのか? という質問を頂きました。
この記事では、そのあたりについてKaggleで金融コンペを開催するための(僕が知っている)すべてを記載してみようと思います。
もし、このような話に興味があればマケデコDiscordのリンクを以下に記載しておきますので、ぜひご参加ください!
キックオフイベントも開催しますので、よろしければこちらにご登録ください!
なお、本記事はコンペ主催のJPX総研様からも許可をいただき、記載させていただいております。JPX総研様が提供する株価/財務情報を取得できるJQuants APIもご興味あれば、現在は無料ですので、ぜひお試しください。
Kaggleにおける金融コンペとは
まず、金融コンペを考える上で、純然たる事実があります。それは、Kaggleの課題において正当な努力がスコアに反映されない問題(いわゆる 運ゲー )は非常に嫌われるということです。この運ゲー問題がどうして起きるかと言うと、例えば、以下のような問題をコンペ運営が出すと起きます。
- データにノイズが多すぎてパターンを見出すことが出来ない
- 学習用のデータと評価用のデータがあまりにも違いすぎるために学習させたモデルが全く役に立たない
- 時系列データにおいて、突然レジームチェンジが起きてゲームのルールが全く変わってしまう
このような性質は株価などのいわゆる金融マーケットの時系列データにかなり当てはまります。つまり、データサイエンスコミュニティに嫌われない、受け入れられる株式予測コンペについて考える必要があります。
あと、補足ですがコンペ運営側がミスをするケースもあります。
- トレーニングと評価用のデータが混ざっている
- データの中に正解を導き出されるあまり問題と関係ないデータ・部分が混ざっている(画像の撮影の背景から予測できたり、特徴量の中に正解ラベルがなぜかはいっていたり)
実際にコンペを開催するとなると、これらの問題も非常に怖い問題で注意しすぎるこことはありません。ただ、幸運にも我々は過去に2回SIGNATEでコンペを開催していたため、Kaggleにおける金融コンペの勘所も把握しておりました。
金融コンペの問題設計の基本的な考え方
それでは、金融コンペの問題設計のときに考えなければいけないことは何でしょうか?一般的に金融マーケットの時系列データの2つの異なる期間において、データが同一の分布を永続的に持つことを仮定することはできません。例えば、2020年2月までと2020年3月以降では、新型コロナウイルス感染症等による世界情勢の変化により、マーケットの性質は大きく変化しました。
このようにデータ分布の特性が移り変わる金融マーケットを題材としたコンペの場合、問題設定として、データ分布の変化に依らないロバストなモデルを構築した人をコンペの勝利者とするべきと考えました。そのためには 問題設計があるていどロバスト性がたかい性質 を題材にしている必要があります。
では、ロバスト性の高い問題とは何でしょうか?おそらく、大きく分けて2つの考え方があると思います。
A. そもそもロバストの高い事象を見つけてそれを題材にしてしまう
B. ロバスト性は低い事象だが問題設計を工夫して問題になんとかロバスト性をもたせる
JQuantsの第1回目のコンペはこのAの手法を使いました。JQuantsの第1回目のコンペは以下のようなものです。
JQuantsの第1回目のコンペの問題
第一回の課題は、以下の図のように銘柄情報・株価情報・ファンダメンタル情報等を駆使して、各東証上場企業(普通株式のみ。ETFやREIT等は除きます。)が、決算短信(四半期決算短信を含みます。)を発表した後の20営業日の間における、当該企業の株価の最高値および最安値の予測をしています。
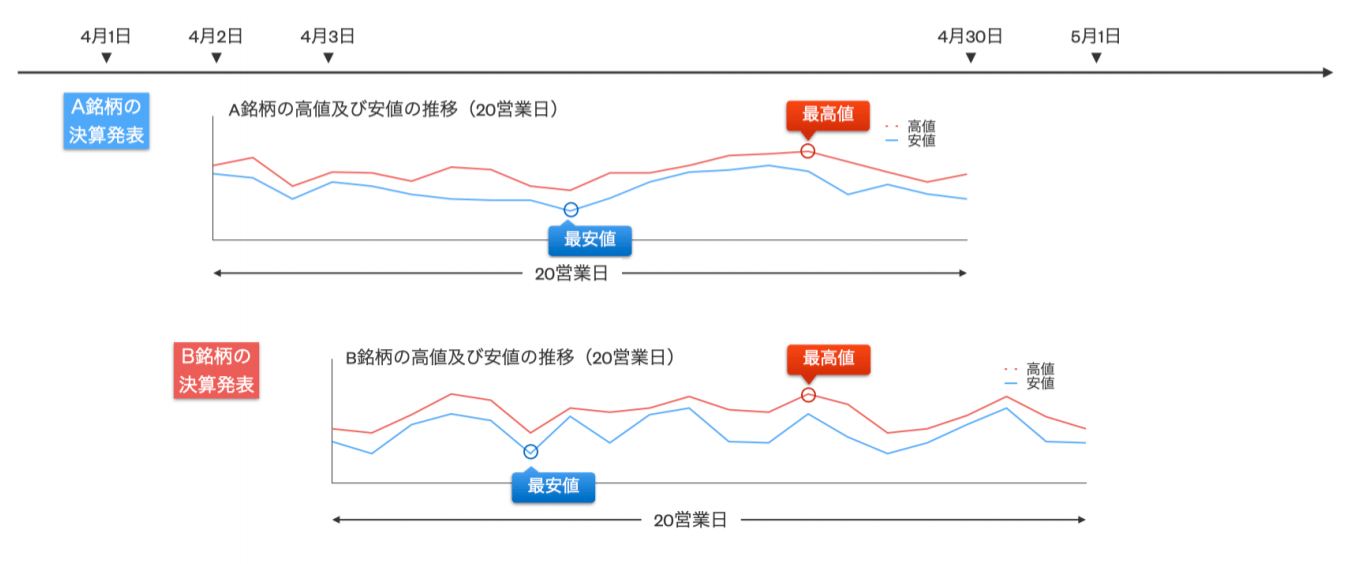
モデルの予測と真の値(決算短信の開示後から起算して20営業日以内に発生する最高値及び最安値)との順位相関係数(算出式1)による定量評価としています。
先ず、決算発表後からの最高値もしくは最安値への変化率について、それぞれスピアマンの順位相関係数を計算します。この順位相関係数を使った以下のスコアを計算します。この式に置いてP_high=最高値の順位相関係数、P_lowが最安値の順位相関係数です。
順位相関係数を採用しているのは、以下にも記載されているように金融商品の価格変動の変化率の分布は必ずしも正規分布になるとは限らないためです。 そのため、この問題では特定の分布を仮定しない順位相関係数を採用しています。
このコンペがどうして そもそもロバストの高い事象を見つけてそれを題材にしてしまう に該当するのか、直感的にはわからないかもしれません。しかし実際に解いてみるとわかるのですが、この問題はシンプルなモデルでも順位相関係数で0.2くらい出ます。
すこし凝ったことをすると0.3が出ることがAlapcaのデータサイエンティストが解いてみてわかりました。通常の未来の株価を予測するような予測では相関係数が0.1でていればいいところですから、これはもうほぼ解ける問題と仮定できます。
その要因はこの問題が株価の方向性だけではなく ボラティリティ も題材にしているところにあります。この高値・安値という概念はオプションのトレードなどを行う時などに非常に重要な概念で、誤解をおせれずにいうなら、ボラティリティが高い銘柄ほど高値も安値も大きい可能性があるためです。
そして、 ボラティリティ というのは自己相関がある時系列データであるため、ランダムウォークを仮定する必要がある自己相関がないシンプルな株価予測の問題よりもずっと簡単な題材になります。実際にコンペでも優勝モデルは相関係数0.5-0.6を競い合うようなハイレベルな戦いになりました。よく、決算発表後にアナリストが目標株価というのを発表することがありますが、相関係数0.6では当てることは出来ていないと思われますので、この分野においては予測モデルの性能はかるく人間を凌駕していると思われます。
JQuantsの第1回目のコンペの問題設計のプロセス
さて、このコンペの問題は、以下のようなプロセスで設計しました。まず、本コンペを設計する上で、JPX様と一緒に過去のすべての株式系のコンペの問題を分析しました。当時は合計12個のコンペが過去にありましたが、その全てがデータサイエンティストの努力が反映されない設計になっておりました。
ただ、この問題はその後、認識されていたようで、その後に行われたOptiverなどではおもにVolatilityを題材にしておりましたので、多くの金融コンペの設計者は同じ問題に気づいたのだと思っています。なお、Optiverはtime_idが想像以上に時系列順に並んでいるというリークがあり、前述の通りVolatilityは自己相関があるため、リークを利用するモデルが上位を競う結果になりました。これは問題設計というよりデータ設計の甘さが招いたミスであると思っています。
さて、問題の分析の後に実際に20個程度の問題を作成し、有望ないくつかの問題を実際にAlpacaのデータサイエンティストがデータを用意して解いてみて以下の5観点で評価しました。
- 元データの取得しやすさ
- 話題性(面白さ)
- 実取引での有用性
- 金融初学者の参入しやすさ
- 分析しやすさ
こちらが解いてみたときの資料の一部です。いろいろな特徴量とモデルを複数用意し、その組み合わせを作って、メトリクスのバラツキを確認することで問題のロバスト性を検証しています。
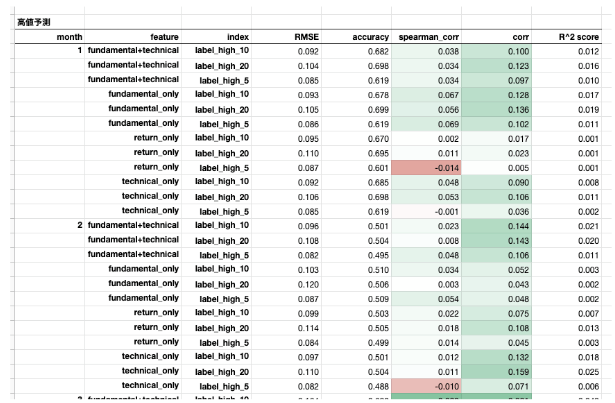
この評価をした後、データサイエンティストの工夫に比例して、パフォーマンスが向上し、決算分析という王道の問題で、アナリストがよく発表する目標株価と近い概念の「20日以内の高値・安値予測」という問題が完成しました。
Kaggleコンペにおける問題
さて、JPX Tokyo Stock Exchange Predictionにおける問題設計ですが、こちらは実はJQuants第一回のアプローチと異なり ロバスト性は低い事象だが問題設計を工夫して問題になんとかロバスト性をもたせる を採用しています。
これはどういうことかというと、高値・安値予測のような問題自体はロバスト性が高くて非常に扱いやすいのですが、一方で世界最高レベルのデータサイエンティストが競うコンペでは簡単すぎるという問題があるためです。また、実務的にもリターン予測にチャレンジすることが最も手法的な価値が高いだろうと考えたためです。
問題設計は以下のようになります。この問題設計もパット見は非常にわかりにくいかもしれませんが、簡単にいうと1日先(ただしエントリーは次の日の終値)の予測を毎営業日実施して、そのlong/shortのトレードのパフォーマンスをシャープレシオを競うというものです。
-
モデルは毎営業日(t)に、その営業日までの終値(C_t)等のデータを入力データとして、翌営業日の終値(C_t+1)から翌々営業日の終値(C_t+2)までの変化率(r_t+1)の上位200銘柄と下位200銘柄を予測します。
r_t+1 = (C_t+2 - C_t+1) / (C_t+1) -
予測した上位200銘柄に対して1から200位までにそれぞれ2から1の線形のウェイトをそれぞれの変化率に対して掛けたものの総和を計算しこれをS_upとします。
-
予測した下位200銘柄に対して下位1から200位までにそれぞれ2から1の線形のウェイトをそれぞれの変化率に対して掛けたものの総和を計算しこれをS_downとします。
-
S_upからS_downを引いた結果をR_dayとし「デイリースプレッドリターン」と呼ぶことにします。
-
デイリースプレッドリターンをpublic/private期間中、毎営業日計算し、当該期間の時系列として取得します。デイリースプレッドリターンの時系列の平均/標準偏差をスコアとします。
スコア計算式(xはpublic/private期間の営業日):
Average(R_day1-dayx) / STD(R_day1-dayx) -
private期間の最大のスコアを獲得したカグラーが勝利となります。
Kaggleコンペにおける問題設計のプロセス
Kaggleコンペの問題評価プロセスは前回からすこし変えました。
まず、元データの取得しやすさですが、こちらは将来的にJQuants APIで提供を想定している株価・財務データが対象ですので、あまり気にする必要はありません。金融初学者の参入しやすさは今回はよりハイレベルなデータサイエンティストを対象とするため劣後することにしました。それ以上に重視したのが 新規性 です。前回のSIGNATEコンペやKaggleの既存コンペとの差別化ができており、類似コンペがない、つまり世の中にきちんとした解法が無い問題であることを重要視しました。これは、Kaggleという大舞台で競い合う以上、どうせなら世の中でだれも解いたことがない問題をといてほしかったためです。
また、問題設計のときに、雑多な箇条書きになりますが、以下のようなポイントも考慮しました。
- 個別銘柄の事象にあまり左右されることなくモデルの性能を競い合うことができるように、毎営業日に予測する銘柄数を投資対象銘柄(2000銘柄)に対して10%以上である上下それぞれ200銘柄の変化率の差分としています。ただし実務的には機関投資家やファンドの投資対象は50-100銘柄とすることが多く、若干現実の問題設定と乖離がありますが、本コンペティションでは問題の安定性を優先して設計しています。
- デイリースプレッドリターンの計算に際しては、1位により収益率が高い(下位であれば低い)銘柄が配置されるように、1位から200位に対して1から2の線形のウェイトを掛けています。
- 「リスクコントロール」も投資にとって重要な要素であるため、競い合うスコアをデイリースプレッドリターンの単純平均や総和ではなく、デイリースプレッドリターンの時系列の平均/標準偏差としています。これにより特定の日だけ大勝ちするモデルではなく、データの分布の変化に対応し安定的に高い性能が出るモデルを構築することが必要になります。
- 本コンペでは、マーケット自体のボラティリティやリスク要素を推測する手がかりとなるオプションデータ等のデータも提供しています。これらのデータを活用することでより高度なリスクコントロールができるかもしれません。また、下位200銘柄も予測対象に含めているため、マーケット・ニュートラルな戦略を採用することも可能(なお、ベータ値をわざと偏らせることでロング側にバイアスを掛ける戦略も可能)で、ベータ値をコントロールすることでマーケットの値動きに大きく左右されない標準偏差がコントロールされたモデルの構築が可能です。
さて、今回ももちろん問題を解いてみています。解き方は一緒でいろいろな特徴量とモデルを用意し、その組み合わせで性能がでることを見ています。ただし、今回はリターン予測を行うので、性能は前回ほどはでないことを想定しておりました。
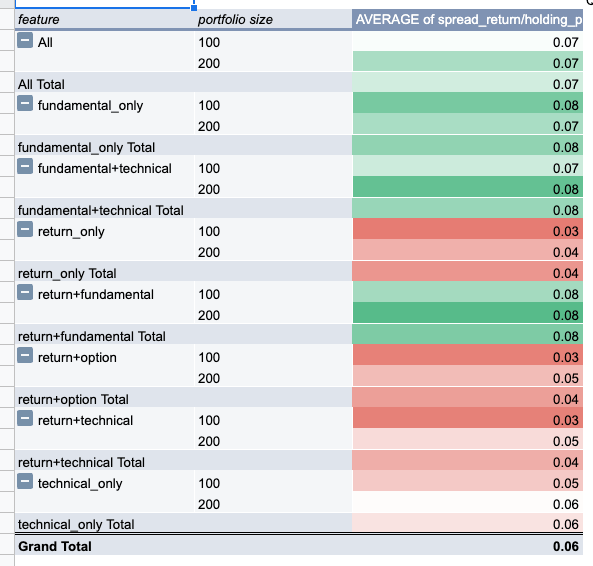
以下がその検証結果の一部です。すこしわかりにくいですが、tecnical-onlyという一番シンプルなモデルと比較して、fundamental+technicalなどが1.5倍程度の性能が出ていることがわかります。また、この後に行った、今回の問題の目玉の一つである日経225オプションのデータもきちんと特徴量設計したところ、非常に性能に貢献することがわかりました。
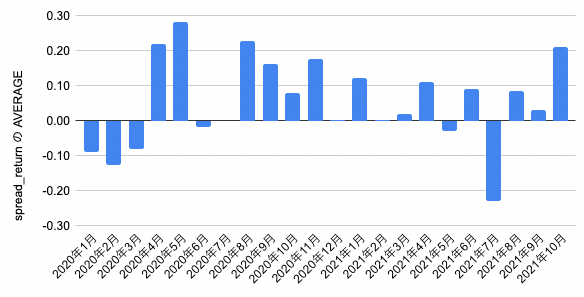
また、以下のように時系列方向の性能の安定性も見ておりました。というのも、ある特定期間だけ性能が出る問題というのは存在するためで、private期間がそこに当たると目も当てられないからです。結果的にコロナ前と直後の劇的に難しい期間を除けば時系列的な問題の安定性も十分でした。コロナのような出来事はさすがにprivate期間では起きないだろうという思いで問題を決めました(これが死亡フラグになっていないようでよかったです)。
この問題設計は元ミレニアムの株式用責任者/元QuantopoanのCIO、現在Numeraiにも出資している方からも高い評価をいただいたり:
Kagglerからも過去最高デザインのコンペだとお褒めのことばをいただき、安心しました(なお、この発言の方は現在上位にいるようです):

また、コンペ終了後にUKIさんからもお褒めの言葉をいただきました:
最後に
そのようなわけで、長くなってしまいましたが、金融コンペの問題設計の話をしました。ここまでまとまった情報は英語圏でもみたことがないので、おそらくそれなりに今後もし金融コンペを企画するのであれば、役に立つ知見ではないかと思います。
また、最後に告知になりますが、このようなトピックを扱うマケデコ(Market API Developer Communityの略)というコミュニティをDiscord上に立ち上げています。
キックオフイベントも開催しますので、よろしければこちらにご登録ください!
Discussion