GoogleのBigQueryに保存されているデータを活用してランキング機能を作成したかった為、RailsのGemにある google-cloud-bigquery を使ってBigQueryから必要なデータの取得を行いました。
その際に、毎回同じリクエストを叩くとその度に料金が発生してしまい非常に勿体無いため、Railsに備わっているキャッシュ機能と組み合わせて、最低限のリクエストで済むようにしました。
google-cloud-bigqueryの使い方
google-cloud-bigquery は、Googleが公式で提供してくれているGemなので、こちらの公式ドキュメントを参考に導入することができます。
gem install google-cloud-bigquery
Gemのインストールが完了しましたら、下記のようにライブラリを読み込んだのちに、BigQueryにアクセスするためのインスタンスを作成します。
require "google/cloud/bigquery"
query = Google::Cloud::Bigquery.new(
project: "your-project-id",
credentials: "path/to/your/credentials.json"
)
次に、実行するクエリを定義します。
例えば、 your_dataset.your_table というテーブルから name と age を取得したい場合は以下のようにクエリを定義して変数に格納します。
sql = "SELECT name, age FROM `your_dataset.your_table` LIMIT 10"
最後に、作成したインスタンスのqueryメソッドの引数に先ほど定義して格納したクエリ変数を入れて実行すると、BigQueryにアクセスして、 name と age の値を取得することができます。
results = bigquery.query sql
results.each do |row|
puts "名前: #{row[:name]}, 年齢: #{row[:age]}"
end
google-cloud-bigqueryのメソッド紹介
Gemの google-cloud-bigqery には、BigQueryでクエリを実行するための色々なメソッドがあるため、そちらのご紹介もします。
小規模データを同期的に取得する
結果のサイズが10MB以下の小規模なものであれば、 query メソッドを利用することで同期的にデータを取得することができます。
results = bigquery.query("SELECT name, age FROM `your_dataset.your_table`")
大規模データを非同期で取得する
大規模なクエリや長時間実行されるクエリの場合は、 create_query_job メソッドの利用がおすすめです。
job = bigquery.create_query_job("SELECT name, age FROM `your_dataset.your_table`")
results = job.query_results
このメソッドを利用することで、データ処理のためのジョブを生成してバックグラウンドで実行してくれます。
これにより、大規模なデータや複雑なクエリの実行時に、プログラムの実行をブロックすることなく処理を進めることが可能になります。
クエリジョブの確認をしたい場合
すでに実行されているクエリジョブの状態を確認したい場合は、query_job メソッドを利用することで確認することができます。
job = bigquery.query_job(job_id)
こちらのメソッドを利用することで、ジョブが完了したか、まだ実行中かなど状態を確認できたり、ジョブの実行中にエラーが発生した場合はそのエラーの詳細を取得することも可能です。
また、ジョブの実行にかかった時間や処理したデータ量なども取得可能です。
job_id = "your_job_id"
job = bigquery.query_job(job_id)
# ジョブの状態を確認
if job.done?
puts "ジョブは正常に完了しました"
else
puts "ジョブは実行中です"
end
# エラー情報の確認
if job.failed?
puts "ジョブの実行中にエラーになりました: #{job.error}"
end
非同期で実行されたクエリの結果を取得する
create_query_job メソッドで非同期でクエリが実行された後に、その結果を取得するには query_results を使用します。
このメソッドを使用することで、非同期で実行されたクエリの結果を取得することが可能になります。
ただしquery_results メソッドで非同期データの結果を取得する場合は、必ずジョブが完了していることを確認した後に行う必要があるため、そこだけ注意が必要です。
job.wait_until_done! でジョブの完了を待つことができるため、下記のように使用できます。
job = bigquery.create_query_job("SELECT name, age FROM `your_dataset.your_table`")
# ジョブの完了を待つ
job.wait_until_done!
# ジョブが完了した後、結果を取得
results = bigquery.query_results(job.job_id)
以上が google-cloud-bigquery のメソッドの紹介になります。
Railsのキャッシュ機能と組み合わせて使う
Railsにある cache メソッドを利用することで、Railsにデフォルトで備わっているキャッシュストアにキャッシュされたデータを保存することができます。
Rails.cache.fetch("some_key") do
# ここには重い計算やデータベースクエリなどが入る
end
この cache メソッドを利用してクエリの実行をキャッシュすることで、BigQueryからデータを取得する際に発生するコストを抑えることができます。
Rails.cache.fetch
cache メソッドも様々な使い方ができますが、今回は cache メソッドの中の fetch メソッドを利用しました。
このメソッドを利用すると、キャッシュストアを参照した際に、リクエストされたkeyと同じkeyデータがあればそのkeyに対応するキャッシュのデータを返します。
もし同じkeyが存在しなけれな、新たにそのkeyでキャッシュデータを作成してくれます。
キャッシュの有効期限を決める
fetchメソッドの第二引数で、 expires_in: 時間 でキャッシュの有効期限を指定することができます。
例えば1時間の有効期限を指定する場合は以下のように指定します。
Rails.cache.fetch("some_key", expires_in: 1.hour) do
# クエリなどの結果を計算するコードが入る
end
あまりにも古いキャッシュを使用し続けるのはパフォーマンス的によろしくないため、適切な有効期限を決める必要があります。
Railsキャッシュ機能の詳細に関しては公式ドキュメントをご参照ください。
実際の使用例
require "google/cloud/bigquery"
class Api::SearchRankingToolsController < Api::BaseApiController
def index
results = fetch_data_and_create_sql(search_ranking_tool_params)
cateogry_db_id = get_category_db_id(search_ranking_tool_params[:template_name])
res = fetch_category_db_data(cateogry_db_id, search_ranking_tool_params)
render json: results.map { |result| Api::SearchRankingToolSerializer.serialize(result, res) }, status: :ok
end
private
def search_ranking_tool_params
params.permit(:template_name, :limit)
end
def fetch_data_and_create_sql(params)
cache_key = "#{params[:template_name]}_#{params[:limit]}"
search_ranking_result = Rails.cache.fetch(cache_key, expires_in: 1.day) do
query = Google::Cloud::Bigquery.new(project: Settings.spartan.project_id, credentials: Settings.google_cloud.damrey_keyfile_path)
# SQLインジェクション対策のため、paramsを直接埋め込まずに、プレースホルダーを使ってSQLを組み立てる
params = {
template_name: params[:template_name],
limit: params[:limit].to_i
}
sql = %(
WITH word_data AS (
SELECT SPLIT(data_value, ' ') AS word_list
FROM `production.hogehoge.event_logs`
WHERE _PARTITIONDATE BETWEEN DATE_SUB(DATE(CURRENT_TIMESTAMP(), "UTC"), INTERVAL 7 DAY)
AND DATE_SUB(DATE(CURRENT_TIMESTAMP(), "UTC"), INTERVAL 1 DAY)
AND data_key = @template_name
),
unnested_word_data AS (
SELECT word
FROM word_data,
UNNEST(word_list) AS word
)
SELECT word, COUNT(*) as word_search_count
FROM unnested_word_data
GROUP BY word
ORDER BY word_search_count DESC
LIMIT @limit
);
tmp_result = query.query sql, params: params
# 必要なデータのみを抽出してシリアライズ可能な形式に変換
tmp_result.map do |row|
{ word: row[:word], word_search_count: row[:word_search_count] }
end
end
return search_ranking_result
end
def fetch_category_db_data(category_db_id, params)
Rails.cache.fetch((params[:template_name]).to_s, expires_in: 1.hour) do
Category.find(category_db_id).records.published
end
end
def get_category_db_id(template_name)
case template_name
when "dqm3_synthetic_monster_search"
return 18739
when "dqm3_reverse_synthetic_monster_search"
return 18739
when "dqm3_encyclopedia_search_name"
return 18739
when "dqm3_move_list_search_name"
return 18748
when "dqm3_skill_search_to_suggest_skill_name"
return 18747
else
return nil
end
end
end
BigQueryから取得したデータをシリアライザーへ渡してデータを成形する場合、BigQueryから取得したデータはそのまま渡すと不要なデータが紛れて上手く機能しないため、必要なデータのみを抽出する処理を挟んでデータをシリアライズ可能か形式に変換しています。
また、SQLインジェクションの対応も必要なため、paramsでパラメータ化してそれをqueryメソッドの第二引数に渡して対応しています。
参考記事: https://zenn.dev/aldagram_tech/articles/sql-injection-with-big-query
出力データ
クエリメソッドでBigQueryから取得したデータの結果が下記になります。

このデータを活用して、最終的に下記のようなランキング機能を作成しました。
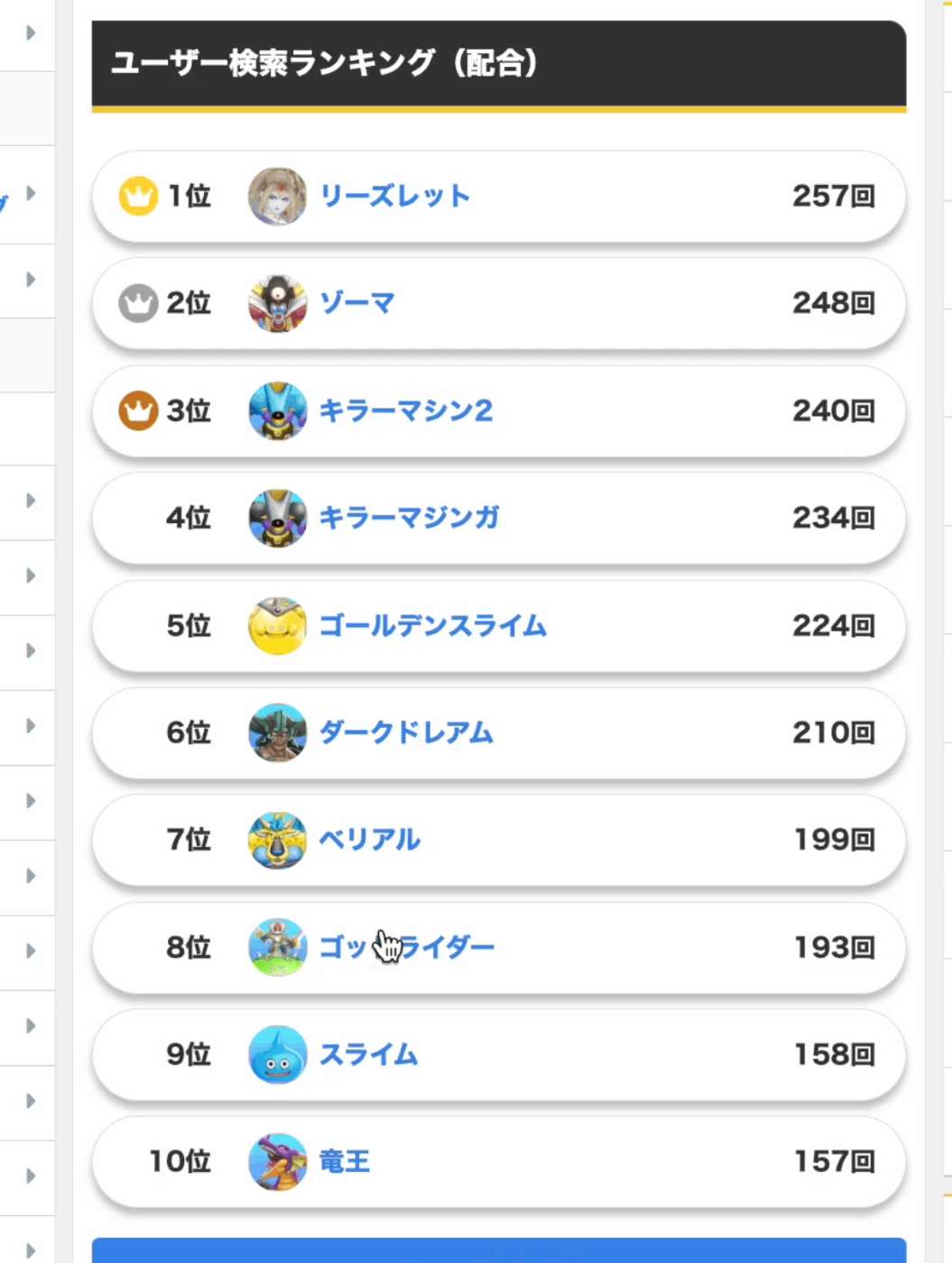
まとめ
以上で、 BigQureyから取得したデータをRailsアプリでキャッシュして利用する方法の紹介を終わります。
Railsの cache は利用したことがありましたが、 google-cloud-bigquery は今回初めて利用してみてとても便利に感じたため、 BigQueryとRailsアプリケーションを組み合わせて何か作成したい場合はぜひ活用してみてください。
最後まで読んでいただきありがとうございました。
本記事が少しでも誰かのお役に立てれていれば幸いです。

Discussion