この記事は株式会社ガラパゴス(有志) Advent Calendar 2025の18日目です
お疲れ様です、波浪です。
さて、前回、前々回はScratch3.0で推論機を作ってPythonで学習した重みを移植することで実装しました。
day1 Scratch推論機
day2 重みの作成とScratchへの移植
ここまできたらやるしかないですね、誤差逆伝播法をScratchで実装です。
ただ、day1,day2のコードを拡張したら無事バグだらけになったので一から作り直します。
いままでの俺はスクラッチ初心者でしたが、今なら初級者くらいにはなってますからね!!
改善方針
-
重みやΔは一つの配列にいれて実行時にスライスして使います
-
関数はグローバル変数を引数と戻り値に使うことにして リストのやりとりを可能にします
- 元の機能である関数の引数は使える時と使えない時の切り分けが面倒なので一律利用しません
- この「関数の引数を使わない」事でスプライトの外から別の関数を呼び出せるなと思って、この方式にしましたがGOTOっぽくなるので、別スプライトへの呼び出しはやってません。
-
前回のモデルはReLUだったので数字の上限が無制限、Scratch上で学習させたらNaNに収束して失敗したので 活性化関数をsigmoidに変更します
-
sigmoidのためにexp と logを作ります
-
exp/logを四則演算だけで近似させる手法は僕の腕じゃ無理なのと、多分実装しても速度がでないので、むかーしむかしフーリエ級数展開を使った画像の水面反射エフェクトをガラケーに実装した時の手法を思い出したのでそれで対処します
-
具体的にはある程度の範囲の計算結果を先に用意しておく方法で対処します
- tableのindexを超えたものは上限下限でつぶします
- log は 0.0から1.0を 0.0001 刻みで計算結果テーブル作成
- exp は -10.0 〜 +10.0 0.001刻みで計算結果テーブル作成
- expの範囲は適当に勘で決めました、ちゃんとやるならスクラッチ変数が何Bitなのかを考えるべきですが、なんとかならんかったら後で変えりゃいいやのノリです
- stepも雑に決めました、スクラッチだしあんま細かくしてもリストが重くなるだけだしなみたいなノリで決めてます
- 計算自体はPythonでやって、計算結果を一次元txtリストに保存、Scratchで読み込み
-
一つの配列に重みやΔを入れるので、レイヤー構造も動的にできるよう考えます
-
前回はループカウンタを1からはじめることでリストを処理していましたが、今回は動的に処理する関係上offset処理があるので、ループカウンタは0からはじめます。
-
前回はローカル変数にtmpを使い回していたが、そのままやるとバグの温床になるのでなるべくやめます
-
あるていどの関数のまとまり(util,init,fwd,bwd)ごとにスプライトを分ける事を検討をしたが、メッセージの非同期処理がGOTO文的で上記のグローバル変数の使い回しと同じでバグの温床になるので基本的には一つのスプライトに書きます
-
かわりの案としてutil系の関数は頭に u_ をつけ、u_系関数でつかう変数も u_ を付与します
-
順伝播、逆伝播の順に s1,s2... のプリフィクスを関数に付与します
- 関数ローカルとして使う変数には s1,s2を付与することで利用範囲をなるべく明確にします
- 関数の引数とreturn値はp_を付与します
- リスト系の変数は s / _arr / _list みたいなサフィックスがつきます
- int,float,text 系の変数は単数系にします
- learning_rate みたいな伝統的な変数も、一回決めて動かないやつは定数として大文字
- その他伝統的な変数もなるべく設計に沿わせて変更します、例えばepochs は EPOCH_COUNT みたいにします
-
なるべく、tmpみたいな変数は使いません....でもでもでもでも、正直めんどくさいよおおおお
その他
Scratchにはintキャストがないのでexp/logテーブルのindex指定に悩みましたが、試したところ2.9348 みたいなfloatをリストのIndexに指定したら勝手に小数点を切り捨ててくれたのでキモいなぁと思いつつ小数点付きの数値をリストのindexに指定する暴挙で進めます
utilから組んでいきます
exp

動作確認


テーブルのIndexを決めるu_exp_indexをみてもらえればわかるとおり小数点が入ったままだがテーブルからは正しい値がとれてしまう、きもい。
あとScratchはindexを1から始めるのほんとやめてほしい、頭が混乱する。
log
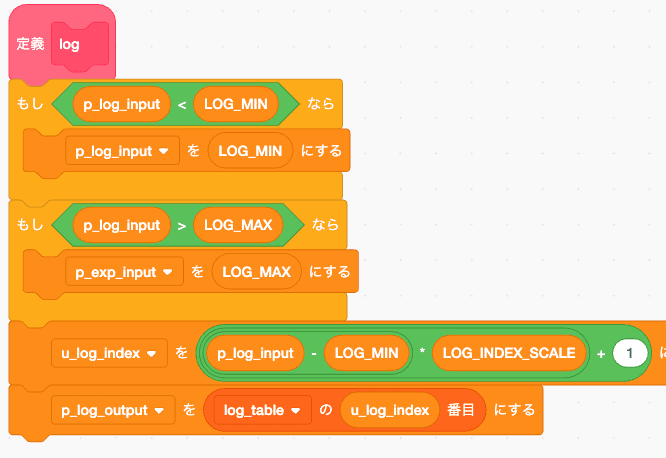
動作確認


おk
sigmoid


まあ、これくらいの精度がでれば十分じゃないかな
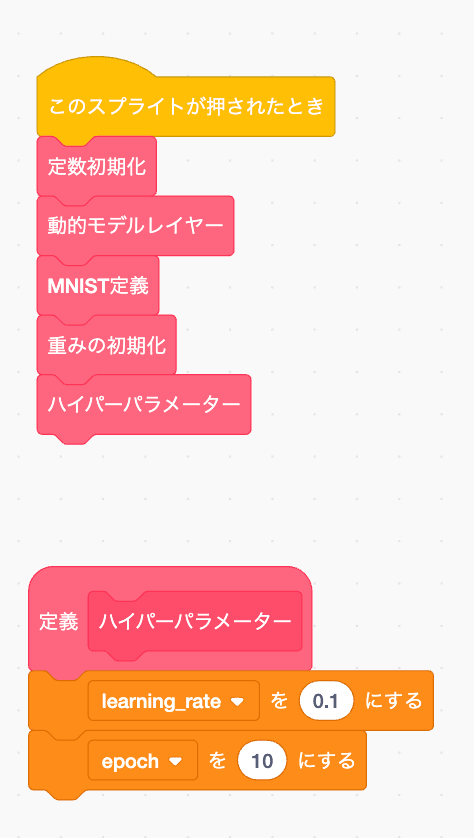
初期化処理
MNIST
学習時に回したりする時使うだろう定数を設定
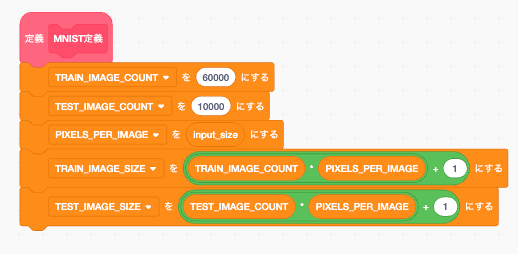
weight スライス用定数作成
重みを一次元で
W1 B1 W2 B2 ....
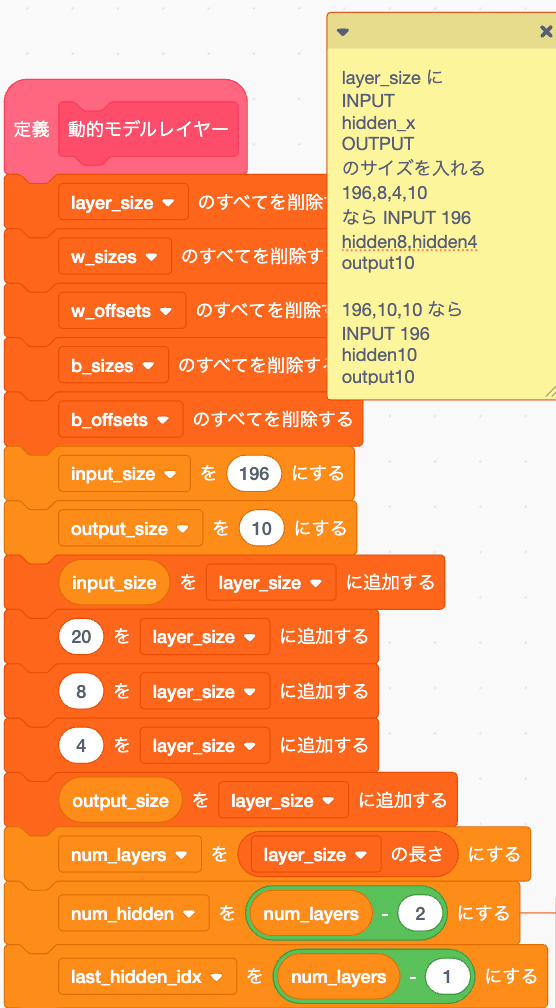
という形で保存して切り出すために、各重みやバイアスのoffsetとサイズを設定していきます。
初期値として
layer_size リストを設定します

196,20,8,4,10
なら INPUTが196
hidden1が20
hidden2が8
hidden3が4
Outputが10です。
なんかややこい処理をしていますが
やっていることは動的にレイヤー構造を設定しようとしているだけです。
ここはできそうだからお遊び要素としてやるか、で実装したところなので誤差逆伝播を試すだけならこんなことしないでoffsetsもsizesも全部定数決めうちでいいです。
と言うかなるべくこんな処理やめた方がいいです
こいつのせいで 変数表示域がめちゃくちゃ汚れて後々かなり後悔しました。
やるにしても初期化時に一回しか呼ばないのでoffsets,sizesあたりだけグローバルにするべきでした... 一度つくっちゃうと編集でグローバル/Localを戻せない...

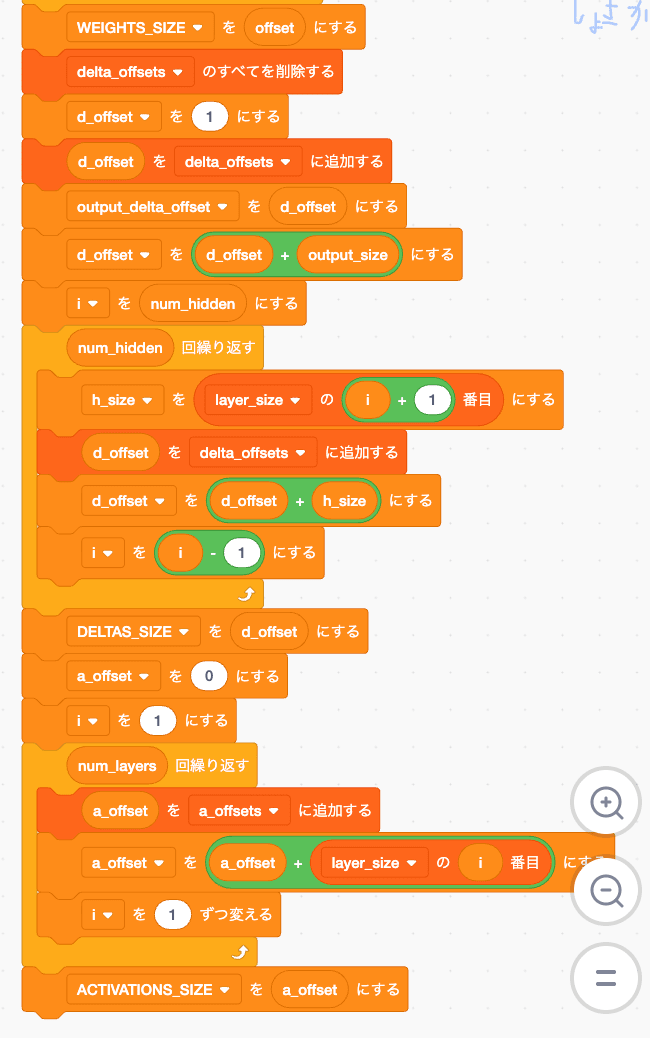
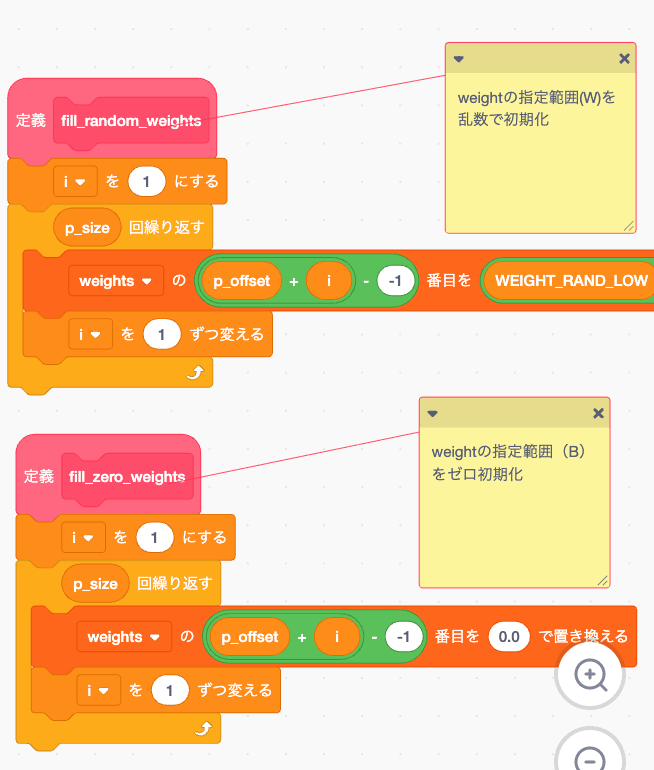
重み初期化
W範囲は乱数初期化
B範囲はゼロ初期化します
これも WとBを並べたせいで面倒なことになっていますが、W1,W2.... B1,B2...
で並べればもっと簡単でした... 俺の馬鹿...
学習画像
これは前回作ったやつをそのまま適用します。
つまり背景を白にして、14x14にリサイズして、1/0にしたやつです。
Pythonから直列にしたtxtで吐き出して、それぞれのリストに読み込みします
一部違うのは、ONE_HOT_LABELにするとリストが長くなるのでPython側ではそのまま出力しています。

あと学習画像60000件、テスト画像が10000件でプロジェクトが保存できなくなりました。

開発をすすめるために 学習600件、テスト100件まで縮小します。
確認用
ついでにデバッグとして学習画像を確認できるようにします
スプライトが押されたらランダムで画像を取り出して、入力用スプライトに展開します。
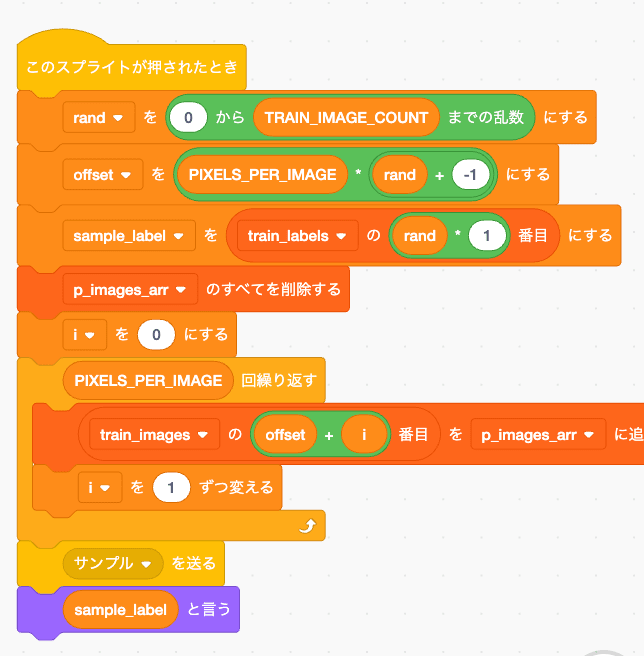
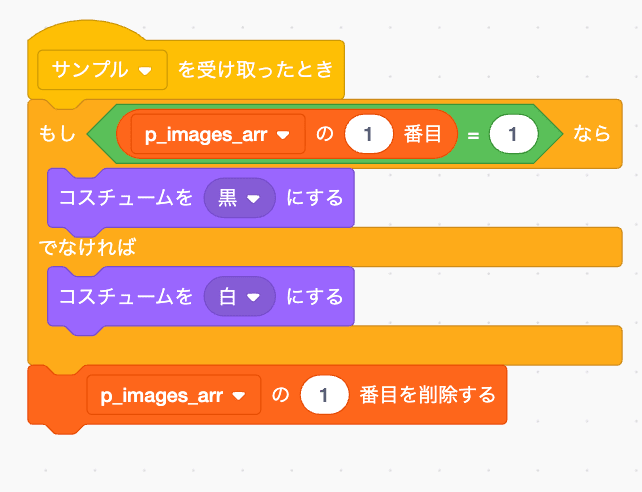


それを9と言い張るんだ...みたいな気持ちになりますね...まあこれらが学習画像です。
重み初期化
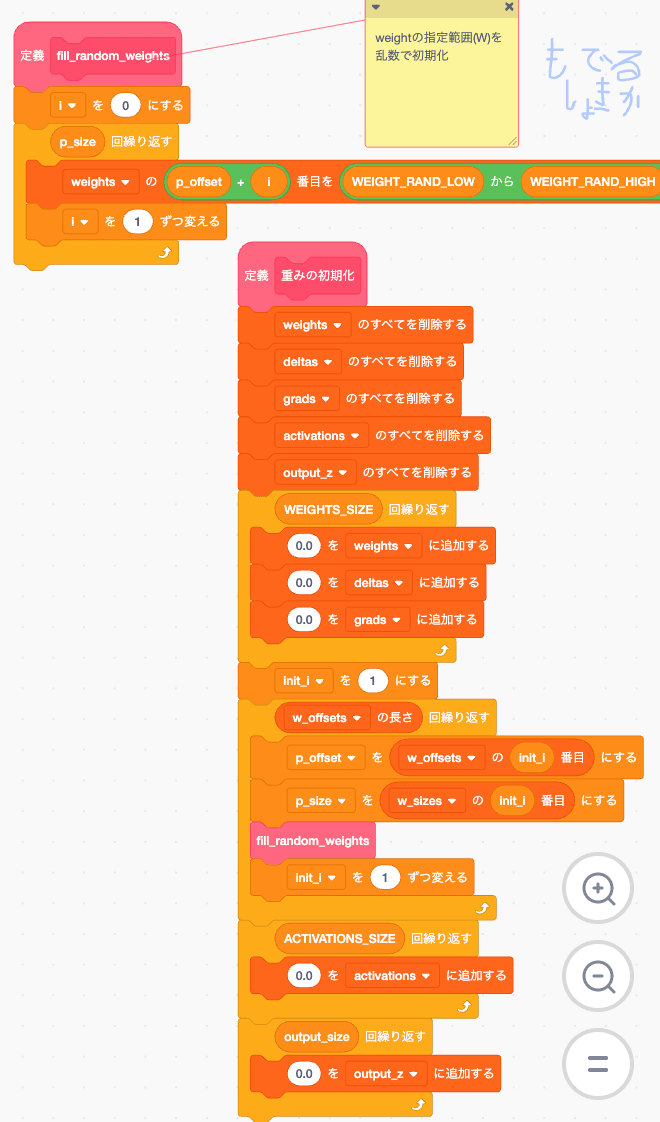
そのまんまですね、weightを0で初期化してから
Wの部分だけランダムに付け替えてます。
他のΔとか勾配もここで0.0にしています。
初期化実行
特に言うことなし
学習用コードの作成
さて、ここまでで学習用の画像とか定数が揃ったんで、学習に使う他の関数も作っていきます
dot
つまるところは z = Σ_i inputs[i]*W[i,j] + b[j] です
かなり横長になっていますが、これは切り出しがあるせいですね。
tmp変数とか使えばもっと横幅は圧縮できるんですが
tmp使うの今回はなるべくやめようとしたらこうなっちゃいました、うーん?色々うまくいかない
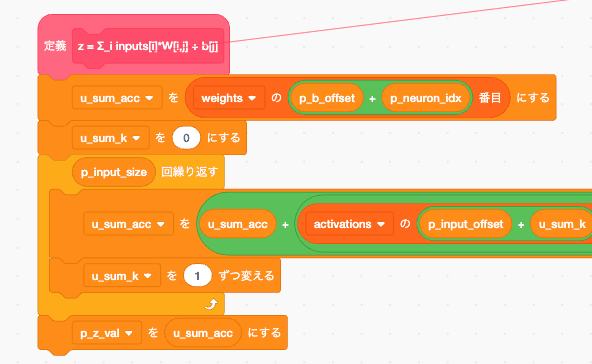

p_ のプリフィクスがついてるやつは引数なのでこの関数を呼ぶ前に定義が必要です。
コメントにも書いてありますがそれぞれ
p_neuron_idx: j
activations[p_input_offset + i]: input[i]
weights[p_w_offset + i * p_hidden_size + j]: W[i,j]
weights[p_b_offset + j]: b[j]
に対応しています。
また p_hidden_sizeは 行サイズとして利用です。
p_w_offsetとp_b_offset は つまるところW1とかB1みたいな重み行列の名前に読み替えてください。
仮に
p_w_offsetがW2のことを指していれば
p_w_offset + i * p_hidden_size + j
ってのはW2のi行,j列目のデータを取り出したいって意味です。
うーん? これweightを切り出す共通関数用意した方が良かったかもですね。
今回は引数を使う関数を作らない、みたいな設計思想を引いてしまいましたが
例外としてweight_slice(W1)みたいなコールをすると、p_weight_target
みたいなグローバルリストに対象のW1が入るようにして、それを処理する方が多分見通しよかったですね。
W1変数にW1のオフセットいれといて、あ、いやそれだと動的にできないんだった。うーん
動的レイヤー構成がよくない、できそうだしやっちゃお!なんて軽い気持ちでやるべきではなかったわ。
u_max_output_z
expのテーブルは自分が雑に作った範囲なので、なるべく収まりがよくなるように最大値を引いていく
つまりexp(z_i - max) / Σexp(z_j - max)の maxを取得するための関数です。

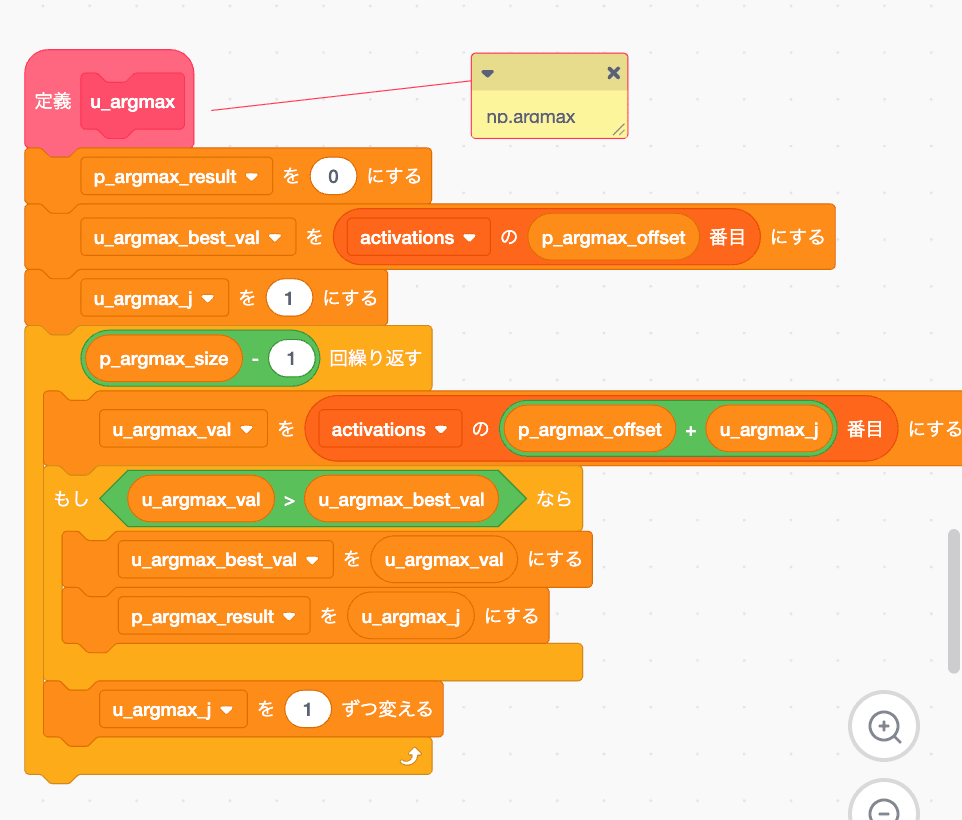
u_argmax
np.argmaxです。
勾配降下法
w = w - learning_rate * grad
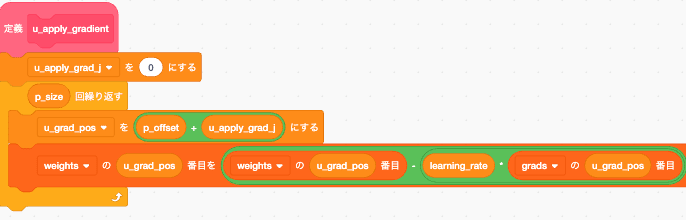
引数として p_offset,p_sizeを必要としますが見たまんまなので説明は省略。数式をコードにしただけです
画像読み出し
画像データを activations の入力層にコピーし、ラベルを target_label に設定する関数
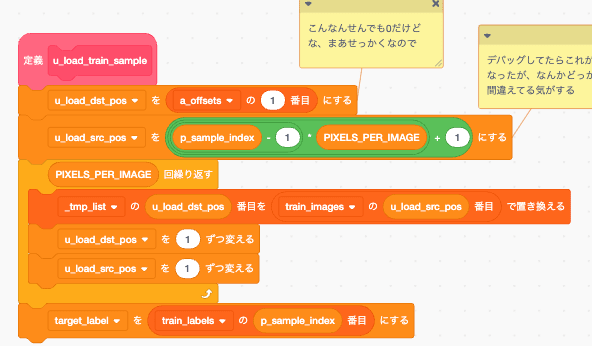
test_loadもほぼ同じ、読み出し元が違うだけなのでtest側は省略
順伝播
はい、順伝播に必要なutilは終わったんで 順伝播を組んでいきます。
にしてもScratchでutil作ってるとめっちゃ飽きてきますね、やっぱ数学苦手なんだなぁ...
前々回にも言った通りMNISTや学習自体の説明は今回しません

そしてここまでくると説明するほどのことがないんですよね
p_wやp_bに今回使うwやbのoffset記述して、それぞれのサイズ書いて次実行してるだけですからね
スライス処理のために書いてる部分除いたらまじ単純な順伝播です。
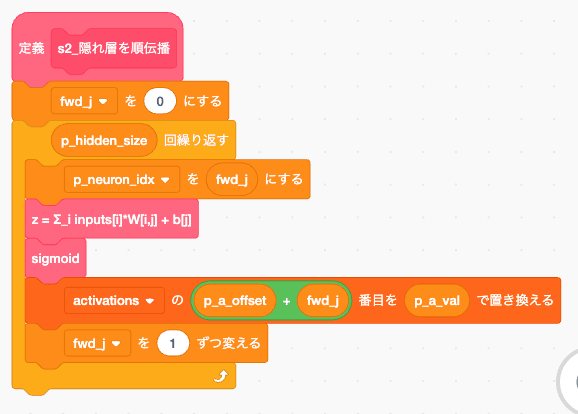
これも、1ニューロンずつ処理してるだけでやってることはDOTとって、活性化関数通してその値をactivationsに保存してるだけです。
普段と違うのは初めにも書きましたがReLUで作ったら数字が爆発してNaNになっちゃったのと、exp/logが先に計算しておいた範囲しかだせない制限があるため、その範囲内に収めるためにsigmoidにしているくらいです。

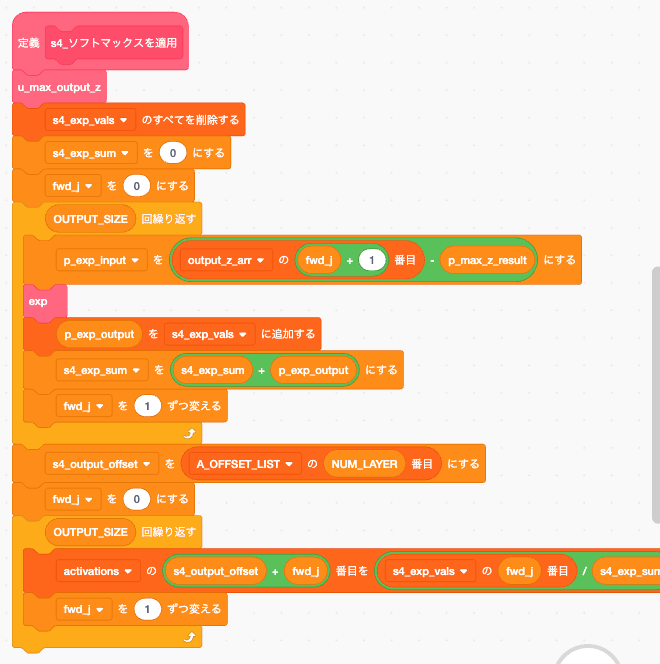

前回は平均誤差で誤魔化してましたがexp/logを実装したおかげでsoftmaxが使えるようになり
さらにいつも通りになりましたね。
はい、順伝播はこれで終わり。
逆伝播用util
次から 逆伝播に必要なutilを組んでいきましょう
といっても、残りは勾配計算だけですが

biasはコピーするだけなので説明不要、
引数はどっちもスライス用のoffsetとそれぞれの行列サイズを送りつけてるだけです。
重みの勾配は ∂L/∂W[i,j] = a[i] × δ[j]
ところで、このスクラッチの画面よく見てほしいんですがループカウンタにした i と j ってめっちゃ区別つきにくくないですか?
なんでiとjを数式に使ったんだ、バグの温床なので 連続する数式にiとjを採用したやつまじどうにかなってほしい、大切な場面で必ず鼻毛が「こんにちはー」って見えちゃう呪いとかかかってほしい。
ついでに + と * も区別つきにくいので どうにかしてほしい。Scratch画面のフォント変えたい
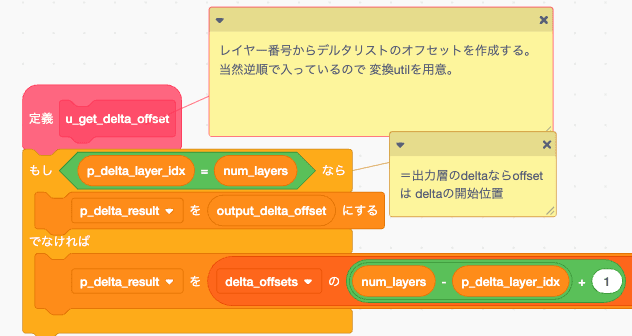
get_delta_offset
仮に 順伝播が
input → hidden1 → hidden2 → output
の時Δは
outputΔ → hidden2Δ → hidden1Δ
の順で 作られるので、それを取り出すためのdelta_offsetの位置取得関数です。
逆伝播
さて、逆伝播を組んでいきますが、順伝播を下から組んでいって正直きつかったんで今度は上から組みます。
正直ボトムアップ型苦手かも...
いやまあこれ逆に上から組んでいったらできるのか?って言われたら、うーん、まあデバッグがさらにキツかったと思う。
つーわけで愚痴り終わり、次は上から組みます

はい、こんなんでしょ、いやー美しい。
説明不要なの嬉しいです
出力層更新

途中のオレンジの箱は全部offset位置を引数として渡すための処理です。
定数にしときゃこんなもん全部不要です。
なんで動的レイヤーなんて挑戦しちゃったんだ...
まあそれも後少しです。

はい、メインのΔ計算部分ですね。
ちょっと前にも書いてますがdeltaを逆伝播の順に更新していきます。
つまり出力層が1番目で、次に隠れ層_n n-1 ... 隠れ層_1と格納していきます。
隠れ層更新
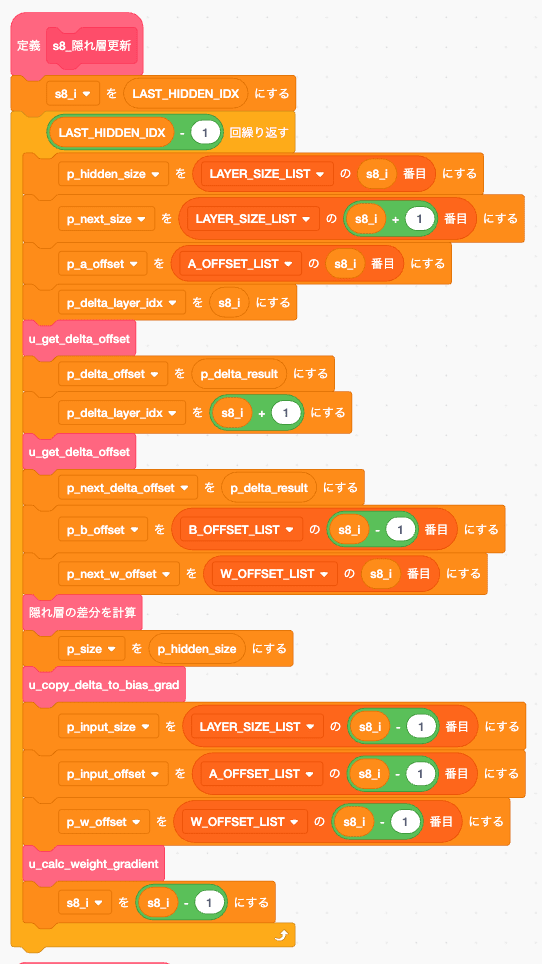
これも途中のオレンジの箱はoffset位置か、グローバル変数に引数を設定しているものです。

hidden_layer のΔ計算ですね。
ある意味今回のメインなんですが、ここまで書いてきたことを組み合わせているだけなので、特段説明するべきことがないですね。
引数をグローバル変数にいれてるせいでオレンジの箱が多くてみにくいだけで、そこを除けば差分計算して、更新してるだけの普段通りのやつです。
update_weight
というわけで重みを更新します

なんで s11なの? s9じゃないのと思った方がいたらするどい。
元は差分更新関数にもstepがついていたからで、隠れ層更新がs9だからです
じゃあなんでそこ消したんだって言われたら、更新関数を一個に共通化しようとあれこれいじっていたけど、読みづらかったんで元にもどしたからです!!!
それならs11もs9にしろよって思った方、あなたはレビュワーの才能があります。
だって、隠れ層更新は s9_ってついてる変数使ってんだもん... 直すと被るじゃん... ごめん...
完成
と、いうわけで完成しました わーぱちぱちぱち。
はい、早速回してみましょう。
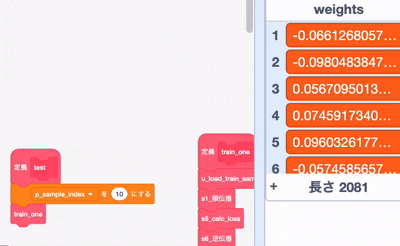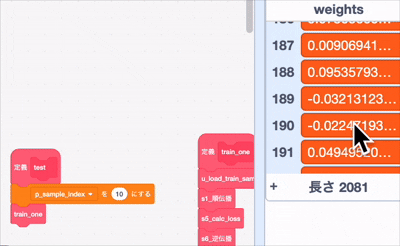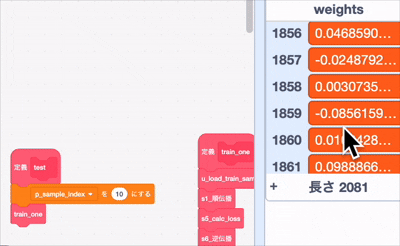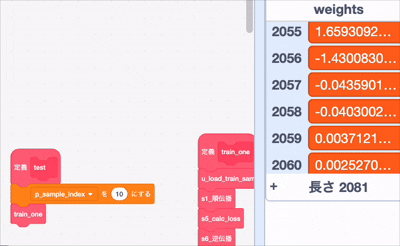
あーーーーー..... 重みの上の方が更新されてないですね...
下の方は更新されているので、勾配計算が届いてない
まあ、それでも一部は更新されているので、どっかのアホが動的にしたせいでoffsetがずれてるんでしょうな、勾配消失の可能性もあるかな?はー、ほんとアホは最後の最後まで問題を残す
というわけで今日はここまで、次回はデバッグ作業です!
Link
day1 MNIST推論機をScrachで組む
day2 推論機に重みを移植する
day3
本記事
day4 デバッグする
最終的に完成する誤差逆伝播をScratchの標準機能だけで実装したやつ

株式会社ガラパゴス(有志) 株式会社ガラパゴスのエンジニアを中心に情報発信をしている Publication です。 各記事の内容は個人の意見であり、企業を代表するものではございません。
Discussion